
우리가 만든 프로젝트 - LEGO2ME Github 주소
AI Application Development by Silicon Valley Engineering with Headstart Silicon Valley
프로그램의 방향성을 잘 알고 하자 🏢
나는 사실 이번 프로그램이 기업과 매칭되어 미국 기업에서 직접 업무를 하고 서비스에 기여를 할 수 있는 프로그램 인 줄 알았다. 그러나 이번 프로그램으 취지는 아래와 같다.
실리콘 밸리에서 일하는 업무문화를 경험하고 풀스택 개발자로서 플랫폼 구축과 관련된 개인 프로젝트 경력을 쌓고자 하는 대학생을 위한 프로젝트 기반 프로그램
기업매칭이 아니였다!😭 실제 회사 업무를 하는건 아니지만 현지 엔지니어와 멘토들과 함께 5주간 프로젝트를 진행한다. 부스트캠프와 비슷한데 여기서 두곽을 나타내는 친구들은 인턴쉽 기회를 얻을 수 있기 때문에 인턴쉽이라는 이름이 붙은 것 같다.
기업에서 실무 경험을 쌓지 못한건 아쉽지만 프로젝트 경험 자체가 적었던 나는 좋은게 좋은거란 마인드로 참여하였다.
우물 안 개구리 🐸

미국 대학생과 서울권 및 수도권 대학교의 학생들과 함께 참여했다. 그리고 오전 세션에는 멘토님들과 네카라쿠배당토 라고 불리는 서비스 기업의 종사하고 계신 분들이 오셔서 강의도 진행을 해주셨다.
세션은 Web, Infra, Backend(Django), Frontend(React) 두루두루 다뤄졌다. 세션의 난이도 자체는 높지 않았다. 나는 리마인드 한다는 편한 마음으로 세션에 참여하였고, 중간중간 내가 알고 있던 개념과 설명해주신 개념이 다를때 확실하게 알고 싶어서 적극적으로 질문을 하였던 것 같다.
하지만 내가 우물 안 개구리라고 느낀건 해외 개발자(FANG)들의 현실과 한국의 취업 시장(네카라쿠배)에서의 수요에서 크게 느꼈다. 나는 해외 취업을 고려하고 있던 터라 한국에서 개발자로 취업해 해외 생계비용과 경력을 쌓은 후 미국이나 호주로 가는 커리어패스를 생각하고 있었다.
하지만 내 예상보다 실리콘벨리의 취업시장은 녹록치 않았고 미국엔 좋은 학교와 천재들이 너무 많았다. 나에게 까지 올 기회는 정말 적었다. 아니 없다고 볼 수 있다. 또한 한국 서비스 기업은 많은 개발자 채용을 진행하고 있지만 그들이 원하는건 주니어 개발자가 아니라 연차가 있고 개발을 잘하는 개발자 였다.
일단 내 커리어패스의 첫 단추가 틀어졌다. 나는 연차도 없고 개발도 잘하지 못하기 때문이다. 이번 프로젝트에서 5주간 프로그램을 짜며 더욱 절실히 느꼈다. 나름 학교에서 다른 친구들보다 조금 더 많은 경험을 했기에 스스로 잘 한다고 생각했던 과거의 내가 너무 부끄러웠다. 아 나는 우물 안 개구리 였구나. 개굴 🐸
세번이나 뒤엎었어요. 🌋
초보 개발자들이 모여서 굴러가는 서비스를 만드는게 꽤나 쉬운 일은 아니였다. 게다가 거기에 AI 모델을 붙여보면 어떨까?
