Dart OpenAPI
1) 먼저 키 발급받기
API란? - 서버에 접근하는 ‘창구’와 같은 것
https://opendart.fss.or.kr/uat/uia/egovLoginUsr.do
2) 라이브러리 설치
!pip install dart-fss
인터넷창에 'dart fss 라이브러리' 검색하기
이 홈페이지가 라이브러리에서 제공하는 공식문서다.

3)
dart_fss를 사용하겠다 판다스도 사용하겠다 전체 회사리스트를 받아서 출력해주겠다 - 는 내용이다.

4)
저 부분의 코드를 복사해서 colab에 넣어준다.

5) 위 사진의 아랫부분만 따로 코드로 분류하면 절차가 간단해진다.
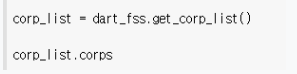

양이 많고 반복되는 형태이므로 0번째꺼만 불러와도 된다.(확인용)
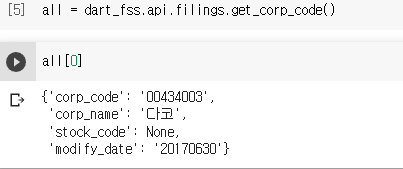
그러면 데이터프레임으로 만들어주자
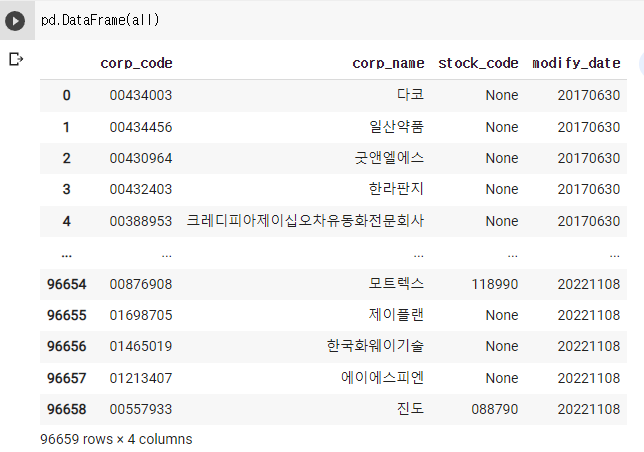
목록중 stock_code가 있는 애들과 없는 애들을 구분해보자
1) stock_code가 있는 회사
여기서 없는애들은 아니다 해서 != 'null' 이렇게 쓰면 안먹힌다.

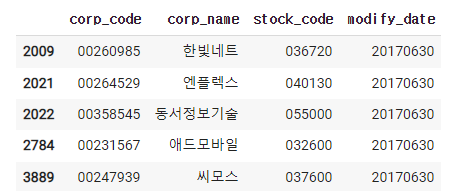
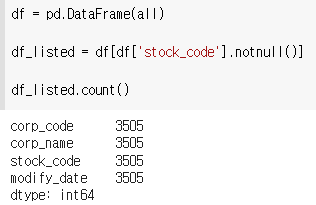
2) stock_code가 없는 회사
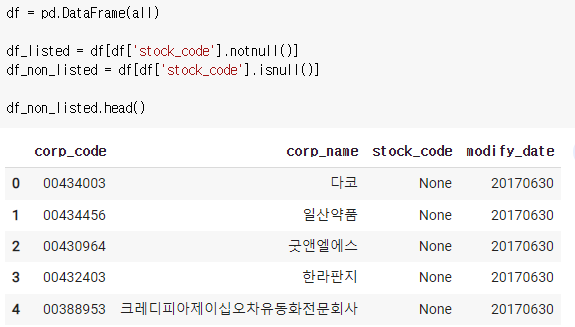
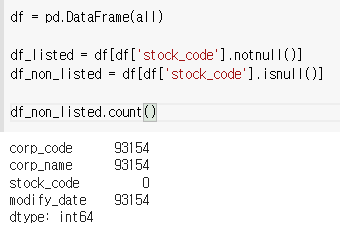
6) 엑셀파일로 만들어보기

1. dart API 사용해보기
1) 회사 코드(corp_code) 찾아오기
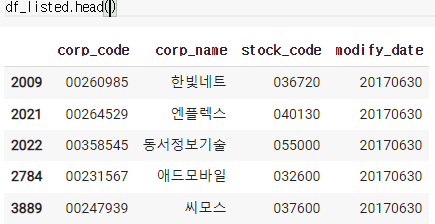
먼저
로 어떻게 생겼나 보고
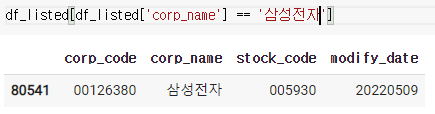
회사 이름으로 목록을 불러온 후에 iloc로 특정 값을 불러온다.



