요약
이번 주차에는 오토스케일링에 대해 진행했다. 파드의 오토스케일링으로 HPA, VPA 그리고 노드에 비례해서 파드 개수를 조정하는 CPA까지 있다. 노드를 스케줄링하는 KEDA, CA, Karpenter 까지 진행하면서 이번주차는 끝난다.
파드의 스케줄링은 파드의 리소스 사용량을 기준으로 진행한다. 파드의 개수를 늘리는 것은 부하분산이 없다면 의미없는 일이지만, selector 를 통한 부하분산을 지원하기에 효과적이다. 또한, VPA는 리소스를 늘리나 재실행이 필요하다는 단점이 있다. [앞으로 재실행없이 리소스 변경이 가능할지도 모른다. (Docs)], HPA -VPA 모두 쿠버네티스에서 지원해줘, 플러그인 설치 없이 진행가능하다.
노드를 스케줄링하는 CA, KEDA, Karpenter가 있다. CA는 파드를 통해 모니터링하고, 리소스 메트릭을 통해 스케일링한다. KEDA는 CA와는 다르게 리소스 메트릭이 아닌 이벤트 기반으로 스케일여부를 결정한다. 마지막으로 Karpenter는 다른 오토스케일링과 다르게 초 단위로 컴퓨팅 리소스를 제공한다.
Karpenter를 마지막으로 실습은 종료된다. 주제가 오토스케일링이다보니 끝나고 나서 자원을 꼭 삭제해줘야한다.
용어설명
- 스케일 아웃, 스케일 인
스케일 아웃은 기존의 인프라이외에 새로운 인프라를 추가해서 확장하는 방식이다. ‘스케일인’은 반대
- 스케일 업, 스케일 다운
스케일 업은 기존의 인프라를 확장하는 것이다. ‘스케일 다운’은 반대! ex) CPU 변경, RAM추가
배포환경
기존의 배포환경과 동일하게, kube-ops-view, 프로메테우스, 그라파나까지 설치한다. 관련된 배포는 이전주차를 참고하면 된다.
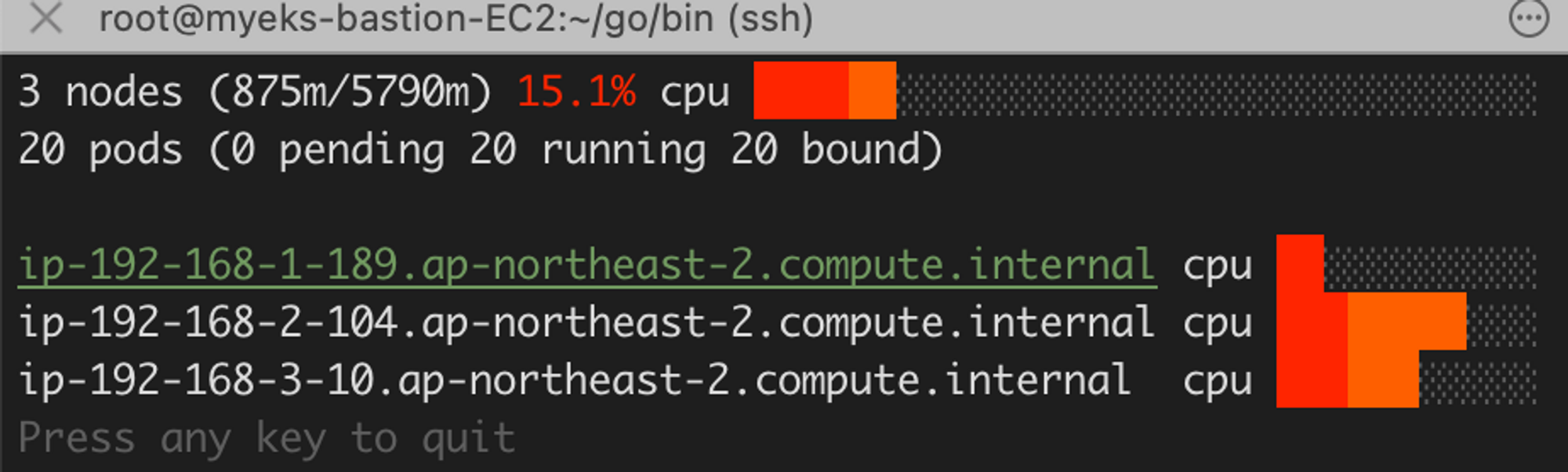
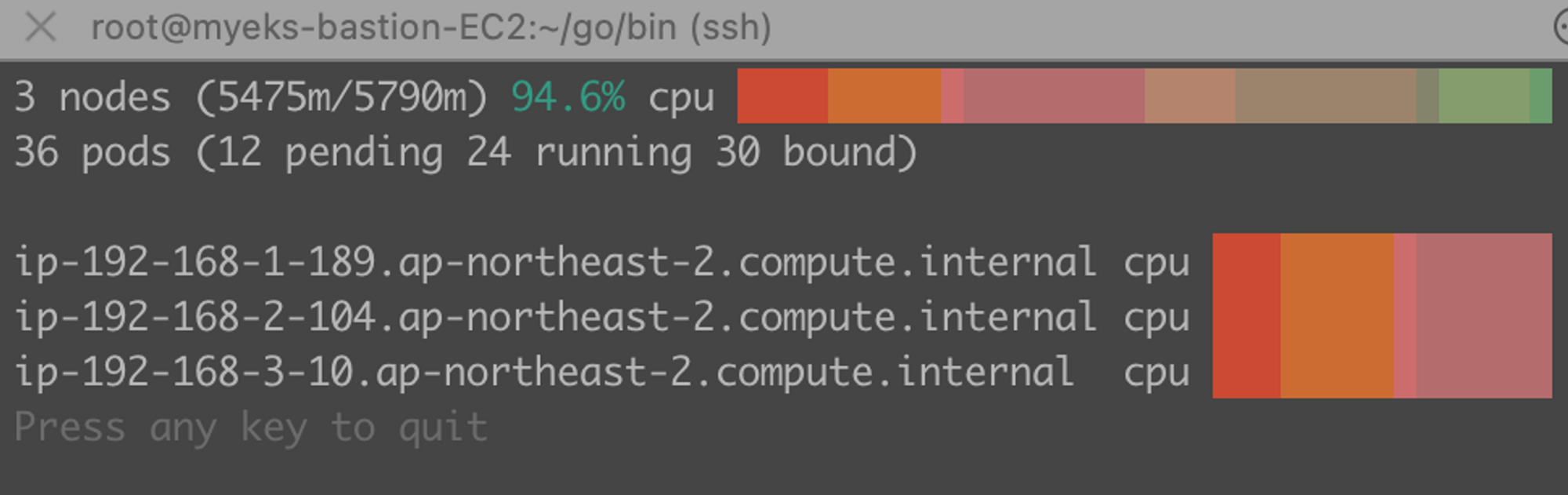
이번 주차에서는 노드의 오토스케일링을 확인하기 위해 EKS Node Viewer를 설치하여 각 노드들의 CPU 사용량을 모니터링한다.
EKS Node Viewer 설치 : 노드 할당 가능 용량과 요청 request 리소스 표시, 실제 파드 리소스 사용량 X
# Go 설치
$yum install -y go
Loaded plugins: extras_suggestions, langpacks, priorities, update-motd
...
# EKS Node Viewer 설치
$go install github.com/awslabs/eks-node-viewer/cmd/eks-node-viewer@latest
$tree ~/go/bin
/root/go/bin
└── eks-node-viewer
설치를 마무리 하고, 디렉토리에 들어가 ./eks-node-viewer 를 실행하면 아래와 같이 노드를 모니터링화면이 나온다.
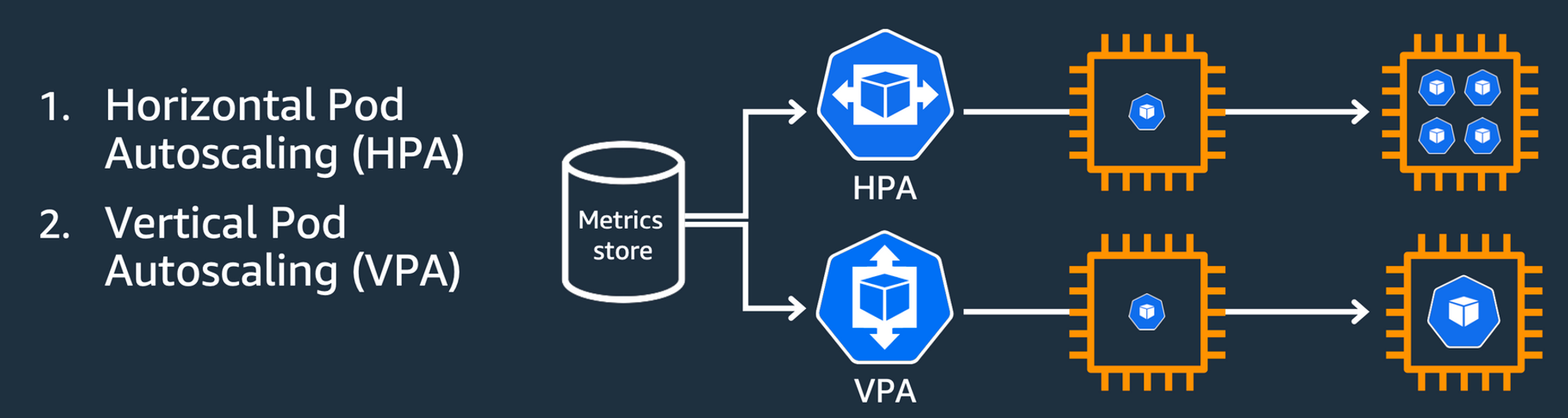
Pod AutuScaling
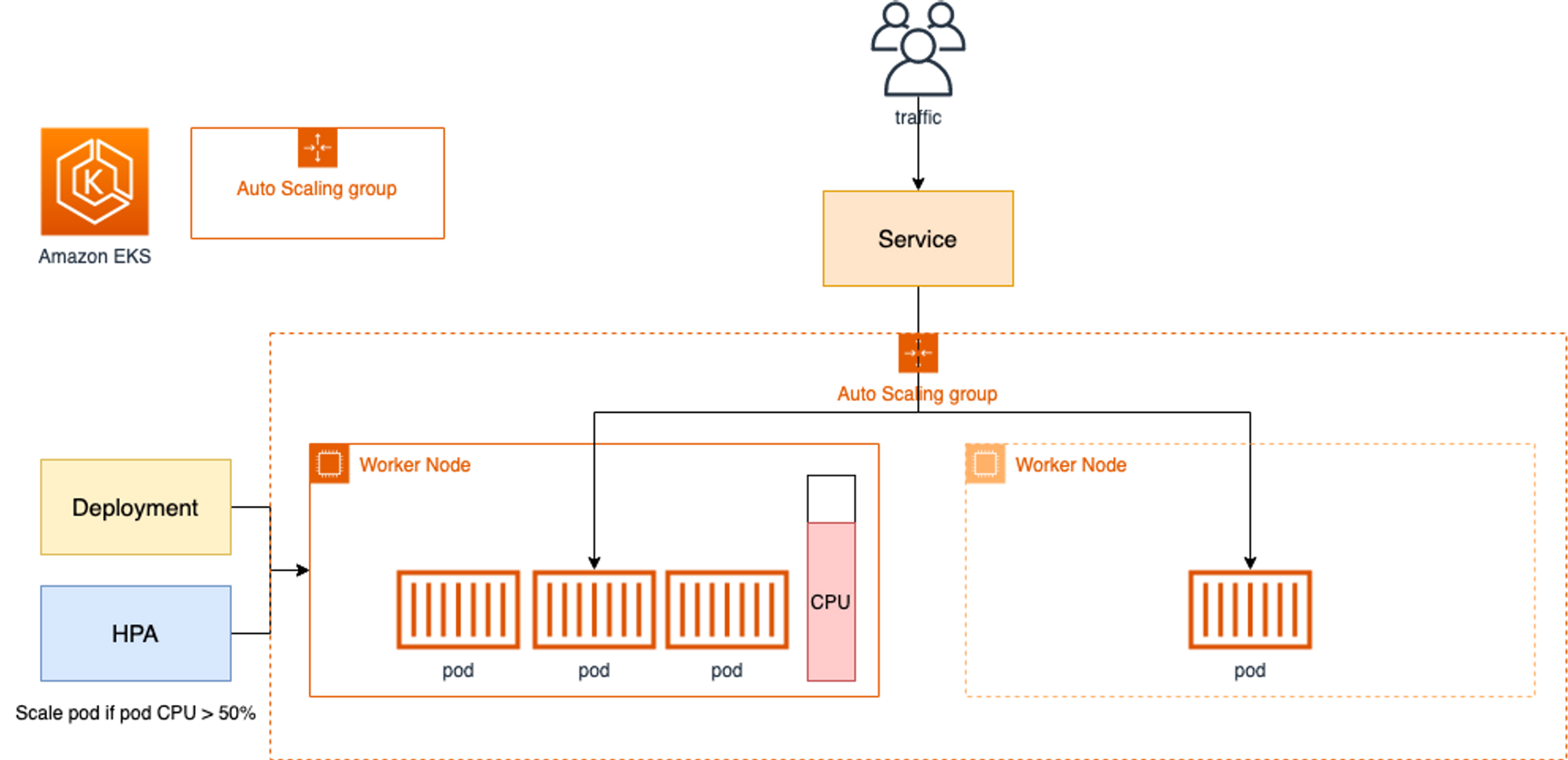
해당 파트에서는 파드의 오토스케일링에 대해 실습한다. 아래의 그림에서 알 수 있듯이 같은 스펙의 파드를 증가시키는 HPA와 파드의 리소스를 증가시키는 VPA가 있다.
HPA - Horizontal Pod Autoscaler
HPA는 리소스 메트릭을 통해 파드의 리소스를 파악하여 스케일링한다. 아래의 아키텍처를 통해서 자세한 원리를 알 수 있다. HPA로 진행되는 파드는 로드밸런싱 설정을 진행해야 한다. 로드밸런싱을 통해 하나의 파드만 부하를 받는 것이 아닌 새로운 파드까지 부하를 분담한다.(selector) 그렇기에 효율적으로 리소스를 관리할 수 있다.
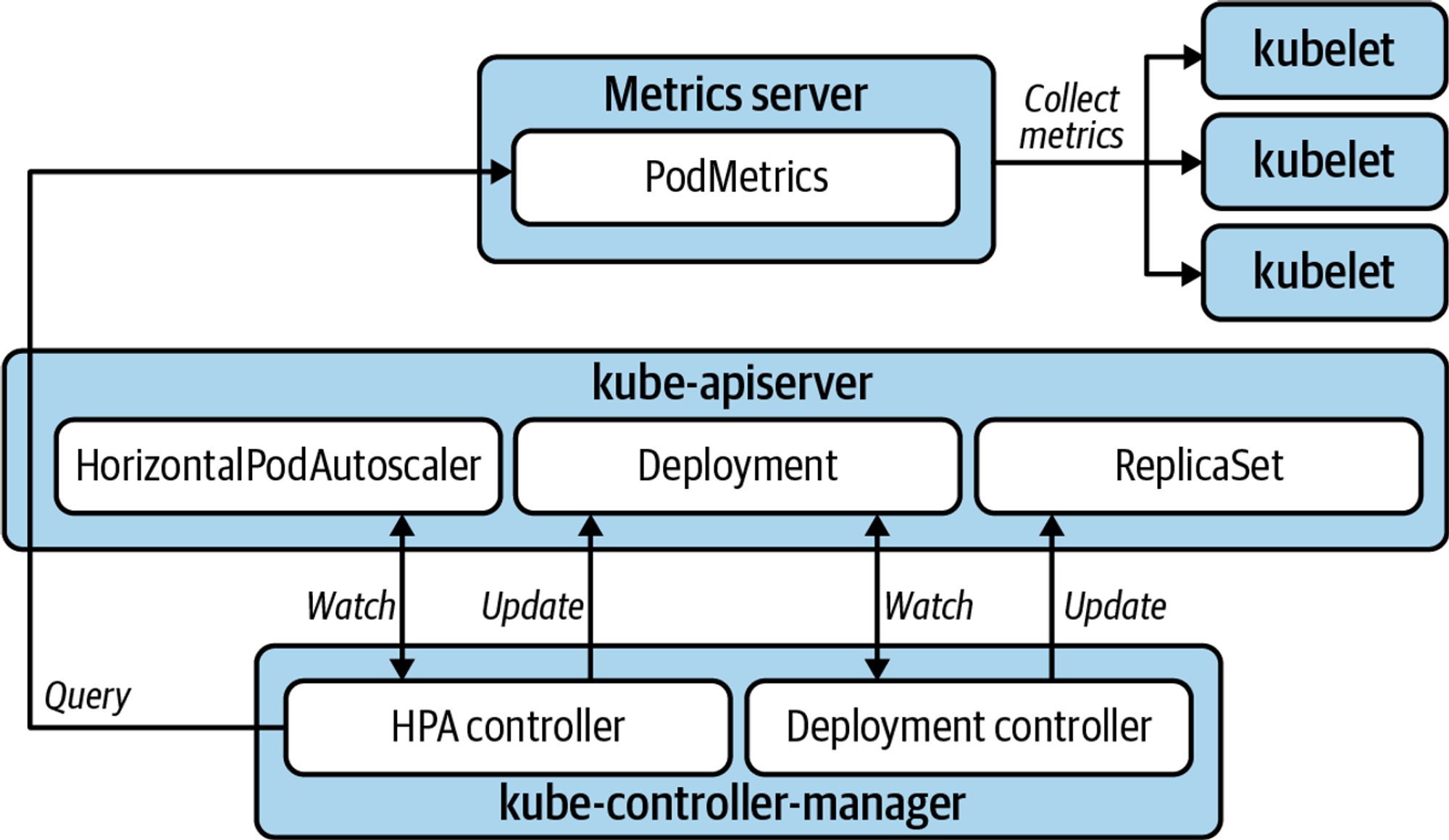
그림 출처 - (🧝🏻♂️)김태민 기술 블로그 - 링크
테스트 애플리케이션 배포
$curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml
$cat php-apache.yaml | yh
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
**requests:
cpu: 200m**
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
# 테스트 용 php-apache server 배포
$k apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
# 확인, 연산의 복잡도를 주었다.
$kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
$PODIP=$(kubectl get pod -l run=php-apache -o jsonpath={.items[0].status.podIP})
# 위와 같이 커리를 날리면 위의 연산 후 트래픽이 날아온다.
$curl -s $PODIP; echo
OK!HPA 설정 및 확인
# cpu 사용량을 기준으로 HPA
$kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
# 확인 가능
$kubectl describe hpa
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: php-apache
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sun, 21 May 2023 22:33:48 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
매니페스트에서 상태값은 버리고, 정리해주는 툴인 neat 플러그인을 설치한다.
