데이터분석
1.데이터 분석 - 1

열 추가 혹은 열 삭제 방법값 추가 혹은 값 삭제 방법지정한 열 이름 변경 모든 칼럼을 다 변경하는 방법이다 (칼럼 수 가 같아야 한다) columns 안에 dict 형태로 "기존의 컬럼 이름" : "변경할 칼럼 이름 "rename 안에 inplace 옵션을 True
2.데이터 분석 - 2

매핑 기준에 따라 : 인덱스 (행) , 컬럼이름(열) 을 기준으로 데이터 프레임을 붙이는 작업이다.세로 (행으로 합쳐라 ) 행 방향으로 붙이는 작업이다 칼럼 이름이 똑같아야 한다.inner , outer 옵션이 있다.inner 옵션은 같은 행과 열만 합치고 , oute
3.데이터 분석 - 3
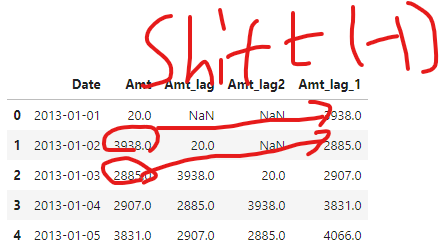
행과 행에 시간의 순서 (흐름) 행과 행 의 시간간격이 동일한 데이터 날짜 타입의 변수로 부터 날짜의 요소를 뽑아낼 수 있습니다.dt.날짜요소(년,월,일,시,분,초,분기,요일,...등등)format 형식은 알려줘야 한다.시계열 데이터에서 시간의 흐름 전후로 정보를 이동
4.데이터 분석 - 4
matplotlib 기본 차트 그리기데이터 요건차트 꾸미기 비즈니스 패턴을 인식하기 위한 목적이다.원본 데이터 가 요약이 된다.요약을 하는 관점에서 해석이 달라질수가 있다.어떤 식으로 요약을 하면 정보의 손실이 발생한다.기본 차트를 그리는 방법 중에 하나이다.x축 :
5.데이터 분석 - 5
단변량 분석 - 숫자형 if 20명의 나이 데이터 가 존재 한다고 보자 한눈에 파악할려면 무엇을 해야 할까요? 숫자형 변수 정리 방법 대푯값 으로 요약하기 mean : 평균 / 산술 평균 / 기하 평균 / 조화 평균 median : 자료의 순서상 가운데 위치한 값
6.EDA & CDA
탐색적 데이터 분석그래프 , 통계량 데이터를 요약하는 값들 (합계 , 평균 , 최대값 , 최솟값)만약 어떠한 case 가 맞는지 틀리는지 보고 싶을떄 가설검정실험언제 어떤 그래프를 그릴것인가.언제 어떤 통계량을 구할것인가언제 어떤 가설감정 방법을 사용할것인다.개별 변수
7.데이터 전처리
데이터 구조 만들기모델링을 위한 전처리 누락되는 값이 없어야 한다.(Nan)모든 값이 숫자여야 모델링이 가능하다 (범주 ->숫자)범주의 값도 숫자화 해야 한다.이상치의 값을 맞춰줘야 한다.
