[AI Research review] Language Models Perform Reasoning via Chain of Thought
0
🔗 출처 : https://blog.research.google/2022/05/language-models-perform-reasoning-via.html
-
LLM 모델의 과제 : math word problems과 commonsense reasoning 같은 특정 다단계 추론 어려움 해소
-
"Chain of Thought Prompting Elicits Reasoning in Large Language Models”에서는 언어 모델의 추론 능력을 향상시키기 위한 프롬프트 방법을 제시 ⇒ Chain of Thought Prompting
-
모델이 다단계(muti-step) 문제를 중간 단계로 분해 가능, 충분한 규모(~100B 매개변수)의 언어 모델은 표준 프롬프트 방법으로는 해결할 수 없는 복잡한 추론 문제를 해결
Comparison to Standard Prompting
-
표준 프롬프트를 사용하면 모델에 입력-출력 쌍의 예(질문 및 답변 형식)을 같이 제공하여 예측

-
Chain of Thought Prompting에서 모델은 다단계 문제에 대한 최종 답변을 제공하기 전에 중간 추론 단계를 생성

Arithmetic Reasoning
- 언어 모델이 일반적으로 어려움을 겪는 과제 중 하나는 산술 추론(arithmetic reasoning,수학 단어 문제 해결)
- 산술 추론의 benchmark task: MultiArith, GSM8K
- standard prompting : 모델의 크기를 늘려도 성능이 크게 향상되지 않음
- chain of thought prompting : 모델의 크기를 늘려감에 따라 성능이 대형 모델은 표준 프롬프트 보다는 크게 향상
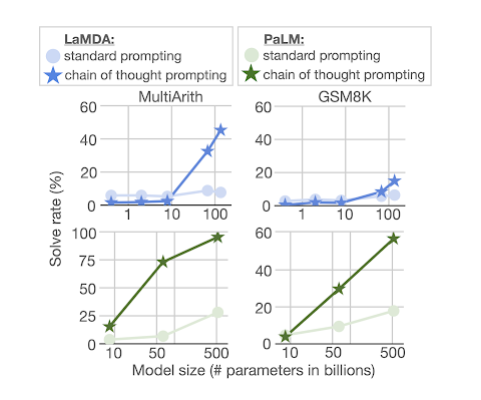
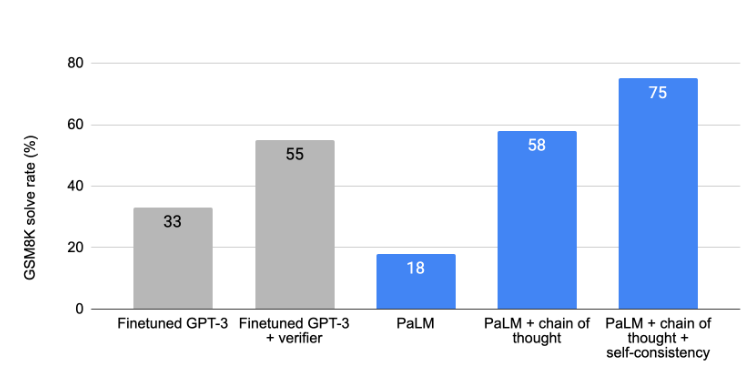
- PaLM(540B parameters) 수학 단어 문제의 GSM8K 데이터세트에서 눈에 띄는 성능을 보여 줌
- PaLM + chain of thought : 58% > Finetuned GPT-3(175B) : 55%
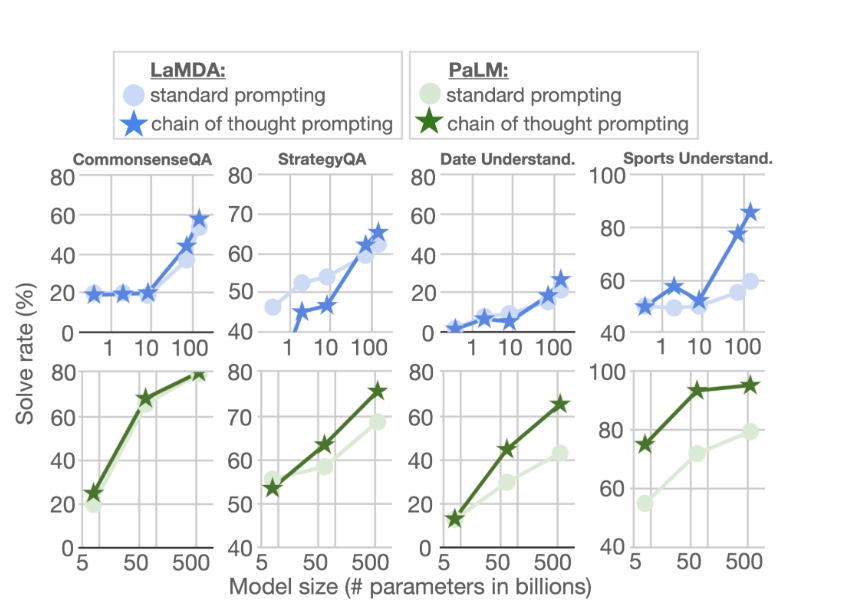
Commonsense Reasoning
- the language-based nature of chain of thought prompting가 물리적, 인간적 상호작용에 대한 추론을 포함하는 상식적 추론에도 적용될 수 있는가?
- benchmark task : CommonsenseQA, StrategyQA, BIG-Bench collaboration(date understanding and sports understanding)

- Chain of thought prompting는 sports understanding에 가장 큰 성능개선 (PaLM 540B는 95%)
- CommonsenseQA, StrategyQA, and Date Understanding에서는 작은 개선
Conclusions
- chain of thought prompting은 추론 작업을 수행하는 언어 모델의 능력을 향상시키기 위한 간단하고 광범위하게 적용가능한 방법

우당탕탕 / 블로그 이사 중