$kubectl krew install neat
...
# 상태값까지 출력되어 보기 불편하다.
$kubectl get hpa php-apache -o yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2023-05-21T13:33:48Z"
name: php-apache
namespace: default
resourceVersion: "6344"
uid: cae373a4-fb84-4ff3-9945-d19984fe811c
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
status:
conditions:
- lastTransitionTime: "2023-05-21T13:34:03Z"
message: recent recommendations were higher than current one, applying the highest
recent recommendation
reason: ScaleDownStabilized
status: "True"
type: AbleToScale
- lastTransitionTime: "2023-05-21T13:34:03Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2023-05-21T13:34:03Z"
message: the desired count is within the acceptable range
reason: DesiredWithinRange
status: "False"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: 1m
name: cpu
type: Resource
currentReplicas: 1
desiredReplicas: 1
# 깔끔하게 출력되는 모습
# 아래의 내용을 확인하면 최대 10개이고 기준은 CPU의 평균활용량 50$이다!, 50%를 넘으면 자동으로 새로운 파드가 생성된다.
$kubectl get hpa php-apache -o yaml | kubectl neat | yh
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
**maxReplicas: 10**
metrics:
- resource:
**name: cpu**
target:
**averageUtilization: 50**
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache부하를 주어 테스트하는 모습, 파드가 증가하는 모습은 아래의 사진을 통해 자세하게 확인할 수 있다!
$while true;do curl -s $PODIP; sleep 0.5; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!^C
$while true;do curl -s $PODIP; sleep 0.3; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!^C
$kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
If you don't see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
$kubectl delete deploy,svc,hpa,pod --all
deployment.apps "php-apache" deleted
service "kubernetes" deleted
service "php-apache" deleted
horizontalpodautoscaler.autoscaling "php-apache" deleted
pod "load-generator" deleted
pod "php-apache-698db99f59-4s7d7" deleted
pod "php-apache-698db99f59-qkd2h" deleted
pod "php-apache-698db99f59-wcxvg" deleted
pod "php-apache-698db99f59-wh62k" deleted
pod "php-apache-698db99f59-x2x5r" deleted
pod "php-apache-698db99f59-zblfs" deleted파드 하나당 CPU활용량이 50% 미만이되려면 6~7개정도의 파드가 생성되어야 했다. apache 서비스를 통해 지속적으로 트래픽을 날리는 것이므로 selector 에 의해 자동으로 로드밸런싱이 된다. 그렇기에 부하가 분산이 가능해 7개면 50%미만으로 떨어진다.
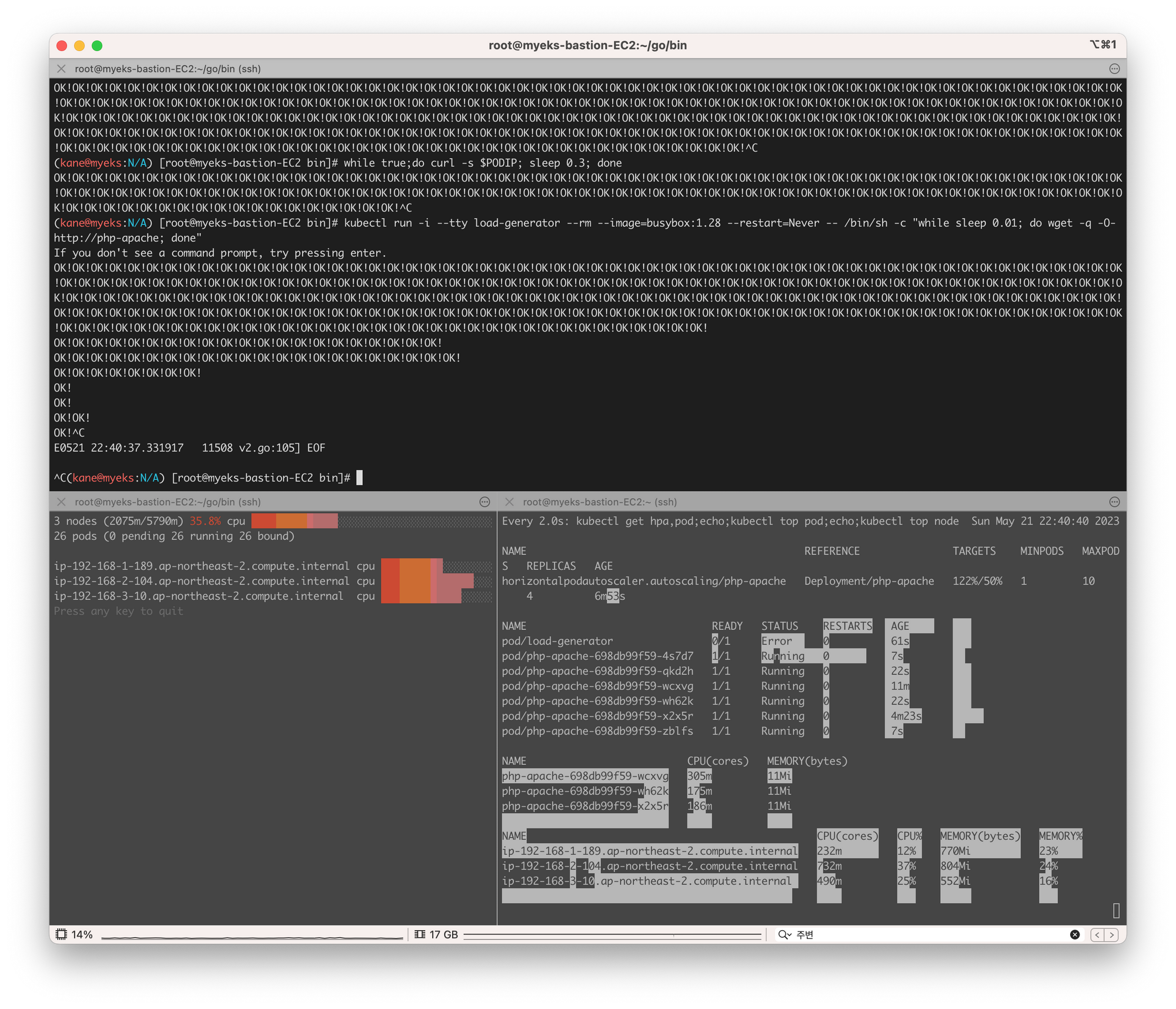
그라파나 대시보드를 통해 확인한 파드의 개수!
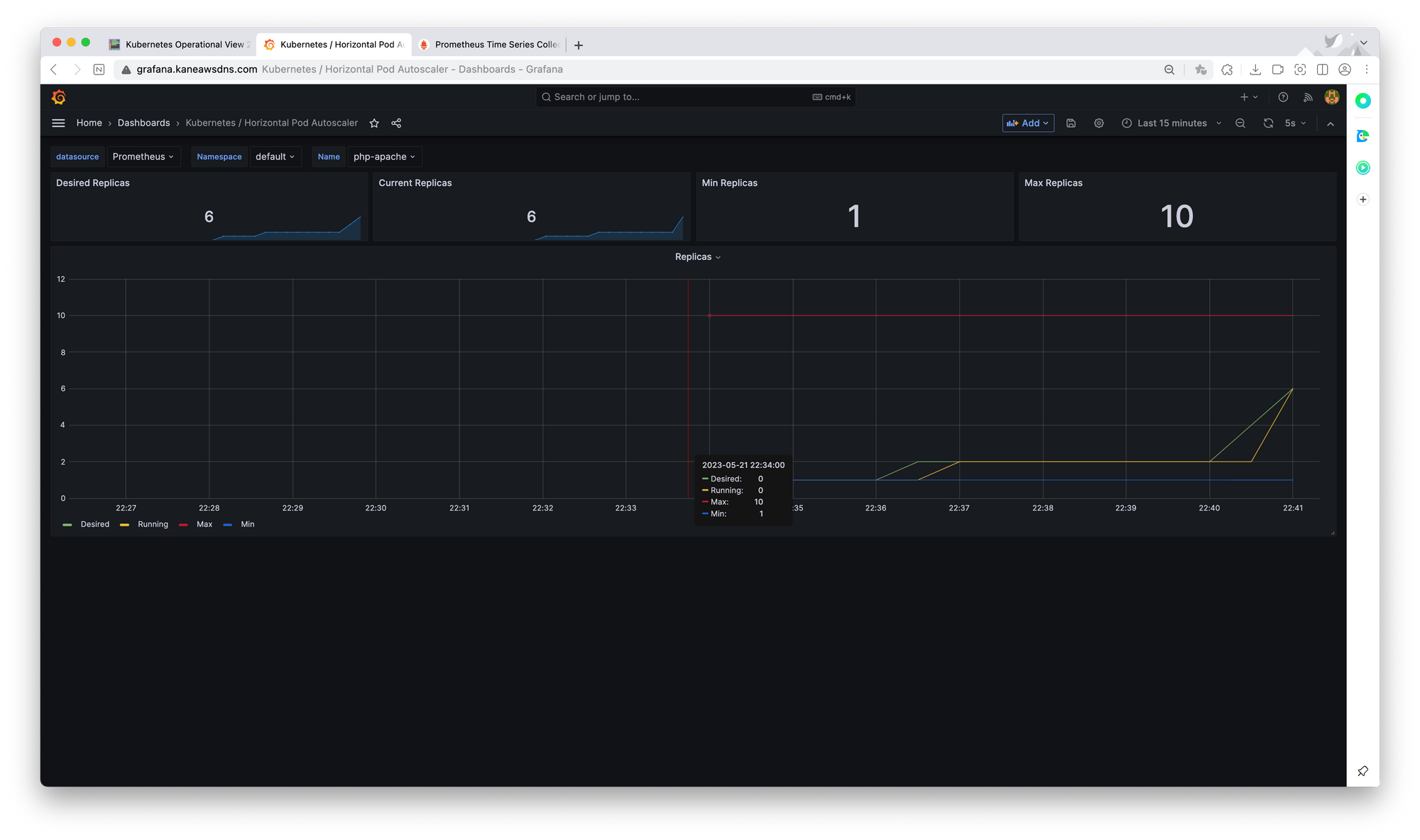
VPA - Vertical Pod Autoscaler
HPA는 동일한 스펙의 파드의 개수를 늘리는 것이었다면, VPA는 현재 실행중인 파드의 리소스를 확장한다. 이 과정에서 재시작이 필요하다는 단점이 있다. 파드를 재시작해야되기에, 실제 운영환경에서는 별로 추천하지 않는다고 한다. 스터디원분이 알려주신 아래의 문서와 같이 재실행없이 리소스 변경이 가능하다면 운영환경에서도 쓸모있을 것 같다.
https://kubernetes.io/blog/2023/05/12/in-place-pod-resize-alpha/
또한, VPA는 메트릭서버를 통해 파드의 로그를 수집하여 리소스 최적값을 추천해준다. 아래의 아키텍처를 통해 작동방식을 파악할 수 있다.
[악분님의 블로그 참고! https://malwareanalysis.tistory.com/603]
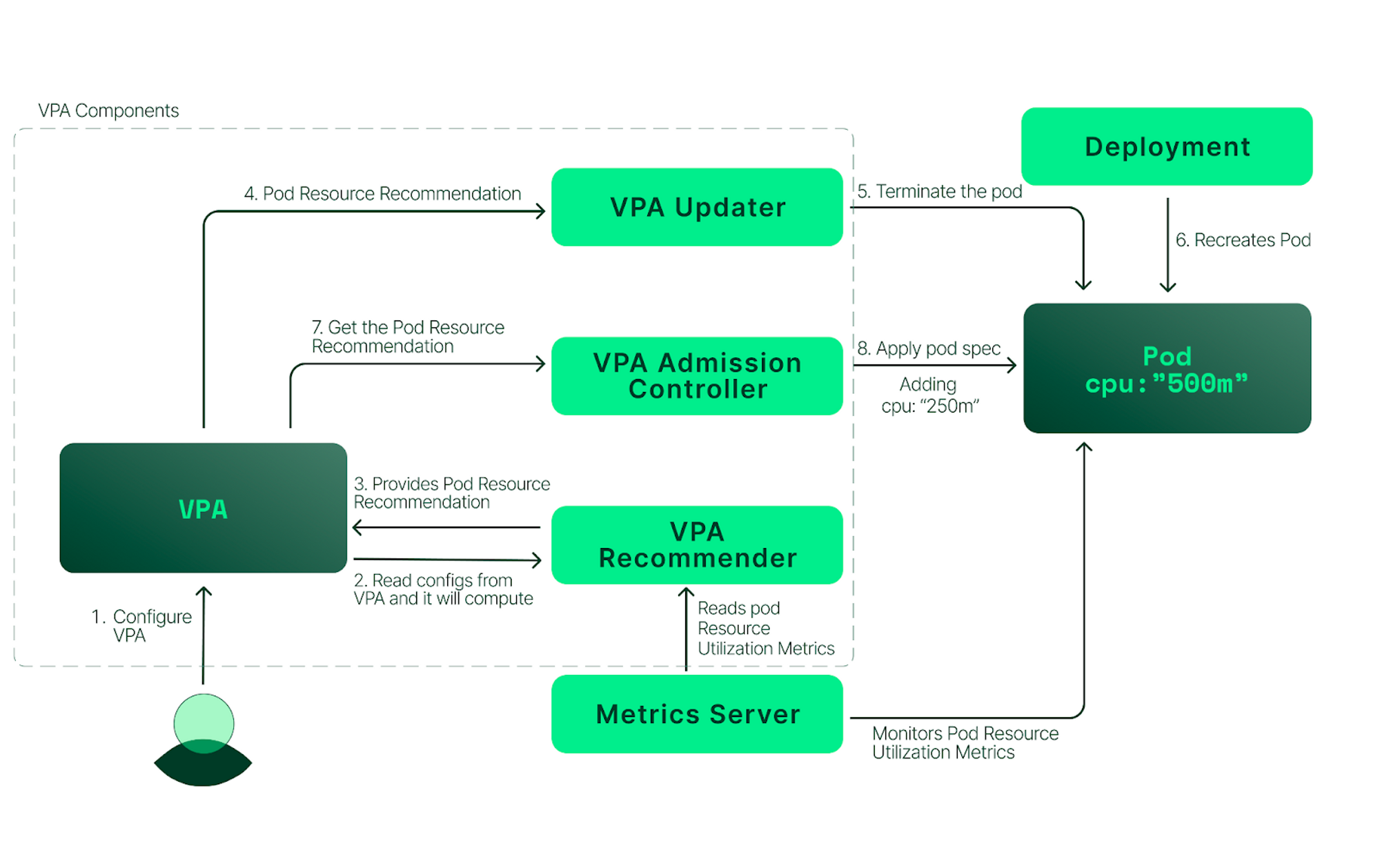
그림 출처 : Blog
이제 쿠버네티스에서 제공한 예시를 통해 실습을 진행한다.
