데이터베이스
데이터베이스 관련 명령어
데이터베이스 생성

데이터베이스 사용
데이터베이스를 이용해 테이블을 만들거나 수정하거나 삭제하는 등의 작업을 하려면, 먼저 데이터베이스를 사용하겠다는 명령을 전달해야 합니다.

테이블 생성
USE 를 이용해 데이터베이스를 선택했다면, 이제 테이블을 만들 수 있습니다.
다음은 user라는 테이블을 만드는 예제입니다. 테이블은 필드(표의 열)와 함께 만들어야 합니다.
다음과 같은 필드 조건이 있다고 가정합니다.
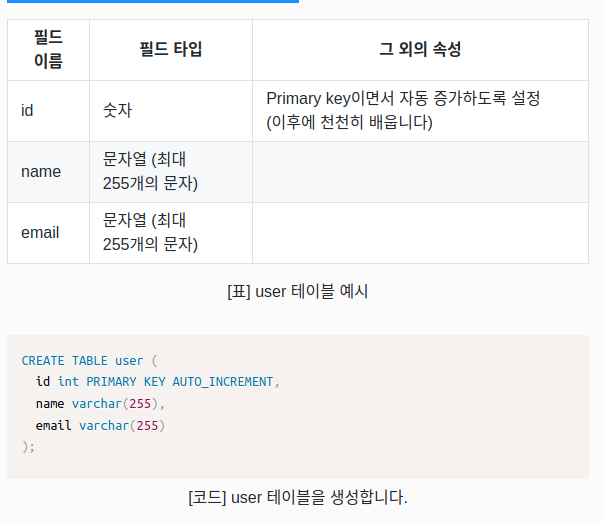
SQL 콘솔에서 Enter 키를 이용해 여러 줄의 코드를 입력할 수 있습니다.
위와 같이 입력하고, 다음에서 설명할 DESCRIBE 명령어를 이용해 테이블 정보를 확인합니다.
테이블 정보 확인
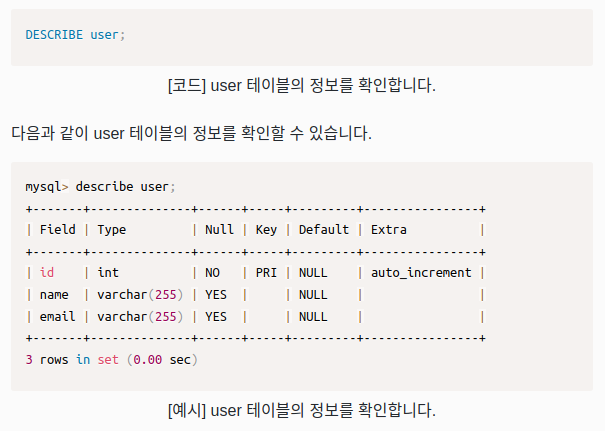
참조 : https://jhnyang.tistory.com/307
https://support.microsoft.com/ko-kr/office/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%A0%95%EC%9D%98-%EC%BF%BC%EB%A6%AC%EB%A5%BC-%EC%82%AC%EC%9A%A9%ED%95%98%EC%97%AC-%ED%85%8C%EC%9D%B4%EB%B8%94-%EB%98%90%EB%8A%94-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EB%A7%8C%EB%93%A4%EA%B8%B0-%EB%98%90%EB%8A%94-%EC%88%98%EC%A0%95-d935e129-229b-48d8-9f2d-1d4ee87f418e
관계형 데이터베이스
테이블을 사용하는 데이터베이스를 관계형 데이터베이스라고 합니다.
반드시 알아야 하는 키워드
- 데이터(data): 각 항목에 저장되는 값입니다.
- 테이블(table; 또는 relation) : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적됩니다.
- 칼럼(column; 또는 field) : 테이블의 한 열을 가리킵니다.
- 레코드(record; 또는 tuple) : 테이블의 한 행에 저장된 데이터입니다.
- 키(key) : 테이블의 각 레코드를 구분할 수 있는 값입니다. 각 레코드마다 고유한 값을 가집니다. 기본키(primary key)와 외래키(foreign key) 등이 있습니다.
관계 종류
1:1 관계(거의 사용하지 않음)
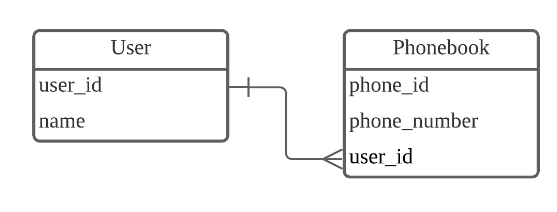
1:N 관계
N:N 관계(Join Table이 필요함)
1:N 관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
N:N 관계
여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우
N:N(다대다) 관계를 위해 스키마를 디자인할 때에는, Join 테이블을 만들어 관리합니다.
고객 한 명은 여러 개의 여행 상품을 구매할 수 있고, 여행 상품 하나는 여러 명의 고객이 구매할 수 있습니다.
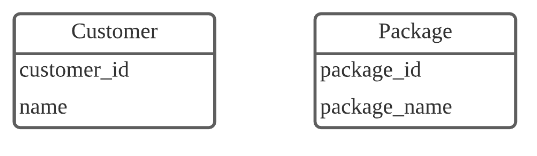
다대다 관계는 두 개의 일대다 관계와 그 모양이 같습니다.
두 개의 테이블과 1:N(일대다) 관계를 형성하는 새로운 테이블로 N:N(다대다) 관계를 나타낼 수 있습니다.
이렇게 다대다 관계를 위한 테이블을 Join table이라고 합니다.

