학습 중/후 성능을 향상시키기 위한 여러가지 방법에 대해 살펴보고자 한다.
- During training
- activation func
- data preprocessing
- weigth initialization
- regularization
1. After Training
1) Model ensembles
여러 개의 CNN을 개별로 학습시킨 후 합치는 방식
CNN1 CNN2 CNN3 (각각은 vgg ,alxnet, cnn 등 상이하게 학습시킬 수 있음)
하나의 이미지를 각각 차, 집, 차 로 분류했다면 가장 유력한 결과(차)를 사용한다. 보팅을 하여 (통계학을 사용) 결론을 내는 방식.
=> 확실한 성능 향상
- End-to-End Training
: 병렬로 동시에 학습시킨 후 평균내는 방식
2) Transfer Learning
- 데이터가 부족 시 오버피팅을 방지하고자 사용한다.
① 유사 대량 데이터셋을 사용해 pre-train을 시킨 모델을 사용
② 마지막에 몇 개의 layer를 잘라 낸다.
③ 일부 레이어를 추가한 후 소수의 데이터로 후 학습시킨다.
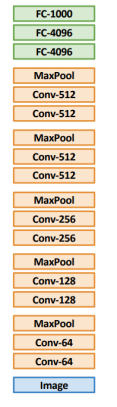
- 상위 레이어에 가까울수록 global한 특징을 추출.
- 하위(초창기) 레이어로 갈수록 디테일한 특징을 추출.
- 대부분 imageNet으로 pre-trained model을 사용해 이미지 학습을 수행 ★
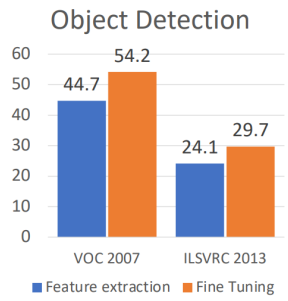
-> 성능 차이는 물론, 점점 복잡해 지는 네트워크에 대해 대량의 데이터를 훈련시키는 대신 transfer learning을 적용하는 것이 일반적
CNN은 함수, F(x)를 만드는 것
2. CNN Applications to CV
1) Image Segmentation(Semantic)
① FCN (Fully Convolutonal Networks)
- 초창기 이미지 세그멘테이션을 위한 모델
- Convolution layer로만 구성된 네트워크 모델
- fully-connected의 경우 연속되는 레이어들의 입출력이 동일해야 한다.
- 반면, Convolution의 경우 입출력 크기가 정해지지 않아도 되며, filter의 크기만 정해져 있다.
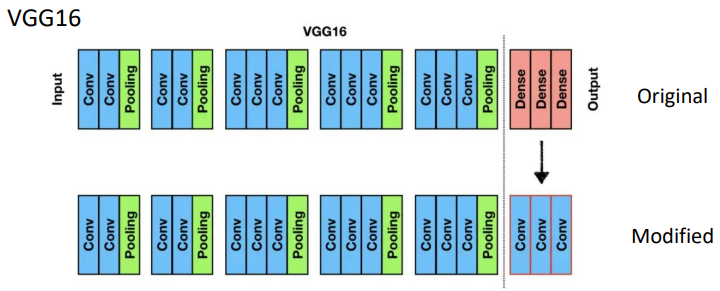
=> dense(Fully connected)를 Conv로 바꾸어 입력 그대로 출력되도록
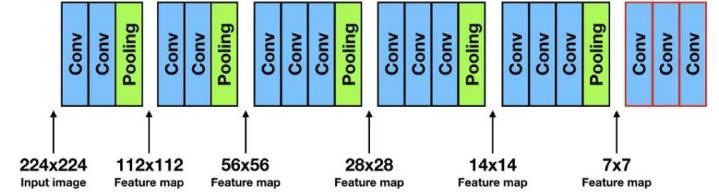
실제로 해보면, Conv와 Pooling의 결과 원본 이미지 대비 작은 크기의 결과물이 생성된다. Pooing으로 인해 사이즈가 절반으로 줄기 때문이다.