# 쿠버네티스 예시 프로젝트
git clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
# openssl 업그레이드, (v1.1.1 이상이어야 한다.)
yum install openssl11 -y
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# 배포!
kubectl apply -f examples/hamster.yaml && kubectl get vpa -w
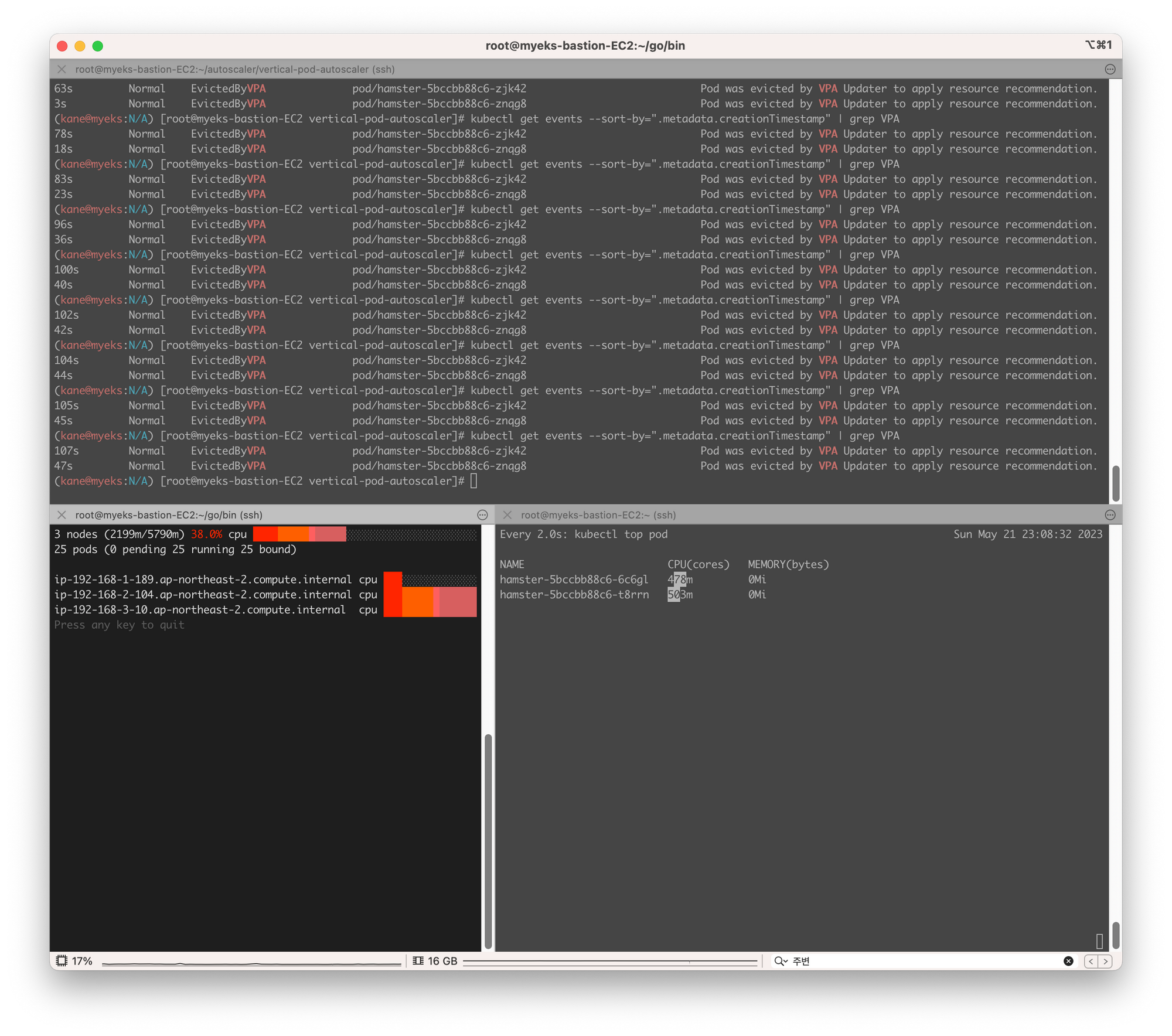
아래는 배포된 yaml 파일이다. 파일에서 설정된 리소스 cpu 100m, memory 50Mi를 확인할 수 있지만, 추후 VPA에 의해 파드가 재생성되면서 리소스를 변경시킨다.
# 아래의 예시 yaml 파일에서 설정된 리소스 cpu 100m, memory 50Mi
apiVersion: apps/v1
kind: Deployment
metadata:
name: hamster
spec:
selector:
matchLabels:
app: hamster
replicas: 2
template:
metadata:
labels:
app: hamster
spec:
securityContext:
runAsNonRoot: true
runAsUser: 65534 # nobody
containers:
- name: hamster
image: registry.k8s.io/ubuntu-slim:0.1
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args:
- "-c"
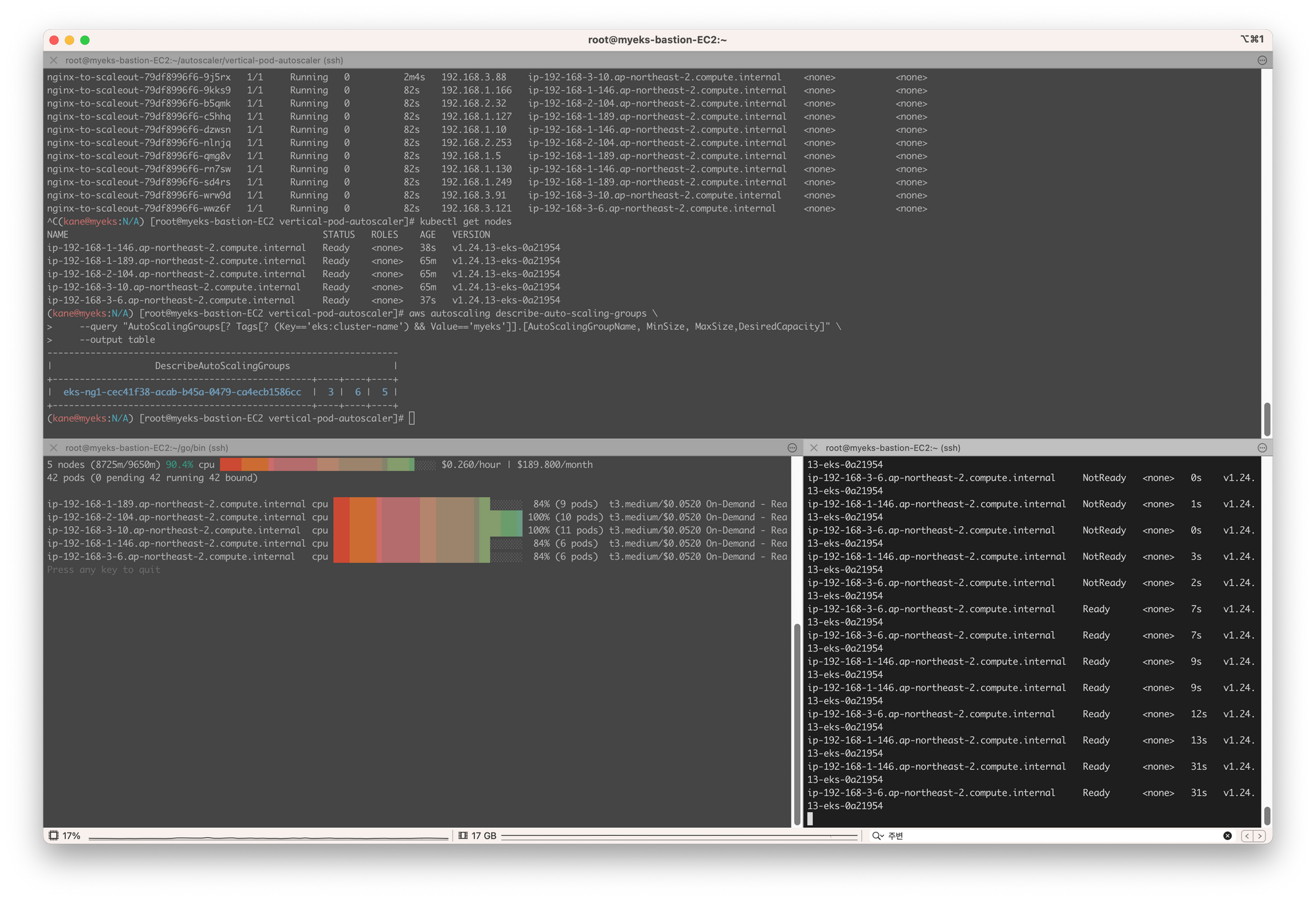
- "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done"아래의 터미널 사진에서 상위를 보면 VPA에 의해 파드가 재생성된 것을 알 수 있고, 하단 오른쪽을 보면 CPU 요청량이 달라진 것을 확인할 수 있다.
KRR
이번에 AWS에서 지원해주는 툴이며, 메트릭을 수집하고 스스로 판단하여 추천을 해준다고 한다. 아래의 그림을 참고하면 자세하게 리소스별 추천을 해주는 것을 확인할 수 있다.
KRR: Prometheus-based Kubernetes Resource Recommendations - 링크 & Youtube - 링크
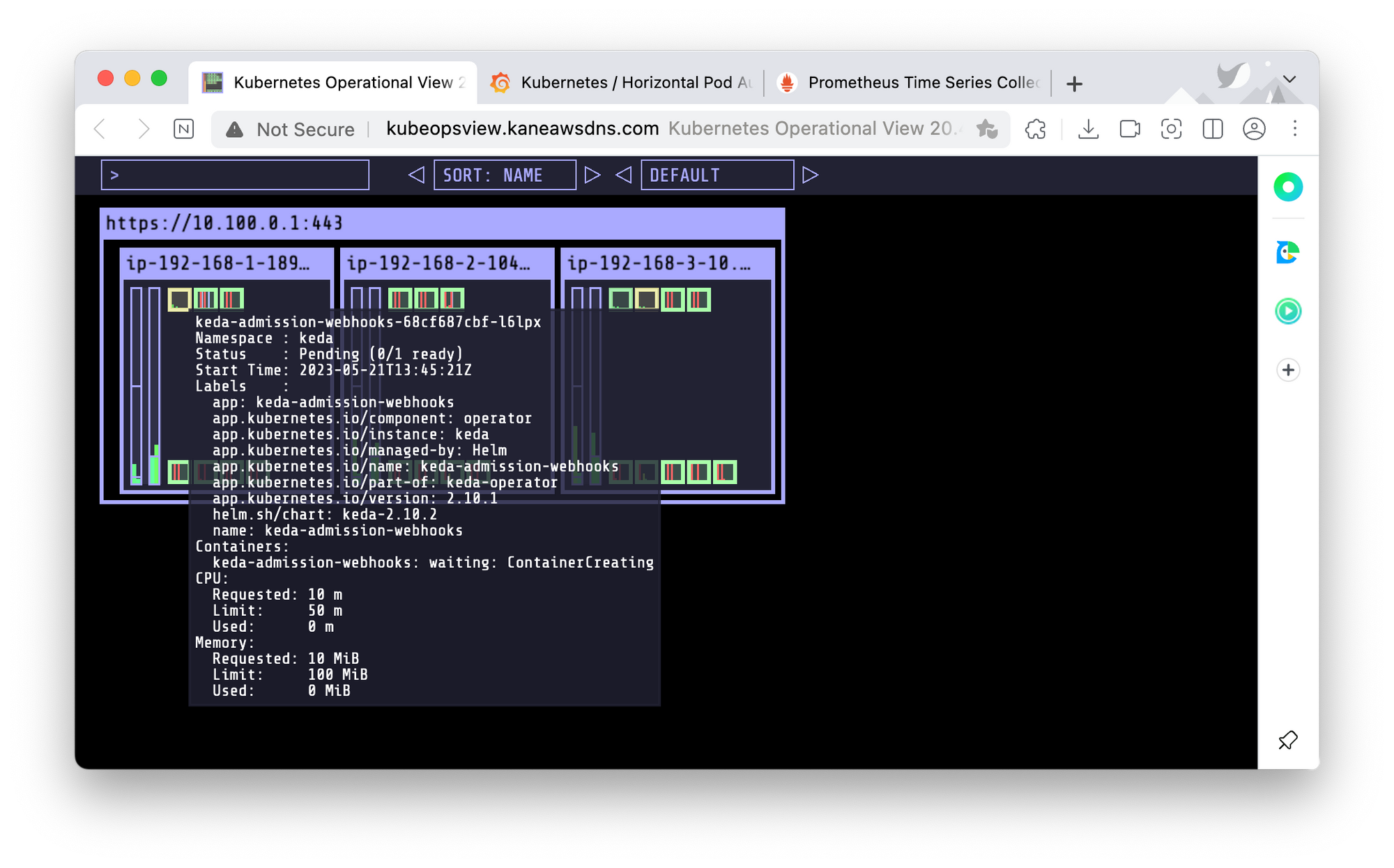
KEDA - Kubernetes based Event Driven Autoscaler
리소스 메트릭이 아닌 특정 이벤트를 기준으로 노드를 오토스케일링한다.
KEDA는 전용 메트릭서버를 별도로 둔다. 아마 메트릭관련 내용이 조금 달라서 그런 것 같다.!
또한, 그라파나의 공식대시보드에 없어서, Github에서 config파일을 복사하고, import 한다.
배포된 kube-ops-view 사진
# KEDA 설치
$cat <<EOT > keda-values.yaml
> metricsServer:
> useHostNetwork: true
>
> prometheus:
> metricServer:
> enabled: true
> port: 9022
> portName: metrics
> path: /metrics
> serviceMonitor:
> # Enables ServiceMonitor creation for the Prometheus Operator
> enabled: true
> podMonitor:
> # Enables PodMonitor creation for the Prometheus Operator
> enabled: true
> operator:
> enabled: true
> port: 8080
> serviceMonitor:
> # Enables ServiceMonitor creation for the Prometheus Operator
> enabled: true
> podMonitor:
> # Enables PodMonitor creation for the Prometheus Operator
> enabled: true
>
> webhooks:
> enabled: true
> port: 8080
> serviceMonitor:
> # Enables ServiceMonitor creation for the Prometheus webhooks
> enabled: true
> EOT
# 별도의 네임스페이스 생성
$kubectl create namespace keda
namespace/keda created
$helm repo add kedacore https://kedacore.github.io/charts
"kedacore" has been added to your repositories
# helm을 통한 배포
$helm install keda kedacore/keda --version 2.10.2 --namespace keda -f keda-values.yaml
NAME: keda
LAST DEPLOYED: Sun May 21 22:45:17 2023
NAMESPACE: keda
STATUS: deployed
REVISION: 1
TEST SUITE: None
# KEDA 설치 확인
$kubectl get-all -n keda
W0521 22:45:24.843016 14118 client.go:102] Could not fetch complete list of API resources, results will be incomplete: unable to retrieve the complete list of server APIs: external.metrics.k8s.io/v1beta1: the server is currently unable to handle the request
NAME NAMESPACE AGE
configmap/kube-root-ca.crt keda 26s
endpoints/keda-admission-webhooks keda 5s
endpoints/keda-operator keda 5s
endpoints/keda-operator-metrics-apiserver keda 5s
pod/keda-admission-webhooks-68cf687cbf-l6lpx keda 5s
pod/keda-operator-656478d687-4m47m keda 5s
pod/keda-operator-metrics-apiserver-7fd585f657-xjltw keda 5s
secret/sh.helm.release.v1.keda.v1 keda 6s
serviceaccount/default keda 26s
serviceaccount/keda-operator keda 6s
service/keda-admission-webhooks keda 5s
service/keda-operator keda 5s
service/keda-operator-metrics-apiserver keda 5s
deployment.apps/keda-admission-webhooks keda 5s
deployment.apps/keda-operator keda 5s
deployment.apps/keda-operator-metrics-apiserver keda 5s
replicaset.apps/keda-admission-webhooks-68cf687cbf keda 5s
replicaset.apps/keda-operator-656478d687 keda 5s
replicaset.apps/keda-operator-metrics-apiserver-7fd585f657 keda 5s
endpointslice.discovery.k8s.io/keda-admission-webhooks-jtdd2 keda 5s
endpointslice.discovery.k8s.io/keda-operator-7pdhn keda 5s
endpointslice.discovery.k8s.io/keda-operator-metrics-apiserver-9ltmf keda 5s
podmonitor.monitoring.coreos.com/keda-operator keda 5s
podmonitor.monitoring.coreos.com/keda-operator-metrics-apiserver keda 5s
servicemonitor.monitoring.coreos.com/keda-admission-webhooks keda 5s
servicemonitor.monitoring.coreos.com/keda-operator keda 5s
servicemonitor.monitoring.coreos.com/keda-operator-metrics-apiserver keda 5s
rolebinding.rbac.authorization.k8s.io/keda-operator keda 5s
role.rbac.authorization.k8s.io/keda-operator keda 6s
$kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-68cf687cbf-l6lpx 0/1 ContainerCreating 0 6s
pod/keda-operator-656478d687-4m47m 0/1 ContainerCreating 0 6s
pod/keda-operator-metrics-apiserver-7fd585f657-xjltw 0/1 ContainerCreating 0 6s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-admission-webhooks ClusterIP 10.100.253.109 <none> 443/TCP,8080/TCP 6s
service/keda-operator ClusterIP 10.100.239.105 <none> 9666/TCP,8080/TCP 6s
service/keda-operator-metrics-apiserver ClusterIP 10.100.137.4 <none> 443/TCP,80/TCP,9022/TCP 6s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-admission-webhooks 0/1 1 0 6s
deployment.apps/keda-operator 0/1 1 0 6s
deployment.apps/keda-operator-metrics-apiserver 0/1 1 0 6s
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-admission-webhooks-68cf687cbf 1 1 0 6s
replicaset.apps/keda-operator-656478d687 1 1 0 6s
replicaset.apps/keda-operator-metrics-apiserver-7fd585f657 1 1 0 6s
$kubectl get crd | grep keda
clustertriggerauthentications.keda.sh 2023-05-21T13:45:20Z
scaledjobs.keda.sh 2023-05-21T13:45:20Z
scaledobjects.keda.sh 2023-05-21T13:45:20Z
triggerauthentications.keda.sh 2023-05-21T13:45:20Z테스트를 위해, 위에서도 사용했던 php-apache 배포
# 테스트용 디플로이 배포
$kubectl apply -f php-apache.yaml -n keda
deployment.apps/php-apache created
service/php-apache created
# php-apache 배포 확인
$kubectl get pod -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-68cf687cbf-l6lpx 1/1 Running 0 64s
