- pandas와 numpy 설치 후 import
!pip install pandas numpy
import pandas as pd
import numpy as np
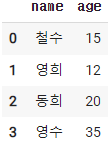
- DataFrame 기초 만들기
data = {
'name':['철수','영희','동희','영수'],
'age' : [15,12,20,35]
}
df = pd.DataFrame(data)
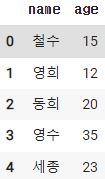
2-1. row 추가하기
doc = {
'name' : '세종',
'age' : 23
}
df.append(doc, ignore_index=True)
※ignore_index란 인덱스를 만들지 않고 그냥 추가로 붙이겠다는 뜻이다
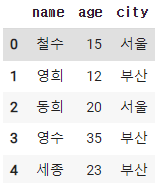
2-2. column 추가하기
df['city'] = ['서울','부산','서울','부산','부산']
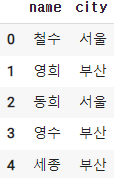
2-3. 특정 column 만 출력하기(대괄호 2번하기)
df[['name','city']]
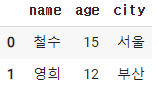
2-4. 특정 조건으로 출력하기 (나이 20 미만)
cond = df['age'] < 20
df[cond]
2-5. 마지막줄의 정보
1) df.iloc[-1]
2) df.iloc[-1,0]

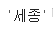
2-6. 정렬
1)나이순으로 내림차순
df.sort_values(by='age', ascending=False)
2) 첫번째의 나이를 구해라
df.sort_values(by='age',ascending=False).iloc[0,1]

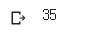
2-7. 조건추가하기
1) 20미만 청소년 나머지 성인
df['is_adult']= np.where(df['age'] < 20, '청소년','성인')
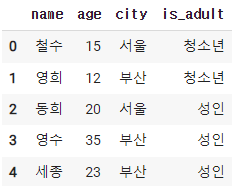
2-8. 계산하기
df['age'].describe()

퀴즈
서울에서 사는 사람들 나이의 평균 구하기
1) df[df['city']=='서울']
2) df[df['city']=='서울']['age']
3)df[df['city']=='서울']['age'].mean()


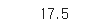
-
엑셀 import 하기
1) 파일에 종목데이터 추가
2) df=pd.read_excel('종목데이터.xlsx')
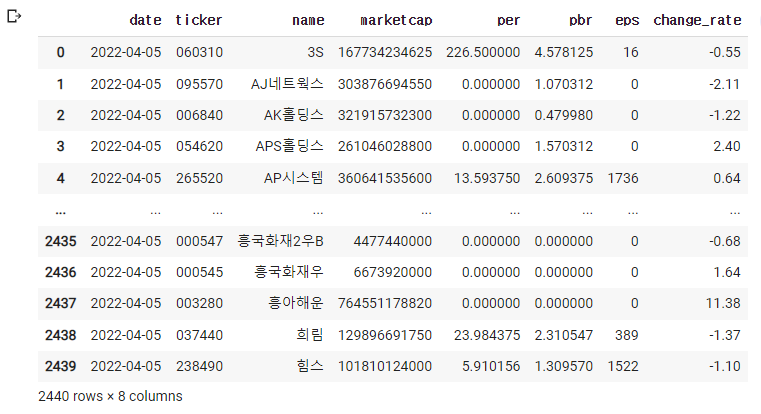
3) 앞에 5개만 가져오기(기본이 5개)
df=pd.read_excel('종목데이터.xlsx')
df.head()
4) 소수점 둘째자리 (한번만 실행하면 됨)
pd.options.display.float_format = '{:.2f}'.format
실행 후 3)것을 실행해보면 된다.
-
pandas 실전
1) 어제 오른 종목들만 골라보기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df[cond]
2) per가 0인 종목들을 제거하기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df
3) 순이익, 종가를 추가하기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] df['eps']
df['earning'] = df['marketcap'] / df['pbr']
df
4) date 컬럼을 없애기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] df['eps']
df['earning'] = df['marketcap'] / df['pbr']
del df['date']
df
5) pbr < 1 & 시총 1조 이상 & per < 20 을 추려보기
df=pd.read_excel('종목데이터.xlsx')
cond=df['change_rate'] > 0
df = df[cond]
cond = df['per'] > 0
df = df[cond]
df['close'] = df['per'] * df['eps']
df['earning'] = df['marketcap'] / df['pbr']
del df['date']
cond = (df['pbr'] < 1) & (df['marketcap'] > 1000000000000) & (df['per'] < 20)
df = df[cond]
df
6) 정렬해서 보기
df.sort_values(by='marketcap',ascending = False)
7) 숫자들의 정보만 보기
df.describe()
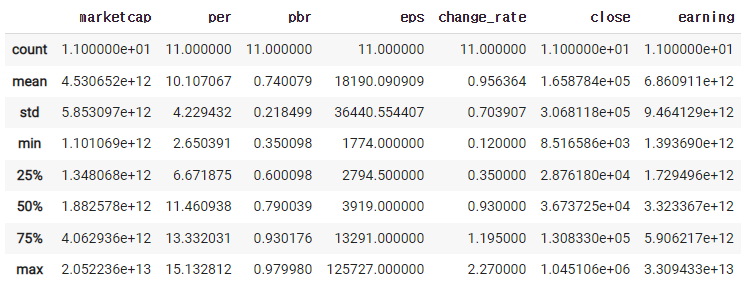
-
해외주식 다루기 - yfinance
1)!pip install yfinance
2)import pandas as pd
import numpy as np
import yfinance as yf
3)company = yf.Ticker('TSLA')
company
3)-1 company.info
3)의 밑줄에 .info넣어보면 정보가 나온다
※원래 홈페이지의 용어와 코드에서 나온 값의 이름이 다를수도 있다.

