Pytorch Tutorial of CNN Implementation(Fashion MNIST) on Colab
Purpose of Tutorials
- implement linear regression model and check performance
- implement cnn and compare performance with linear model
1. Preprocessing Data
: 학습 할 데이터셋을 구성하고, data loader에 넣어 입력 값을 정의한다.
0) Enable Cuda
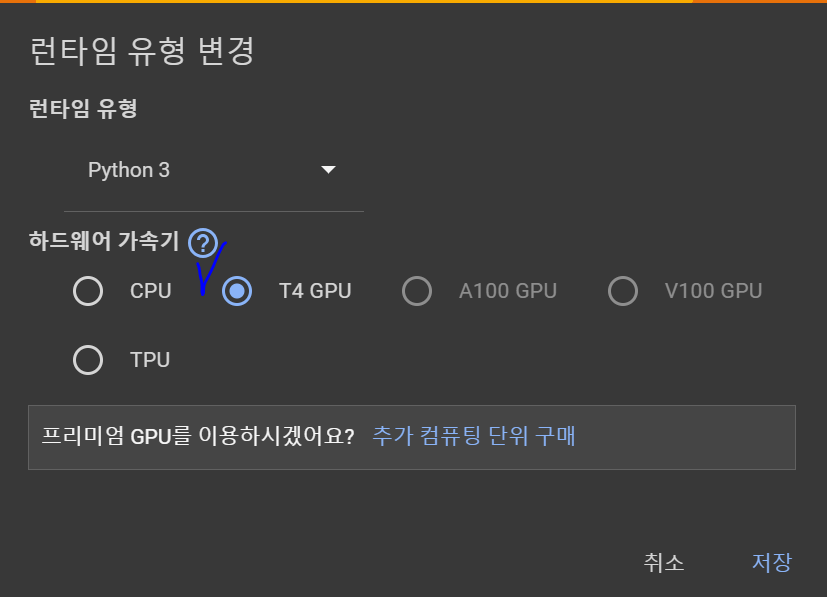
가장 먼저 런타임 환경에 CPU가 아닌 GPU를 사용하도록 변경한다.
1) 라이브러리 임포트
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortorchvision에서 제공하는 dataset을 사용하도록 한다.
2) 데이터셋 다운로드
① 학습 데이터셋 and ② 테스트 데이터셋
# 공개 데이터셋에서 학습 데이터를 내려받습니다.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# 공개 데이터셋에서 테스트 데이터를 내려받습니다.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)3) 데이터로더 생성
학습을 위해 데이터로더를 생성한다.
batch_size = 64
# 데이터로더를 생성합니다.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break2. Define Model
입력 데이터셋과 데이터로더가 준비되었다면, 학습할 모델의 아키텍쳐를 설계하도록 한다.
1) 학습에 사용할 장치 설정
# 학습에 사용할 CPU나 GPU, MPS 장치를 얻습니다.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")2) Linear Regression Model 설계
# 1. Linear Regression
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.flatten = nn.Flatten()
self.linear = nn.Linear(28*28, 10)
def forward(self, x):
x = self.flatten(x)
logits = self.linear(x)
return logits
# 모델 생성 및 디바이스 설정
model = LinearRegressionModel().to(device)
print(model)3) 매개변수 최적화
모델 학습을 위해 필요한 loss function과 optimizer를 정의한다.
