👩💻인덱스 내부 작동
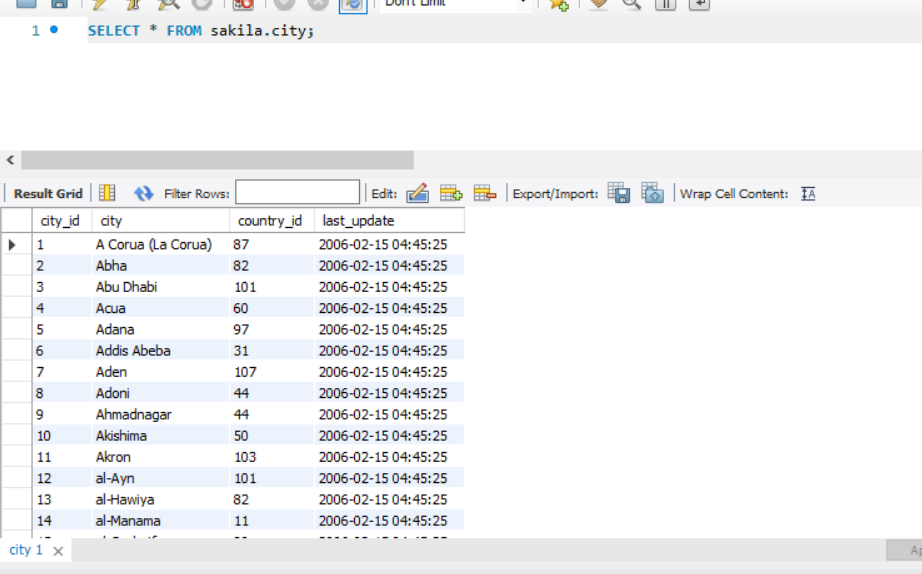
B-Tree(Balanced Tree- 균형 트리)
새로운 용어
- 루트 노드 : 노드의 가장 상위 노드
- 리프 노드 : 제일 마지막에 존재하는 노드
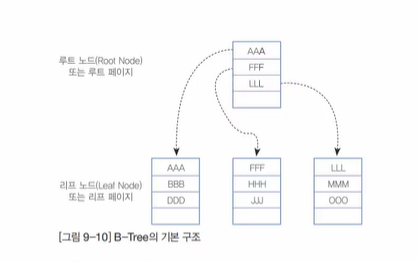
INSERT를 할 때 오히려 성능을 저하 시킬 수 있다.
예제를 만들어보자
인덱스가 없이 아래와 같이 테이블을 만들고, 데이터를 입력하자.
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS clustertbl;
CREATE TABLE clustertbl
(userID CHAR(8),
name VARCHAR(10)
);
INSERT INTO clustertbl(userID, name) VALUES (2, '카일워커');
INSERT INTO clustertbl(userID, name) VALUES (27, '진첸코');
INSERT INTO clustertbl(userID, name) VALUES (16, '로디리');
INSERT INTO clustertbl(userID, name) VALUES (20, '베르나르두 실바');
INSERT INTO clustertbl(userID, name) VALUES (25, '페르난지뉴');
INSERT INTO clustertbl(userID, name) VALUES (7, '라힘 스털링');
INSERT INTO clustertbl(userID, name) VALUES (26, '리야드 마레즈');
INSERT INTO clustertbl(userID, name) VALUES (9, '홀란드');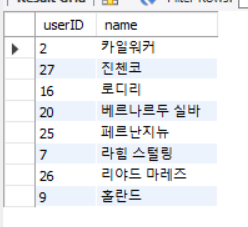
PK로 지정하자.
ALTER TABLE clustertbl
ADD CONSTRAINT PK_clustertbl_userID
PRIMARY KEY (userID);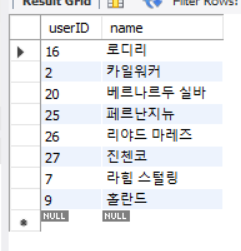
위와 같이 userID가 PK로 지정되면 클러스터형 인덱스가 되므로 사전식으로 정렬이 된다.
Unique제약조건을 이용해 보조 인덱스를 생성해보자
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS secondarytbl;
CREATE TABLE secondarytbl
( userID CHAR(8),
name VARCHAR(10)
);
INSERT INTO secondarytbl(userID, name) VALUES (2, '카일워커');
INSERT INTO secondarytbl(userID, name) VALUES (27, '진첸코');
INSERT INTO secondarytbl(userID, name) VALUES (16, '로디리');
INSERT INTO secondarytbl(userID, name) VALUES (20, '베르나르두 실바');
INSERT INTO secondarytbl(userID, name) VALUES (25, '페르난지뉴');
INSERT INTO secondarytbl(userID, name) VALUES (7, '라힘 스털링');
INSERT INTO secondarytbl(userID, name) VALUES (26, '리야드 마레즈');
INSERT INTO secondarytbl(userID, name) VALUES (9, '홀란드');
ALTER TABLE secondarytbl
ADD CONSTRAINT UK_secondarytbl_userID
UNIQUE (userID);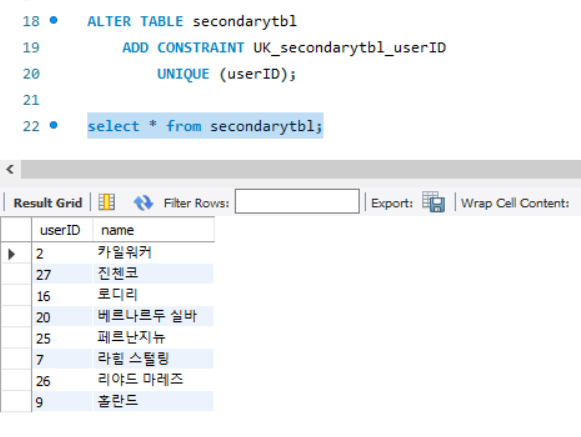
UNIQUE 제약 조건을 주어도, 변하지 않는 것을 알 수 있다.
