
Kubecon Overview
이번에 기회가 되서 스페인 발렌시아에서 진행된 kubecon 2022에 참석하게 되었습니다. 아직 쿠버네티스를 공부한지 얼마되지 않아 이해못한 세션들이 너무 많아서 아쉬었습니다. 그래도 미처 알지 못한 다양한 오픈소스 프로젝트를 알게 되었고, 프로젝트 개발자와 얘기해보면서 많이 자극받았습니다. 당분간 kubecon에서 얻은 정보를 정리할 예정이고, 가능하다면 오픈소스 프로젝트에도 참여 해보려 합니다.
kubecon에 있는 동안에 공통적으로 자주 언급되는 기술 스택과 느낀점에 대해 정리해보았습니다.
Kubernets CRD & Operator
문제 해결 과정에서 CRD & Operator를 사용했다는 얘기를 여러 세션들에서 많이 들었고, 특히 쿠버네티스에서 데이터베이스를 사용할 때 가장 많이 들었습니다. 예를 들어 postgreSQL의 CloudNativePG, cassandra의 k8ssandra, kafka의 strimzi-kafka-operator가 있습니다. 쿠버네티스 특성 상 stateful한 workload를 운영하기에 적합하지 않았지만, 쿠버네티스에 Operator가 생긴 이후엔 좋은 Operator가 있으면 오히려 데이터베이스의 단점을 쿠버네티스가 보완하여 더 큰 시너지 효과를 발휘할 수 있다고 말합니다. 데이터베이스와 Operator를 같이 사용하면 크게 2가지 장점이 있습니다.
첫 번째는 데이터베이스 설치 및 관리가 용이합니다. 데이터베이스 관련 설정들을 yaml에 쉽게 할 수 있으며, 설치하는 것도 시스템 환경에 상관없이 쿠버네티스에 CR을 배포하면 됩니다. 그리고 버전 업그레이드 등 수정 사항이 생겼을 때도 쉽게 적용할 수 있습니다.
두 번째는 Failover(장애 극복)입니다. 어떤 이유로든 불시에 데이터베이스 서버가 다운될 수 있으며, 이를 빨리 복구하지 않으면 Operator로 배포하면 서버가 다운됐을 때 재시작하고 데이터 복구를 자동화할 수 있습니다. 특히 HA 클러스터 형태로 배포하는 데이터베이스에는 더욱더 빛을 발합니다. 클러스터를 구성하는 서버 하나가 다운되고 재시작 됐을 때 자동으로 클러스터에 조인하거나 해당 서버의 역할(e.g. primary and standby in postgresql)을 다시 정하는 등의 필요한 작업들을 자동화할 수 있습니다.
데이터베이스 이외에도(e.g. storage) 다양한 상황에서 Operator를 많이 사용합니다. 앞으로 쿠버네티스에서 데이터베이스를 사용할 때 최대한 Operator를 사용하는 방향으로 가보는게 좋을 것 같아보이고, Operator를 많이 쓰는 만큼 Operator 관리에도 신경을 많이 쓰게 될 수 있습니다. Operator Lifecycle Management(OLM) 이라는 툴로 Operator를 관리할 수 있습니다만, 나중에 따로 정리할 예정입니다.
Linkerd > Istio ?!
이번 kubecon에서 프로젝트의 tech stack이나 service mesh관련 발표에서 거의 대부분 Linkderd를 사용하고 있다는 내용이었습니다. 이제 Istio 대신에 Linkerd가 Service Mesh의 트랜드로 자리 잡히는 느낌이 들었고 그래서 Linkerd에 대해, 그리고 Linkerd가 Istio보다 어떤 점에서 차별점이 있는지 조사하였습니다.
Service Mesh란?
서비스들 사이의 트래픽 추적, mTLS, 네트워크 정책 등을 정의할 수 있도록 추상화하여 MSA가 적용된 시스템에 안정성, 신뢰성, 가시성 등을 확보하는 Infrastructure Layer입니다. 이 개념은 쿠버네티스를 위한 것이 아닌 그 이전부터 있었고, MSA가 활발하게 퍼지게 되면서 자연스럽게 떠오른 개념입니다.