5-2.
1) 기본 정보 얻기 (예 회사명, 산업, 시가총액, 매출)
(위의 .info에서 ''안의 내용 복사 붙여넣기 하자)
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
revenue = company.info['totalRevenue']
print(name, industry, marketcap, revenue)
2) 재무제표에서 3년치 데이터 얻기 (대차대조표, 현금흐름표, 기업 실적)
2)-1 company.balance_sheet
2)-2 특정 목록만 보기
company.balance_sheet.loc[['Cash']]
2)-3 company.cashflow
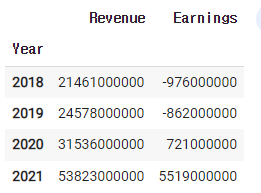
2)-4 매출하고 이익만 보여주기
company.earnings
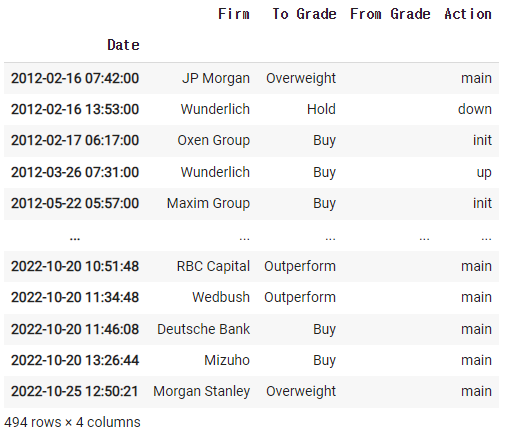
2)-5 company.recommendations
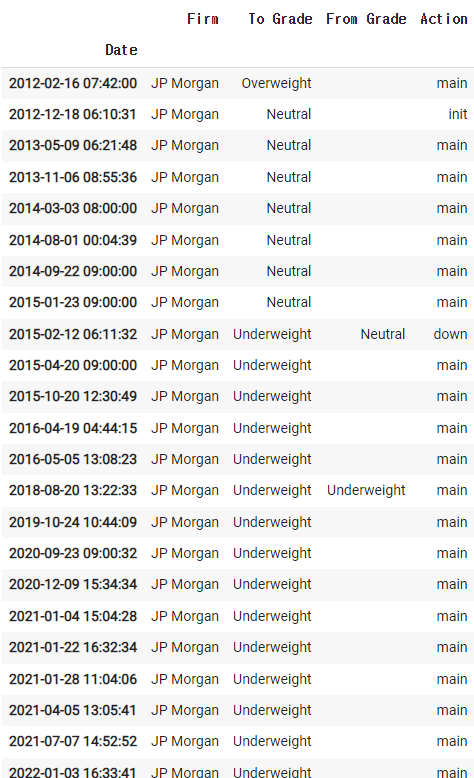
2)-6 JP Morgan의 자료만 가져오기
df = company.recommendations
cond = df['Firm'] == 'JP Morgan'
df[cond]
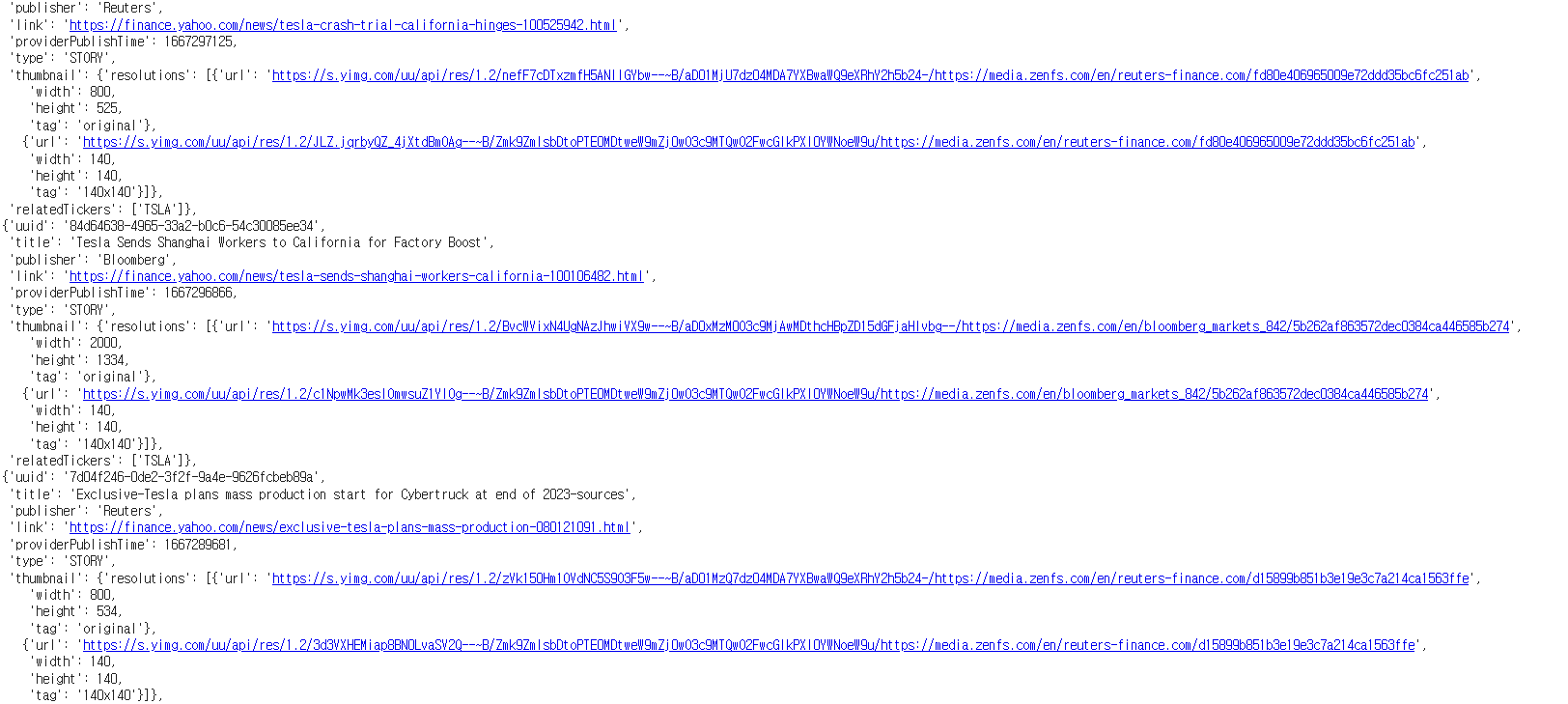
2)-7 company.news
news = company.news
news[0]
news = company.news
news[0]['title']