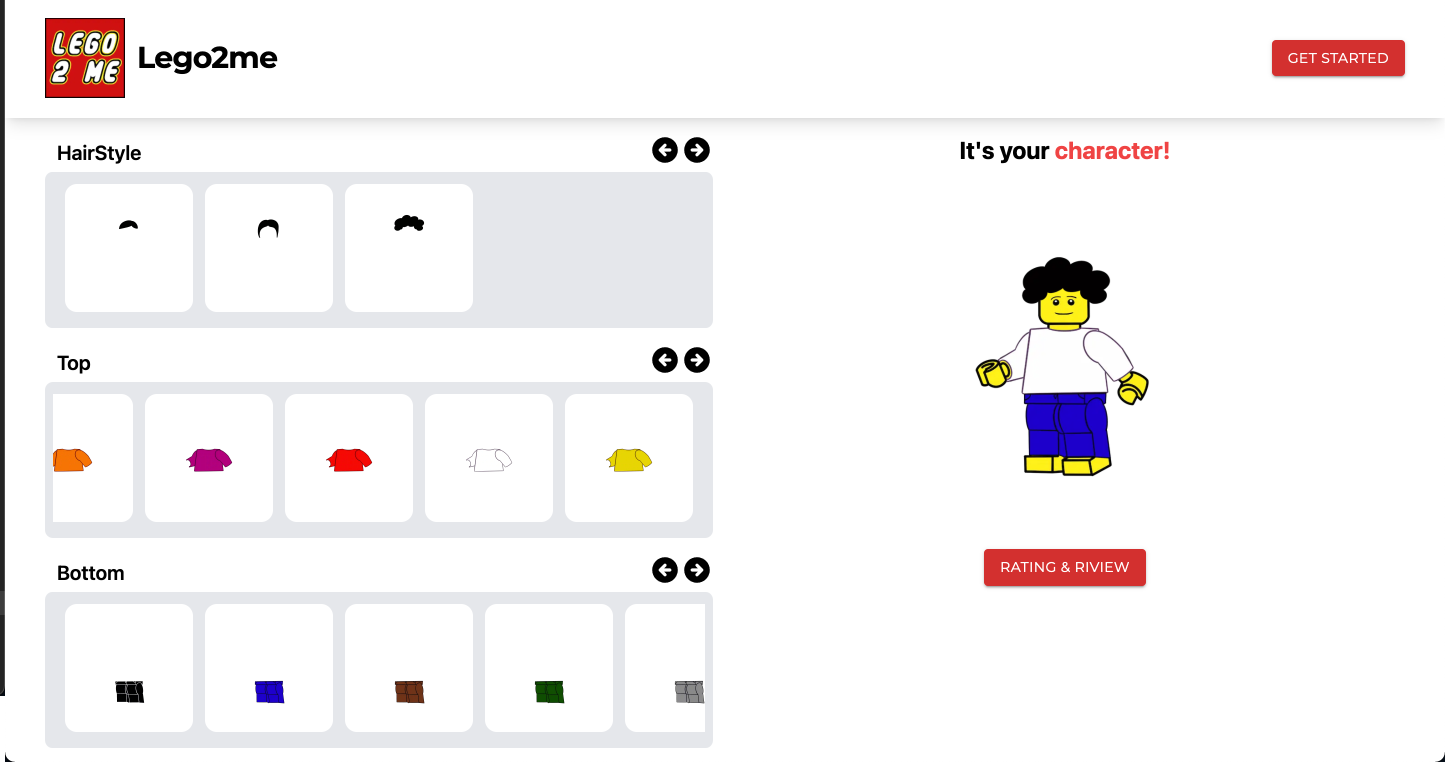
사용자의 이미지를 업로드하면 상의와 하의 정보를 AI 모델이 추출하여 귀여운 레고 케릭터로 변환해주는 웹 서비스

첫번째 AI Model - OpenCV, YOLO
https://github.com/normalclone/fashion-ai-analysis
일단 우리는 모델을 학습 시키는 방향보다는 기존에 존재하는 AI 모델을 가지고와서 flask와 연결하여 API 통신을 할 계획을 했다.
하지만 AI 경험이 없는 우리를 기다리는 가장 큰 문제가 있었으니 그것은 바로 CUDA 였다. 실리콘칩 맥북 세 명과 구닥다리 윈도우 노트북으로 모인 우리팀은 디버깅도 못해보고 있었다. 그래픽 카드의 중요성이 여기서 드러나는구나..
하지만 해결방법은 존재한다.
CUDA를 사용하지 않는 함수로 대체하는 것도 속도가 너무 느렸고 일단 colab을 통해 그래픽카드를 하나 할당해주고 충분히 local 환경에서 테스팅하며 개발을 했다. 그리고 어느정도 우리의 입맛에 맞게 output이 나오면 GPU가 있는 Intance에 올려서 개발을 진행하기로 결정했다.