이렇게 조인 테이블을 생성하더라도, 조인 테이블을 위한 기본키(여기서는 cp_id)는 반드시 있어야 합니다.
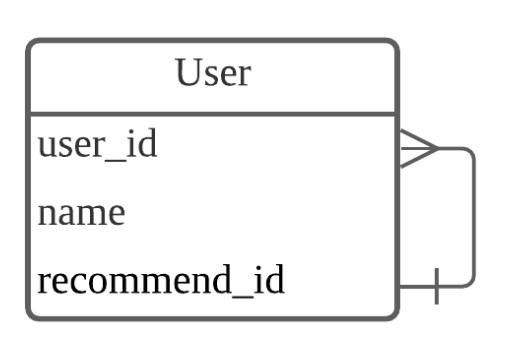
자기참조관계
때로는 테이블 내에서도 관계가 필요합니다.
예를 들어 추천인이 누구인지 파악하기 위해 사용할 수 있습니다.
참조 : https://www.w3schools.com/sql/sql_alias.asp
SQL
mysql -u root -p
//엔터치고 sql 접속
use mysql
alter user 'root'@'localhost' identified with mysql_native_password by '여기에비밀번호작성하세요';
//Query OK, 0 rows affected (0.01 sec) -> 이 멘트뜨면 비밀번호 설정완료
exit
mysql -u root -p
//변경한 비밀번호 입력
//sql 접속 완료주의사항
모든 것은 객체다!!!!
띄어쓰기를 하고싶으면 []안에 띄어쓰기해서 넣기!!
기본적으로 띄어쓰기는 안 된다
EXTRACT
특정 날짜/시간 값이나 날짜 값을 가진 표현식으로부터 원하는 날짜 영역을 추출하여 출력
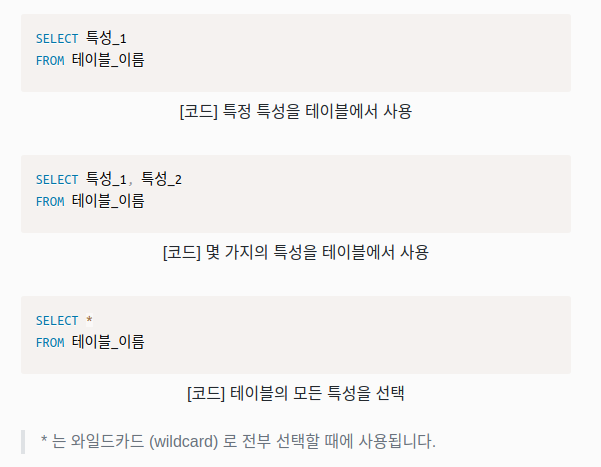
SELECT
하나 또는 그 이상의 테이블에서 데이터를 추출하는 SQL의 데이터 조작 언어(DML) 중 하나이다.
이것은 데이터베이스 중 하나 또는 그 이상의 테이블에서 데이터를 추출하기 위한 명령으로 데이터 조작 언어 (DML)에서 가장 많이 사용.
SELECT는 데이터셋에 포함될 특성을 특정합니다.
SELECT + colume
FROM
테이블과 관련한 작업을 할 경우, 반드시 입력해야 한다.
FROM 뒤에는 결과를 도출해 낼 데이터베이스 테이블을 명시한다.
FROM + Tablename
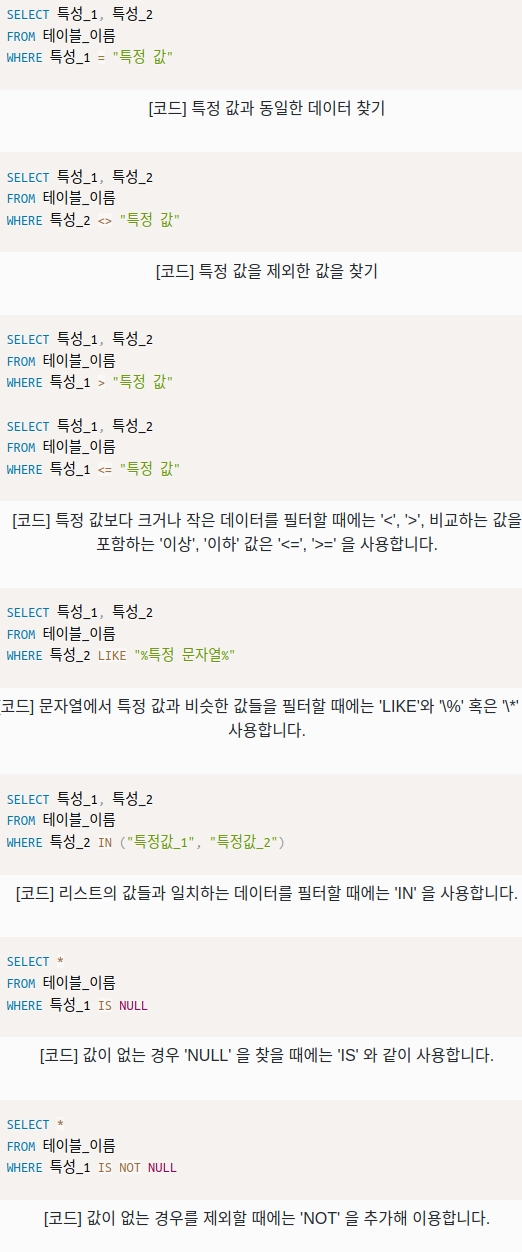
WHERE
If!!!
WHERE + colume
필터 역할을 하는 쿼리문입니다.
WHERE은 선택적으로 사용할 수 있습니다.
UPDATE
DB의 테이블에서 데이터를 갱신
웹 페이지에서 ‘등록’이나 ‘갱신’와 같은 버튼을 클릭했을 때 처리되는 데이터 갱신 기능
테이블에 존재하지 않는 열을 지정하면 에러가 발행하여 해당 명령은 실행되지 않는다
DELETE
테이블 의 DELETE기존 레코드를 삭제하는 데 사용됩니다.
다음 SQL 문은 "Customers" 테이블에서 고객 "Alfreds Futterkiste"를 삭제합니다.
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';
INSERT INTO
테이블에 새 레코드를 삽입하는 데 사용됩니다.
다음 SQL 문은 "Customers" 테이블에 새 레코드를 삽입합니다.
INSERT INTO Customers//Tablename (CustomerName, ContactName, Address, City, PostalCode, Country)//column
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway')//column에 들어갈 것. 순서를 지켜야 함.;
앞에 ID는 자동으로 들어간다
SELECT DISTINCT
유니크한 값을 받고 싶을 때 사용한다.
지정된 것이 중복되지 않고 고유한 자료만을 반환한다.
테이블 내부의 열에는 종종 많은 중복 값이 포함되기 때문에, 고유한 값만 나열하고 싶을 때 사용.