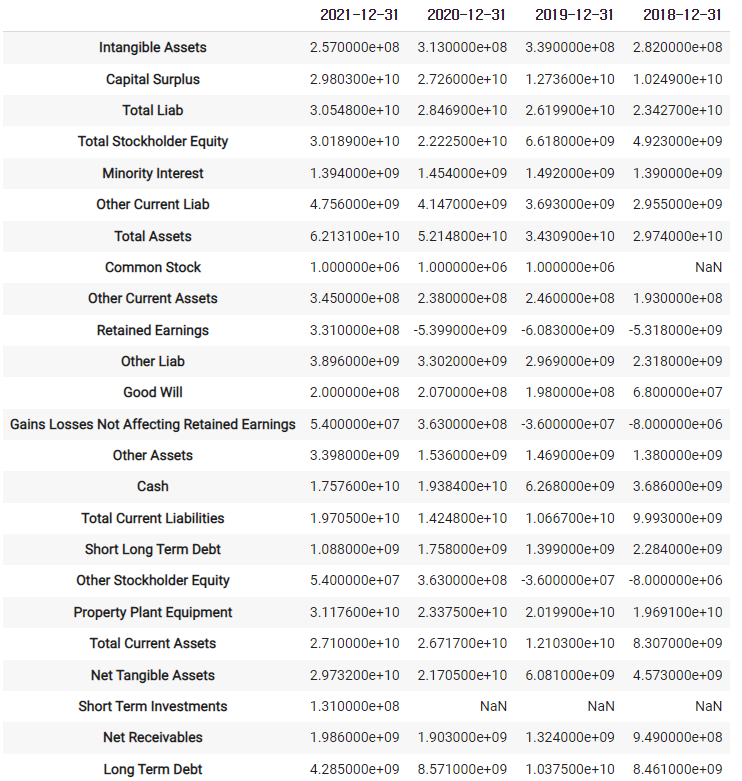

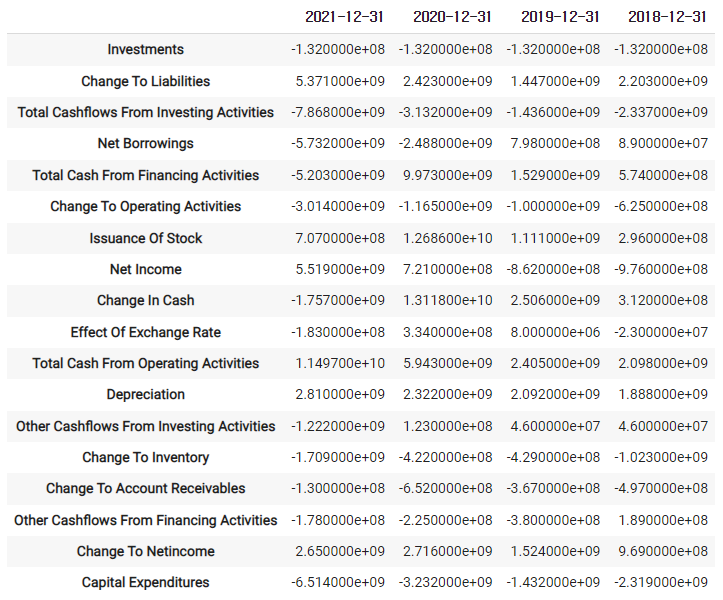


- 분석하기(1) : 전략 세우기, 데이터 모으기
1)-1 company = yf.Ticker('TSLA')
code = 'TSLA'
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
summary = company.info['longBusinessSummary']
currentprice = company.info['currentPrice']
targetprice = company.info['targetMeanPrice']
per = company.info['trailingPE']
eps = company.info['trailingEps']
pbr = company.info['priceToBook']
print(code,name, company,industry,marketcap,summary,currentprice,targetprice,per,eps,pbr)
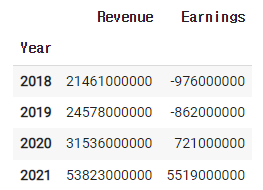
1)-2 company.earnings
1)-3 rev2021 = company.earnings.iloc[-1,0]
rev2021
1)-4 rev2021 = company.earnings.iloc[-1,0]
rev2020 = company.earnings.iloc[-2,0]
rev2019 = company.earnings.iloc[-3,0]
ear2021 = company.earnings.iloc[-1,1]
ear2020 = company.earnings.iloc[-2,1]
ear2019 = company.earnings.iloc[-3,1]

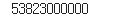
조금 복습하기
2)-1 빈 데이터프레임만들기
df = pd.DataFrame()
df

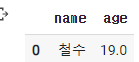
2)-2 df = pd.DataFrame()
doc = {
'name' : '철수',
'age' : 19
}
df.append(doc, ignore_index = True)
2)-3 ※doc 안에 들어갈때 ,꼭 넣기!!
def add_company(code):
company = yf.Ticker(code)
name = company.info['shortName']
industry = company.info['industry']
marketcap = company.info['marketCap']
summary = company.info['longBusinessSummary']
currentprice = company.info['currentPrice']
targetprice = company.info['targetMeanPrice']
per = company.info['trailingPE']
eps = company.info['trailingEps']
pbr = company.info['priceToBook']
rev2021 = company.earnings.iloc[-1,0]
rev2020 = company.earnings.iloc[-2,0]
rev2019 = company.earnings.iloc[-3,0]
ear2021 = company.earnings.iloc[-1,1]
ear2020 = company.earnings.iloc[-2,1]
ear2019 = company.earnings.iloc[-3,1]
doc = {
'name' : name,
'industry' : industry,
'marketcap' : marketcap,
'summary' : summary,
'currentprice' : currentprice,
'targetprice' : targetprice,
'per' : per,
'eps' : eps,
'pbr' : pbr,
'rev2021' : rev2021,
'rev2020' : rev2020,
'rev2019' : rev2019,
'ear2021' : ear2021,
'ear2020' : ear2020,
'ear2019' : ear2019
}
return doc
실행한번 시킨 후
2)-4 df = pd.DataFrame()
row = add_company('TSLA')
df.append(row, ignore_index = True)

2)-5 소수점둘째자리
새로 코드만들기에서 이것만 넣고 실행(후 삭제 해도됨)
pd.options.display.float_format = '{:.2f}'.format
그 후 2)-4 다시 실행시키면 깔끔하게 보인다

