
이전에 index 관련된 글을 올렸습니다.
B-Tree 방식으로 index가 구성되어있다는 것만 알고 깊게 보진 않았는데요.
오늘은 B-Tree에 대해 자세히 살펴보고자 합니다.
B-Tree 란?
B-Tree는 균형 이진 트리(Balanced Binary Tree)의 일종으로, 데이터베이스 시스템과 파일 시스템에서 널리 사용되는 자료구조입니다.
대량의 데이터를 효율적으로 관리하고 검색할 수 있게끔 설계되어있습니다.
특징
B-Tree에서 지켜야하는 몇 가지 특징이 있는데요. 아래와 같습니다.
- 균형 트리: B-Tree의 모든 Leaf 노드는 동일한 깊이를 가지며, 트리가 변경될 때마다 이 균형이 유지됩니다.
- 다입도: B-Tree의 각 노드는 여러 개의 자식을 가질 수 있습니다. 이때 노드당 가질 수 있는 최대 자식의 수를 차수(order)라고 합니다. 차수를
m이라고 가정할 때, 최대m개의 자식을 가질 수 있기 때문에 노드는 최대 2개의 키를 저장할 수 있습니다. - 키 정렬: 각 노드에 저장된 키는 정렬된 상태로 유지됩니다.
- 분할 및 병합: 노드의 키가 너무 많아지면 노드가 분할되고, 반대로 키가 너무 적어지면 노드가 인접한 형제 노드와 병합됩니다.
- 최소 사용률: B-Tree는 각 노드가 최소한 차수의 절반만큼 키를 가지도록 유지시킵니다. 만약 절반으로 나누어떨어지지 않다면 올림합니다.
목적
B-Tree의 주요 목적은 디스크 I/O 작업을 최소화하면서 대량의 데이터를 저장하고 검색하는 것입니다.
저는 그래서 메모리에 인덱스 테이블을 올려두고 작업하는줄 알았는데요. 그것이 아니었습니다. 일부의 index만 메모리에 올려둔다고 하네요.
디스크에서 데이터를 읽거나 쓸 때, 보통 한 번의 I/O 작업으로 디스크 내의 한 블록의 데이터를 읽거나 씁니다. B-Tree는 이러한 블록 단위의 I/O를 최적화하기 위해 설계되었다고 하는데요. 이때 노드마다 하나의 블록에 저장되는 방식을 이용하여 디스크 I/O를 최소한으로 줄입니다.
이진 트리를 이용하게 되면 각 노드는 하나의 키 밖에 가지지 못하기 때문에 공간 비효율적이게 됩니다.
B-Tree는 이런 문제점을 개선하고자 이진 트리를 확장하여 N개의 자식을 가질 수 있도록 고안되었습니다. 이때 각 노드는 넣을 수 있는 양 만큼의 키를 저장하여 공간 효율적으로 디스크를 관리합니다.
동작 원리
차수(order)를 3이라고 가정하고 B-Tree를 차곡차곡 쌓아보겠습니다.
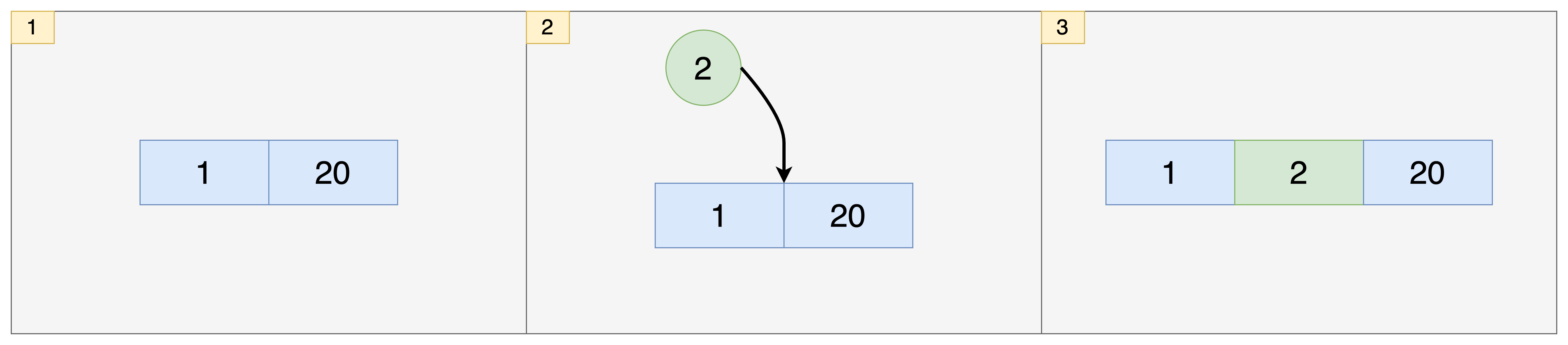
- 키가 1과 20인 것이 tree에 있었다고 가정합니다.