그러나 다른 문제에 직면했고 해당 모델에서 정확한 데이터 수치를 뽑아내기가 어렵다는 말이였다. 정확히 말하면 훈련데이터의 정확도와 테스트 데이터의 정확도, loss 값과 epoch, 학습률, 혼돈행렬 등의 데이터를 뽑아낼 수 없었다. 우리가 직접 학습시킨 데이터가 아니였고 데이터셋 또한 weight 파일로 제공되었기 원본을 알 수 없었다. 때문에 우리의 입맛에 맞게 학습시키고 디벨롭 시키는데는 한계가 있었다. 그래서 우리는 AI 모델을 변경하기로 했다.
두 번째 AI Model - Google AutoML Vision
쉽게 말해 구글에서 제공하는 머신러닝 모델 만들기 키트이다.
머신러닝에 대한 지식이 부족해도 고품질의 모델을 학습시킬 수 있다는게 엄청난 장점이였다.
또한 AutoML Image를 사용하면 객체감지와 이미지 분류를 통해서 라벨링이 가능했고 REST 및 RPC API 사용,객체와 객체의 위치 및 개수 인식,커스텀 라벨을 사용한 이미지 분류,에지에 ML 모델 배포 등의 장점이 있어 우리가 Flask에 직접 API를 연결하지 않아도 된다는 장점이 있어 개발시간을 줄일 수 있다고 생각했다.
그러나 우리를 기다리는건 놀라운 학습 결과물이였다. 슬랙으로 함께 개발해주시는 분이 급히 새벽에 연락이 왔다.

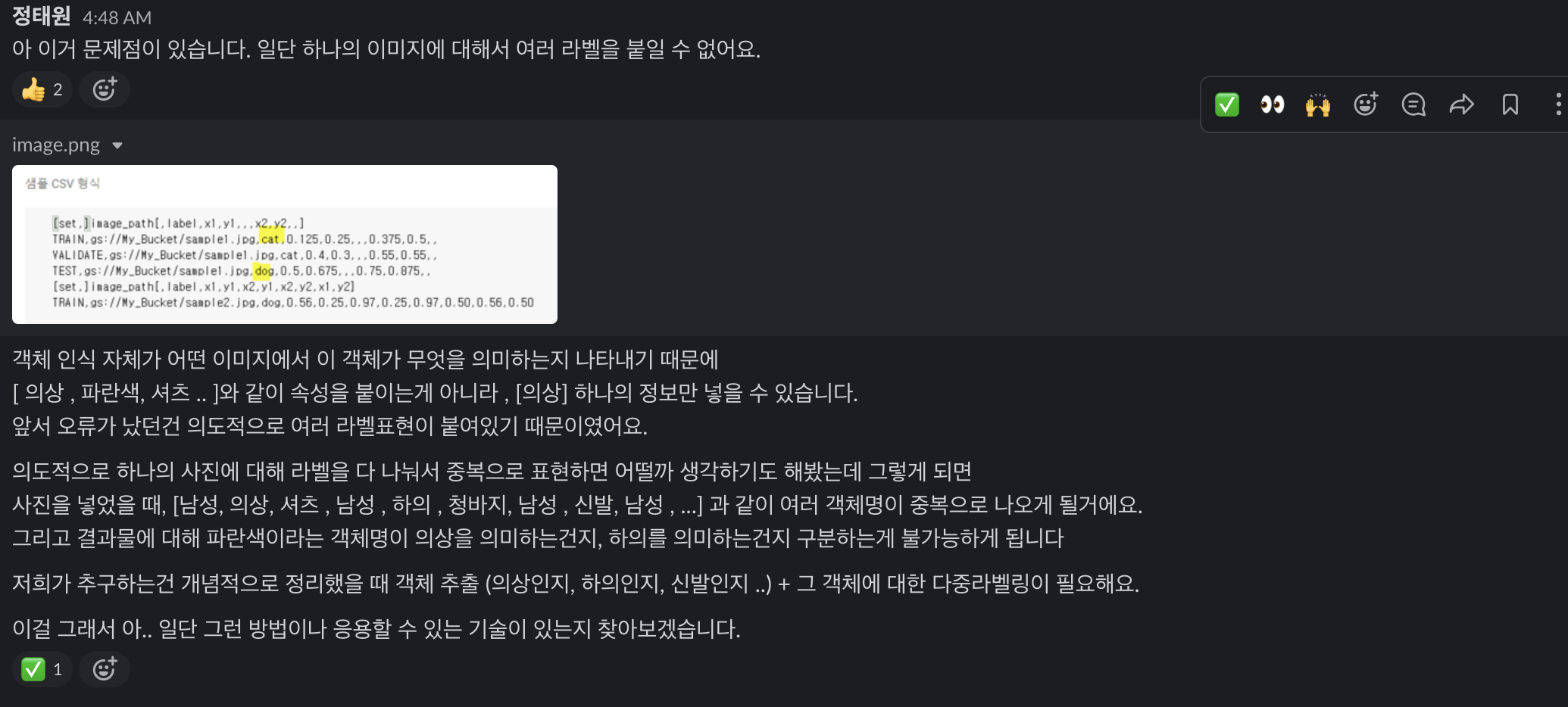
즉 정리하면 우리가 원한건 전신사진 한 장을 넣으면 {성별 : 남성, 상의: 셔츠, 상의 색 : 검정, 하의 : 청바지, 하의색 : 블루} 이렇게 JSON 형식으로 뱉어내기를 원했다. 하지만 의상 하나의 정보만 추출할 수 있다는 문제점이 존재했다!... 오마이갓