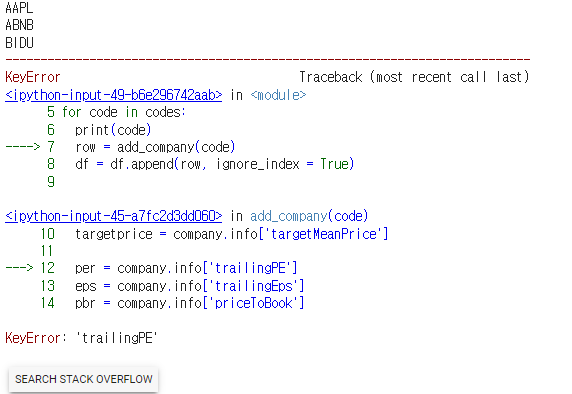
2)-6 for문으로 돌려보기
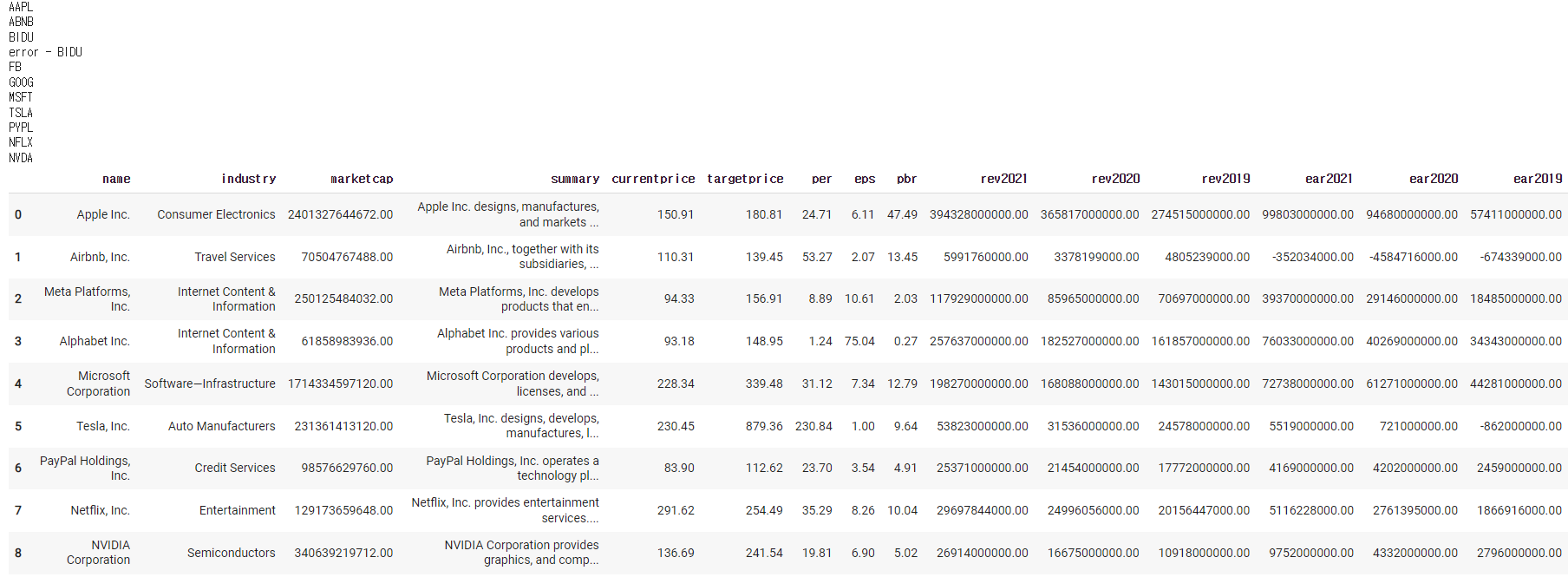
df = pd.DataFrame()
codes = ['AAPL','ABNB','BIDU','FB','GOOG','MSFT','TSLA','PYPL','NFLX','NVDA']
for code in codes:
print(code)
row = add_company(code)
df = df.append(row, ignore_index = True)
df
이러면 에러가 뜰것이다.
실제로 yahoofinance에 검색해보면 자료가 없을때가 있다. 이렇게 에러가 뜨면
☆ : try: ...... except: 를 넣어보자
(try해서 없으면 except의 문장을 넣어라)
df = pd.DataFrame()
codes = ['AAPL','ABNB','BIDU','FB','GOOG','MSFT','TSLA','PYPL','NFLX','NVDA']
for code in codes:
print(code)
try:
row = add_company(code)
df = df.append(row, ignore_index = True)
except:
print(f'error - {code}')
df
- 분석하기(2) : 분석하기
1)-1 먼저 (head() = 위에서 5개만 보기)
df.head()