- 2를 추가하는 요청이 들어왔습니다. 2는 1보다 크고, 20보다 작기 때문에 1과 20 사이에 저장됩니다.
- 2가 노드에 추가되었습니다. 그런데 노드에 2개의 키 밖에 저장하지 못하기 때문에 새로운 노드를 만들어야합니다.
- 먼저 20을 떼어내서 새로운 노드를 만듭니다. 그리고 가운데 키 값이었던 2는 부모 노드로 만들어 승급시킵니다. 이렇게 노드가 2개 추가되었습니다.
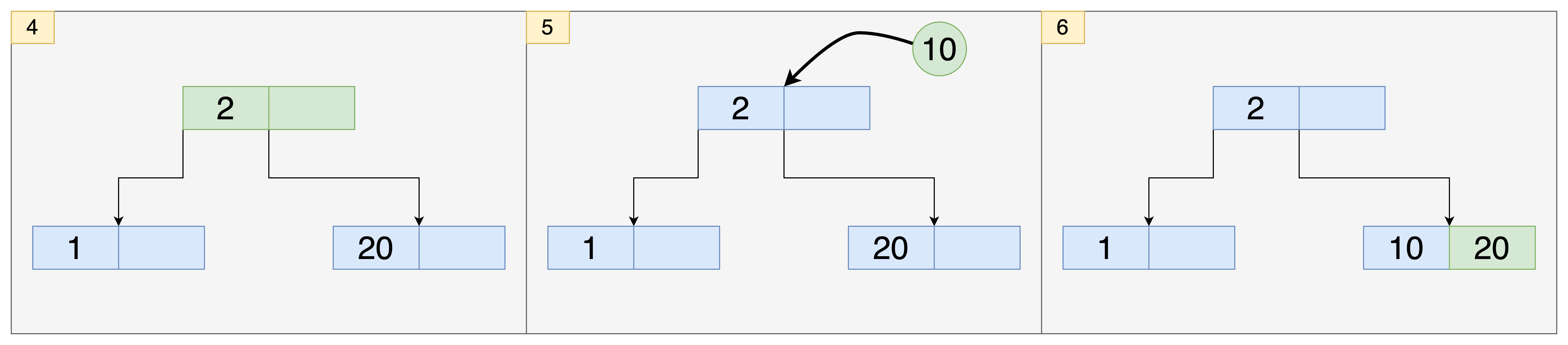
- 이번에는 10이 요청으로 들어왔습니다. 부모 노드에서 10이 2보다 큰 지 비교합니다. 2보다 크기 때문에 오른쪽 자식 노드로 이동합니다.
- 자식 노드(leaf 노드)에 있던 20과 비교했을 때, 10은 20보다 작기 때문에 10을 20보다 앞에 둡니다. 이렇게 자식 노드가 정렬됩니다. 만약 중간 branch 노드였다면 자식 노드를 더 탐색해야했지만, leaf 노드이기 때문에 key를 추가했습니다.