수많은 어플리케이션들이 생기고 사라지기를 반복하기 때문에 운영, 관리 그리고 모니터링 측면에서 제한이 많았고 이를 해결하기 위한 것이 Service Mesh입니다. 그래서 여러 기능을 요구하고 있는데, 대표적으로 Service Discovery, LoadBalancing, mTLS, metric 수집 등이 있습니다.
보통 Service Mesh는 사이드카 패턴으로 구현되어 있습니다. 모든 어플리케이션 프로세스(혹은 컨테이너)에 경량화된 proxy들이 배치되는 패턴으로, 모든 트래픽이 proxy를 거쳐가게 함으로써 서비스들 사이의 트래픽을 제어, 관리, 모니터링을 하는 것입니다.
대표적인 프로젝트로 Istio와 Linkerd가 있습니다.
The Service Mesh: What Every Engineer Needs to Know about the World's Most Over-Hyped Technology
Linkerd
Kubernetes Service Mesh를 구현한 오픈소스 프로젝트입니다. Istio와 양대산맥을 이루고 있는 아주 큰 프로젝트입니다. Linkerd는 Service Mesh로써 갖추고 있어야할 기능들이 있습니다만, 범용이 아닌 쿠버네티스를 위한 Service Mesh라는 특징이 있습니다.
Linkerd vs Istio
Linkerd는 쿠버네티스를 위한 Service Mesh인데 반해 Istio는 범용 Service Mesh 입니다. 그렇기 때문에 Linkerd가 Istio에 비해 훨씬 간단하고 가볍다고 합니다. 둘 다 Service Mesh로써의 기능은 잘 지원하고 있기 때문에, 어떤 점에서 간단하고 가벼운지에 초점을 두고 비교해봤습니다.
- Proxy
Linkerd와 Istio 둘 다 사이드카 프록시가 배치됩니다. 하지만 Linkerd는 linkerd2-proxy라는 rust로 구현된 자체 프록시를 사용하고, Istio는 C++로 구현된 Envoy 프록시를 사용합니다. linkerd2-proxy는 쿠버네티스와 같은 컨테이너 환경의 리눅스에서 사용하기 위해 만들어졌기 때문에 매우 가볍습니다. 반면에 envoy는 Lyft라는 회사에서 만들어졌으며, 범용적으로 쓰기 위한 프록시이기 때문에 linkerd2-proxy에 비해 훨씬 다양한 기능을 제공하지만 동시에 훨씬 복잡하고 무겁습니다. Linkerd에는 없는 기능으로는 대표적으로 Circuit Breaker가 있습니다.
- Performance
Service Mesh의 모든 활동은 Data Plane에서 일어나기 때문에 결국엔 Proxy의 성능 차이가 Linkerd와 Istio의 성능 차이를 가져옵니다. 애초에 linkerd2-proxy는 쿠버네티스를 위해 만들어 졌고 envoy는 범용성을 고려해서 만들어졌다는 것에서부터 성능 차이가 날 수밖에 없습니다. Linkerd에서 Istio와 벤치마크 테스트를 했었고 Latency와 Resource Consumption에서 엄청난 차이가 있었습니다. 벤치마크에 대한 자세한 정보는 여기를 참조.