1)-2
df.sort_values(by='eps',ascending=False)
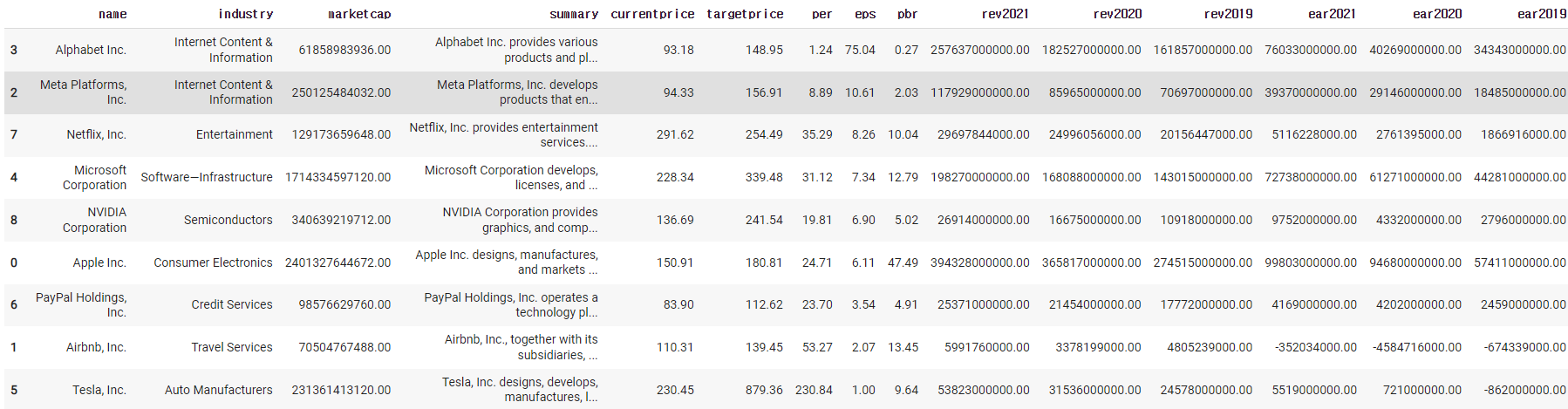
1)-3
df.sort_values(by='eps',ascending=False).head()

2) 특정 per 이하만 보기(+내림차순)
cond = df['per'] > 30
df[cond].sort_values(by='per', ascending = False)

