
이번 글에서는 클린 아키텍처를 사용할 때 많이 하는 실수에 대해서 작성해보려고 합니다.
글에 대해서 작성 전 클린 아키텍처에 대해서 간략하게 설명한 후 본격적으로 설명해보겠습니다.
클린 아키텍처의 목적은 바로 관심사를 분리하여 각 클래스가 한가지 역할만을 할 수 있도록 구현하는 것을 의미합니다.
이는 SOLID에서 단일책임원칙인 SRP와도 같은 개념이라 할 수 있습니다.
계층을 통해 관심사를 분리하게 되는 계층 구조에서 외부에서 내부로 의존성을 가지고 있기에 내부로 갈 수록 의존성은 더 낮아지게 됩니다.
간단하게 각 계층의 설명만 하고 본 글을 시작하겠습니다.
UI계층(Presentation Layer)
- 화면의 표시,애니메이션,사용자 입력 처리 등 UI에 관련된 모든 처리
- 뷰 -> 직접적으로 플랫폼 의존적인 구현입니다. 즉 UI 화면 표시와 사용자 입력만을 담당합니다. 여기서 주의할 점은 View가 꼭 Activity/Fragment를 의미하지 않는다는 것입니다.
- Presenter(혹은 viewModel) -> View와는 달리 OS의 렌더링 API 등에 직접적으로 의존하지 않습니다. 뷰 관점의 비즈니스 로직을 담당합니다.
- 가장 하위 계층이라고 할 수 있습니다
Domain 계층
- Usecase -> 도메인 관점의 비즈니스 로직, UI계층에도 비즈니스 로직이 있는데 차이는 다음과 같습니다. 도메인의 비즈니스 로직이라고 하면 개발자가 생각하는 로직이 아닌 기획자나 코드에 대해서 모르고 앱의 사업적 룰을 말합니다.
- 도메인 모델 -> 앱의 논리적인 데이터
- Translater -> 데이터 계층의 엔티티, 도메인 모델을 변환하는 mapper의 역할 (데이터 계층에서 low하게 받아온 데이터들)
Data 계층
- Repository -> Usecase가 필요로 하는 데이터 저장/수정 등의 기능을 제공, 데이터 소스를 인터페이스 형태로 참조하기 때문에 이 클래스에서 데이터 소스 객체를 갈아끼우는 형태로, 외부 API 호출/로컬 DB접근/mock object출력을 전환할 수 있음 (데이터 계층의 인터페이스라고 할 수 있습니다)
- 엔티티(Entity) -> 데이터를 정의한 모델, REST API의 요청/응답을 위한 JSON, 로컬DB에 저장된 테이블을 표현하는 data class 형태가 일반적입니다.
클린아키텍처에 대한 설명은 여기까지 하고 실수들에 대해 작성하겠습니다.
1. Domain 레이어에서의 특정 종속성을 사용하는 경우
바로 예시로 설명하겠습니다.
사용자의 이메일의 유효성을 검사하는 Usecase에 다음과 같은 코드들이 있습니다.
import android.util.Patterns
Class ValidateEmailUseCase(){
fun execute(emial:String): Boolean {
return Patters.EMAIL.ADDRESS.matcher(email),matches()
}
}다음과 같이 패턴 클래스를 통해 결과값을 받아오게 되는데 Patterns가 Android 프레임 워크에서 import되어 가져오게 됩니다. 하지만 도메인 레이어의 사용 목적은 재사용이 가능하고 다른 종속성과 최대한 격리하는 것입니다. 그렇기 때문에 이러한 코드 사용은 잘못된 방법입니다.
위의 코드에서 처럼 Android 클래스에 대한 종속성이 발생하면 위의 재사용과 같은 문제와 함께 발생되는 더 큰 문제가 있습니다. 바로 Unit Test를 하기 어려워지거나 불가능하다는 것입니다.
우선 Android에서는 Local Unit Test와 instrumented Unit Test가 있습니다.
instrumented Unit Test는 에뮬레이터 또는 실제 기기에서 실행을 하여 테스트 하는 것입니다.
왜?? Unit Test가 힘들다라는 거지? 라고 생각하신다면 조금 더 쉽게 설명해드리겠습니다. 위와 같이 Android 종속성이 발생하게 된다면 해당 기능의 경우 APK를 컴파일 해야 동작한다라는 조건이 발생되기 때문입니다. 하지만 Unit Test의 경우 APK를 사용하지 않고 JVM에서 로컬로 실행할 수 있는 즉 테스트 하는데 실제 기기나 에뮬레이터가 필요없는 테스트 방식이라는 것입니다. JVM에서 직접 실행되며 APK 부팅 등을 컴파일할 필요가 없기 때문에 테스트의 속도가 훨씬 더 빠릅니다. 그렇기 때문에 Local Unit Test를 권장하는 것 입니다.
Usecase에서 작성 가능한 코드는 비즈니스 로직만 포함되어야 합니다. 위의 코드로 예를 들면 이메일 유호성을 검사하지만 이메일에서 유호성을 검사하는 개체가 이 Android에서 오는 경우에만 검사가 가능하다는 것입니다. 그렇기 때문에 종속성 제거를 위해 작성하는 도메인 계층의 사용 목적에 위배된다는 것입니다.
위의 문제를 해결하려면 다음과 같이 작성할 수 있습니다. 우선 위의 Patterns를 통해서 email의 유효성을 검사하는 것이 아니라 다른 방법으로 검사해야 한다는 것입니다.
코드로 설명하겠습니다.
fun execute(email: String) : Boolean {
if(email.isBlank()){
return false
}
}다음과 같이 우선 email이 비어있는지 확인을 해줍니다.