8.CRISP - DM
business understanding -> data understanding -> data preparation -> modeling -> evaluation -> deployment1단계 문제를 정의 비즈니스 문제를 해결해야 한다. 2단계 데이터 이해데이터가 어디
9.데이터 분석 - 6
범주별 빈도수를 세는 경우가 많다 (pd.value_counts())범주별 비율을 만든다 (각각의 개수를 / 전체 개수로 나눠라 )시리즈의 값들의 빈도를 체크normalize 를 True 로 바꾸면 일반화 (빈도수 의 비율화) 로 바꿔주는 작업을 한다.범주별 빈도수를
10.데이터 분석 - 7
새로운 연구를 위해 새로운 가설을 수립한다.실험을 통해 결과 데이터를 수집한다.수집한 데이터를 통해 입증을 해야 한다.기존 가설 -> 기존 가설의 반하는 증거 확인 -> 가설 수립 -> 데이터 수집 -> 가설 검정-> 채택가설이 충족하지 않은 경우 가설을 업데이트 해야
11.데이터 분석 - 8
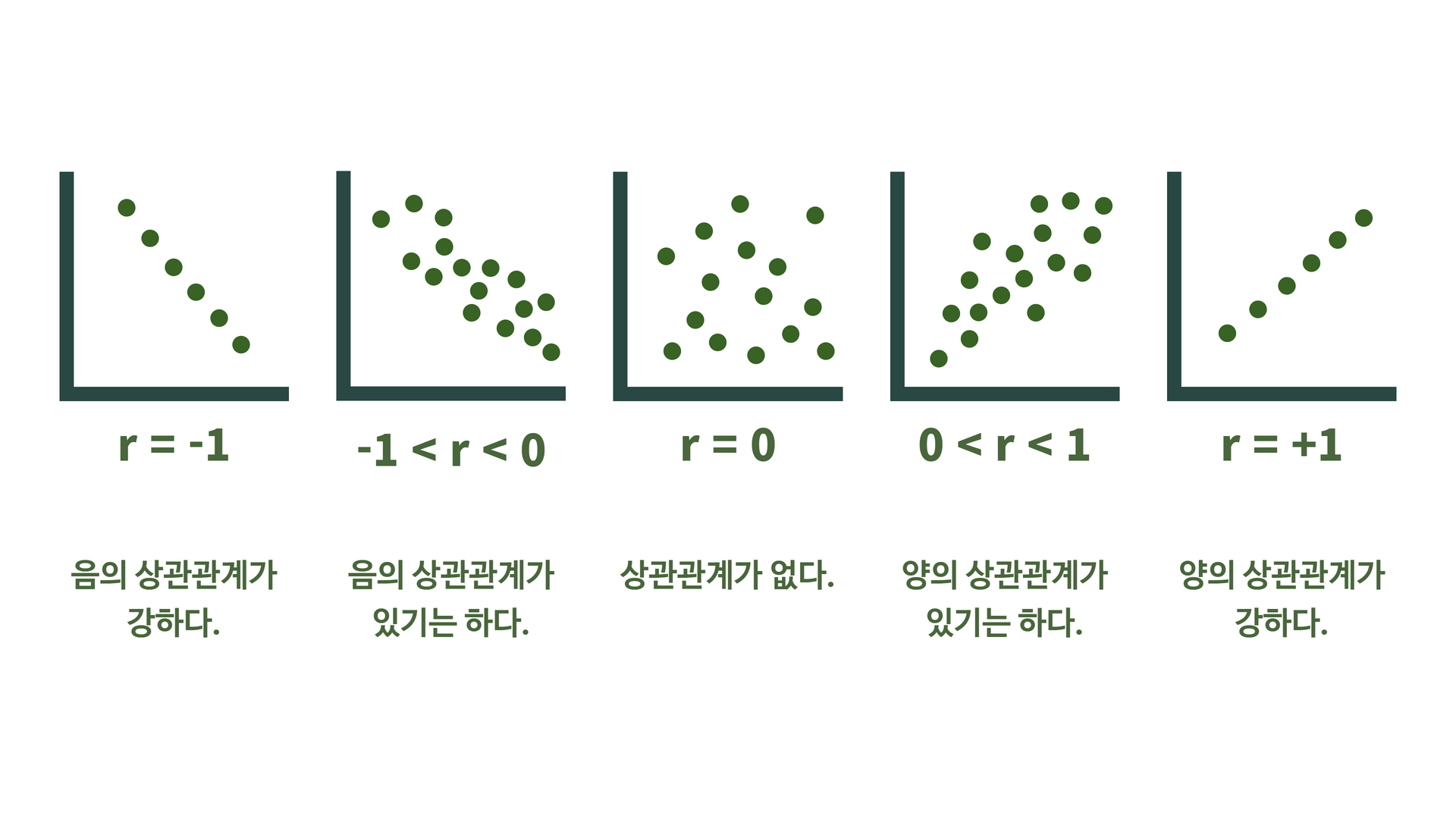
시각화 : 산점도 (scatter)수치화 : 상관 분석 점을 찍어서 그래프를 그린다각 점들이 얼마나 직선에 모여 있는지를 직선을 그린다두 숫자형 변수의 관계를 나타내는 그래프 는 무조건 산점도 이다.직선의 관계 가 있는지 확인해야 한다.plt.scatter(x값 , y
12.데이터 분석 - 9
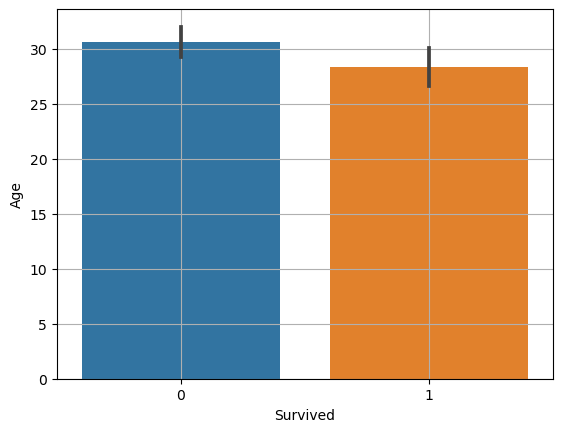
범주 -> 숫자를 비교하는 방법은 평균을 비교한다barplot 을 사용범주가 2개 : 두 평균의 차이 비교 범주가 3개 : 전체 평균과 각 범주의 평균 비교 생존 여부에 따라 나이의 차이가 있다.평균 비교 barplot()평균을 계산하는 plot()평균값이 얼마나 믿을
13.데이터 분석 - 신뢰구간
평균과 분산모집단과 표본표본평균 으로 모평균 추정중심극한정리95% 신뢰구간 한 집단을 설명하기 위해 대푯값으로 평균을 계산했을떄 값들이 평균으로 부터 얼마나 떨어져 있는지 나타내는 값을 표준 편차라고 한다분산 : 편차 제곱의 평균표준편차 : $$분산 \*\* 0.5$$
14.데이터 분석 - 10