keda-operator-656478d687-4m47m 1/1 Running 1 (51s ago) 64s
keda-operator-metrics-apiserver-7fd585f657-xjltw 1/1 Running 0 64s
php-apache-698db99f59-rkqxp 0/1 ContainerCreating 0 1s
특정시간(0,15,30,45)에 시작하고 (05,20,35,50)종료하는 이벤트 기반 정책 생성
# ScaledObject 정책 생성 : cron
# triggers 부분에서 이벤트기반 정책을 확인할 수 있다.
$cat <<EOT > keda-cron.yaml
> apiVersion: keda.sh/v1alpha1
> kind: ScaledObject
> metadata:
> name: php-apache-cron-scaled
> spec:
> minReplicaCount: 0
> maxReplicaCount: 2
> pollingInterval: 30
> cooldownPeriod: 300
> scaleTargetRef:
> apiVersion: apps/v1
> kind: Deployment
> name: php-apache
> triggers:
> - type: cron
> metadata:
> timezone: Asia/Seoul
> start: 00,15,30,45 * * * *
> end: 05,20,35,50 * * * *
> desiredReplicas: "1"
> EOT
$kubectl apply -f keda-cron.yaml -n keda
scaledobject.keda.sh/php-apache-cron-scaled created
$k get ScaledObject -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True False Unknown 6m39s
아래의 명령어가 잘 안먹음
# $kubectl get ScaledObject -w
# 확인!
$kubectl get ScaledObject,hpa,pod -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True True Unknown 2m45s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 1 2m45s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-68cf687cbf-l6lpx 1/1 Running 0 4m12s
pod/keda-operator-656478d687-4m47m 1/1 Running 1 (3m59s ago) 4m12s
pod/keda-operator-metrics-apiserver-7fd585f657-xjltw 1/1 Running 0 4m12s
pod/php-apache-698db99f59-rkqxp 1/1 Running 0 3m9s
# 위에서 ACTIVE인 이유는 현재 시각이 45분
$date
Sun May 21 22:50:43 KST 2023
# 50분이 되었으니 다시 명령 실행, 아래의 ACTIVE 속성이 'False'로 바뀜! ㄴ
$kubectl get ScaledObject,hpa,pod -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True False Unknown 4m15s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 1 4m16s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-68cf687cbf-l6lpx 1/1 Running 0 5m43s
pod/keda-operator-656478d687-4m47m 1/1 Running 1 (5m30s ago) 5m43s
pod/keda-operator-metrics-apiserver-7fd585f657-xjltw 1/1 Running 0 5m43s
pod/php-apache-698db99f59-rkqxp 1/1 Running 0 4m40s
# false 확인 가능!
$kubectl get ScaledObject,hpa,pod -n keda
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 cron True False Unknown 4m47s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 1 4m47s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-68cf687cbf-l6lpx 1/1 Running 0 6m14s
pod/keda-operator-656478d687-4m47m 1/1 Running 1 (6m1s ago) 6m14s
pod/keda-operator-metrics-apiserver-7fd585f657-xjltw 1/1 Running 0 6m14s
pod/php-apache-698db99f59-rkqxp 1/1 Running 0 5m11s
$k get ScaledObject
No resources found in default namespace.
$kubectl get pod -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-68cf687cbf-l6lpx 1/1 Running 0 8m32s
keda-operator-656478d687-4m47m 1/1 Running 1 (8m19s ago) 8m32s
keda-operator-metrics-apiserver-7fd585f657-xjltw 1/1 Running 0 8m32s
php-apache-698db99f59-rkqxp 1/1 Running 0 7m29s
# ScaledObject 확인 가능!
$kubectl describe -n keda ScaledObject
Name: php-apache-cron-scaled
Namespace: keda
Labels: scaledobject.keda.sh/name=php-apache-cron-scaled
Annotations: <none>
API Version: keda.sh/v1alpha1
Kind: ScaledObject
Metadata:
Creation Timestamp: 2023-05-21T13:46:48Z
Finalizers:
finalizer.keda.sh
Generation: 1
Managed Fields:
API Version: keda.sh/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:finalizers:
.:
v:"finalizer.keda.sh":
f:labels:
.:
f:scaledobject.keda.sh/name:
Manager: keda
Operation: Update
Time: 2023-05-21T13:46:48Z
API Version: keda.sh/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:status:
.:
f:conditions:
f:externalMetricNames:
f:hpaName:
f:lastActiveTime:
f:originalReplicaCount:
f:scaleTargetGVKR:
.:
f:group:
f:kind:
f:resource:
f:version:
f:scaleTargetKind:
Manager: keda
Operation: Update
Subresource: status
Time: 2023-05-21T13:46:48Z
API Version: keda.sh/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:cooldownPeriod:
f:maxReplicaCount:
f:minReplicaCount:
f:pollingInterval:
f:scaleTargetRef:
.:
f:apiVersion:
f:kind:
f:name:
f:triggers:
Manager: kubectl-client-side-apply
Operation: Update
Time: 2023-05-21T13:46:48Z
Resource Version: 10339
UID: ac336308-4464-4c86-87d8-307de28d4df5
Spec:
Cooldown Period: 300
Max Replica Count: 2
Min Replica Count: 0
Polling Interval: 30
Scale Target Ref:
API Version: apps/v1
Kind: Deployment
Name: php-apache
Triggers:
Metadata:
Desired Replicas: 1
End: 05,20,35,50 * * * *
Start: 00,15,30,45 * * * *
Timezone: Asia/Seoul
Type: cron
Status:
Conditions:
Message: ScaledObject is defined correctly and is ready for scaling
Reason: ScaledObjectReady
Status: True
Type: Ready
Message: Scaler cooling down because triggers are not active
Reason: ScalerCooldown
Status: False
Type: Active
Status: Unknown
Type: Fallback
External Metric Names:
s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx
Hpa Name: keda-hpa-php-apache-cron-scaled
Last Active Time: 2023-05-21T13:49:48Z
Original Replica Count: 1
Scale Target GVKR:
Group: apps
Kind: Deployment
Resource: deployments
Version: v1
Scale Target Kind: apps/v1.Deployment
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal KEDAScalersStarted 7m56s keda-operator Started scalers watch
Normal ScaledObjectReady 7m56s keda-operator ScaledObject is ready for scaling
$date
Sun May 21 22:55:17 KST 2023
keda-operator 자세히 확인!
$k -n keda describe pod keda-operator
Name: keda-operator-656478d687-4m47m
Namespace: keda
Priority: 0
Service Account: keda-operator
Node: ip-192-168-3-10.ap-northeast-2.compute.internal/192.168.3.10
Start Time: Sun, 21 May 2023 22:45:21 +0900
Labels: app=keda-operator
app.kubernetes.io/component=operator
app.kubernetes.io/instance=keda
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=keda-operator
app.kubernetes.io/part-of=keda-operator
app.kubernetes.io/version=2.10.1
helm.sh/chart=keda-2.10.2
name=keda-operator
pod-template-hash=656478d687
Annotations: container.seccomp.security.alpha.kubernetes.io/keda-operator: runtime/default
kubernetes.io/psp: eks.privileged
Status: Running
IP: 192.168.3.180
IPs:
IP: 192.168.3.180
Controlled By: ReplicaSet/keda-operator-656478d687
Containers:
keda-operator:
Container ID: containerd://e2fc885cb68003dce46ae15bb58f1b2156a4389bb55c6961cde0182fae232697
Image: ghcr.io/kedacore/keda:2.10.1
Image ID: ghcr.io/kedacore/keda@sha256:1489b706aa959a07765510edb579af34fa72636a26cfb755544c0ef776f3addf
Port: 8080/TCP
Host Port: 0/TCP
Command:
/keda
Args:
--leader-elect
--zap-log-level=info
--zap-encoder=console
--zap-time-encoding=rfc3339
--cert-dir=/certs
--enable-cert-rotation=true
--cert-secret-name=kedaorg-certs
--operator-service-name=keda-operator
--metrics-server-service-name=keda-operator-metrics-apiserver
--webhooks-service-name=keda-admission-webhooks
--metrics-bind-address=:8080
State: Running
Started: Sun, 21 May 2023 22:45:36 +0900
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Sun, 21 May 2023 22:45:30 +0900
Finished: Sun, 21 May 2023 22:45:34 +0900
Ready: True
Restart Count: 1
Limits:
cpu: 1
memory: 1000Mi
Requests:
cpu: 100m
memory: 100Mi
Liveness: http-get http://:8081/healthz delay=25s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:8081/readyz delay=20s timeout=1s period=10s #success=1 #failure=3
Environment:
WATCH_NAMESPACE:
POD_NAME: keda-operator-656478d687-4m47m (v1:metadata.name)
POD_NAMESPACE: keda (v1:metadata.namespace)
OPERATOR_NAME: keda-operator
KEDA_HTTP_DEFAULT_TIMEOUT: 3000
KEDA_HTTP_MIN_TLS_VERSION: TLS12
Mounts:
/certs from certificates (ro)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-5ktsx (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
certificates:
Type: Secret (a volume populated by a Secret)
SecretName: kedaorg-certs
Optional: true
kube-api-access-5ktsx:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: kubernetes.io/os=linux
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned keda/keda-operator-656478d687-4m47m to ip-192-168-3-10.ap-northeast-2.compute.internal
Warning FailedMount 10m kubelet MountVolume.SetUp failed for volume "certificates" : failed to sync secret cache: timed out waiting for the condition
Normal Pulled 10m kubelet Successfully pulled image "ghcr.io/kedacore/keda:2.10.1" in 6.362549579s
Normal Pulling 10m (x2 over 10m) kubelet Pulling image "ghcr.io/kedacore/keda:2.10.1"
Normal Created 10m (x2 over 10m) kubelet Created container keda-operator
Normal Started 10m (x2 over 10m) kubelet Started container keda-operator
Normal Pulled 10m kubelet Successfully pulled image "ghcr.io/kedacore/keda:2.10.1" in 699.131003ms
Name: keda-operator-metrics-apiserver-7fd585f657-xjltw
Namespace: keda
Priority: 0
Service Account: keda-operator
Node: ip-192-168-3-10.ap-northeast-2.compute.internal/192.168.3.10
Start Time: Sun, 21 May 2023 22:45:21 +0900
Labels: app=keda-operator-metrics-apiserver
app.kubernetes.io/component=operator
app.kubernetes.io/instance=keda
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=keda-operator-metrics-apiserver
app.kubernetes.io/part-of=keda-operator
app.kubernetes.io/version=2.10.1
helm.sh/chart=keda-2.10.2
pod-template-hash=7fd585f657
Annotations: container.seccomp.security.alpha.kubernetes.io/keda-operator-metrics-apiserver: runtime/default
kubernetes.io/psp: eks.privileged
Status: Running
IP: 192.168.3.10
IPs:
IP: 192.168.3.10
Controlled By: ReplicaSet/keda-operator-metrics-apiserver-7fd585f657
Containers:
keda-operator-metrics-apiserver:
Container ID: containerd://8eca27ff65b4e907ece4d4fe53b8b85920a1023ca070dc806f0c32be612134df
Image: ghcr.io/kedacore/keda-metrics-apiserver:2.10.1
Image ID: ghcr.io/kedacore/keda-metrics-apiserver@sha256:d1f1ccc8d14e33ee448ec0c820f65b8a3e01b2dad23d9fa38fa7204a6c0194ca
Ports: 6443/TCP, 8080/TCP, 9022/TCP
Host Ports: 6443/TCP, 8080/TCP, 9022/TCP
Args:
/usr/local/bin/keda-adapter
--port=8080
--secure-port=6443
--logtostderr=true
--metrics-service-address=keda-operator.keda.svc.cluster.local:9666
--client-ca-file=/certs/ca.crt
--tls-cert-file=/certs/tls.crt
--tls-private-key-file=/certs/tls.key
--cert-dir=/certs
--metrics-port=9022
--metrics-path=/metrics
--v=0
State: Running
Started: Sun, 21 May 2023 22:45:46 +0900
Ready: True
Restart Count: 0
Limits:
cpu: 1
memory: 1000Mi
Requests:
cpu: 100m
memory: 100Mi
Liveness: http-get https://:6443/healthz delay=5s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get https://:6443/readyz delay=5s timeout=1s period=10s #success=1 #failure=3
Environment:
WATCH_NAMESPACE:
POD_NAMESPACE: keda (v1:metadata.namespace)
KEDA_HTTP_DEFAULT_TIMEOUT: 3000
KEDA_HTTP_MIN_TLS_VERSION: TLS12
Mounts:
/certs from certificates (ro)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-psqzd (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
certificates:
Type: Secret (a volume populated by a Secret)
SecretName: kedaorg-certs
Optional: false
kube-api-access-psqzd:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: kubernetes.io/os=linux
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned keda/keda-operator-metrics-apiserver-7fd585f657-xjltw to ip-192-168-3-10.ap-northeast-2.compute.internal
Warning FailedMount 10m kubelet MountVolume.SetUp failed for volume "certificates" : failed to sync secret cache: timed out waiting for the condition
Warning FailedMount 10m (x4 over 10m) kubelet MountVolume.SetUp failed for volume "certificates" : secret "kedaorg-certs" not found
Normal Pulling 10m kubelet Pulling image "ghcr.io/kedacore/keda-metrics-apiserver:2.10.1"
Normal Pulled 10m kubelet Successfully pulled image "ghcr.io/kedacore/keda-metrics-apiserver:2.10.1" in 6.593596109s
Normal Created 10m kubelet Created container keda-operator-metrics-apiserver
Normal Started 10m kubelet Started container keda-operator-metrics-apiserver
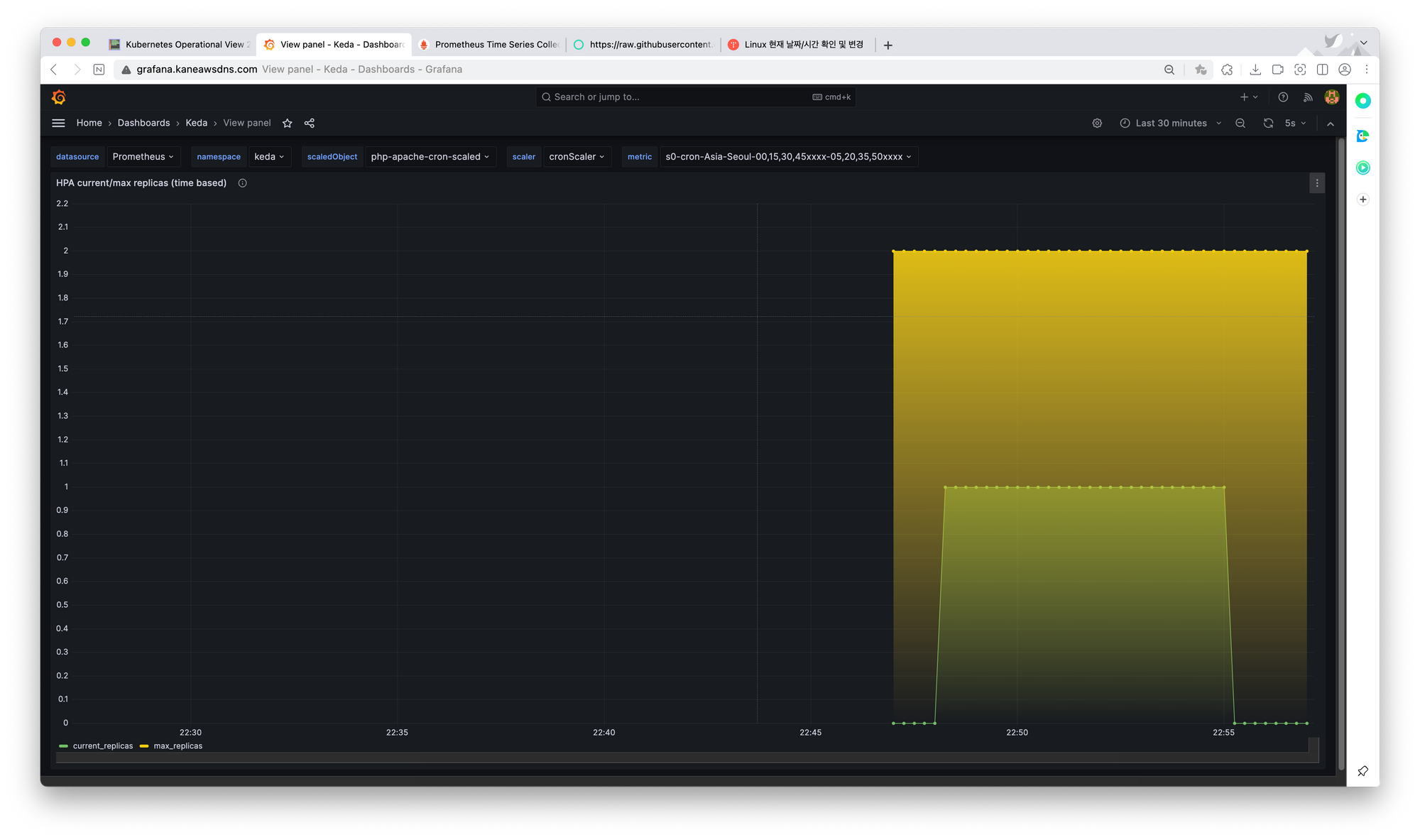
결과가 진행된 그라파나 대시보드 사진(50분전에 시작하고,,, 55분에 끝나는 조금 이상하지만?!) 암튼 이벤트기반으로 스케일링된다!