AS
바꾸기.
바꾼다기보다는 새로운 KEY를 만들어 KEY 값을 AS 다음에 나오는 새로운 KEY에 복사하여 할당한다고 생각하면된다.
column 3 {3455667}
AS로 5로 수정 -> colume 5 {3455667}
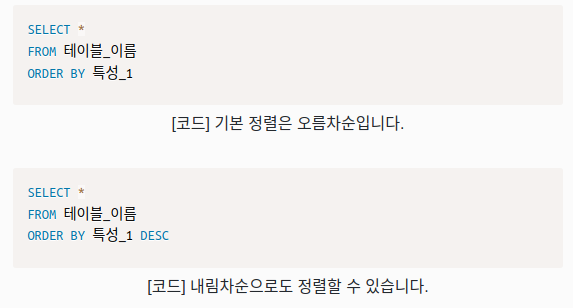
ORDER BY
ORDER BY 키워드는 결과 집합을 오름차순 또는 내림차순으로 정렬하는 데 사용됩니다 .
키워드는 ORDER BY기본적으로 레코드를 오름차순으로 정렬합니다.
레코드를 내림차순으로 정렬하려면 DESC키워드를 사용하십시오.
오름차순으로 정렬하려면 ASC 사용
LIMIT
결과로 출력할 데이터의 개수를 정할 수 있습니다.
LIMIT은 선택적으로 사용할 수 있습니다.
그리고 쿼리문에서 사용할 때에는 가장 마지막에 추가합니다.