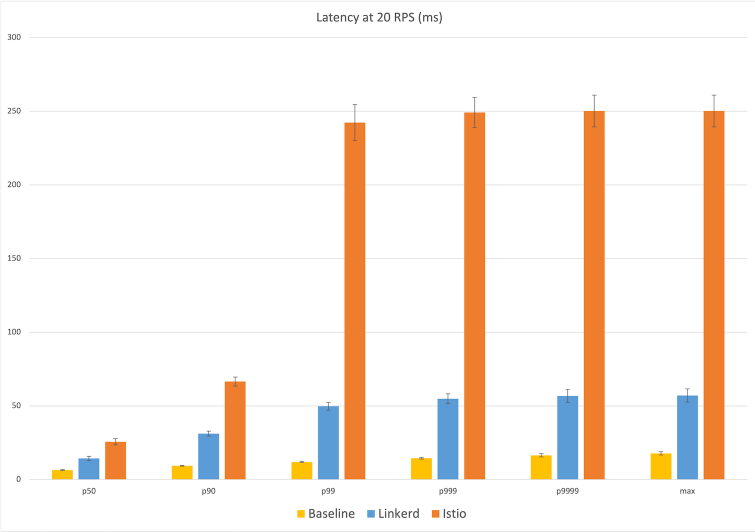

결론
성능 중심으로 비교했기 때문에 Linkerd가 압도적으로 좋게 보일 것이고, 실제로 이것 때문에 많은 기업과 프로젝트에서 Linkerd를 사용하고 있습니다. 하지만 빠르고, 가볍고, 간단한 service mesh를 원하면 Linkerd가, 트래픽 관련해서 좀 더 풍성한 기능을 원하면 Istio가 훨씬 더 적합할 겁니다. 따라서 본인이 Service Mesh를 어떤 목적으로 사용할 지에 따라 정하는 것이 가장 좋은 선택이라고 생각합니다.
Chaos Engineering
Chaos Engineering의 중요성에 대해 다룬 세션들을 몇 개 들었었고, 여러 프로젝트에서 자세히 다루진 않았지만 "자기들은 chaos engineering 툴로 어떤 것을 쓴다" 라는 말을 꽤 많이 들었습니다. 예전에 chaos engineering을 시도했었기 때문에 이번 기회로 리서치를 더 하고, 툴 숙련도를 올려 chaos engineering을 본격적으로 사용해보는 것이 좋다고 생각했습니다.
Chaos Engineering이란
클라우드 환경에 배포된 MSA 어플리케이션에 예기치 못한 상황을 부여하여, 시스템이 이러한 상황에 어떻게 동작하는지 미리 학습하여 실제 서비스를 운영할 때의 사전 예방 및 빠른 대처를 하기 위한 작업입니다. 어떻게 보면 저희가 해왔던 Testing과 큰 차이가 없어보이지만, 가장 큰 차이점은 Testing은 예상 가능한 범주 내에서 어플리케이션들의 동작 및 상호작용 여부를 테스트하는 것이고, Chaos Engineering은 전혀 예측하지 못한 상황, 그리고 어플리케이션의 테스트 뿐만 아니라, 네트워크 Failure와 Latency 등 클라우드에서 발생할 수 있는 상황들까지 고려한다는 것입니다.
결국 안정성과 신뢰성을 확보한 서비스를 클라우드 환경에서 운영하려면, Chaos Engineering은 꼭 필요한 작업입니다.
Chaos-Mesh
잠시 사용했었던 CNCF Incubating 프로젝트입니다. UI도 제공하고 있고 CRD도 제공하고 있어 간단하고 쉽게 chaos engineering을 할 수 있습니다. 하지만 조금 아쉬운 부분은 제공하고 있는 장애 종류가 적었습니다. 그래도 버전이 업그레이드 되면서 장애 종류가 하나씩 생기고 있고, UI도 점차 발전하고 있습니다. 아래 링크에서 katacoda로 튜토리얼을 해볼 수 있습니다.
Interactive Tutorial | Chaos Mesh
Litmus
chaos-mesh와 마찬가지로 chaos engineering을 위한 오픈소스 툴입니다. 다양한 장애, 모니터링, 결과 분석 등 사용자 경험 면에서 chaos-mesh에 비해 훨씬 풍부한 기능을 제공하고 있으며, 제가 느꼈던 litmus의 가장 큰 장점은 ChaosHub입니다. ChaosHub에서 mysql과 같은 어플리케이션 개발자들과 벤더 회사들이 미리 정의한 장애들을 다운받아서 사용해볼 수 있습니다. 이것만 해도 엄청 다양한 장애들을 시도해볼 수 있으며, 내가 직접 장애를 만들어 볼 수도 있습니다. 잘 쓰면 매우 좋은 툴인 것 같아, 나중에 따로 정리할 예정입니다.