[도전과제2] KEDA 활용 : Karpenter + KEDA로 특정 시간에 AutoScaling - 링크 Youtube Airflow
→ 은행의 월요일아침, 이벤트 추첨시간 등 대규모 트래픽이 예상되는 시간에 KEDA를 통해, 오토스케일링
CA - Cluster Autoscaler(CAS)
CA는 노드의 리소스를 파악하고, 리소스 메트릭에 의해 트리거되어 노드를 스케일링한다. 오토스케일러 동작을 위해 별도의 디플로이를 배포해둔다. CA는 pending 상태의 파드가 존재할 경우, 워커노드를 스케일 아웃한다.
클라우드 플랫폼에서 주로 사용하고, 실제 노드 리소스가 없는 데 파드를 배포해야 하면 신규 워커노드를 추가한다. 온프라미스에선 적용하긴 힘들다.
실습진행
일부로 워커노드가 감당못하게 request를 500m = 0.5 코어로 할당 → 스케일링을 통해 15개로 늘림 → 노드 부족!
$**aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table**
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-c2c41e26-6213-a429-9a58-02374389d5c3 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
아래는 min, max, desired# autuscaler 권한 확인(관련 태그)
$aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh | grep autoscaler
- Key: k8s.io/cluster-autoscaler/enabled
- Key: k8s.io/cluster-autoscaler/myeks
- Key: k8s.io/cluster-autoscaler/enabled
- Key: k8s.io/cluster-autoscaler/myeks
- Key: k8s.io/cluster-autoscaler/myeks
- Key: k8s.io/cluster-autoscaler/enabled
# 아래의 테이블은 차례로, (min,max,desired)을 의미!
$aws autoscaling describe-auto-scaling-groups \
> --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
> --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-cec41f38-acab-b45a-0479-ca4ecb1586cc | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
$export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tay=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
# MaxSize 6개로 수정
$aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 정보 확인
$aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-cec41f38-acab-b45a-0479-ca4ecb1586cc | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
# 배포 : Deploy the Cluster Autoscaler (CA)
$curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
$sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
$kubectl apply -f cluster-autoscaler-autodiscover.yaml
serviceaccount/cluster-autoscaler created
clusterrole.rbac.authorization.k8s.io/cluster-autoscaler created
role.rbac.authorization.k8s.io/cluster-autoscaler created
clusterrolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
rolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
deployment.apps/cluster-autoscaler created
$kubectl get pod -n kube-system | grep cluster-autoscaler
cluster-autoscaler-74785c8d45-wrtjp 0/1 ContainerCreating 0 7s
$kubectl describe deployments.apps -n kube-system cluster-autoscaler
Name: cluster-autoscaler
Namespace: kube-system
CreationTimestamp: Sun, 21 May 2023 23:16:38 +0900
Labels: app=cluster-autoscaler
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=cluster-autoscaler
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=cluster-autoscaler
Annotations: prometheus.io/port: 8085
prometheus.io/scrape: true
Service Account: cluster-autoscaler
Containers:
cluster-autoscaler:
Image: registry.k8s.io/autoscaling/cluster-autoscaler:v1.26.2
Port: <none>
Host Port: <none>
Command:
./cluster-autoscaler
--v=4
--stderrthreshold=info
--cloud-provider=aws
--skip-nodes-with-local-storage=false
--expander=least-waste
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
Limits:
cpu: 100m
memory: 600Mi
Requests:
cpu: 100m
memory: 600Mi
Environment: <none>
Mounts:
/etc/ssl/certs/ca-certificates.crt from ssl-certs (ro)
Volumes:
ssl-certs:
Type: HostPath (bare host directory volume)
Path: /etc/ssl/certs/ca-bundle.crt
HostPathType:
Priority Class Name: system-cluster-critical
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: cluster-autoscaler-74785c8d45 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 18s deployment-controller Scaled up replica set cluster-autoscaler-74785c8d45 to 1
$kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"^C
$kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"^C
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
$kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
deployment.apps/cluster-autoscaler annotated테스트 진행, 파드 하나당 리소스 요청량을 크게 잡고, 스케일아웃하여 오토스케일링이 정상적으로 작동되나 확인
$cat <<EoF> nginx.yaml
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: nginx-to-scaleout
> spec:
> replicas: 1
> selector:
> matchLabels:
> app: nginx
> template:
> metadata:
> labels:
> service: nginx
> app: nginx
> spec:
> containers:
> - image: nginx
> name: nginx-to-scaleout
> resources:
> limits:
> cpu: 500m
> memory: 512Mi
> requests:
> cpu: 500m
> memory: 512Mi
> EoF
$kubectl apply -f nginx.yaml
deployment.apps/nginx-to-scaleout created
$kubectl get deployment/nginx-to-scaleout
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-to-scaleout 0/1 1 0 3s
# 파드 개수 증가
$kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
deployment.apps/nginx-to-scaleout scaled
Sun May 21 23:18:42 KST 2023
$kubectl get pods -l app=nginx -o wide --watch
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-to-scaleout-79df8996f6-2vjqm 1/1 Running 0 82s 192.168.3.11 ip-192-168-3-6.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-5pc5k 1/1 Running 0 82s 192.168.3.221 ip-192-168-3-6.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-5wvgl 1/1 Running 0 82s 192.168.2.172 ip-192-168-2-104.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-8bbc9 1/1 Running 0 82s 192.168.3.188 ip-192-168-3-10.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-9j5rx 1/1 Running 0 2m4s 192.168.3.88 ip-192-168-3-10.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-9kks9 1/1 Running 0 82s 192.168.1.166 ip-192-168-1-146.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-b5qmk 1/1 Running 0 82s 192.168.2.32 ip-192-168-2-104.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-c5hhq 1/1 Running 0 82s 192.168.1.127 ip-192-168-1-189.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-dzwsn 1/1 Running 0 82s 192.168.1.10 ip-192-168-1-146.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-nlnjq 1/1 Running 0 82s 192.168.2.253 ip-192-168-2-104.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-qmg8v 1/1 Running 0 82s 192.168.1.5 ip-192-168-1-189.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-rn7sw 1/1 Running 0 82s 192.168.1.130 ip-192-168-1-146.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-sd4rs 1/1 Running 0 82s 192.168.1.249 ip-192-168-1-189.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-wrw9d 1/1 Running 0 82s 192.168.3.91 ip-192-168-3-10.ap-northeast-2.compute.internal <none> <none>
nginx-to-scaleout-79df8996f6-wwz6f 1/1 Running 0 82s 192.168.3.121 ip-192-168-3-6.ap-northeast-2.compute.internal <none> <none>
# 노드가 추가적으로 붙는 모습, 관련된 eks-node-view, 그라파나 사진도 아래에 있습니다.
$kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-1-146.ap-northeast-2.compute.internal Ready <none> 38s v1.24.13-eks-0a21954
ip-192-168-1-189.ap-northeast-2.compute.internal Ready <none> 65m v1.24.13-eks-0a21954
ip-192-168-2-104.ap-northeast-2.compute.internal Ready <none> 65m v1.24.13-eks-0a21954
ip-192-168-3-10.ap-northeast-2.compute.internal Ready <none> 65m v1.24.13-eks-0a21954
ip-192-168-3-6.ap-northeast-2.compute.internal Ready <none> 37s v1.24.13-eks-0a21954
# 테이블로 확인
$aws autoscaling describe-auto-scaling-groups \
> --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
> --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-cec41f38-acab-b45a-0479-ca4ecb1586cc | 3 | 6 | 5 |
+------------------------------------------------+----+----+----+
$kubectl delete -f nginx.yaml && date
deployment.apps "nginx-to-scaleout" deleted
Sun May 21 23:21:27 KST 2023
# 자동으로 삭제되는 데, 시간이 10분이상 지체되어 삭제!파드의 개수를 증가하자, CPU 사용량 폭증
kube-ops-view에서도 할당못받는 파드를 확인가능
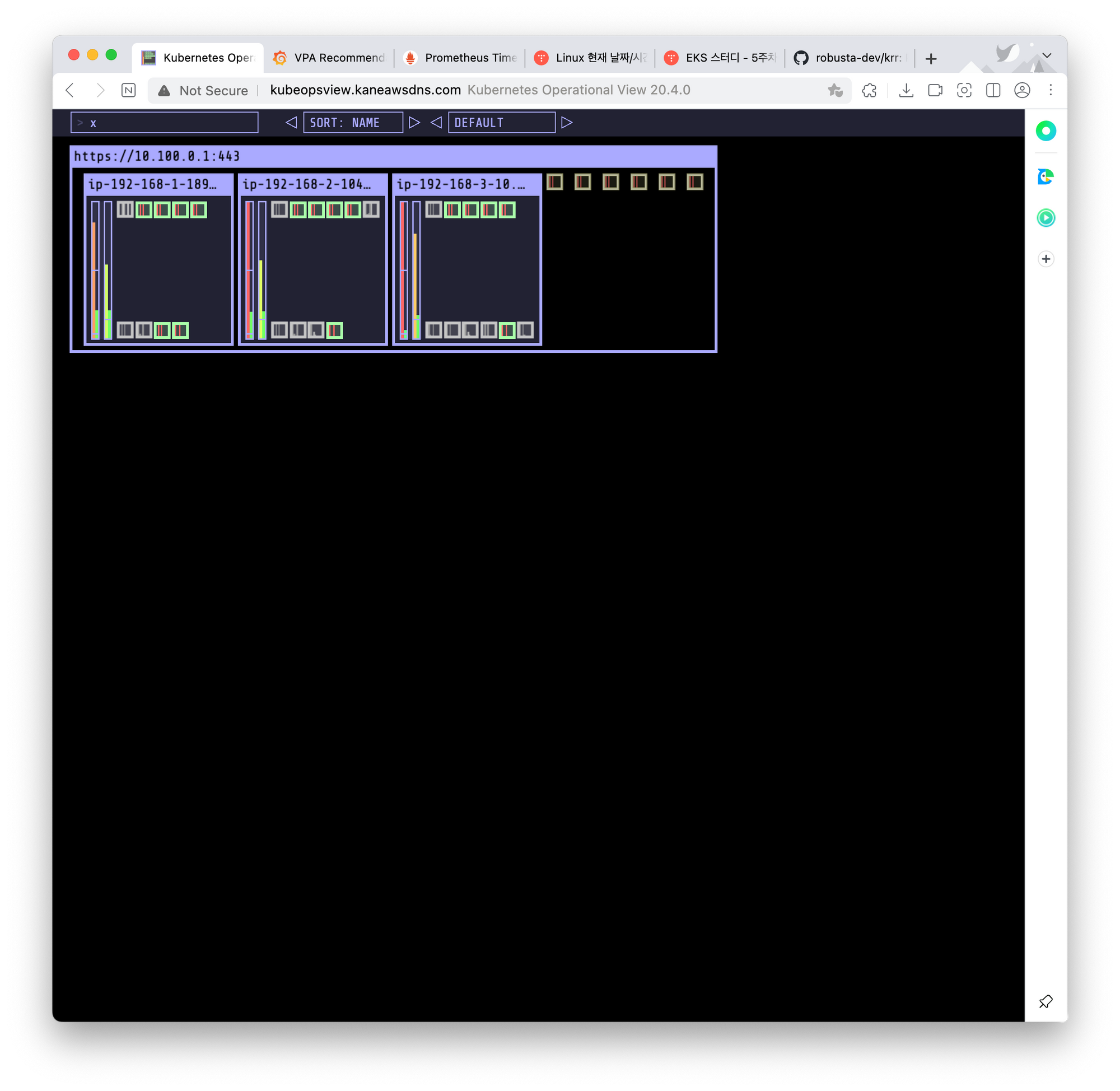
노드가 오토스케일링되어, 증가되는 것을 확인가능!
삭제 후 사용량이 작아진 모습

데몬셋도 적고, 여러 가지 노드의 기본적인 세팅이 별로 없어서 테스트 결과 빠르지만, 실제 운영환경에서는 빠르지 않음! → 자동으로 축소하는 10분정도로 시간도 느리다. (실제 환경이면 기본적으로 배포하는 것들이 많아 더 느리다고 한다.)
CPA - Cluster Proportional Autoscaler
coredns 파드와 같이 클러스터가 커질수록 부하가 증가하는 중요한 파드는 노드의 개수에 비례해서 파드를 오토스케일링한다. CPA는 노드 비례 파드 스케일링이다. 직접 규칙을 만들어서 정책을 수립한다. Metrics server 등을 사용하지 않고 kubapi server API를 사용합니다. 사용자 입장에서는 적절한 규칙만 세우면 된다.!
배포!
$helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
"cluster-proportional-autoscaler" already exists with the same configuration, skipping
# cluster-proportional-autoscaler 부터 배포!
$helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
Release "cluster-proportional-autoscaler" does not exist. Installing it now.
$cat <<EOT > cpa-nginx.yaml
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: nginx-deployment
> spec:
> replicas: 1
> selector:
> matchLabels:
> app: nginx
> template:
> metadata:
> labels:
> app: nginx
> spec:
> containers:
> - name: nginx
> image: nginx:latest
> resources:
> limits:
> cpu: "100m"
> memory: "64Mi"
> requests:
> cpu: "100m"
> memory: "64Mi"
> ports:
> - containerPort: 80
> EOT
$kubectl apply -f cpa-nginx.yaml
deployment.apps/nginx-deployment created
# 아래의 규칙 확인
$cat <<EOF > cpa-values.yaml
> config:
> ladder:
> nodesToReplicas:
> - [1, 1]
> - [2, 2]
> - [3, 3]
> - [4, 3]
> - [5, 5]
> options:
> namespace: default
> target: "deployment/nginx-deployment"
> EOF
$helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
NAME: cluster-proportional-autoscaler
LAST DEPLOYED: Sun May 21 23:57:59 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
autoscaler awscliv2.zip cpa-values.yaml externaldns.yaml irsa.yaml krew-linux_amd64.tar.gz kube-ps1 monitor-values.yaml precmd.yaml
aws cpa-nginx.yaml create-eks.log go krew-linux_amd64 kubectl LICENSE myeks.yaml yh-linux-amd64.zip
addon-resizer balancer builder charts cluster-autoscaler code-of-conduct.md CONTRIBUTING.md hack LICENSE OWNERS README.md SECURITY_CONTACTS vertical-pod-autoscaler
$helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
"cluster-proportional-autoscaler" already exists with the same configuration, skipping
$helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
Release "cluster-proportional-autoscaler" has been upgraded. Happy Helming!
NAME: cluster-proportional-autoscaler
LAST DEPLOYED: Sun May 21 23:59:35 2023
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: None
$helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
Release "cluster-proportional-autoscaler" has been upgraded. Happy Helming!
NAME: cluster-proportional-autoscaler
LAST DEPLOYED: Sun May 21 23:59:49 2023
NAMESPACE: default
STATUS: deployed
REVISION: 3
TEST SUITE: None
이제 노드를 증가시켜 테스트! 아래는 [노드, 파드] 테이블이다.
[1, 1], [2, 2], [3, 3], [4, 3], [5, 5]
$export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
# 노드 5개로 증가
$aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
$aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-cec41f38-acab-b45a-0479-ca4ecb1586cc | 5 | 5 | 5 |
+------------------------------------------------+----+----+----+
# 노드 3개
$k get no
NAME STATUS ROLES AGE VERSION
ip-192-168-1-146.ap-northeast-2.compute.internal Ready <none> 41m v1.24.13-eks-0a21954
ip-192-168-2-104.ap-northeast-2.compute.internal Ready <none> 105m v1.24.13-eks-0a21954
ip-192-168-3-6.ap-northeast-2.compute.internal Ready <none> 41m v1.24.13-eks-0a21954
# 파드 3개, [3,3] 규칙만족
$k get po
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-75bddf49cb-lwhxs 1/1 Running 0 2m46s
nginx-deployment-858477475d-8lj5g 1/1 Running 0 2m45s
nginx-deployment-858477475d-l8rsd 1/1 Running 0 2m45s
nginx-deployment-858477475d-z8jbb 1/1 Running 0 3m1s
# 노드를 5개로 스케일링, [5,5] 규칙확인
$k get no
NAME STATUS ROLES AGE VERSION
ip-192-168-1-146.ap-northeast-2.compute.internal Ready <none> 41m v1.24.13-eks-0a21954
ip-192-168-2-104.ap-northeast-2.compute.internal Ready <none> 106m v1.24.13-eks-0a21954
ip-192-168-2-217.ap-northeast-2.compute.internal Ready <none> 17s v1.24.13-eks-0a21954
ip-192-168-3-6.ap-northeast-2.compute.internal Ready <none> 41m v1.24.13-eks-0a21954
ip-192-168-3-76.ap-northeast-2.compute.internal NotReady <none> 6s v1.24.13-eks-0a21954
# 파드가 5개로 만족하는 것을 볼 수 있음
$k get po
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-75bddf49cb-lwhxs 1/1 Running 0 3m24s
nginx-deployment-858477475d-8lj5g 1/1 Running 0 3m23s
nginx-deployment-858477475d-jv2z6 1/1 Running 0 23s
nginx-deployment-858477475d-l8rsd 1/1 Running 0 3m23s
nginx-deployment-858477475d-rpd2s 1/1 Running 0 23s
nginx-deployment-858477475d-z8jbb 1/1 Running 0 3m39s
# 노드를 4개로 스케일링
$aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
# 노드 하나로 줄어서 이제 파드도 한개 줄어야함
# 죽지 않고, 스케줄불가 상태로 두면 알아서, [4,4] 규칙 만족
$k get no
NAME STATUS ROLES AGE VERSION
ip-192-168-1-146.ap-northeast-2.compute.internal Ready <none> 42m v1.24.13-eks-0a21954
ip-192-168-2-104.ap-northeast-2.compute.internal Ready,SchedulingDisabled <none> 107m v1.24.13-eks-0a21954
ip-192-168-2-217.ap-northeast-2.compute.internal Ready <none> 74s v1.24.13-eks-0a21954
ip-192-168-3-6.ap-northeast-2.compute.internal Ready <none> 42m v1.24.13-eks-0a21954
ip-192-168-3-76.ap-northeast-2.compute.internal Ready <none> 63s v1.24.13-eks-0a21954
$k get po
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-75bddf49cb-lwhxs 1/1 Running 0 4m6s
nginx-deployment-858477475d-jv2z6 1/1 Running 0 65s
nginx-deployment-858477475d-l8rsd 1/1 Running 0 4m5s
nginx-deployment-858477475d-z8jbb 1/1 Running 0 4m21s
# - [4, 3] 테이블 규칙 만족
$aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-cec41f38-acab-b45a-0479-ca4ecb1586cc | 4 | 4 | 4 |
+------------------------------------------------+----+----+----+
$helm uninstall cluster-proportional-autoscaler && kubectl delete -f cpa-nginx.yaml
release "cluster-proportional-autoscaler" uninstalled
deployment.apps "nginx-deployment" deleted
Karpenter 실습 환경 준비를 위해서 현재 EKS 실습 환경 전부 삭제
$helm uninstall -n kube-system kube-ops-view
release "kube-ops-view" uninstalled
$helm uninstall -n monitoring kube-prometheus-stack
release "kube-prometheus-stack" uninstalled
$eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAMEKarpenter : K8S Native AutoScaler & Fargate
Karpenter는 오픈소스 노드 수명주기 관리 솔루션으로, 기존 오토스케일링 툴과는 다르게 초단위로 컴퓨팅 리소스를 제공한다. 아래의 그림과 같이 기존의 오토스케일링에서 거치던 단계를 생략하기에 가능하다. 자세한 내용은 스터디원분의 블로그를 참고하면 된다.