그래서 나는 한가지 아이디어를 제안해보았다. 다중 라벨링이 불가능하다면 빨간 상의, 검정 상의, 주황 상의... 아이템 자체를 학습시켜서 Object Detection을 해보는 방향으로 모델을 바꿔보자는 제안이였다. 실로 그럴 듯했다...! 하지만 그 결과는 너무나 처참했다.


문제는 결과에서 바지를 추출하지 못하고 있었다. 학습 데이터가 너무 적은 문제도 있었지만 다중 객체 추출이 안된다는 문제가 존재했다. 하...

진짜 최종 AI Model - Teachable Machine
Teachble Machine With Google이란?
Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding
Teachable Machine은 REST API 지원은 해주고 있지 않지만 웹페이지에서 학습시키면 TensorFlow 모델을 다운로드 받아 우리 아키택처에 붙이면 되기 때문에 너무나 좋았다.
첫번째 AI 모델을 개발하던 방식처럼 안정성을 위해 Flask에 연결하여 Web Applicaiton Server와 REST API 통신하던 방식으로 하고 싶었으나 이 당시 개발 시간이 2주밖에 남지 않아서 WAS 역할을 하는 Django 안에 붙여서 개발을 진행하였다.
하지만 AI는 호락호락한 존재가 아니였다.
-의상이나 하의에 대한 확률이 50:50이 아니라,
AI가 “ 이 사진은 의상 (하의) 이야” 라고 인식하는 경향이 있습니다.
그래서 또 다른 아이디어를 제시해보았다.
상의만 학습하는 모델과 하의만 학습하는 모델 두개를 만들어서 돌려보는건 어떨까요?
사진 처럼 나는 프론트에서 유저가 상의와 하의를 지정하여 모델에 던져주면 모델이 함수처럼 작동하기 때문에 결국 API에 아래와 같이 나올 수 있다는 가능성을 보고 접근하였다.