교차표를 만들어야 한다.if 타이타닉호에서 성별 생존 여부를 계산할떄 남자중에 사망수 / 생존수 여자 중에 사망수 / 생존수 를 계산해 교차표를 만들어야 한다.이러한 교차표를 Confusion Matrix 라고 한다.교차표를 시각화 해야 한다 (Mosaic Plot)
15.데이터 분석 - 11
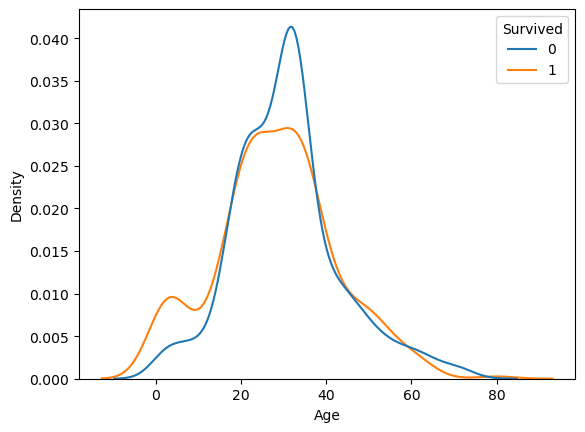
kdeplot 을 통해 판단을 하는것이다 .common_norm = False 옵션과 multiple = 'fill'시각화 는 kde plot 을 그리는 데 group 별로 그렸다.두개의 그래프가 접촉 하는 부분은 전체 평균과 같은 지점이다.그래프를 해석 할때는 전체
16.데이터 분석 - 실습
고객사는 \* 대출업무는은행 창구에서 신청을 받고본사의 심사부서에서는 신용평가를 통해 대출 신청에 대한 승인 여부를 결정해 왔습니다.현장의 요구경쟁사의 공격적인 대출상품 판매로, 본사에서는 자사 은행의 대출 실적이 줄어들고 있는 것에 부담을 느끼고 있습니다.그런데, 자
17.데이터 분석 - 대중교통
서울시 대중교통 데이터 서울시 구별 버스 승하차 이용 데이터 / 서울시 버스 데이터서울시 구별 생활 인구 데이터서울시 구별 주민 등록 인구 데이터서울기 구별 업종 등록 데이터 서울시 버스는 경기도 를 넘나든다 -> 서울시 정보만 추출해야 한다5자리 버스 정류장 코드
18.가설 검정 결론 - 온도
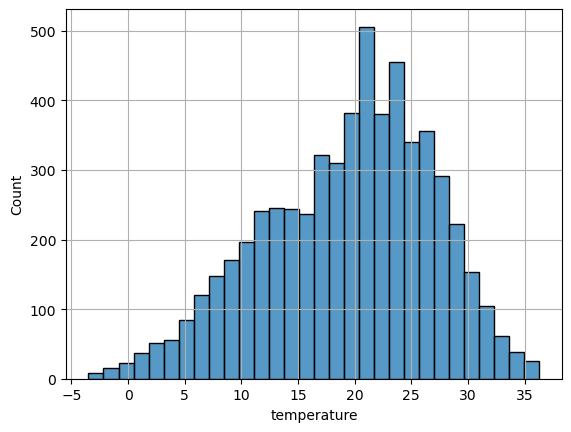
H0 : 온도가 따릉이 수요와 관련이 없다H1 : 온도가 따릉이 수요와 관련이 있다histplot 으로 출력해보면 15도 ~ 25도 데이터가 50% 를 차지하는것을 확인할수 있습니다.온도 -> 습도 영향을 미치는지 확인하기 위해서 regplot 을 그려 선형성을 확인해
19.가설 검정 결론 - 습도
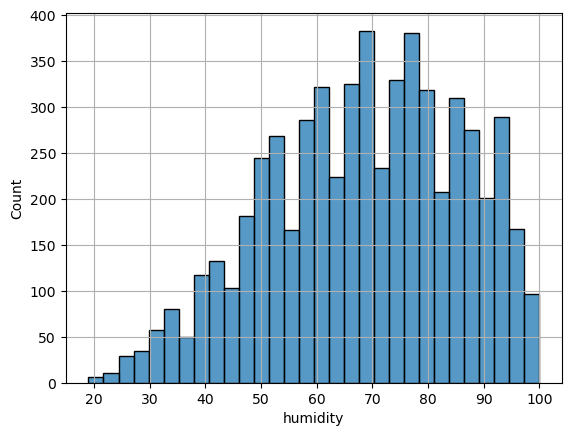
H0 : 습도는 따릉이 수요와 관련이 없다.H1 : 습도는 따릉이 수요와 관련이 있다.이상치가 없는 데이터 분포를 나타내고 있으면서 60% ~80% 습도가 전체 데이터의 50% 를 차지한다.습도가 높으면 우하향 그래프를 그리는 결과를 확인할수 있다.상관관계 값 역시 중