linuxer 정태환님이 EKS Nodeless 컨셉을 정리해주셨다! 링크
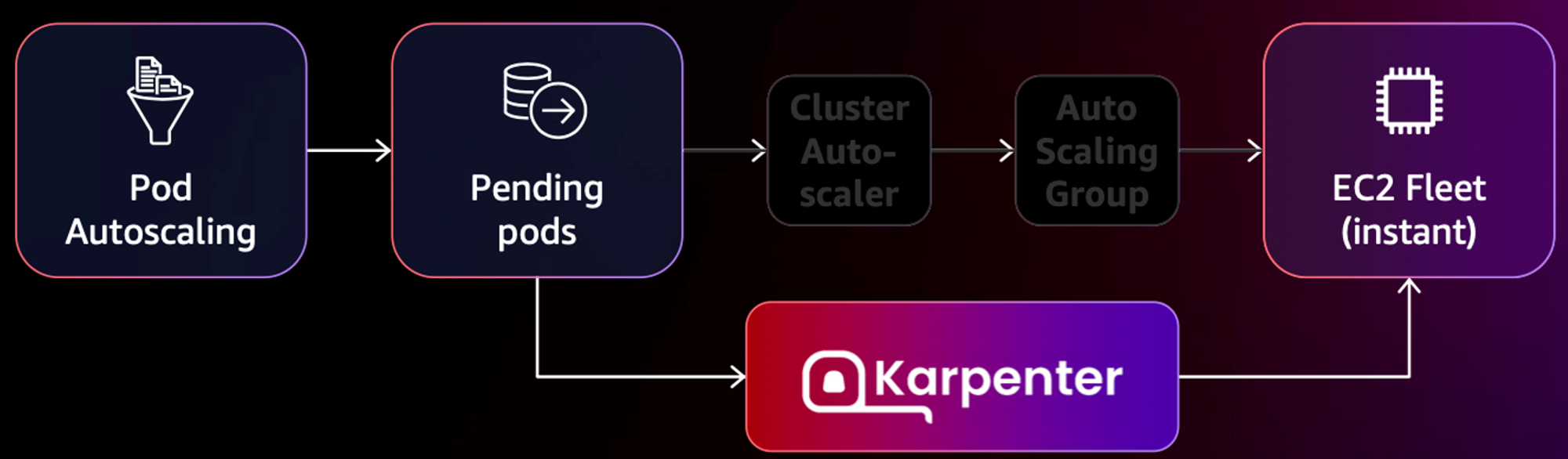
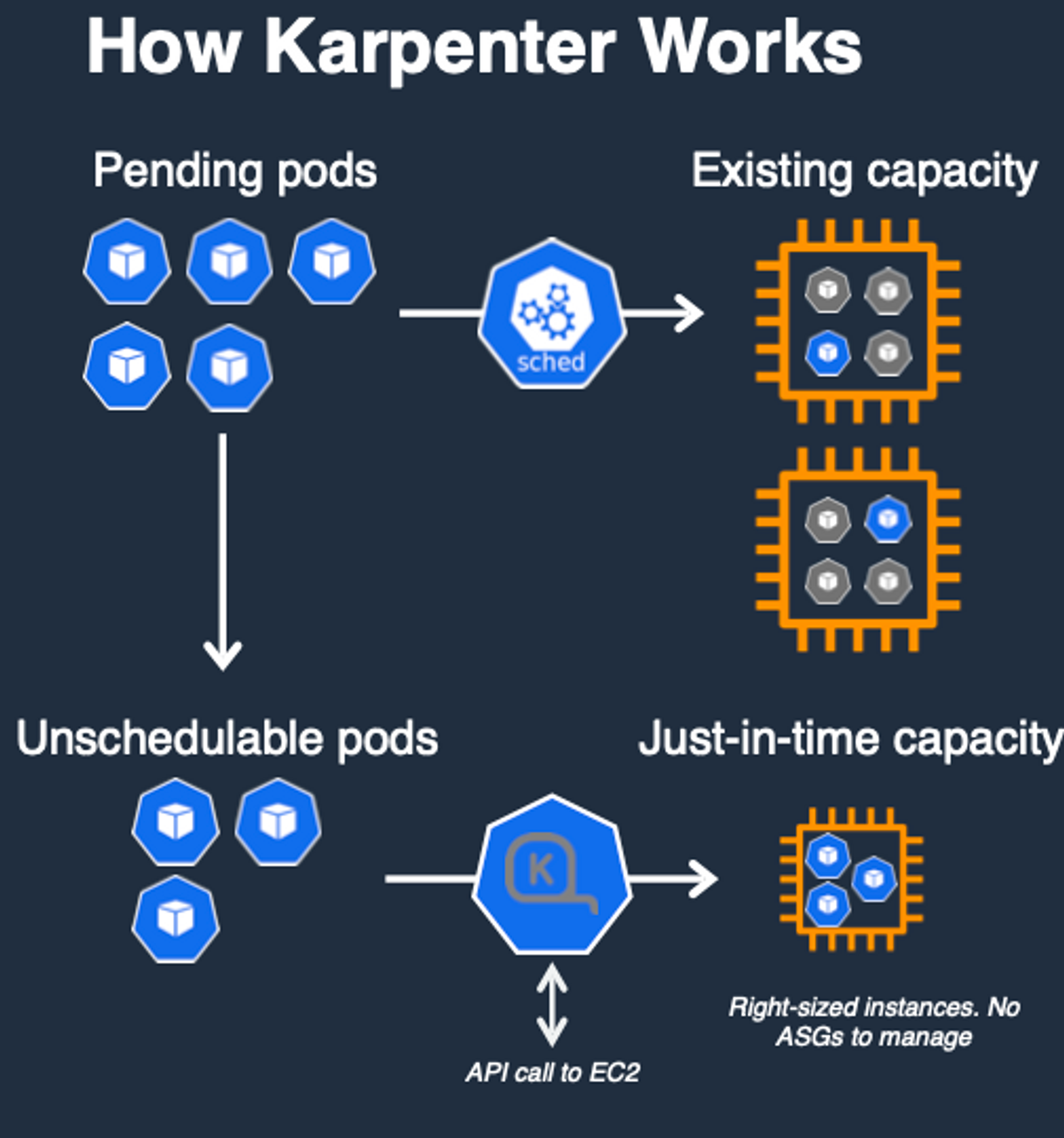
시간이 어느정도 걸려서 배포부터 진행 → 작업용 EC2만 만들어짐, 스택이름을 기존과 일부로 구분!
# 환경 변수 확인
$export | egrep 'ACCOUNT|AWS_|CLUSTER' | egrep -v 'SECRET|KEY'
declare -x ACCOUNT_ID="871103481195"
declare -x AWS_ACCOUNT_ID="871103481195"
declare -x AWS_DEFAULT_REGION="ap-northeast-2"
declare -x AWS_PAGER=""
declare -x AWS_REGION="ap-northeast-2"
declare -x CLUSTER_NAME="myeks2"
# 환경변수 설정
$export KARPENTER_VERSION=v0.27.5
$export TEMPOUT=$(mktemp)
$echo $KARPENTER_VERSION $CLUSTER_NAME $AWS_DEFAULT_REGION $AWS_ACCOUNT_ID $TEMPOUT
v0.27.5 myeks2 ap-northeast-2 871103481195 /tmp/tmp.X5iRenSltU
# CloudFormation 스택으로 IAM Policy, Role, EC2 Instance Profile 생성 : 3분 정도 소요
$curl -fsSL https://karpenter.sh/"${KARPENTER_VERSION}"/getting-started/getting-started-with-karpenter/cloudformation.yaml > $TEMPOUT \
> && aws cloudformation deploy \
> --stack-name "Karpenter-${CLUSTER_NAME}" \
> --template-file "${TEMPOUT}" \
> --capabilities CAPABILITY_NAMED_IAM \
> --parameter-overrides "ClusterName=${CLUSTER_NAME}"
Waiting for changeset to be created..
No changes to deploy. Stack Karpenter-myeks2 is up to date
클러스터 생성
- 배포 파일
eksctl create cluster -f - <<EOF --- apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: ${CLUSTER_NAME} region: ${AWS_DEFAULT_REGION} version: "1.24" tags: karpenter.sh/discovery: ${CLUSTER_NAME} iam: withOIDC: true serviceAccounts: - metadata: name: karpenter namespace: karpenter roleName: ${CLUSTER_NAME}-karpenter attachPolicyARNs: - arn:aws:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME} roleOnly: true iamIdentityMappings: - arn: "arn:aws:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}" username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes managedNodeGroups: - instanceType: m5.large amiFamily: AmazonLinux2 name: ${CLUSTER_NAME}-ng desiredCapacity: 2 minSize: 1 maxSize: 10 iam: withAddonPolicies: externalDNS: true ## Optionally run on fargate # fargateProfiles: # - name: karpenter # selectors: # - namespace: karpenter EOF
클러스터 생성 확인
# 클러스터 생성 완료, eks 배포 확인
$eksctl get cluster
NAME REGION EKSCTL CREATED
myeks2 ap-northeast-2 True
$eksctl get nodegroup --cluster $CLUSTER_NAME
CLUSTER NODEGROUP STATUS CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID ASG NAME TYPE
myeks2 myeks2-ng ACTIVE 2023-05-22T10:04:38Z 1 10 2 m5.large AL2_x86_64 eks-myeks2-ng-56c42175-7bbd-1c3a-4e92-b89992023b8c managed
$eksctl get iamidentitymapping --cluster $CLUSTER_NAME
ARN USERNAME GROUPS ACCOUNT
arn:aws:iam::871103481195:role/KarpenterNodeRole-myeks2 system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
arn:aws:iam::871103481195:role/eksctl-myeks2-nodegroup-myeks2-ng-NodeInstanceRole-1B2P33I00KCYF system:node:{{EC2PrivateDNSName}} system:bootstrappers,system:nodes
$eksctl get iamserviceaccount --cluster $CLUSTER_NAME
NAMESPACE NAME ROLE ARN
karpenter karpenter arn:aws:iam::871103481195:role/myeks2-karpenter
kube-system aws-node arn:aws:iam::871103481195:role/eksctl-myeks2-addon-iamserviceaccount-kube-s-Role1-18H2GYOABHE8X
# $eksctl get addon --cluster $CLUSTER_NAME
# 2023-05-22 20:41:43 [ℹ] Kubernetes version "1.24" in use by cluster "myeks2"
# 2023-05-22 20:41:43 [ℹ] getting all addons
# No addons found
# kubernetes cluster 정보 확인
$kubectl cluster-info
Kubernetes control plane is running at https://AC31499751431C8E285778113EC3F0B3.gr7.ap-northeast-2.eks.amazonaws.com
CoreDNS is running at https://AC31499751431C8E285778113EC3F0B3.gr7.ap-northeast-2.eks.amazonaws.com/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE CAPACITYTYPE ZONE
ip-192-168-30-154.ap-northeast-2.compute.internal Ready <none> 96m v1.24.13-eks-0a21954 m5.large ON_DEMAND ap-northeast-2a
ip-192-168-86-220.ap-northeast-2.compute.internal Ready <none> 96m v1.24.13-eks-0a21954 m5.large ON_DEMAND ap-northeast-2c
$kubectl get pod -n kube-system -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aws-node-9fh2n 1/1 Running 0 96m 192.168.86.220 ip-192-168-86-220.ap-northeast-2.compute.internal <none> <none>
aws-node-tk9mc 1/1 Running 0 96m 192.168.30.154 ip-192-168-30-154.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-98j9g 1/1 Running 0 104m 192.168.26.223 ip-192-168-30-154.ap-northeast-2.compute.internal <none> <none>
coredns-dc4979556-lw7gf 1/1 Running 0 104m 192.168.6.105 ip-192-168-30-154.ap-northeast-2.compute.internal <none> <none>
kube-proxy-gzs29 1/1 Running 0 96m 192.168.86.220 ip-192-168-86-220.ap-northeast-2.compute.internal <none> <none>
kube-proxy-hlnpt 1/1 Running 0 96m 192.168.30.154 ip-192-168-30-154.ap-northeast-2.compute.internal <none> <none>
$kubectl describe cm -n kube-system aws-auth
Name: aws-auth
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
## 주요
rolearn: arn:aws:iam::871103481195:role/KarpenterNodeRole-myeks2
username: system:node:{{EC2PrivateDNSName}}
- groups:
- system:bootstrappers
- system:nodes
## 주요
rolearn: arn:aws:iam::871103481195:role/eksctl-myeks2-nodegroup-myeks2-ng-NodeInstanceRole-1B2P33I00KCYF
username: system:node:{{EC2PrivateDNSName}}
mapUsers:
----
[]
BinaryData
====
Events: <none>
카펜터 설치!
# 설정 변수 대입
$export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)"
$export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
$echo $CLUSTER_ENDPOINT $KARPENTER_IAM_ROLE_ARN
https://AC31499751431C8E285778113EC3F0B3.gr7.ap-northeast-2.eks.amazonaws.com arn:aws:iam::871103481195:role/myeks2-karpenter
# IAM 생성
$aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
{
"Role": {
"Path": "/aws-service-role/spot.amazonaws.com/",
"RoleName": "AWSServiceRoleForEC2Spot",
"RoleId": "AROA4VUOQIVVYLQHDALB7",
"Arn": "arn:aws:iam::871103481195:role/aws-service-role/spot.amazonaws.com/AWSServiceRoleForEC2Spot",
"CreateDate": "2023-05-22T11:42:43+00:00",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"sts:AssumeRole"
],
"Effect": "Allow",
"Principal": {
"Service": [
"spot.amazonaws.com"
]
}
}
]
}
}
}
# docker logout : Logout of docker to perform an unauthenticated pull against the public ECR
$docker logout public.ecr.aws
Removing login credentials for public.ecr.aws
# karpenter 설치
$helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} --namespace karpenter --create-namespace \
> --set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \
> --set settings.aws.clusterName=${CLUSTER_NAME} \
> --set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME} \
> --set settings.aws.interruptionQueueName=${CLUSTER_NAME} \
> --set controller.resources.requests.cpu=1 \
> --set controller.resources.requests.memory=1Gi \
> --set controller.resources.limits.cpu=1 \
> --set controller.resources.limits.memory=1Gi \
> --wait
Release "karpenter" does not exist. Installing it now.