{
"top" : "WhiteShirts",
"bottom": "BluePants"
}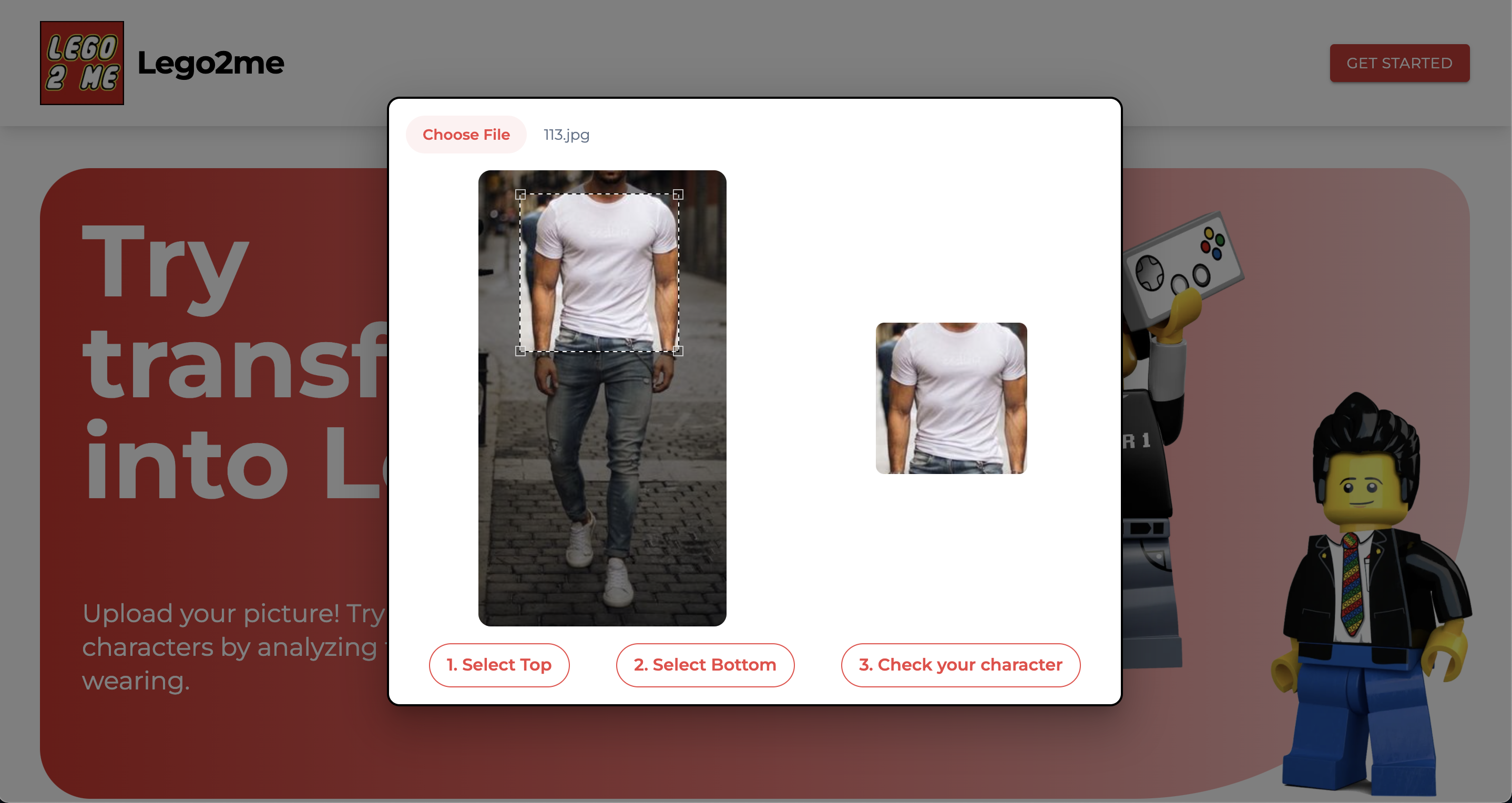
그리고 우리의 아이디어가 맞았고 드디어 우리가 원하는 방향으로 해결하였다!! 각 색상에 맞는 아이템을 학습시켜 나갔다. 중간중간 보라색이 인지되지 못하는 문제는 있었으나 학습데이터를 늘리니 문제가 해결되어갔다.
이후 웹 크롤링 및 Kaggle(캐글)을 통한 이미지를 더 추가하여 부족한 부분의 라벨에 대한 정확도를 높였다.
각 라벨당 130개의 이미지를 넣어 약 2600개의 이미지를 학습데이터로 사용하였다.
그래서 결과는?
