
데이터베이스에서 인덱스란?
- 데이터베이스에 존재하지 않더라도 지금까지의 데이터를 조회하고 변경하는데 아무런 문제가 되지 않는다. 그럼에도 인덱스 자체는 데이터베이스의 성능에 아주 중요한 역할을 하기 때문에 없어서는 안될 데이터베이스 개체이다.
⚾ 인덱스는 언제 쓰일까
예를 들어, 우주비행사라는 단어를 찾는다고 했을때, 104p까지 찾아야 한다.

하지만, index를 활용하면 찾는 횟수를 줄일 수 있다.
🎈 인덱스 사용의 장점
- 검색 속도가 무척 빨라질 수 있다.
- 그 결과 해당 쿼리의 부하가 줄어들어서, 결국 시스템 전체 성능이 향상된다.
🎈 인덱스 사용의 단점
- 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해지는데, 대략 데이터베이스의 10% 정도의 추가 공간이 필요하다.
- 처음 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터의 변경 작업이 자주 일어날 경우에는 오히려 성능이 나빠질 수 있다.
🧨 인덱스의 종류
🎍 클러스터형 인덱스
- 영어 사전과 같은 책
- 테이블당 한 개만 생성
🎍 보조 인덱스
- 책 뒤에 <찾아보기>와 같은 책
- 테이블당 여러 개
🎁 자동으로 생성된 인덱스
예제1
- 회원 테이블을 생성
DROP DATABASE IF EXISTS sqldb; -- 만약 sqldb가 존재하면 우선 삭제한다.
CREATE DATABASE sqlDB;
CREATE TABLE userTbl -- 회원 테이블
( userID CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
name VARCHAR(10) NOT NULL, -- 이름
birthYear INT NOT NULL, -- 출생년도
addr CHAR(2) NOT NULL,
mobile1 CHAR(3), -- 휴대폰의 국번 (011, 016, 017 ,...)
mobile2 CHAR(8), -- 휴대폰의 나머지 전화번호(하이폰제외)
height SMALLINT, -- 키
mDate DATE -- 회원 가입일
);- 데이터를 넣어보자
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('1111','일일일',1991,'광명','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('KBS','케베스','1878','소하','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('MCM','엠씨엠',2019,'일직','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('SBS','에세베',1098,'일산',NULL,NULL,171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('JTBC','제티비시',2022,'파주','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('TVCHU','티비조선',2020,'춘천','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('MBN','엠비엔',1994,'원주','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('tvn','티비앤',1912,'바다','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('spotv','스포티비',1933,'강릉',NULL,NULL,171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('lulu','룰루',1891,'강북','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('lala','랄라',1911,'강남','010','11111111',171,'2012-01-01');
INSERT INTO usertbl (userID, name, birthYear, addr, mobile1, mobile2, height, mDate) VALUES ('hlelo','안녕',1994,'일직','010','11111111',171,'2012-01-01');
값은 어떤 순서대로 들어갈까?
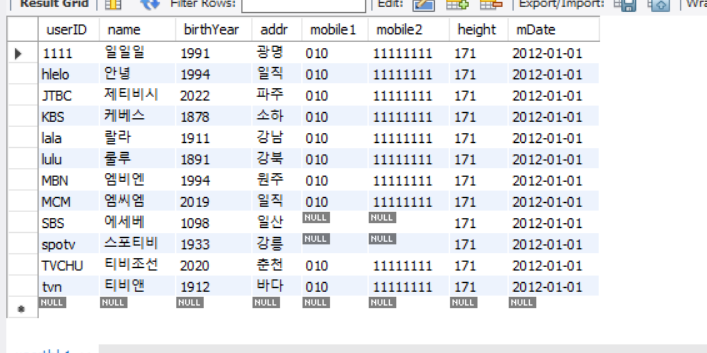
대,소문자를 무시하고 알파벳 순서로 데이터가 들어간 것을 볼 수 있다.
왜그럴까?
그 이유는 userTbl의 userID가 PK로 지정이 되었고, 클러스터형 인덱스로 저장이 되었기 때문이다.
따라서 영어사전순으로 정렬이 된다.
예제2
CREATE DATABASE IF NOT EXISTS testDB;
USE testDB;
DROP TABLE IF EXISTS userTbl;
CREATE TABLE userTbl
(userID char(8) NOT NULL PRIMARY KEY,
name varchar(10) NOT NULL,
birthYear int NOT NULL,
addr nchar(4) NOT NULL
);
INSERT INTO usertbl(userID, name, birthYear, addr) VALUES('herry01', '해리케인', 1990, '영국');
INSERT INTO usertbl(userID, name, birthYear, addr) VALUES('우리흥', '손흥민', 1993, '한국');
INSERT INTO usertbl(userID, name, birthYear, addr) VALUES('우라우라모', '모우라', 1988, '브라질');
INSERT INTO usertbl(userID, name, birthYear, addr) VALUES('철벽수비', '데이비스', 1980, '웨일스');
INSERT INTO usertbl(userID, name, birthYear, addr) VALUES('뚝배기', '핸더슨', 1910, '독일'); 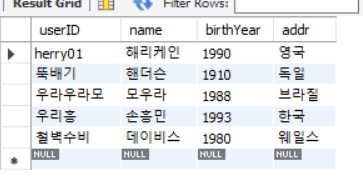
위와 같이 userID를 PK로 지정했기 때문에 userID는 클러스터형 인덱스가 되어서 userID 를 기준으로 사전식으로 정렬이 된다.
⚾ PK를 바꾸어 수정해보자
ALTER TABLE usertbl DROP PRIMARY KEY;- usertbl에서 PRIMARY KEY를 삭제한다.
ALTER TABLE usertbl
ADD CONSTRAINT pk_name PRIMARY KEY(name);
SELECT * FROM userTbl;- PRIMARY KEY 로 지정한 열은 클러스터형 인덱스가 생성된다.
- UNIQUE NOT NULL로 지정한 열은 인덱스가 생성된다.
참고 자료

그래야만 한다