Pulled: public.ecr.aws/karpenter/karpenter:v0.27.5
Digest: sha256:9491ba645592ab9485ca8ce13f53193826044522981d75975897d229b877d4c2
NAME: karpenter
LAST DEPLOYED: Mon May 22 20:42:54 2023
NAMESPACE: karpenter
STATUS: deployed
REVISION: 1
TEST SUITE: None
# karpenter 설치 확인
$kubectl get-all -n karpenter
NAME NAMESPACE AGE
configmap/config-logging karpenter 17s
configmap/karpenter-global-settings karpenter 17s
configmap/kube-root-ca.crt karpenter 17s
endpoints/karpenter karpenter 17s
pod/karpenter-6c6bdb7766-2kq5b karpenter 16s
pod/karpenter-6c6bdb7766-bj6nn karpenter 16s
secret/karpenter-cert karpenter 17s
secret/sh.helm.release.v1.karpenter.v1 karpenter 17s
serviceaccount/default karpenter 17s
serviceaccount/karpenter karpenter 17s
service/karpenter karpenter 17s
deployment.apps/karpenter karpenter 17s
replicaset.apps/karpenter-6c6bdb7766 karpenter 17s
lease.coordination.k8s.io/karpenter-leader-election karpenter 8s
endpointslice.discovery.k8s.io/karpenter-mt5ph karpenter 17s
poddisruptionbudget.policy/karpenter karpenter 17s
rolebinding.rbac.authorization.k8s.io/karpenter karpenter 17s
role.rbac.authorization.k8s.io/karpenter karpenter 17s
$kubectl get cm -n karpenter karpenter-global-settings -o jsonpath={.data} | jq
{
"aws.clusterEndpoint": "",
"aws.clusterName": "myeks2",
"aws.defaultInstanceProfile": "KarpenterNodeInstanceProfile-myeks2",
"aws.enableENILimitedPodDensity": "true",
"aws.enablePodENI": "false",
"aws.interruptionQueueName": "myeks2",
"aws.isolatedVPC": "false",
"aws.nodeNameConvention": "ip-name",
"aws.vmMemoryOverheadPercent": "0.075",
"batchIdleDuration": "1s",
"batchMaxDuration": "10s",
"featureGates.driftEnabled": "false"
}
$kubectl get crd | grep karpenter
awsnodetemplates.karpenter.k8s.aws 2023-05-22T11:42:54Z
provisioners.karpenter.sh 2023-05-22T11:42:54Z
Create Provisioner : 관리 리소스는 securityGroupSelector and subnetSelector 로 찾음, ttlSecondsAfterEmpty(미사용 노드 정리, 데몬셋 제외)
provisioner install
$cat <<EOF | kubectl apply -f -
> apiVersion: karpenter.sh/v1alpha5
> kind: Provisioner
> metadata:
> name: default
> spec:
> requirements:
> - key: karpenter.sh/capacity-type
> operator: In
> values: ["spot"]
> limits:
> resources:
> cpu: 1000
> providerRef:
> name: default
> ttlSecondsAfterEmpty: 30
> ---
> apiVersion: karpenter.k8s.aws/v1alpha1
> kind: AWSNodeTemplate
> metadata:
> name: default
> spec:
> subnetSelector:
> karpenter.sh/discovery: ${CLUSTER_NAME}
> securityGroupSelector:
> karpenter.sh/discovery: ${CLUSTER_NAME}
> EOF
provisioner.karpenter.sh/default created
awsnodetemplate.karpenter.k8s.aws/default created
provisioners 설치 확인
$kubectl get awsnodetemplates,provisioners
NAME AGE
awsnodetemplate.karpenter.k8s.aws/default 9s
NAME AGE
provisioner.karpenter.sh/default 9s
external dns, kube-ops-view, 그라파나, 프로메테우스 설치!
$helm repo add grafana-charts https://grafana.github.io/helm-charts
"grafana-charts" has been added to your repositories
$helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
$helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "grafana-charts" chart repository
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
$kubectl create namespace monitoring
namespace/monitoring created
$curl -fsSL https://karpenter.sh/"${KARPENTER_VERSION}"/getting-started/getting-started-with-karpenter/prometheus-values.yaml | tee prometheus-values.yaml
alertmanager:
persistentVolume:
enabled: false
server:
fullnameOverride: prometheus-server
persistentVolume:
enabled: false
extraScrapeConfigs: |
- job_name: karpenter
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- karpenter
relabel_configs:
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: http-metrics
action: keep
$helm install --namespace monitoring prometheus prometheus-community/prometheus --values prometheus-values.yaml --set alertmanager.enabled=false
NAME: prometheus
LAST DEPLOYED: Mon May 22 20:44:27 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The Prometheus server can be accessed via port 80 on the following DNS name from within your cluster:
prometheus-server.monitoring.svc.cluster.local
Get the Prometheus server URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9090
#################################################################################
###### WARNING: Persistence is disabled!!! You will lose your data when #####
###### the Server pod is terminated. #####
#################################################################################
#################################################################################
###### WARNING: Pod Security Policy has been disabled by default since #####
###### it deprecated after k8s 1.25+. use #####
###### (index .Values "prometheus-node-exporter" "rbac" #####
###### . "pspEnabled") with (index .Values #####
###### "prometheus-node-exporter" "rbac" "pspAnnotations") #####
###### in case you still need it. #####
#################################################################################
The Prometheus PushGateway can be accessed via port 9091 on the following DNS name from within your cluster:
prometheus-prometheus-pushgateway.monitoring.svc.cluster.local
Get the PushGateway URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus-pushgateway,component=pushgateway" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9091
For more information on running Prometheus, visit:
https://prometheus.io/
$curl -fsSL https://karpenter.sh/"${KARPENTER_VERSION}"/getting-started/getting-started-with-karpenter/grafana-values.yaml | tee grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
version: 1
url: http://prometheus-server:80
access: proxy
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
capacity-dashboard:
url: https://karpenter.sh/v0.27.5/getting-started/getting-started-with-karpenter/karpenter-capacity-dashboard.json
performance-dashboard:
url: https://karpenter.sh/v0.27.5/getting-started/getting-started-with-karpenter/karpenter-performance-dashboard.json
$helm install --namespace monitoring grafana grafana-charts/grafana --values grafana-values.yaml --set service.type=LoadBalancer
NAME: grafana
LAST DEPLOYED: Mon May 22 20:44:35 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.monitoring.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status of by running 'kubectl get svc --namespace monitoring -w grafana'
export SERVICE_IP=$(kubectl get svc --namespace monitoring grafana -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
http://$SERVICE_IP:80
3. Login with the password from step 1 and the username: admin
#################################################################################
###### WARNING: Persistence is disabled!!! You will lose your data when #####
###### the Grafana pod is terminated. #####
#################################################################################
$kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
rPBZBl47fe72XObwGKsXNYtvkGGEWA8FCFYXujwC
$MyDomain=kaneawsdns.com
$echo "export MyDomain=kaneawsdns.com" >> /etc/profile
$MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "${MyDomain}." --query "HostedZones[0].Id" --output text)
$echo $MyDomain, $MyDnzHostedZoneId
kaneawsdns.com, /hostedzone/Z06702063E7RRITLLMJRM
$curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml
$MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst < externaldns.yaml | kubectl apply -f -
serviceaccount/external-dns created
clusterrole.rbac.authorization.k8s.io/external-dns created
clusterrolebinding.rbac.authorization.k8s.io/external-dns-viewer created
deployment.apps/external-dns created
$kubectl annotate service grafana -n monitoring "external-dns.alpha.kubernetes.io/hostname=grafana.$MyDomain"
service/grafana annotated
$echo -e "grafana URL = http://grafana.$MyDomain"
grafana URL = http://grafana.kaneawsdns.com
#kube-ops-view install
$helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
"geek-cookbook" has been added to your repositories
$helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
NAME: kube-ops-view
LAST DEPLOYED: Mon May 22 20:47:00 2023
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace kube-system -l "app.kubernetes.io/name=kube-ops-view,app.kubernetes.io/instance=kube-ops-view" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:8080
$kubectl patch svc -n kube-system kube-ops-view -p '{"spec":{"type":"LoadBalancer"}}'
service/kube-ops-view patched
$kubectl annotate service kube-ops-view -n kube-system "external-dns.alpha.kubernetes.io/hostname=kubeopsview.$MyDomain"
service/kube-ops-view annotated
$echo -e "Kube Ops View URL = http://kubeopsview.$MyDomain:8080/#scale=1.5"
Kube Ops View URL = http://kubeopsview.kaneawsdns.com:8080/#scale=1.5
$kubectl get awsnodetemplates,provisioners
NAME AGE
awsnodetemplate.karpenter.k8s.aws/default 3m40s
NAME AGE
provisioner.karpenter.sh/default 3m40s
테스트 실시!
파드 한 개당 요구량을 1코어로 두고, 이후 증가시켜 오토스케일링 확인
# pause 파드 1개에 CPU 1개 최소 보장 할당
$cat <<EOF | kubectl apply -f -
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: inflate
> spec:
> replicas: 0
> selector:
> matchLabels:
> app: inflate
> template:
> metadata:
> labels:
> app: inflate
> spec:
> terminationGracePeriodSeconds: 0
> containers:
> - name: inflate
> image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
> resources:
> requests:
> cpu: 1
> EOF
deployment.apps/inflate created
# 파드 개수 증가!
$kubectl scale deployment inflate --replicas 5
deployment.apps/inflate scaled
$kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
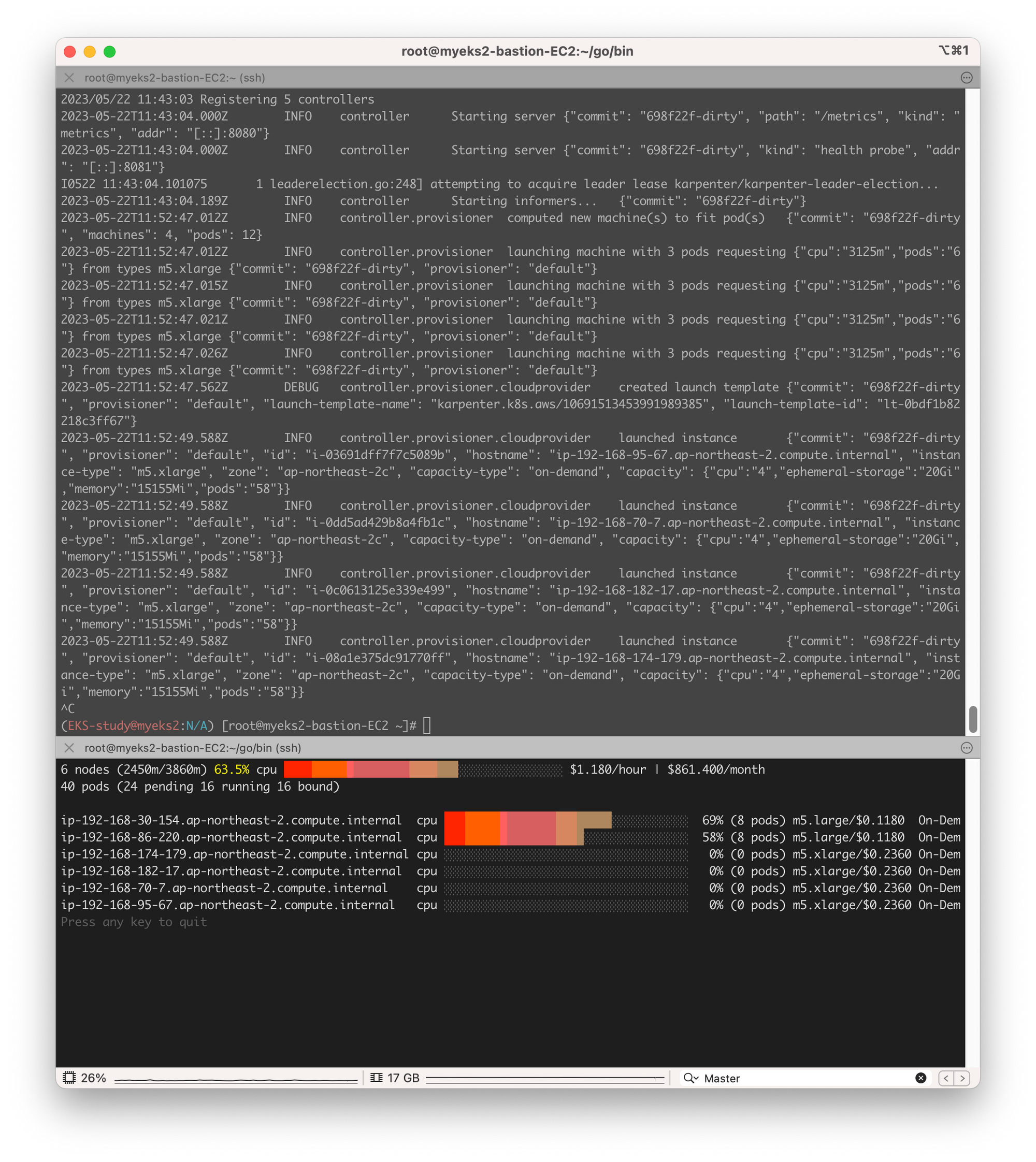
2023-05-22T11:43:55.652Z DEBUG controller.deprovisioning discovered instance types {"commit": "698f22f-dirty", "count": 366}
2023-05-22T11:43:55.743Z DEBUG controller.deprovisioning discovered offerings for instance types {"commit": "698f22f-dirty", "zones": ["ap-northeast-2a", "ap-northeast-2c", "ap-northeast-2d"], "instance-type-count": 367, "node-template": "default"}
2023-05-22T11:48:08.748Z INFO controller.provisioner found provisionable pod(s) {"commit": "698f22f-dirty", "pods": 5}
2023-05-22T11:48:08.748Z INFO controller.provisioner computed new machine(s) to fit pod(s) {"commit": "698f22f-dirty", "machines": 1, "pods": 5}
2023-05-22T11:48:08.749Z INFO controller.provisioner launching machine with 5 pods requesting {"cpu":"5125m","pods":"8"} from types c6i.2xlarge, c6i.24xlarge, r5ad.24xlarge, r6i.24xlarge, r5.24xlarge and 135 other(s) {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:48:09.106Z DEBUG controller.provisioner.cloudprovider discovered kubernetes version {"commit": "698f22f-dirty", "provisioner": "default", "kubernetes-version": "1.24"}
2023-05-22T11:48:09.136Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-0fa3b31d56b9a36b2", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2/recommended/image_id"}
2023-05-22T11:48:09.163Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-021b63322f1c5fc23", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2-gpu/recommended/image_id"}
2023-05-22T11:48:09.173Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-0a31a3ce85ee4a8e6", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2-arm64/recommended/image_id"}
2023-05-22T11:48:09.311Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/16624063517551845275", "launch-template-id": "lt-0458277a0a9530173"}
2023-05-22T11:43:03.998Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-22T11:43:03.999Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/22 11:43:03 Registering 2 clients
2023/05/22 11:43:03 Registering 2 informer factories
2023/05/22 11:43:03 Registering 3 informers
2023/05/22 11:43:03 Registering 5 controllers
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0522 11:43:04.101075 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-22T11:43:04.189Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-22T11:48:11.910Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0f03bf23055b38747", "hostname": "ip-192-168-188-148.ap-northeast-2.compute.internal", "instance-type": "c4.2xlarge", "zone": "ap-northeast-2c", "capacity-type": "spot", "capacity": {"cpu":"8","ephemeral-storage":"20Gi","memory":"14208Mi","pods":"58"}}
$kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type,node.kubernetes.io/instance-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE CAPACITY-TYPE INSTANCE-TYPE
ip-192-168-188-148.ap-northeast-2.compute.internal NotReady <none> 26s v1.24.13-eks-0a21954 spot c4.2xlarge
ip-192-168-30-154.ap-northeast-2.compute.internal Ready <none> 102m v1.24.13-eks-0a21954 ON_DEMAND m5.large
ip-192-168-86-220.ap-northeast-2.compute.internal Ready <none> 102m v1.24.13-eks-0a21954 ON_DEMAND m5.large
$k get po -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default inflate-ccf449f59-cswnb 0/1 ContainerCreating 0 41s
default inflate-ccf449f59-m5cq6 0/1 ContainerCreating 0 41s
default inflate-ccf449f59-t5fxt 0/1 ContainerCreating 0 41s
default inflate-ccf449f59-tl79k 0/1 ContainerCreating 0 41s
default inflate-ccf449f59-wtk4l 0/1 ContainerCreating 0 41s
karpenter karpenter-6c6bdb7766-2kq5b 1/1 Running 0 5m52s
karpenter karpenter-6c6bdb7766-bj6nn 1/1 Running 0 5m52s
kube-system aws-node-9fh2n 1/1 Running 0 102m
kube-system aws-node-dmzdv 0/1 Running 0 37s
kube-system aws-node-tk9mc 1/1 Running 0 102m
kube-system coredns-dc4979556-98j9g 1/1 Running 0 111m
kube-system coredns-dc4979556-lw7gf 1/1 Running 0 111m
kube-system external-dns-cc5c8cd74-v4frr 1/1 Running 0 2m55s
kube-system kube-ops-view-558d87b798-z4wng 1/1 Running 0 107s
kube-system kube-proxy-gzs29 1/1 Running 0 102m
kube-system kube-proxy-hlnpt 1/1 Running 0 102m
kube-system kube-proxy-xb2hs 1/1 Running 0 37s
monitoring grafana-b488f8cdb-8mwn5 1/1 Running 0 4m11s
monitoring prometheus-kube-state-metrics-6fcf5978bf-rzbh8 1/1 Running 0 4m20s
monitoring prometheus-prometheus-node-exporter-jpfgq 1/1 Running 0 36s
monitoring prometheus-prometheus-node-exporter-r8vqh 1/1 Running 0 4m20s
monitoring prometheus-prometheus-node-exporter-vwsk9 1/1 Running 0 4m19s
monitoring prometheus-prometheus-pushgateway-fdb75d75f-jdbhr 1/1 Running 0 4m20s
monitoring prometheus-server-6f974fdfd-l7rv7 2/2 Running 0 4m20sAWS 자원 확인
- AWS 자원 확인