Patterns.EMAIL.ADDRESS.matcher(eamil),matchers()와 같은 코드는 이렇게 변경합니다.
// 도메인 레이어
interface EmailPatternValidator {
fun isValidEmail(email:String) : Boolean
}
// 데이터 레이어
// 여기에서 Patterns을 사용합니다.
class AndroidEmailPatternValidator : EmailPattenValidator {
override fun isValidEmail(email: String) : Boolean {
return Patters.EMAIL.ADDRESS.matcher(email),matches()
}
} //원래 코드
class ValidatorEmailUseCase(
private val validator : EmailPatternValidator
){
fun execute(email:String) : Boolean {
if(email.isBlank()){
return false
}
return validator.isValidEmail(email)
}
}이렇게 구현을 하게되면 ValidatorEmailUsecase의 validator는 추상화에 의존하기 때문에 UnitTest를 할 수 있게 되는 것입니다.
다음 2번으로 넘어가겠습니다.
2. 모든 것을 추상화하는 것!!
코드로 설명하겠습니다.
import java.time.LocalDate
data class Book(
val id: String,
val title: String,
val releaseDate: LocalDate
)책의 id,제목,출시날짜가 포함된 책 데이터 클래스가 있습니다. 그런 다음 Repository에서는 API 통신을 통해 등록된 책들의 데이터를 가져올 수 있고 Book Mapper를 통해 책 dto를 가져와 각각 매핑해줍니다. 이러한 방식은 일반적으로 많이 사용하는 방식입니다.
class BookMapperImpl: BookMapper {
override fun toBook(bookDto: BookDto): Book {
return Book(
id =bookDto.id,
title = bookDto.title,
releaseDate = LocalDate.parse(bookDto.reaseDate)
)
}
override fun toBookDto(book: Book): BookDto {
return BookDto (
id = book.id,
title = book.title,
releaseDate = book.releaseDate.toString()
)
}
}
위의 코드처럼 말입니다. 위 코드를 보면 책을 반환하고 dto를 반환합니다. 여기서 어떤 부분이 잘못되었을까요?
2번의 제목처럼 불필요한 추상화이기 때문입니다. 이러한 추상화는 추상화를 하는 이점이 없습니다. 다중 implementations을 가지고 있는 경우이며 하나의 implementation만 구현하지 않는 이상 이러한 추상화 방식은 잘못되었다고 할 수 있습니다.
1번의 경우 Patterns를 통해 email에 대한 유호성을 검사하기 때문에 추가적인 구현을 통해 테스트가 용이할 수 있게되는 이점을 얻었지만 2번의 Mapper의 경우에는 매핑 논리가 항상 동일하기 때문에 일종의 잘못된 매퍼 시나리오 탐지를 위한 테스트가 필요없습니다. 값을 단순히 끼워넣어주는 동작만을 하기 때문에 별도의 테스트가 필요없는 것이죠
위의 처럼 코드를 구현하는 것보다는 Kotlin 확장 함수로 만들어 다음과 같이 동작하게 해주면 됩니다.
BookDto.toBook(): Book {
return Book(
id =bookDto.id,
title = bookDto.title,
releaseDate = LocalDate.parse(bookDto.reaseDate)
)
}추상화가 필요하지 않은 유스케이스도 마찬가지 입니다. 유스케이스 로직을 인터페이스나 추상 클래스 뒤에 둘 필요가 없습니다. 유스케이스에는 비즈니스만 포함되기 때문에 그렇게 구현할 이유가 없기 때문입니다.
3. Package
위에서 3개의 Layer를 다시 적어보면 이렇게 입니다.
data, domain, presentation
Presentation에는 모든 UI 클래스, domain에는 모든 비즈니스 로직 클래스, data에는 데이터 관련 클래스를 일반적으로 넣습니다.
이러한 부분은 잘못되었다라고 하기 보다는 보기에!
불편할 수 있습니다.
이러한 패키지 접근 방식은 애플리케이션이 확장되는 경우 확장 되지 않는다는 것입니다. 대규모 애플리케이션을 계획하는 경우 클린 아키텍처만 사용하게 되면 앱은 항상 이 3개의 루트 모듈 또는 루트 패키지를 갖게 됩니다. 모든 클래스가 이것들에 들어가야 한다면 결국 방대해지게 되고 추후 리팩토링 및 이슈 처리 시 문제가 되는 클래스 파악에 오랜 시간이 걸리게 되는 문제가 발생할 수 있습니다.
그렇기 때문에 기능에 대해 패키징하여 이러한 문제를 해결할 수 있습니다.
SNS 앱의 경우 기능에 대해 나열해보면 이러한 기능들이 있을 것입니다. -> Login, Auth, feed, feedDetail 등과 같이 말입니다. 이러한 기능을 바탕으로 패키징하는 것 입니다.
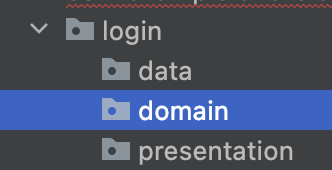{kind=link}
login이라는 package 아래에 data,domain,presentation이렇게 나눠져 있으면 코드의 변경 및 확인할 때 수월해질 수 있습니다.
하지만 프로젝트의 규모가 작거나 다른 팀원과의 명확한 규칙 및 멀티 부분에 익숙하지 않다면 오히려 파악하기 힘들어질 수도 있으니 신중하게 고민 후 사용해야할 방법이라고 생각이 듭니다.
긴글을 읽어주셔서 감사합니다.