INNER JOIN
INNER JOIN 이나 JOIN 으로 실행할 수 있습니다.
두 테이블에서 일치하는 값이 있는 레코드를 선택합니다 .

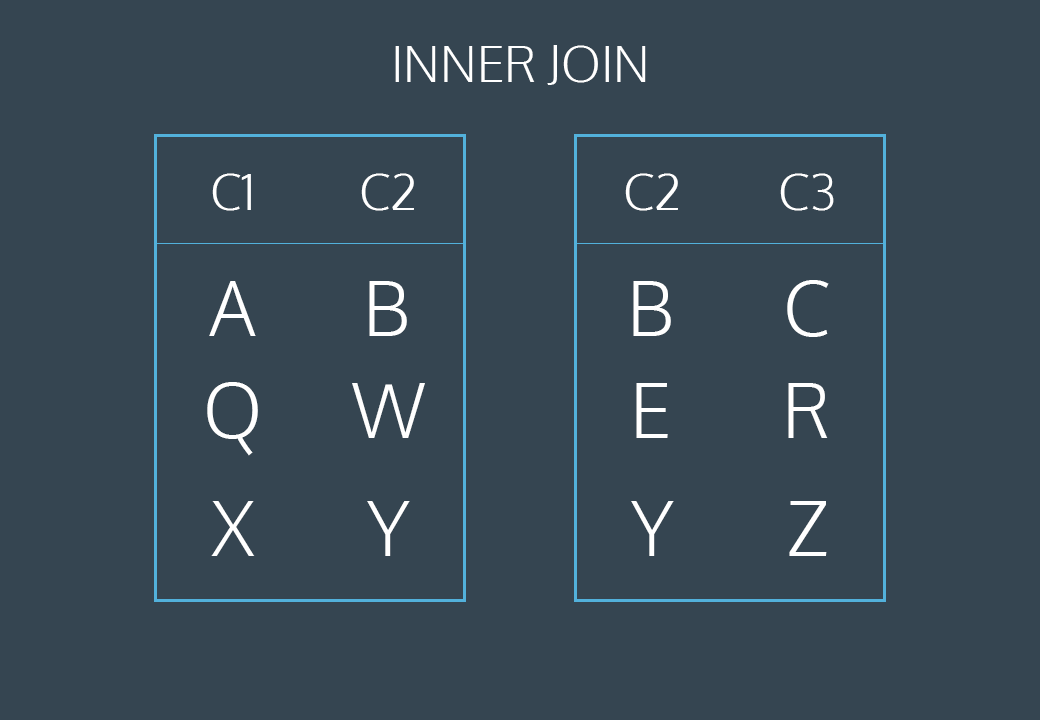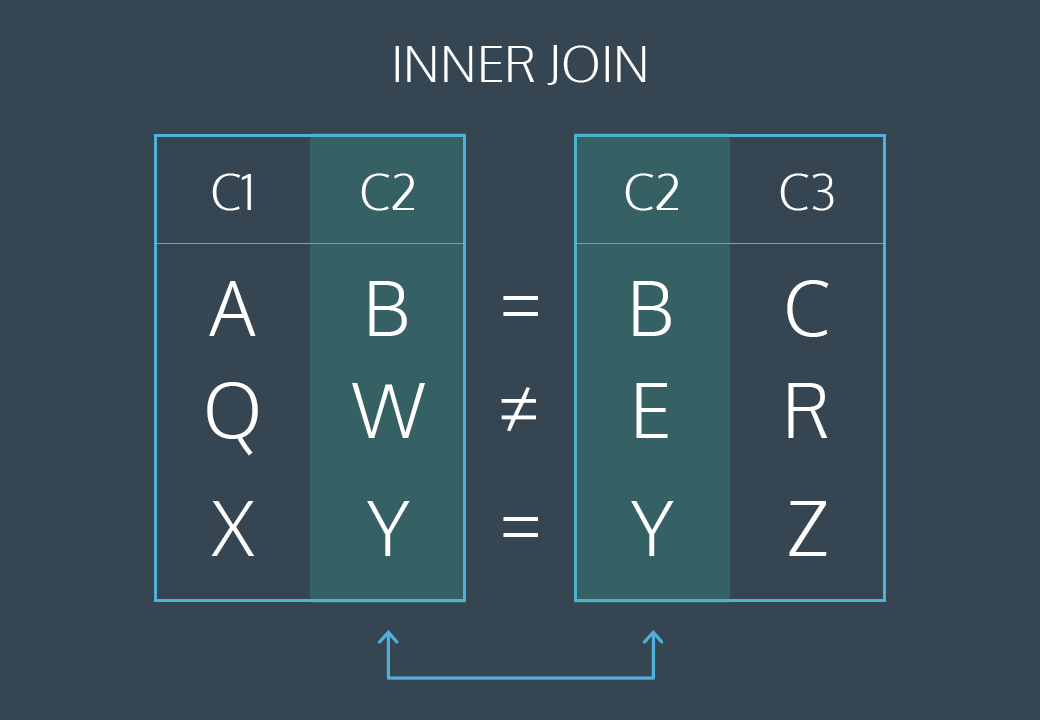