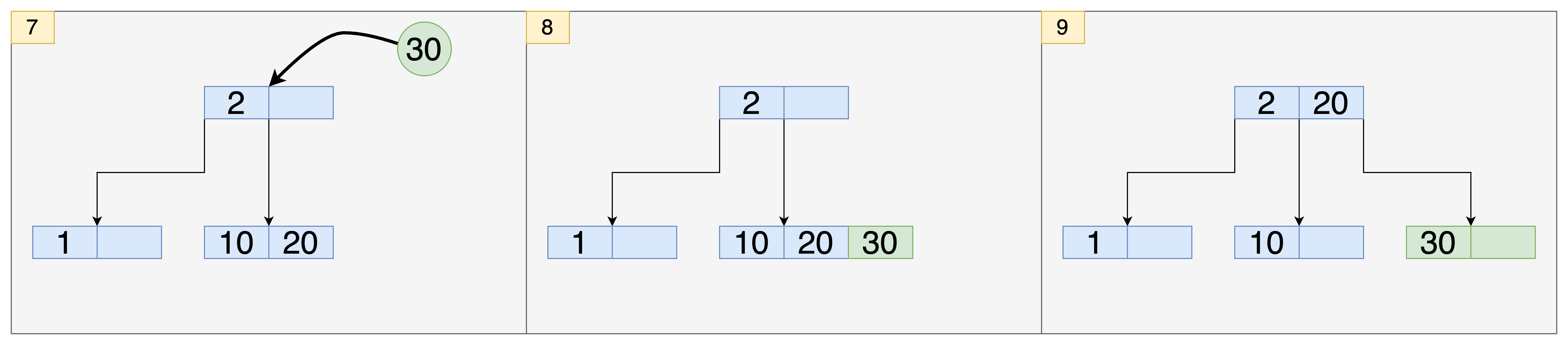
- 30이 추가되는 요청이 들어왔습니다.
- leaf 노드까지는 잘 도착했지만, leaf 노드의 수용 공간이 다 찼습니다. 따라서 새로운 공간을 만들어주었습니다.
- 새로운 leaf 노드를 만들었고, 20을 루트 노드로 승격시켰습니다. 이렇게 2보다 작으면 왼쪽 자식 노드, 2보다 크고 20보다 작으면 중간 자식 노드, 20보다 크면 오른쪽 자식 노드로 이동할 수 있게 했습니다.
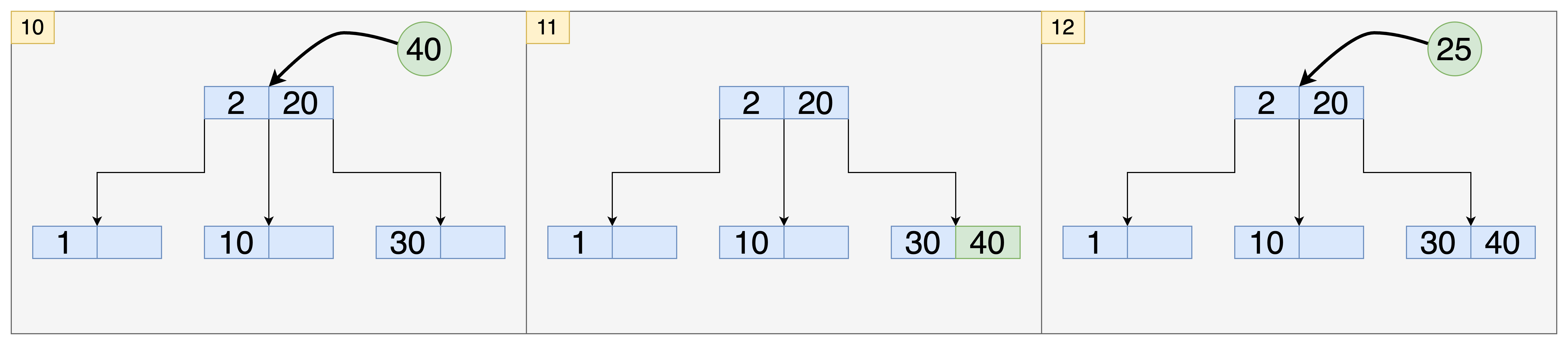
- 40이 추가되는 요청이 들어왔습니다.
- 노드의 추가 없이 40이 오른쪽 자식 노드에 추가되었습니다.
- 25가 추가되는 요청이 들어왔습니다.
