이변량 분석 (범주 -> 숫자)
평균 비교
-
범주 -> 숫자를 비교하는 방법은 평균을 비교한다
-
barplot 을 사용
-
범주가 2개 : 두 평균의 차이 비교
-
범주가 3개 : 전체 평균과 각 범주의 평균 비교
if
- 생존 여부에 따라 나이의 차이가 있다.
sns.barplot()
- 평균 비교 barplot()
- 평균을 계산하는 plot()
sns.barplot(x = 'x' , y = 'y', data = df)
plt.grid()
plt.show()
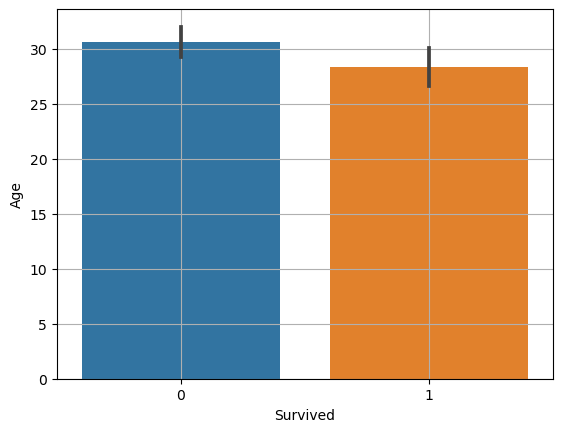
신뢰구간(오차범위)
-
평균값이 얼마나 믿을만 한가.
-
좁을수록 믿을만 하다.
-
데이터 가 많을수록 , 편차가 좁을수록 신뢰구간이 좁아 짐.
-
두 평균에 차이가 크고 , 신뢰구간은 겹치지 않을떄 , 대립가설이 맞다고 볼수 있다.
평균 비교 방법
범주가 2개 일떄 (T-test)
- 두 범주의 평균을 구한다음 차이를 구한다.
범주가 3개 이상일떄(Anova))
- 전체 평균과 각 그룹 평균에 차이가 있는가?
T 통계량
-
두 그룹 간에 평균간 차이를 표준오차로 나눈 값
-
차이 가 클려면 절대값이 커야 한다
-
p-value 가 0.05 보다 작으면 차이가 있다.
-
-2 보다 작고 2보다 크면 차이가 있다.
ttest_ind(B,A ,equal_var = False)
- A와 비교 할때 B 의 평균이 큰가?
- equal_var : A와 B 의 분산이 같은가 (모르면 False)
분산 분석 (ANOVA)
- 여러 집단 간에 차이 비교 : 기준은 전체 평균
- 집단 간 분석이 크면 -> F통계량이 크다 -> 대립가설이 맞을 가능성이 크다
가설
- 귀무가설 : 범주별 숫자형 데이터는 차이가 없다.
- 대립가설 : 범주별 숫자형 데이터는 차이가 있다.
문법 f_oneway(A,B,C)
- 전체 평균과 A,B,C 각각의 평균은 차이가 있는가?
spst.f_oneway(P_1, P_2, P_3)
주의
- 평균 대비 각 그룹간 차이가 있는지만 알려줌
- 어느 그룹 간에 차이가 있는지는 알수가 없음

개발자 되고 싶어요