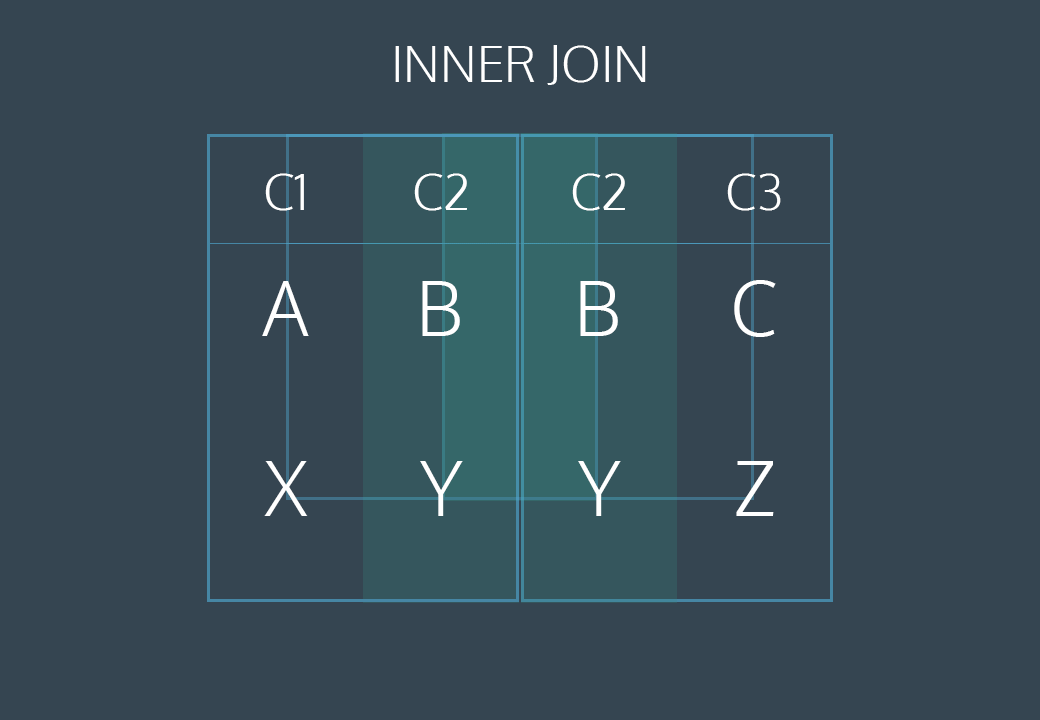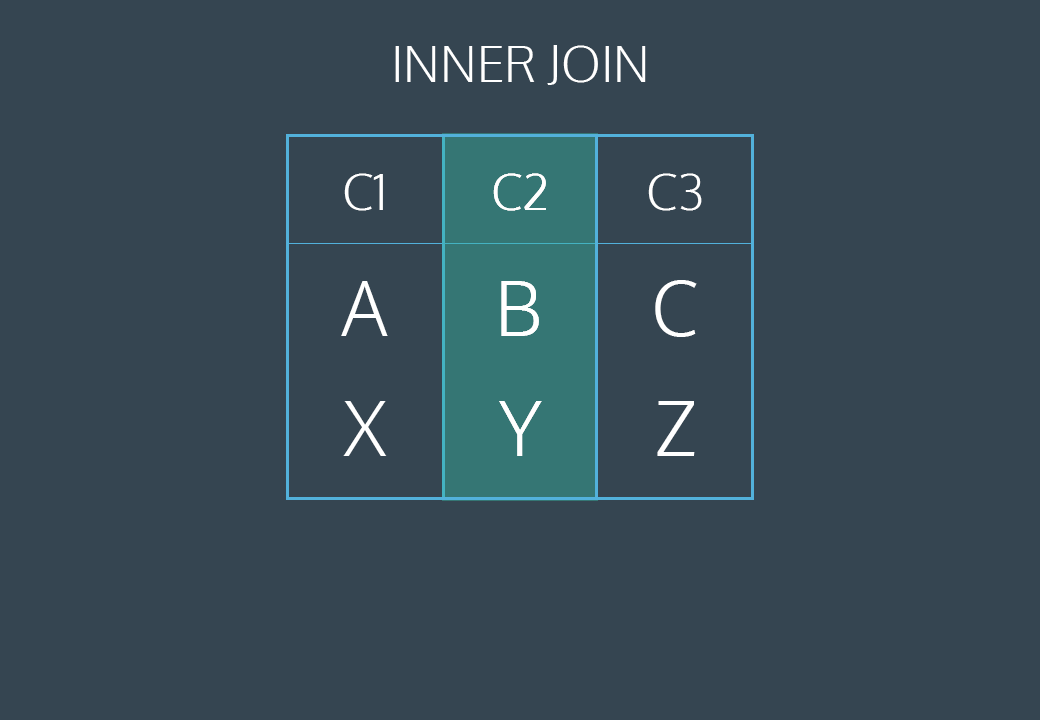
다음 SQL 문은 고객 정보가 있는 모든 주문을 선택합니다.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
OUTER JOIN