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)3. Training
1) 학습 수행
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# 예측 오류 계산
pred = model(X)
loss = loss_fn(pred, y)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")2) 성능 확인
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
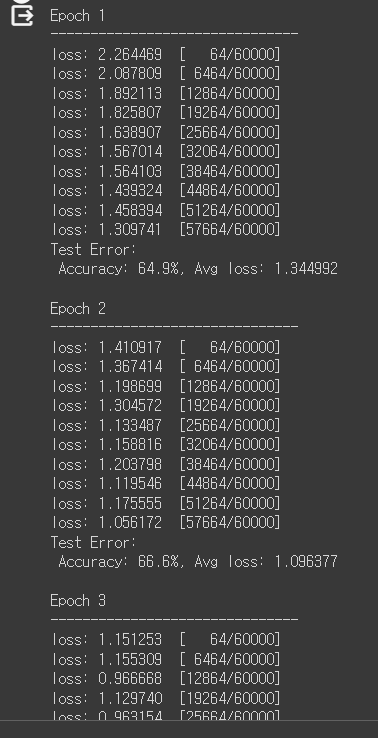
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")학습 단계 마다 오류가 감소하는 것을 확인할 수 있다.
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")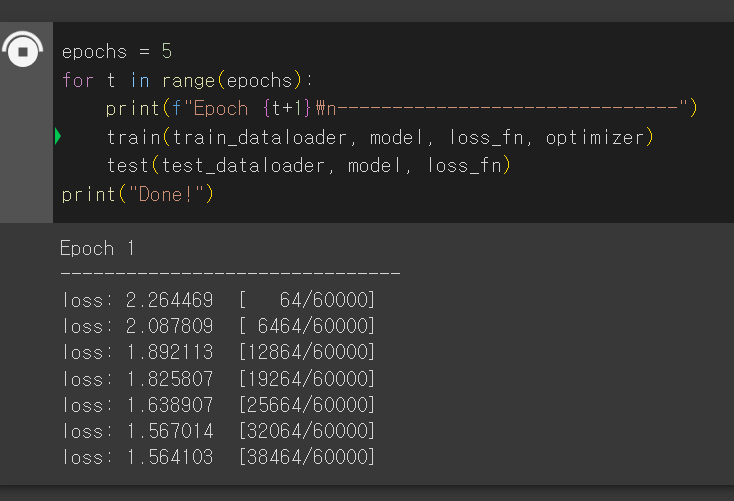
4. 모델 사용하기
학습된 모델을 테스트 데이터셋에 사용하기 위해 모델을 저장하도록 한다.
1) 모델 저장하기
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")2) 모델 불러오기
model = LinearRegressionModel().to(device)
model.load_state_dict(torch.load("model.pth"))모델을 사용해 Classification을 수행해보도록 한다.
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
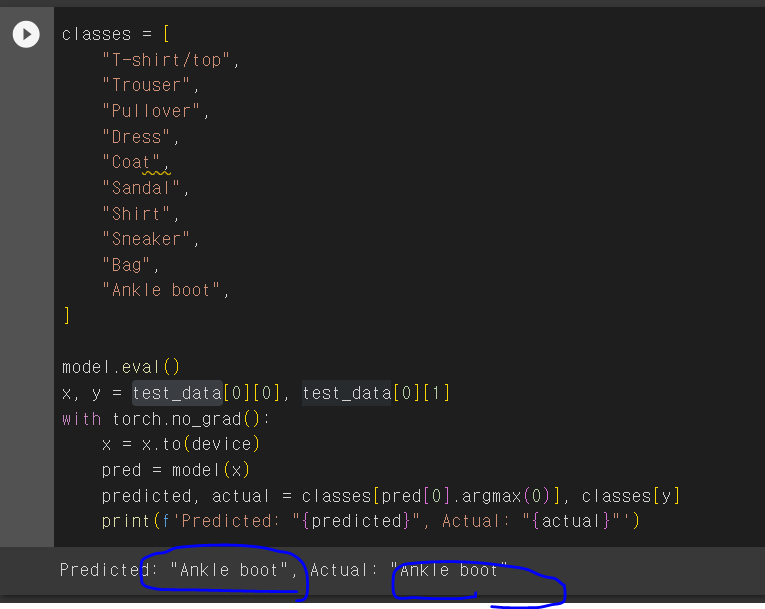
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
x = x.to(device)
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')- 예측 결과
동일한 작언을 CNN모델을 사용해 두 모델의 성능을 비교해보도록 한다.
※ Reference.
https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