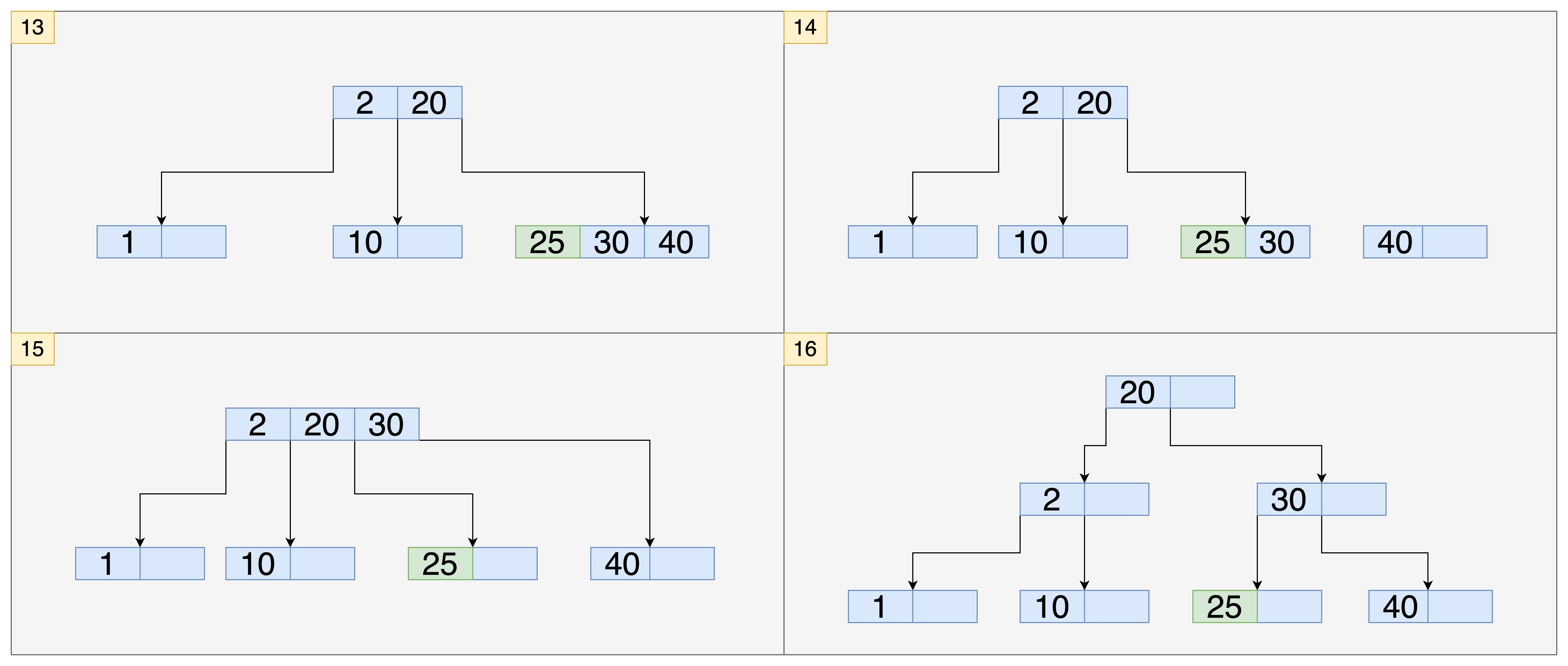
- 20보다 크기때문에 오른쪽 자식 노드로 25를 위치시킵니다. 하지만 자식 노드의 키 개수가 3개가 되었습니다.
- 오른쪽 자식 노드에서 가장 큰 값인 40을 새로운 노드로 만들어 분리했습니다.
- 그리고 30을 부모 노드로 승격시켰습니다. 이때도 문제가 발생합니다. 노드의 키 개수가 3이 되기때문에 부모 노드에서도 노드를 분리합니다.
- 자식 노드와 같은 과정을 거치면 그림처럼 새로운 부모 노드가 생성됩니다.
위와 같은 로직으로 B-Tree의 키가 저장됩니다. 별 것 아닌 규칙들 같지만, 자연스레 모든 leaf 노드가 같은 레벨에 있는 것을 알 수 있습니다.
이렇게 B-Tree는 모든 검색에 대해 logN의 시간 복잡도를 보장하고 있습니다.
B-Tree 조회 방식
B-Tree 의 경우에는 모든 key 값이 pk 값이나 DB 레코드 포인터를 가지고 있습니다.
만약 Primary Key Index 라면 (pk, 레코드 포인터) 쌍을 노드에 저장하고 있고, Secondary Index 의 경우에는 (칼럼 값, pk) 쌍을 노드에 저장하고 있습니다.
중요한 건, 부모 노드, 브랜치 노드, 리프 노드 상관 없이 모든 노드의 key가 pk 값이나 레코드 포인터를 저장하고 있다는 것입니다.