$aws ec2 describe-spot-instance-requests --filters "Name=state,Values=active" --output table ------------------------------------------------------------------------------------------------------ | DescribeSpotInstanceRequests | +----------------------------------------------------------------------------------------------------+ || SpotInstanceRequests || |+--------------------------------------------------+-----------------------------------------------+| || CreateTime | 2023-05-22T11:48:11+00:00 || || InstanceId | i-0f03bf23055b38747 || || InstanceInterruptionBehavior | terminate || || LaunchedAvailabilityZone | ap-northeast-2c || || ProductDescription | Linux/UNIX || || SpotInstanceRequestId | sir-q2r6k2vp || || SpotPrice | 0.454000 || || State | active || || Type | one-time || |+--------------------------------------------------+-----------------------------------------------+| ||| LaunchSpecification ||| ||+------------------------------------+-----------------------------------------------------------+|| ||| ImageId | ami-0fa3b31d56b9a36b2 ||| ||| InstanceType | c4.2xlarge ||| ||+------------------------------------+-----------------------------------------------------------+|| |||| BlockDeviceMappings |||| |||+------------------------------------------------+---------------------------------------------+||| |||| DeviceName | /dev/xvda |||| |||+------------------------------------------------+---------------------------------------------+||| ||||| Ebs ||||| ||||+--------------------------------------------------------------------+-----------------------+|||| ||||| DeleteOnTermination | True ||||| ||||| Encrypted | True ||||| ||||| VolumeSize | 20 ||||| ||||| VolumeType | gp3 ||||| ||||+--------------------------------------------------------------------+-----------------------+|||| |||| IamInstanceProfile |||| |||+-------+--------------------------------------------------------------------------------------+||| |||| Arn | arn:aws:iam::871103481195:instance-profile/KarpenterNodeInstanceProfile-myeks2 |||| |||| Name | KarpenterNodeInstanceProfile-myeks2 |||| |||+-------+--------------------------------------------------------------------------------------+||| |||| Monitoring |||| |||+---------------------------------------------------+------------------------------------------+||| |||| Enabled | False |||| |||+---------------------------------------------------+------------------------------------------+||| |||| NetworkInterfaces |||| |||+-----------------------------------------+----------------------------------------------------+||| |||| DeleteOnTermination | True |||| |||| DeviceIndex | 0 |||| |||| SubnetId | subnet-04e3bff3afc9245a6 |||| |||+-----------------------------------------+----------------------------------------------------+||| |||| Placement |||| |||+-----------------------------------------------+----------------------------------------------+||| |||| AvailabilityZone | ap-northeast-2c |||| |||| Tenancy | default |||| |||+-----------------------------------------------+----------------------------------------------+||| |||| SecurityGroups |||| |||+-----------------------+----------------------------------------------------------------------+||| |||| GroupId | GroupName |||| |||+-----------------------+----------------------------------------------------------------------+||| |||| sg-0ba1ccd4016a58521 | eksctl-myeks2-cluster-ControlPlaneSecurityGroup-WNSB7WW4HLIF |||| |||| sg-0317cb7e7df34881a | eksctl-myeks2-cluster-ClusterSharedNodeSecurityGroup-1VRI6GJ40ZT7A |||| |||+-----------------------+----------------------------------------------------------------------+||| ||| Status ||| ||+--------------------------+---------------------------------------------------------------------+|| ||| Code | fulfilled ||| ||| Message | Your Spot request is fulfilled. ||| ||| UpdateTime | 2023-05-22T11:48:22+00:00 ||| ||+--------------------------+---------------------------------------------------------------------+|| $kubectl get node -l karpenter.sh/capacity-type=spot -o jsonpath='{.items[0].metadata.labels}' | jq { "beta.kubernetes.io/arch": "amd64", "beta.kubernetes.io/os": "linux", "k8s.io/cloud-provider-aws": "35a3405a9b5c02025fe6ff647a94190b", "karpenter.k8s.aws/instance-ami-id": "ami-0fa3b31d56b9a36b2", "karpenter.k8s.aws/instance-category": "c", "karpenter.k8s.aws/instance-cpu": "8", "karpenter.k8s.aws/instance-encryption-in-transit-supported": "false", "karpenter.k8s.aws/instance-family": "c4", "karpenter.k8s.aws/instance-generation": "4", "karpenter.k8s.aws/instance-hypervisor": "xen", "karpenter.k8s.aws/instance-memory": "15360", "karpenter.k8s.aws/instance-network-bandwidth": "2500", "karpenter.k8s.aws/instance-pods": "58", "karpenter.k8s.aws/instance-size": "2xlarge", "karpenter.sh/capacity-type": "spot", "karpenter.sh/provisioner-name": "default", "kubernetes.io/arch": "amd64", "kubernetes.io/os": "linux", "node.kubernetes.io/instance-type": "c4.2xlarge", "topology.kubernetes.io/region": "ap-northeast-2", "topology.kubernetes.io/zone": "ap-northeast-2c" }
테스트 종료
$kubectl delete deployment inflate
deployment.apps "inflate" deleted
$kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-22T11:43:03.998Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-22T11:43:03.999Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/22 11:43:03 Registering 2 clients
2023/05/22 11:43:03 Registering 2 informer factories
2023/05/22 11:43:03 Registering 3 informers
2023/05/22 11:43:03 Registering 5 controllers
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0522 11:43:04.101075 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-22T11:43:04.189Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-22T11:48:09.106Z DEBUG controller.provisioner.cloudprovider discovered kubernetes version {"commit": "698f22f-dirty", "provisioner": "default", "kubernetes-version": "1.24"}
2023-05-22T11:48:09.136Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-0fa3b31d56b9a36b2", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2/recommended/image_id"}
2023-05-22T11:48:09.163Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-021b63322f1c5fc23", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2-gpu/recommended/image_id"}
2023-05-22T11:48:09.173Z DEBUG controller.provisioner.cloudprovider discovered ami {"commit": "698f22f-dirty", "provisioner": "default", "ami": "ami-0a31a3ce85ee4a8e6", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2-arm64/recommended/image_id"}
2023-05-22T11:48:09.311Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/16624063517551845275", "launch-template-id": "lt-0458277a0a9530173"}
2023-05-22T11:48:11.910Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0f03bf23055b38747", "hostname": "ip-192-168-188-148.ap-northeast-2.compute.internal", "instance-type": "c4.2xlarge", "zone": "ap-northeast-2c", "capacity-type": "spot", "capacity": {"cpu":"8","ephemeral-storage":"20Gi","memory":"14208Mi","pods":"58"}}
2023-05-22T11:50:24.721Z DEBUG controller.node added TTL to empty node {"commit": "698f22f-dirty", "node": "ip-192-168-188-148.ap-northeast-2.compute.internal"}
2023-05-22T11:50:56.648Z INFO controller.deprovisioning deprovisioning via emptiness delete, terminating 1 machines ip-192-168-188-148.ap-northeast-2.compute.internal/c4.2xlarge/spot {"commit": "698f22f-dirty"}
2023-05-22T11:50:56.682Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-188-148.ap-northeast-2.compute.internal"}
2023-05-22T11:50:57.064Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-188-148.ap-northeast-2.compute.internal"}
$kubectl delete provisioners default
provisioner.karpenter.sh "default" deleted
새로운 Provisiner 설치
$cat <<EOF | kubectl apply -f -
> apiVersion: karpenter.sh/v1alpha5
> kind: Provisioner
> metadata:
> name: default
> spec:
> consolidation:
> enabled: true
> labels:
> type: karpenter
> limits:
> resources:
> cpu: 1000
> memory: 1000Gi
> providerRef:
> name: default
> requirements:
> - key: karpenter.sh/capacity-type
> operator: In
> values:
> - on-demand
**> - key: node.kubernetes.io/instance-type
> operator: In
> values:
> - c5.large
> - m5.large
> - m5.xlarge**
> EOF
provisioner.karpenter.sh/default created
테스트용 디플로이먼트 배포
$cat <<EOF | kubectl apply -f -
> apiVersion: apps/v1
> kind: Deployment
> metadata:
> name: inflate
> spec:
> replicas: 0
> selector:
> matchLabels:
> app: inflate
> template:
> metadata:
> labels:
> app: inflate
> spec:
> terminationGracePeriodSeconds: 0
> containers:
> - name: inflate
> image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
> resources:
> requests:
> cpu: 1
> EOF
deployment.apps/inflate created
오토스케일링 확인 → 파드개수 증가시키기
$kubectl scale deployment inflate --replicas 12
deployment.apps/inflate scaled로그로 시간 확인 → 10초 이내로 반응
$kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-22T11:43:03.998Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-22T11:43:03.999Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/22 11:43:03 Registering 2 clients
2023/05/22 11:43:03 Registering 2 informer factories
2023/05/22 11:43:03 Registering 3 informers
2023/05/22 11:43:03 Registering 5 controllers
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0522 11:43:04.101075 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-22T11:43:04.189Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-22T11:52:47.012Z INFO controller.provisioner computed new machine(s) to fit pod(s) {"commit": "698f22f-dirty", "machines": 4, "pods": 12}
2023-05-22T11:52:47.012Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.015Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.021Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.026Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.562Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/10691513453991989385", "launch-template-id": "lt-0bdf1b82218c3ff67"}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-03691dff7f7c5089b", "hostname": "ip-192-168-95-67.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0dd5ad429b8a4fb1c", "hostname": "ip-192-168-70-7.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0c0613125e339e499", "hostname": "ip-192-168-182-17.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-08a1e375dc91770ff", "hostname": "ip-192-168-174-179.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
$kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ZONE
ip-192-168-174-179.ap-northeast-2.compute.internal Ready <none> 45s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
ip-192-168-182-17.ap-northeast-2.compute.internal Ready <none> 45s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
ip-192-168-30-154.ap-northeast-2.compute.internal Ready <none> 107m v1.24.13-eks-0a21954 m5.large ap-northeast-2a
ip-192-168-70-7.ap-northeast-2.compute.internal Ready <none> 45s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
ip-192-168-86-220.ap-northeast-2.compute.internal Ready <none> 107m v1.24.13-eks-0a21954 m5.large ap-northeast-2c
ip-192-168-95-67.ap-northeast-2.compute.internal Ready <none> 45s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
스케일 다운! → 오토스케일링 확인
$kubectl scale deployment inflate --replicas 5
deployment.apps/inflate scaled로그 확인
$kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-22T11:43:03.998Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-22T11:43:03.999Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/22 11:43:03 Registering 2 clients
2023/05/22 11:43:03 Registering 2 informer factories
2023/05/22 11:43:03 Registering 3 informers
2023/05/22 11:43:03 Registering 5 controllers
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0522 11:43:04.101075 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-22T11:43:04.189Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-22T11:52:47.012Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.015Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.021Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.026Z INFO controller.provisioner launching machine with 3 pods requesting {"cpu":"3125m","pods":"6"} from types m5.xlarge {"commit": "698f22f-dirty", "provisioner": "default"}
2023-05-22T11:52:47.562Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "698f22f-dirty", "provisioner": "default", "launch-template-name": "karpenter.k8s.aws/10691513453991989385", "launch-template-id": "lt-0bdf1b82218c3ff67"}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-03691dff7f7c5089b", "hostname": "ip-192-168-95-67.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0dd5ad429b8a4fb1c", "hostname": "ip-192-168-70-7.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0c0613125e339e499", "hostname": "ip-192-168-182-17.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-08a1e375dc91770ff", "hostname": "ip-192-168-174-179.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:53:04.005Z DEBUG controller deleted launch template {"commit": "698f22f-dirty", "launch-template": "karpenter.k8s.aws/16624063517551845275"}
2023-05-22T11:54:04.652Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 2 machines ip-192-168-182-17.ap-northeast-2.compute.internal/m5.xlarge/on-demand, ip-192-168-70-7.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-22T11:54:04.709Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-182-17.ap-northeast-2.compute.internal"}
2023-05-22T11:54:04.720Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-70-7.ap-northeast-2.compute.internal"}
2023-05-22T11:54:05.138Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-182-17.ap-northeast-2.compute.internal"}
2023-05-22T11:54:05.140Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-70-7.ap-northeast-2.compute.internal"}스케일 다운! → 1개로 줄임
$kubectl scale deployment inflate --replicas 1
deployment.apps/inflate scaled로그 확인
$kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-03691dff7f7c5089b", "hostname": "ip-192-168-95-67.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0dd5ad429b8a4fb1c", "hostname": "ip-192-168-70-7.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-0c0613125e339e499", "hostname": "ip-192-168-182-17.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:52:49.588Z INFO controller.provisioner.cloudprovider launched instance {"commit": "698f22f-dirty", "provisioner": "default", "id": "i-08a1e375dc91770ff", "hostname": "ip-192-168-174-179.ap-northeast-2.compute.internal", "instance-type": "m5.xlarge", "zone": "ap-northeast-2c", "capacity-type": "on-demand", "capacity": {"cpu":"4","ephemeral-storage":"20Gi","memory":"15155Mi","pods":"58"}}
2023-05-22T11:53:04.005Z DEBUG controller deleted launch template {"commit": "698f22f-dirty", "launch-template": "karpenter.k8s.aws/16624063517551845275"}
2023-05-22T11:54:04.652Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 2 machines ip-192-168-182-17.ap-northeast-2.compute.internal/m5.xlarge/on-demand, ip-192-168-70-7.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-22T11:54:04.709Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-182-17.ap-northeast-2.compute.internal"}
2023-05-22T11:54:04.720Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-70-7.ap-northeast-2.compute.internal"}
2023-05-22T11:54:05.138Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-182-17.ap-northeast-2.compute.internal"}
2023-05-22T11:54:05.140Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-70-7.ap-northeast-2.compute.internal"}
2023-05-22T11:43:03.998Z DEBUG controller discovered kube dns {"commit": "698f22f-dirty", "kube-dns-ip": "10.100.0.10"}
2023-05-22T11:43:03.999Z DEBUG controller discovered version {"commit": "698f22f-dirty", "version": "v0.27.5"}
2023/05/22 11:43:03 Registering 2 clients
2023/05/22 11:43:03 Registering 2 informer factories
2023/05/22 11:43:03 Registering 3 informers
2023/05/22 11:43:03 Registering 5 controllers
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "path": "/metrics", "kind": "metrics", "addr": "[::]:8080"}
2023-05-22T11:43:04.000Z INFO controller Starting server {"commit": "698f22f-dirty", "kind": "health probe", "addr": "[::]:8081"}
I0522 11:43:04.101075 1 leaderelection.go:248] attempting to acquire leader lease karpenter/karpenter-leader-election...
2023-05-22T11:43:04.189Z INFO controller Starting informers... {"commit": "698f22f-dirty"}
2023-05-22T11:54:31.756Z INFO controller.deprovisioning deprovisioning via consolidation delete, terminating 1 machines ip-192-168-174-179.ap-northeast-2.compute.internal/m5.xlarge/on-demand {"commit": "698f22f-dirty"}
2023-05-22T11:54:31.811Z INFO controller.termination cordoned node {"commit": "698f22f-dirty", "node": "ip-192-168-174-179.ap-northeast-2.compute.internal"}
2023-05-22T11:54:32.143Z INFO controller.termination deleted node {"commit": "698f22f-dirty", "node": "ip-192-168-174-179.ap-northeast-2.compute.internal"}
$kubectl get node -l type=karpenter
NAME STATUS ROLES AGE VERSION
ip-192-168-95-67.ap-northeast-2.compute.internal Ready <none> 109s v1.24.13-eks-0a21954
$kubectl get node --label-columns=eks.amazonaws.com/capacityType,karpenter.sh/capacity-type
NAME STATUS ROLES AGE VERSION CAPACITYTYPE CAPACITY-TYPE
ip-192-168-30-154.ap-northeast-2.compute.internal Ready <none> 108m v1.24.13-eks-0a21954 ON_DEMAND
ip-192-168-86-220.ap-northeast-2.compute.internal Ready <none> 108m v1.24.13-eks-0a21954 ON_DEMAND
ip-192-168-95-67.ap-northeast-2.compute.internal Ready <none> 114s v1.24.13-eks-0a21954 on-demand
$kubectl get node --label-columns=node.kubernetes.io/instance-type,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE ZONE
ip-192-168-116-39.ap-northeast-2.compute.internal Unknown <none> 11s c5.large ap-northeast-2a
ip-192-168-30-154.ap-northeast-2.compute.internal Ready <none> 109m v1.24.13-eks-0a21954 m5.large ap-northeast-2a
ip-192-168-86-220.ap-northeast-2.compute.internal Ready <none> 109m v1.24.13-eks-0a21954 m5.large ap-northeast-2c
ip-192-168-95-67.ap-northeast-2.compute.internal Ready,SchedulingDisabled <none> 2m12s v1.24.13-eks-0a21954 m5.xlarge ap-northeast-2c
$kubectl delete deployment inflate
deployment.apps "inflate" deleted
$kubectl delete svc -n monitoring grafana
service "grafana" deleted
$helm uninstall karpenter --namespace karpenter
release "karpenter" uninstalled
$aws ec2 describe-launch-templates --filters Name=tag:karpenter.k8s.aws/cluster,Values=${CLUSTER_NAME} |
> jq -r ".LaunchTemplates[].LaunchTemplateName" |
> xargs -I{} aws ec2 delete-launch-template --launch-template-name {}
{
"LaunchTemplate": {
"LaunchTemplateId": "lt-0bdf1b82218c3ff67",
"LaunchTemplateName": "karpenter.k8s.aws/10691513453991989385",
"CreateTime": "2023-05-22T11:52:47+00:00",
"CreatedBy": "arn:aws:sts::871103481195:assumed-role/myeks2-karpenter/1684755783702281349",
"DefaultVersionNumber": 1,
"LatestVersionNumber": 1
}
}
$eksctl delete cluster --name "${CLUSTER_NAME}"
2023-05-22 20:56:27 [ℹ] deleting EKS cluster "myeks2"
2023-05-22 20:56:28 [ℹ] will drain 0 unmanaged nodegroup(s) in cluster "myeks2"
2023-05-22 20:56:28 [ℹ] starting parallel draining, max in-flight of 1
아래는 배포된 자원을 삭제한 후의 스크린 샷이다. 로그와 EKS-NODE-VIEW를 통해 관련 내용을 확인하면 된다.