큐
배열로 구현한 큐
- 큐는 스택과 반대로 FIFO(First In First Out)의 원리로 동작하는 자료구조이다.
- 순서대로 처리해야 하는 자료를 임시로 저장하는 용도로 사용된다.
- 고속도로 톨게이트에 줄 서있는 차들의 행렬.
- 큐는 자료가 삽입되는 곳과 삭제되는 곳의 위치가 다르기 때문에 두 개의 포인터를 관리해야 한다.
head
다음 삭제될 위치를 가리킨다. 처리할 자료를 빼내가기만 한다.
tail
다음 삽입될 위치를 가리킨다. 새로 도착하는 자료가 끊임없이 쌓인다.
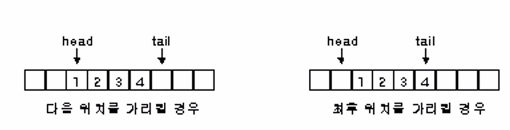
- 큐를 초기화 할 때 최초 head, tail은 모두 배열의 선두인 0을 가리킨다.
- 두 포인터가 같은 위치를 가리키면 대기중인 데이터가 없고 큐가 비어있다는 뜻이다.
- 다음은 다섯 개의 칸을 가진 큐에서 자료가 삽입, 삭제되는 과정이다.
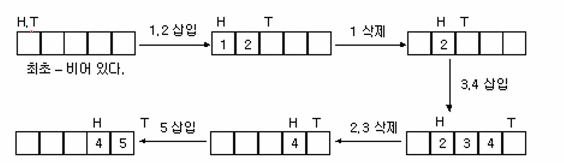
- 이런 식으로 자료를 계속 삽입, 삭제하면 head, tail은 계속 뒤쪽으로 이동하기 때문에 배열의 뒤쪽 공간이 금방 부족해진다.
- 5가 삽입된 후 T는 배열 경계를 넘어서며 이 상태에서는 다음 삽입 동작을 할 수 없다.
- 배열의 크기만큼 자료가 들어 있지 않은데 기억 공간이 부족한 문제가 생긴다.
- 앞쪽에서 먼저 들어왔던 자료들이 삭제되었으므로 공간은 비어있다.
- head의 데이터를 배열 처음으로 보내고 tail의 직전까지 모든 데이터를 앞쪽으로 복사해서 이동시킨다. 포인터도 따라서 이동해야한다.
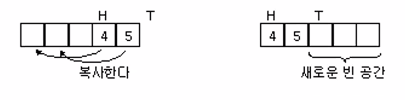
- 이렇게 하면 앞쪽의 남은 공간이 뒤쪽으로 이동하므로 새로운 데이터 삽입이 가능하다.
- 큐가 찰 때마다 이런식으로 매번 복사하는 것은 매우 느리고 비효율적이다.
- 이 방법 대신 배열의 끝에 닿으면 원형으로 연결하는 방법을 사용한다.
#include<stdio.h>
#include <malloc.h>
int* Queue;
int head, tail;
int QSize;
void initQueue(int size)
{
QSize = size;
Queue = (int*)malloc(QSize * sizeof(int));
head = tail = 0;
}
int insert(int data)
{
if ((tail + 1) == head) // 메모리가 꽉 찼다는 의미
{
return 0;
}
Queue[tail] = data;
tail = tail + 1;
return 1;
}
int Delete()
{
int data = Queue[head];
head = head + 1;
return data;
}
void FreeQueue()
{
free(Queue);
}
void main()
{
initQueue(10);
insert(1);
insert(2);
insert(3);
insert(4);
printf("%d\n", Delete());
printf("%d\n", Delete());
printf("%d\n", Delete());
FreeQueue();
}출력결과
1
2
3
연결리스트로 구현한 큐
- 이중 연결 리스트를 사용하여 100개의 자료를 넣었다가 빼보았다.
- 연결 리스트는 데이터 삽입 시 노드를 동적으로 할당해서 뒤에 덧붙여 메모리의 한계까지 큐의 크기를 늘릴 수 있다.
- 큐가 가득차는 오버플로우가 발생하지 않으며 큐의 크기를 미리 정할 필요도 없다.
- 큐를 만들 때 연결리스트가 배열보다는 쓰기 편하다.
- 시스템 전 메모리를 할당하는 것이기 때문에 만약 논리적 에러가 있을 경우 시스템 전 메모리를 다 까먹을 수 있다는 단점이 있다.
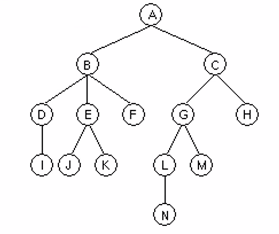
트리
트리의 개념
- 배열, 연결리스트, 스택, 큐 등은 1차원적인 선형구조를 갖는데 비해 트리는 2차원적인 구조를 갖는다.
- 입체적인 트리 구조는 복잡하지만 반면 자료의 삽입, 삭제가 빠르고 효율적이다.
- 트리 구조의 예(토너먼트 대진표, 디렉터리 구조 등)
- 진짜 나무들은 뿌리가 밑에 있고 가지가 위에 있지만 트리를 그릴 때는 루트를 위에 그리고 노드를 아래 쪽에 그린다.
- 노드(Node)와 링크(Link)로 구성된다.
빠른 길을 찾을 때 사용한다.

알고 쓰자!