
ROUGE 성능지표란
- Recall-Oriented Understudy for Gisting Evaluation 의 준말
- 텍스트 요약 모델의 성능 평가 지표
- 텍스트 자동 요약, 기계 번역 등 자연어 생성 모델의 성능을 평가하기 위한 지표
- 모델이 생성한 요약본 혹은 번역본을 사람이 미리 만들어 놓은 참조본과 대조해 성능 점수를 계산
예시를 들어 살펴보면,
시스템 요약 : the cat was found under the bed
라는 모델이 생성한 요약이 있고
참조 요약(Gold standard, reference summary) : the cat was under the bed
라는 사람이 직접 한 요약 문장이 있을 때
모델의 성능 평가를 위해 개별 단어에 집중한다는 가정 하에 두 문장의 겹치는 단어는
the, cat, was, under, the, bed 이렇게 총 6개이다.
그러나 이 숫자만 가지고 성능지표로 사용하기에는 부족하기 때문에 정량적 지표로 사용할 수 있는 값을 위해 이 숫자를 이용해 recall 과 precision을 계산해야 한다.
ROUGE 에서 Recall 과 Precision
- Recall : Gold standard을 구성하는 단어 중 몇 개의 단어가 시스템 요약의 단어들과 겹치는지
unigram을 하나의 단어로 사용한다고 하면 아래의 사진 같이 구할 수 있다.
위의 예시에서 계산해보면 6/6 = 1.0 이다.
이 점수가 뜻하는 것은 gold standard 내 모든 unigram이 모델이 생성한 시스템 요약본에 등장했다는 것이다. 그러나 모델이 생성했던 시스템 요약본이 엄청 긴 문장이었을 경우에 참조 gold standard 와 크게 관련이 없어도 gold standard의 단어 대부분을 포함할 가능성이 커지기 때문에 지표로 사용하기에는 문제가 있다.
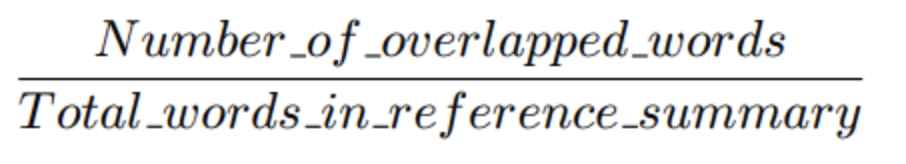
-
Precision : 모델이 생성한 시스템 요약본 중 gold standard와 겹치는 단어들이 얼마나 많은지
위 예시에서 계산해보면 6/7 = 0.86 으로 구해진다. 긴 요약문의 경우에는 불필요한 단어들이 너무 많아질 수 있기 때문에 그런 경우 precision에서 좋은 성능을 갖기 어렵다.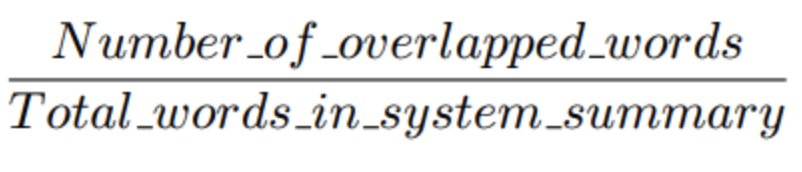
-
따라서 Precision과 Recall 을 모두 계산 후, F-Measure 을 측정한다. 그러나 모델이 제약 조건이 많아서 간결한 요약만 생성하는 경우는 recall 만 평가지표로 사용할수도 있다.
ROUGE-N, ROUGE-S, ROUGE-L
이 세가지는 모두 요약본의 일정 부분을 비교하는 성능 지표이다.
- ROUGE-N : unigram, bigram, trigram 등 문장 간 중복되는 n-gram 을 비교하는 지표
- ROUGE-1 :시스템 요약본과 참조 요약본 간 겹치는 unigram의 수를 보는 지표
- ROUGE-2 :시스템 요약본과 참조 요약본 간 겹치는 bigram의 수를 보는 지표
- ROUGE-S : skip-gram co-ocurrence 기법이라 부르기도 한다. 논문에서는 skip bigram 을 비교하는 지표라고 나온다. 여기서 skip bigram 이란 "cat in the hat" 이라는 문장이 있을 때 "cat in", "cat the", "cat hat", "in the", "in hat", "the hat" 의 쌍을 말한다.
- ROUGE-L : Longest common subsequence(LCS) 를 사용해 최장길이로 매칭되는 문자열을 측정해서 보는 지표
참고 : ROUGE: A Package for Automatic Evaluation of Summaries,
https://huffon.github.io/2019/12/07/rouge/