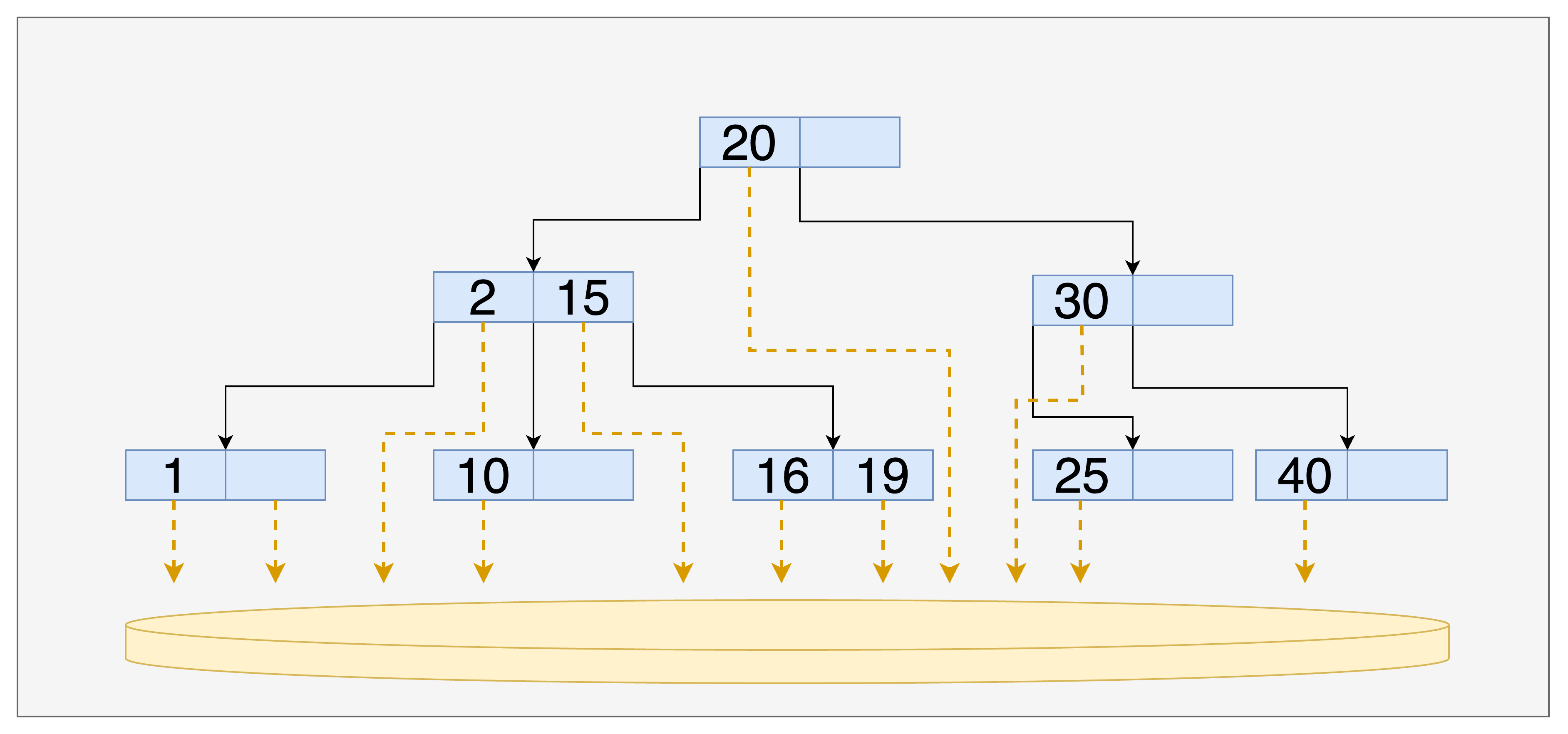
B+Tree
지금까지 B-Tree에 대해 살펴보았는데요. 실제로 mysql은 B-Tree의 개념을 이용한 B+Tree를 사용하여 index 테이블을 구성한다고 합니다.
B+Tree는 B-Tree와 어떤 부분이 다를까요?
- B+Tree에서 모든 키 값들은 leaf 노드에만 저장되며, 브랜치 노드나 루트 노드는 leaf 노드들로의 경로를 가리키는 용도로 사용됩니다. 루트와 브랜치 노드들에는 키 값만 있고, 실제 레코드에 대한 포인터는 leaf 노드에만 존재합니다.
- leaf 노드들이 양방향 혹은 단방향 연결 리스트로 서로 연결되어 있습니다. 덕분에 범위 검색이 더 쉽고 효율적입니다.
- 키가 leaf 노드에만 존재하므로, 루트와 브랜치 노드에 더 많은 키를 한 페이지에 저장할 수 있어 디스크 I/O를 줄이는 데 도움이 됩니다.