3)-1 현재가격 - 1년 후 가격의 비율 차이가 큰 종목들을 추려내기
일단 보기좋게 만들기
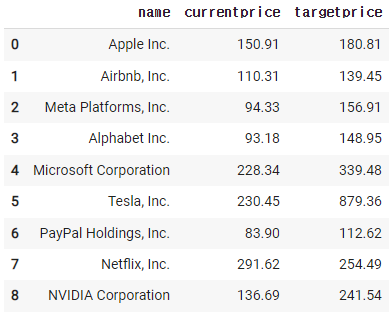
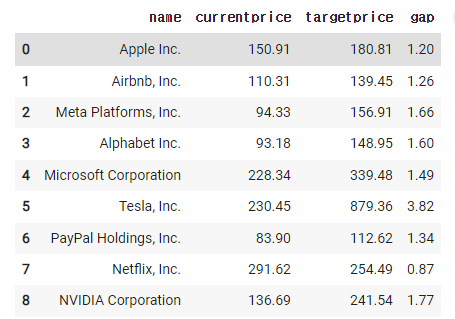
new_df = df[['name','currentprice','targetprice']]
new_df
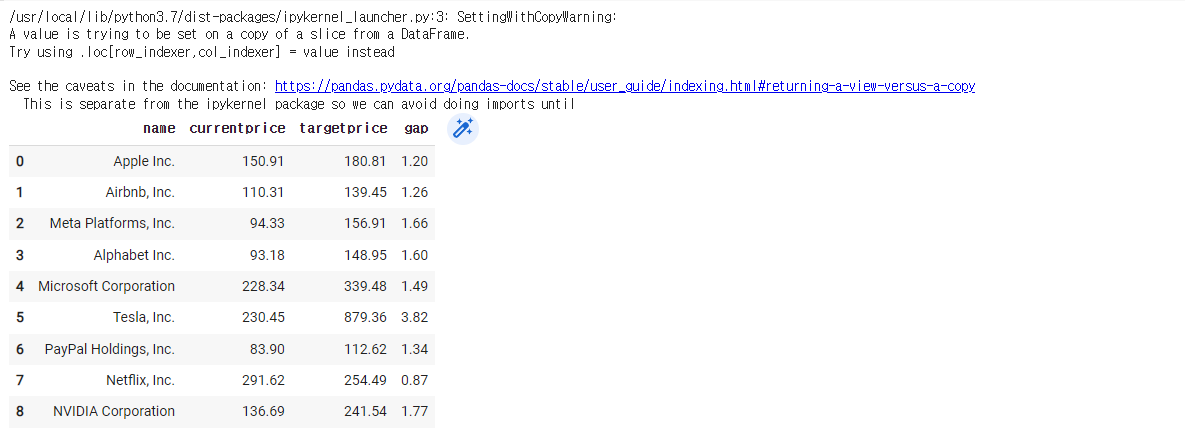
3)-2
new_df = df[['name','currentprice','targetprice']]
new_df['gap'] = new_df['targetprice'] / new_df['currentprice']
new_df
그냥 이렇게 만들면 원본이 훼손된다.
그러므로 1줄을
new_df = df[['name','currentprice','targetprice']].copy()
만들면 된다.
대개의 경우 맨 윗줄에 .copy()를 안한경우가 많다.
그 후 내림차순으로 정렬
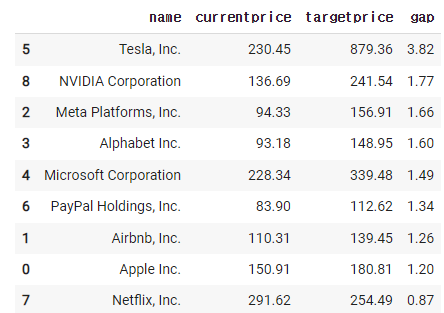
new_df = df[['name','currentprice','targetprice']].copy()
new_df['gap'] = new_df['targetprice'] / new_df['currentprice']