따라서 인풋과 동일한 크기의 결과물을 얻기 위해 Upsampling이 필수적이다.
Upsampling methods
• Bilinear Interpolation : 2D 상에서 픽셀(점)의 위치에 따라 가중치값을 곱해주는 방식
• Transposed Convolution
• Etc.
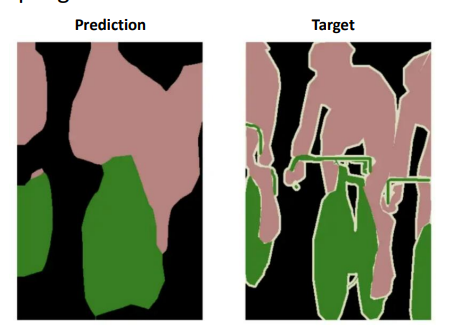
이렇게 반복적으로 upsampling 하게 되면, 마치 그림판으로 확대한것과 같으며 해상도 저하를 보인다.
2) Skip Architecture
상위 레이어에서 Upsampling하는 대신 이전 레이어와 최종 레이어를 합친 후 upsampling을 하게되면 최종 레이어만 upsampling하는 것보다 디테일이 덜 손상된다.
- FCN-8s : 숫자가 작아질수록 디테일이 "추가된"레이어라고 볼 수 있다. (better performance)
Semantic
: 의미론적 접근으로 이미지를 분석하는 방식
3. UNet
better solution for skip architecture is UNet
- Contracing path : VGG based Architecture
- Conv Conv Pooling
- 큰 정보로부터 작은 정보로 추출되는 (정보 압축, global feature)
- Expanding path : transposed convolution
- 원본 이미지와 같은 크기로 사이즈를 키우는 과정 (detail 추가)
pixed-wise softmax : 픽셀마다 cross entropy 계산
4. Object Detection
광범위하게 사용될 수 있는 기술로,
Region Proposal : 후보 영역(patch)를 제공
Classificaiton : 각 후보 패치를 검증 (CNN Classifier, trained)
1) Approach for object detection
-
Naiive
-
Selective Search
한 번 수행될때마다, 비슷한 픽셀끼리 뭉쳐지고, 덩어리와 덩어리끼리 뭉쳐지고,, 이 후 덩어리의 상하좌우 픽셀을 토대로 box를 생성 (점차 box의 개수가 줄어든다)
box에 대해서 classification을 수행

=> box의 개수를 기준으로 어디까지 픽셀들을 뭉칠 지 결정하여야한다.
2) R-CNN
Classifier CNN
1. classification &
2. box 조정
3. Non-max : 겹치는 것들을 제외하고 확률이 가장 높은 것만 남기는 (후보정, post-processing)과정이 필요하다
- 확률이 높은 순서로 정렬,
= 앞에서부터(확률이 높은 것부터) 나머지와 비교(겹치는지)
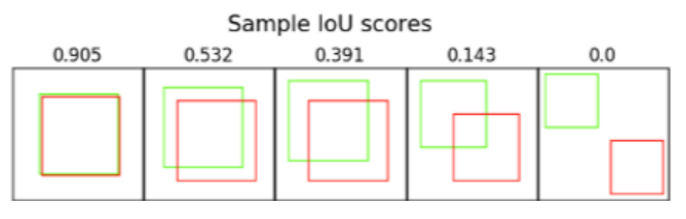
- 이를 비교하기 위해 IoU★를 계산 (교집합/합집합)
- IoU가 일정 기준 이상이면 제외, 즉 removing overlapping boxes
- 계산 비용으로 인해 real time processing에 부하가 올 수 있다.
이를 해결하기 위해 YOLO, Fast R-CNN, Mask R-CNN 등이 존재한다. - 또한, 애초에 overlapping box를 적게하면 computation을 줄일 수 있다. 이를 개선한 모델이 YOLO