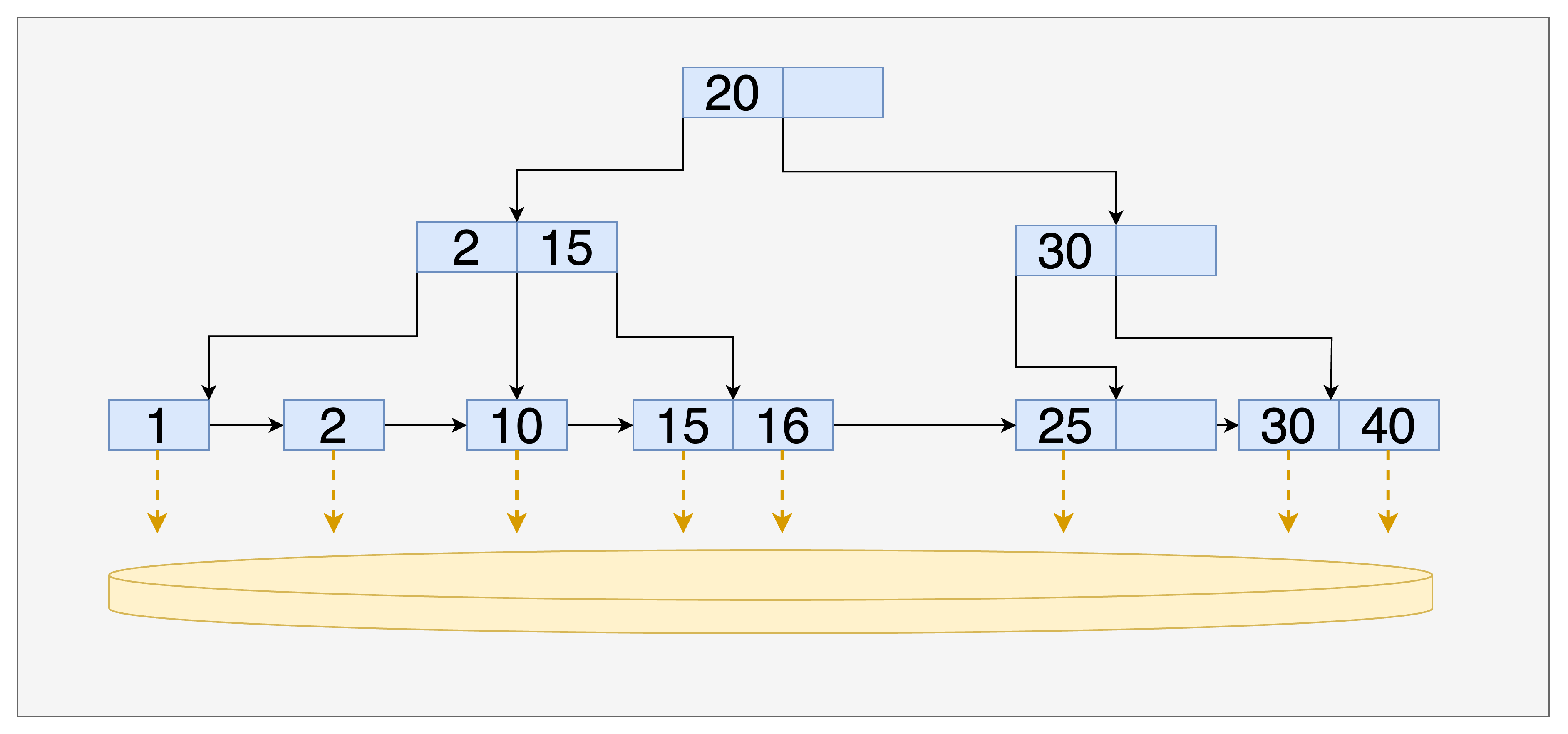
위 그림과 같이 leaf 노드에만 레코드 포인터를 저장하고 있습니다. 그리고 linked list 형태로 leaf 노드 간의 범위 검색이 가능하도록 설계했습니다. (mysql은 더블 링크드 리스트라고 합니다.)
마무리
index가 어떤 방식으로 데이터베이스 레코드 포인터를 검색하는지 알았습니다. 다음에는 mysql 만의 index를 효율적으로 사용하는 방식에 대해 알아보겠습니다.