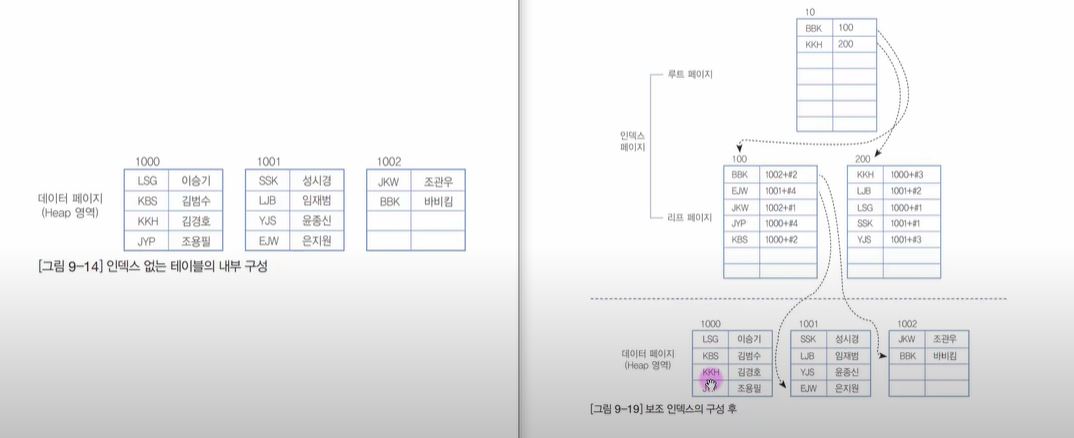
보조 인덱스는 데이터를 그대로 두고, 참고할 인덱스를 만드는 것이다.
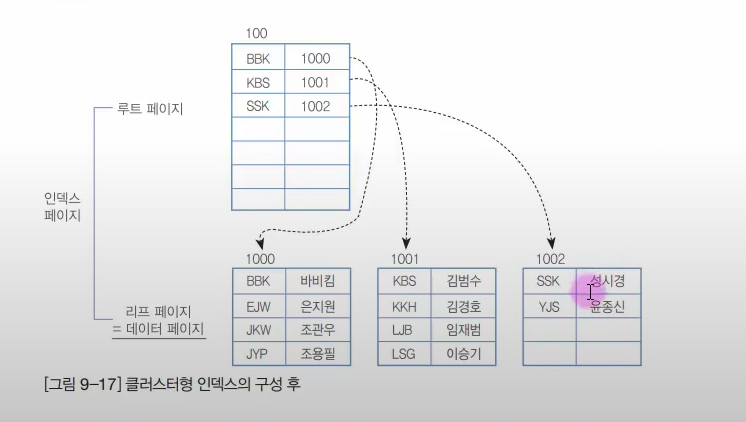
클러스터형 인덱스
-
클러스터형 인덱스 생성 시에는 데이터 페이지 전체가 다시 결정된다.
그러므로 이미 대용량의 데이터가 입력된 상태라면 업무시간에 클러스터형 인덱스를 생성하는 것은 심각한 시스템 부하를 줄 수 있으므로 신중하게 생각해야 한다. -
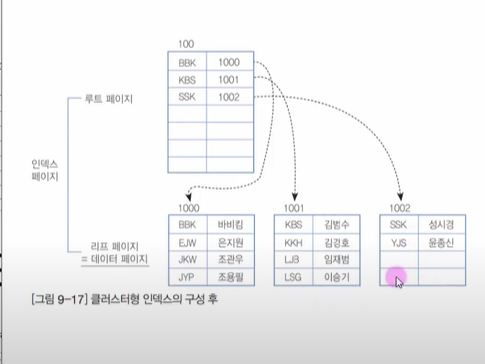
클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터이다. 그러므로, 인덱스 자체에 데이터가 포함되어 있다고 볼 수 있다.
-
클러스터형 인덱스는 성능이 좋지만 테이블에 한 개씩 생성할 수 있다. 그러므로 여러 열에 클러스터형 인덱스를 생성하는지에 따라서 시스템의 성능이 달라 질 수 있다.
그림을 통해 알아보자
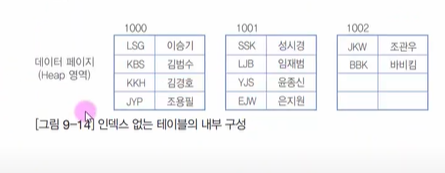
위와 같은 데이터를 클러스텨형 인덱스를 구성하면
보조형 인덱스
- 보조 인덱스의 생성 시 에는 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 보조 인덱스는 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소값(RID)이다. 클러스터형보다 검색 속도는 느리지만, 데이터의 입력/수정/삭제는 덜 느리다.
- 보조 인덱스는 여러개 생성할 수 있다. 하지만 함부로 남용하는 경우는 오히려 시스템 성능을 떨어뜨리는 결과를 초래 할 수 있으므로, 꼭 필요한 열에만 생성하는 것이 좋다.
인덱스의 생성 및 제거
인덱스 생성
CREATE INDEX 인덱스이름
ON 테이블명 (칼럼명);인덱스 확인 방법
SHOW INDEX FROM 테이블명;인덱스 삭제 방법
DROP INDEX 인덱스이름 ON 테이블이름;
그래야만 한다