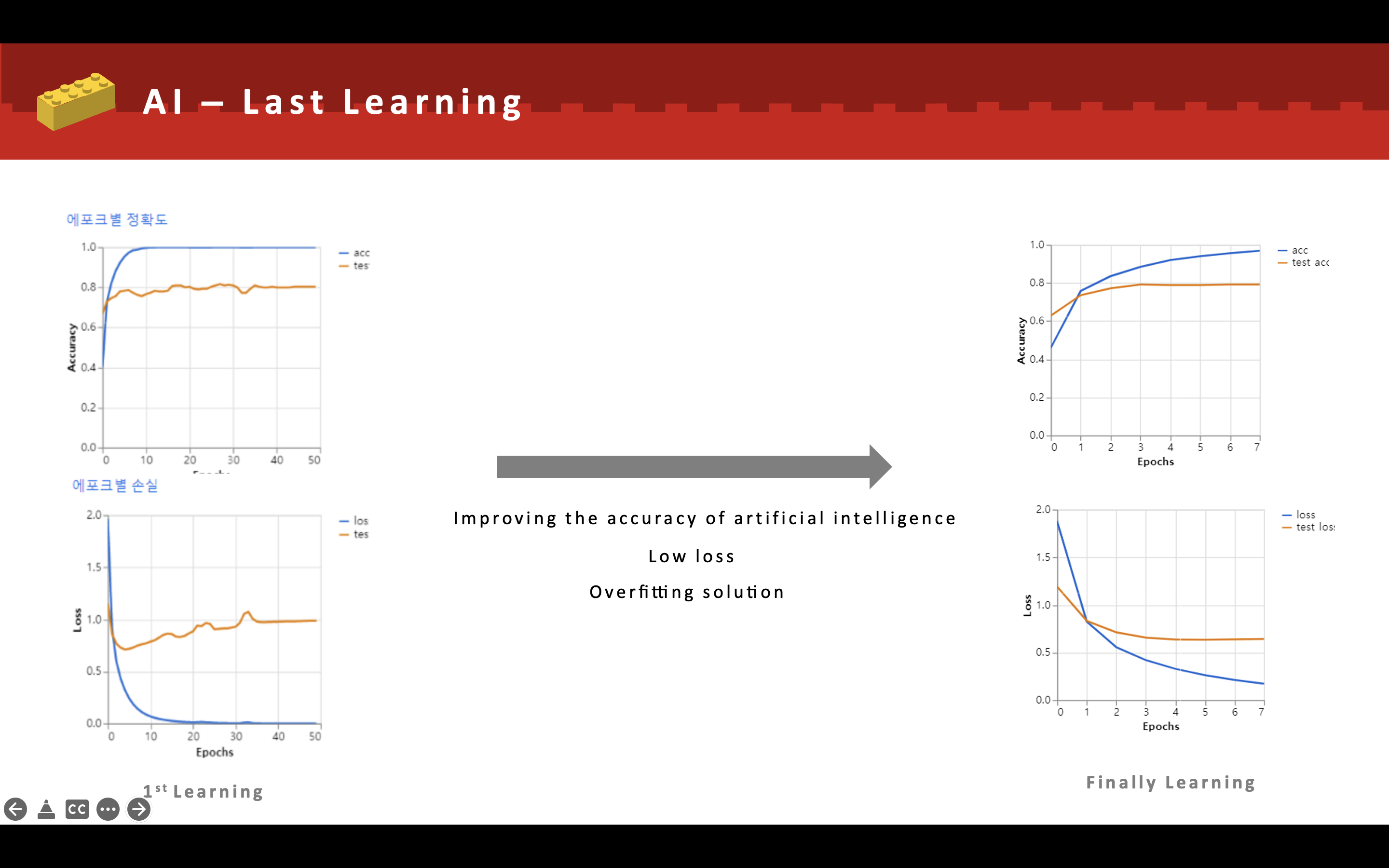
왼쪽은 초기 AI의 모델에 대한 정보이며 오른쪽은 최종 결과물에 따른 AI모델의 에포크 정확도이다.
초반에는 데이터셋도 적고, 과한 에포크수를 통한 학습으로 인해 과적합 문제가 발생하였다.
에포크 수를 낮추고 부족했던 라벨에 대한 이미지를 추가하고 유사성이 떨어지는 이미지를 제거함으로써 전반적인 AI모델의 완성도를 높히고자 했다.