new_df.sort_values(by='gap', ascending = False)
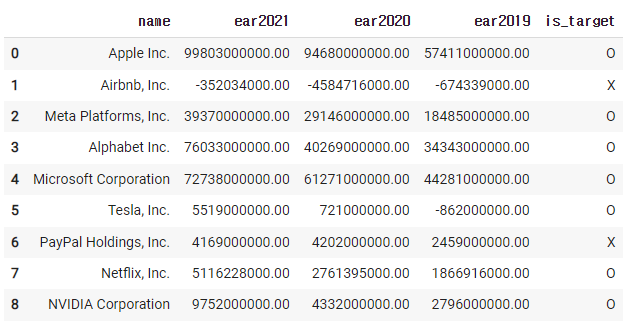
4)-1 3년 연속 순수익이 오른 기업을 표기하기
일단 필요한 자료만 뽑아보자
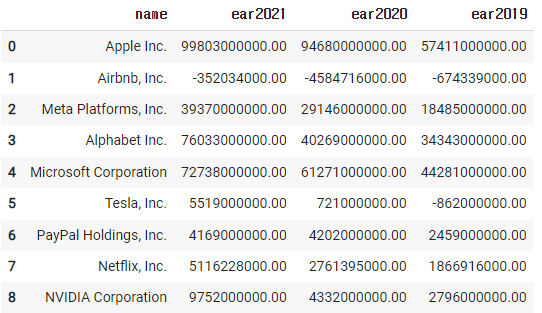
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
new_df
4)-2
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
cond = (new_df['ear2021'] > new_df['ear2020']) & (new_df['ear2020'] > new_df['ear2019'])
new_df[cond]
4)-3 이 자료를 표기하기
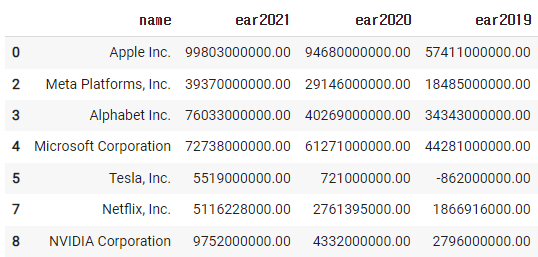
new_df = df[['name','ear2021','ear2020','ear2019']].copy()
cond = (new_df['ear2021'] > new_df['ear2020']) & (new_df['ear2020'] > new_df['ear2019'])
new_df['is_target'] = np.where(cond, 'O','X')
new_df