데이터베이스 정규화
데이터베이스 정규화는 관계형 데이터베이스 데이터 모델의 중복을 최소화하고 데이터의 일관성, 유연성을 확보하기 위한 목적으로 데이터를 분해하는 과정을 뜻합니다. 일반적으로 크고 제대로 조직되지 않은 테이블들을 잘 조직된 여러 개의 테이블을 나누는 과정이라고 생각하시면 이해가 쉬울 듯합니다. 이렇게 정규화를 하는 목적은 데이터들을 조금 더 효율적으로 관리하는 것에 그 목적이 있습니다.
- 불필요하거나 중복되는 데이터(data redundancy)들을 제거한다.
- 이상현상(Anomly)을 방지한다.
- 데이터 저장을 "논리적으로" 한다.
데이터를 효율적으로 관리하기 위해서는 위의 3가지를 고려하여 데이터모델을 재설계해야 합니다. 이렇게 정규화를 수행하면 비즈니스 로직에 변화가 생기더라도 데이터 모델의 변경을 최소화할 수 있습니다.
이상현상이란?
이상현상(Anomaly)의 종류
- 삭제 이상 :
데이터 삭제 시 의도와는 상관없이 다른 정보까지 연쇄적으로 삭제되는 현상 - 삽입 이상 :
데이터 삽입 시 의도와는 상관없이 원하지 않는 값들도 함께 삽입되는 현상 - 수정 이상 :
데이터 수정 시 의도와는 상관없이 데이터의 일부만 수정되어 일어나는 데이터 불일치 현상
 이와 같은 경우, 새로운 학생이 한명 추가될 때 필요한 학과코드가 없다면 임의의 값을 넣어줘야 합니다.
이와 같은 경우, 새로운 학생이 한명 추가될 때 필요한 학과코드가 없다면 임의의 값을 넣어줘야 합니다.
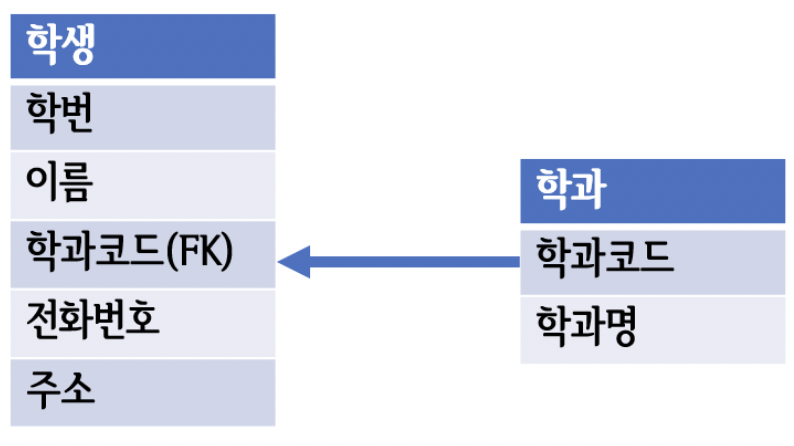 이러한 현상을 해결하기 위해서는 정규화를 수행하여 위와 같이 학생과, 학과 테이블을 나뉘어 관리해주어야 합니다.
이러한 현상을 해결하기 위해서는 정규화를 수행하여 위와 같이 학생과, 학과 테이블을 나뉘어 관리해주어야 합니다. 
Django Fullstack 🍕