drop
Table 자체를 삭제한다(database를 삭제한다)
BETWEEN
주어진 범위 내에서 값을 선택합니다.
값은 숫자, 텍스트 또는 날짜일 수 있습니다.
BETWEEN연산자 포함: 시작 및 종료 값이 포함됩니다 .
다음 SQL 문은 가격이 10에서 20 사이인 모든 제품을 선택합니다.
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20;
NOT NULL
기본적으로 열은 NULL 값을 보유할 수 있습니다.
제약 조건은 열이 NOT NULLNULL 값을 허용하지 않도록 합니다.
이렇게 하면 필드에 항상 값이 포함됩니다.
다음 SQL은 "Persons" 테이블이 생성될 때 "ID", "LastName" 및 "FirstName" 열이 NULL 값을 허용하지 않도록 합니다.
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255) NOT NULL,
Age int
);
LIKE
LIKE연산자는 열에서 지정된 패턴을 검색하기 위해 절에서 사용 됩니다 WHERE.
LIKE연산자와 함께 자주 사용되는 두 개의 와일드카드가 있습니다.
퍼센트 기호(%)는 0, 1 또는 여러 문자를 나타냅니다.
밑줄 기호(_)는 하나의 단일 문자를 나타냅니다.
SQL 내장함수
집합연산: 레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산
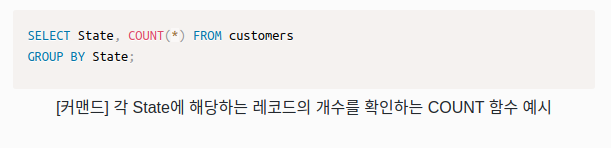
GROUP BY
데이터를 조회할 때 그룹으로 묶어서 조회합니다.
다음과 같은 쿼리가 있다고 가정하겠습니다.