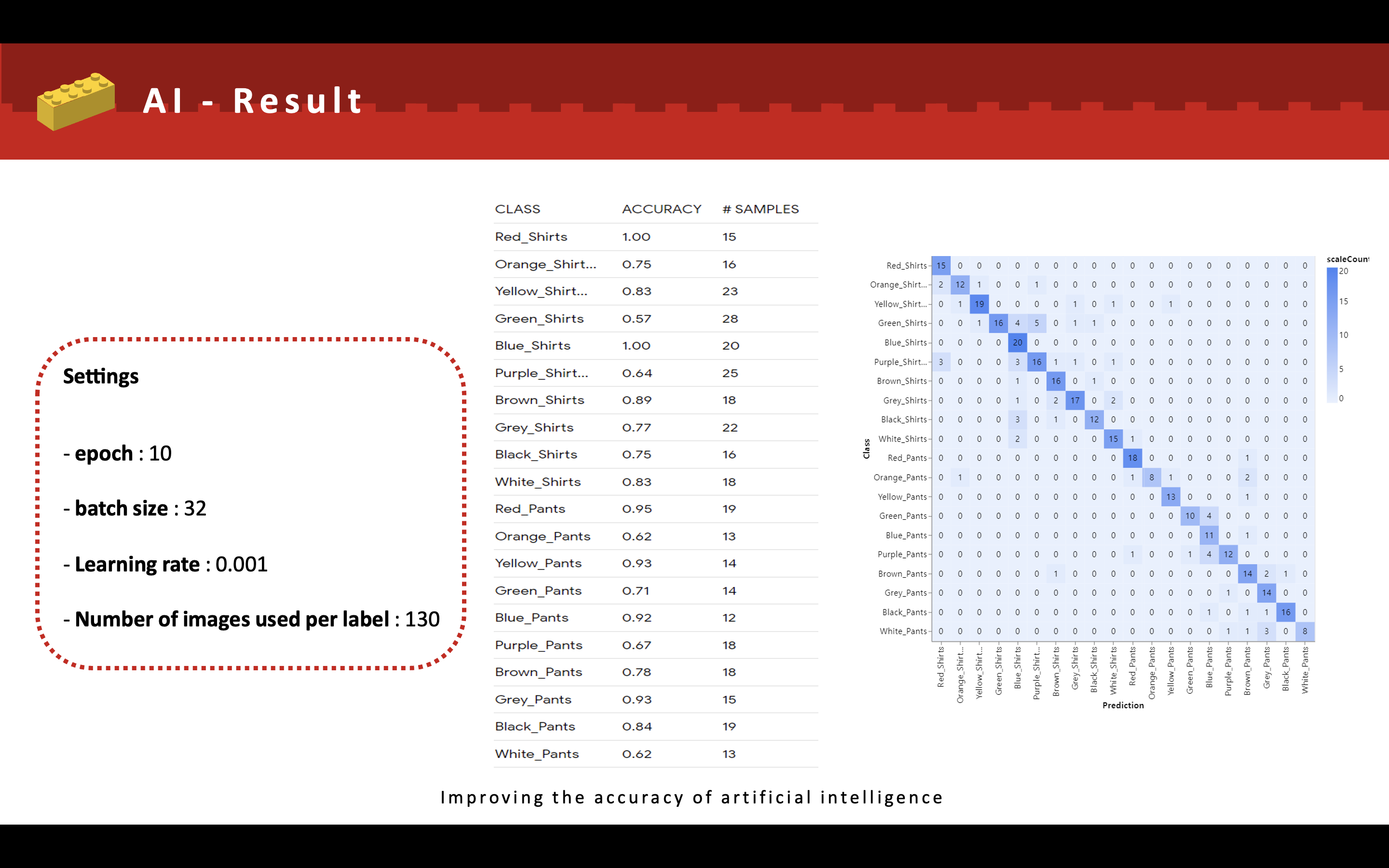
대체적으로 각 라벨당 80%이상의 정확도를 모델을 산출 할 수 있었다.
값진 삽질의 결과물.
마무리하며
사실 이번 인턴쉽 회고를 한 편에 마무리 하려고 했는데 5주의 시간 동안 우리가 정말 많은 것을 경험하였다는 걸 알았다. 그래서 각 파트별로 나눠서 회고를 적어보기로 결정하였다.
AI에 대한 회고는 이렇게 마치고 다음엔 API 통신에 대한 회고를 적어보려고 한다.