이 쿼리를 주(state)에 따라 그룹으로 묶어서 표현할 수 있습니다.

GROUP BY 쿼리로 간단하게 State에 따라 그룹화할 수 있습니다.
쿼리의 결과를 확인하면, 데이터가 중간에 비어있는 것을 확인할 수 있습니다.
데이터베이스에서 데이터를 불러오는 과정에서 State에 따라 그룹을 지정했지만, 그룹에 대한 작업 없이 조회만 했습니다.
그래서 쿼리의 결과로 나타나는 데이터는 각 그룹의 첫 번째 데이터만 표현됩니다. // 무슨말인지 이해 못함
HAVING
HAVING은 GROUP BY 로 조회된 결과를 필터링할 수 있습니다.

이렇게 GROUP BY로 그룹을 지은 결과에 필터를 적용할 때에는 HAVING을 사용할 수 있습니다.
HAVING은 WHERE과는 적용하는 방식이 다릅니다. HAVING은 그룹화한 결과에 대한 필터이고, WHERE는 저장된 레코드를 필터링합니다.
따라서 실제로 그룹화 전에 데이터를 필터해야 한다면, WHERE을 사용합니다.
COUNT()
레코드의 개수를 헤아릴 때 사용합니다.

위 커맨드를 실제로 실행하면, 각 그룹의 첫 번째 레코드와 각 그룹의 레코드 개수를 집계하여 리턴합니다.
다음과 같이 변경하면, 그룹으로 묶인 결과의 레코드 개수를 확인할 수 있습니다.
SUM()
SUM 함수는 레코드의 합을 리턴합니다.

위 커맨드는 invoice_items라는 테이블에서 InvoiceId 필드를 기준으로 그룹하고, UnitPrice 필드 값의 합을 구합니다.
AVG()
AVG 함수는 레코드의 평균값을 계산하는 함수입니다.

MAX(), MIN()
MAX 함수와 MIN 함수는 각각 레코드의 최댓값과 최솟값을 리턴합니다.
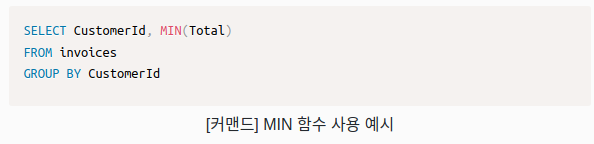
위 커맨드에서 MIN을 MAX로 변경하면, 각 고객이 지불한 최대 금액을 리턴합니다.
SELECT 실행 순서
데이터를 조회하는 SELECT 문은 정해진 순서대로 동작합니다.
SELECT 문의 실행 순서는 다음과 같습니다.
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY

위 쿼리문의 실행 순서는 다음과 같습니다.
1. FROM invoices: invoices 테이블에 접근을 합니다.
2. WHERE CustomerId >= 10: CustomerId 필드가 10 이상인 레코드들을 조회합니다.
3. GROUP BY CustomerId: CustomerId를 기준으로 그룹화합니다.
4. HAVING SUM(Total) >= 30: Total 필드의 총합이 30 이상인 결과들만 필터링합니다.
5. SELECT CustomerId, AVG(Total): 조회된 결과에서 CustomerId 필드와 Total 필드의 평균값을 구합니다.
6. ORDER BY 2: AVG(Total) 필드를 기준으로 오름차순 정렬한 결과를 리턴합니다.
truncate tableName
Table은 유지한 채 안에 record(rows)를 초기화
table 및 field(colume), record(rows)
헷갈리지말고 잘 구별하자