2) 사업보고서 주요정보


[참고사항]
우리가 모르는 것들은
개발가이드 -> 공시정보 -> 기업개황
모르는 것을 맞춰보면 된다.
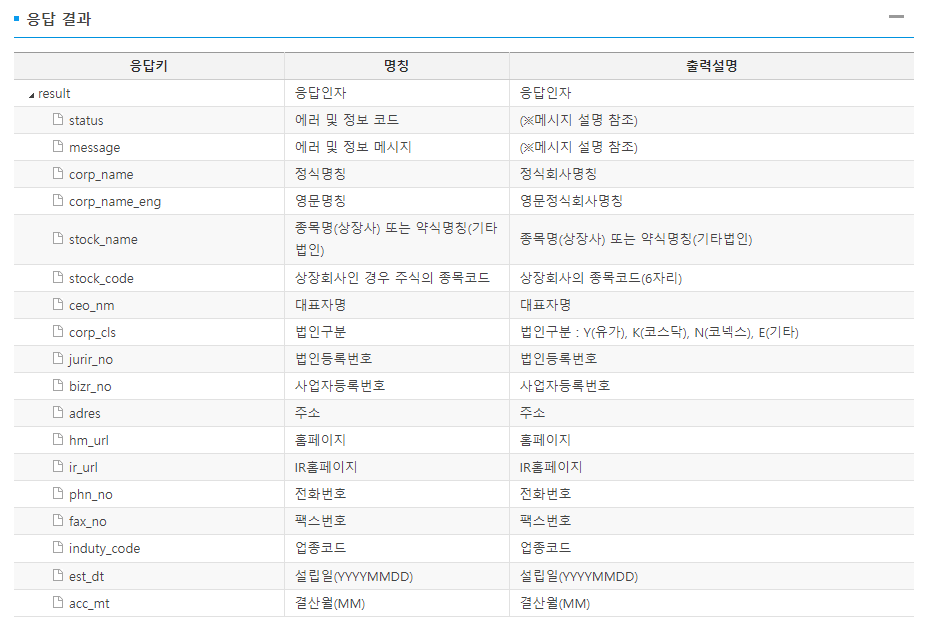
3) 미등기임원 보수 총액
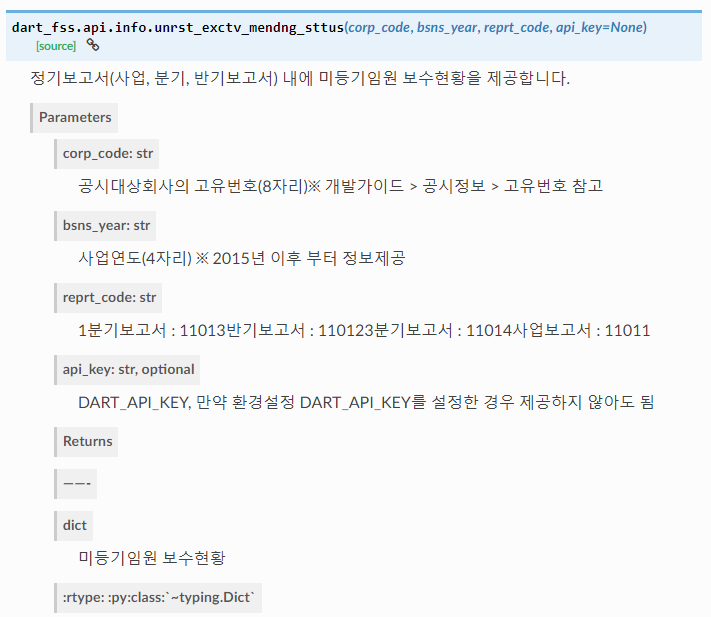
list안에 들어가있으므로 pandas로 표로 만들수있다.
여기서 data = 뒤의 내용만 갈이끼우면 깔끔하게 볼 수 있다.


4) 증자(감자)현황
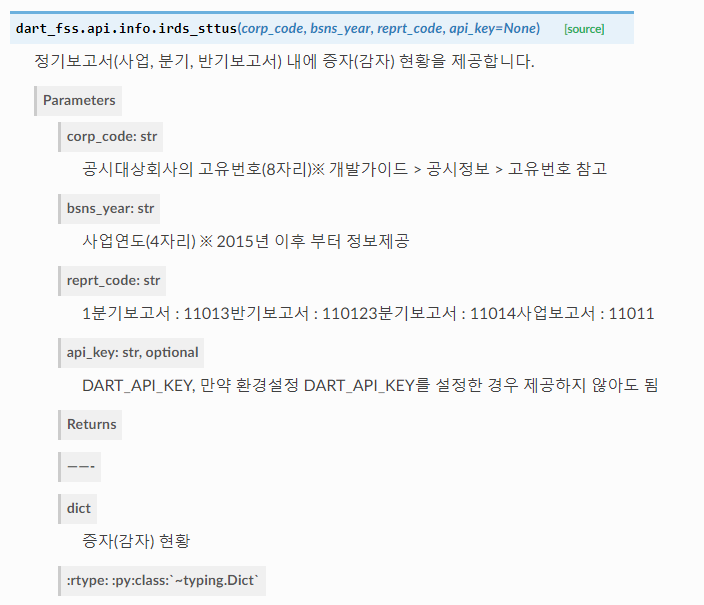
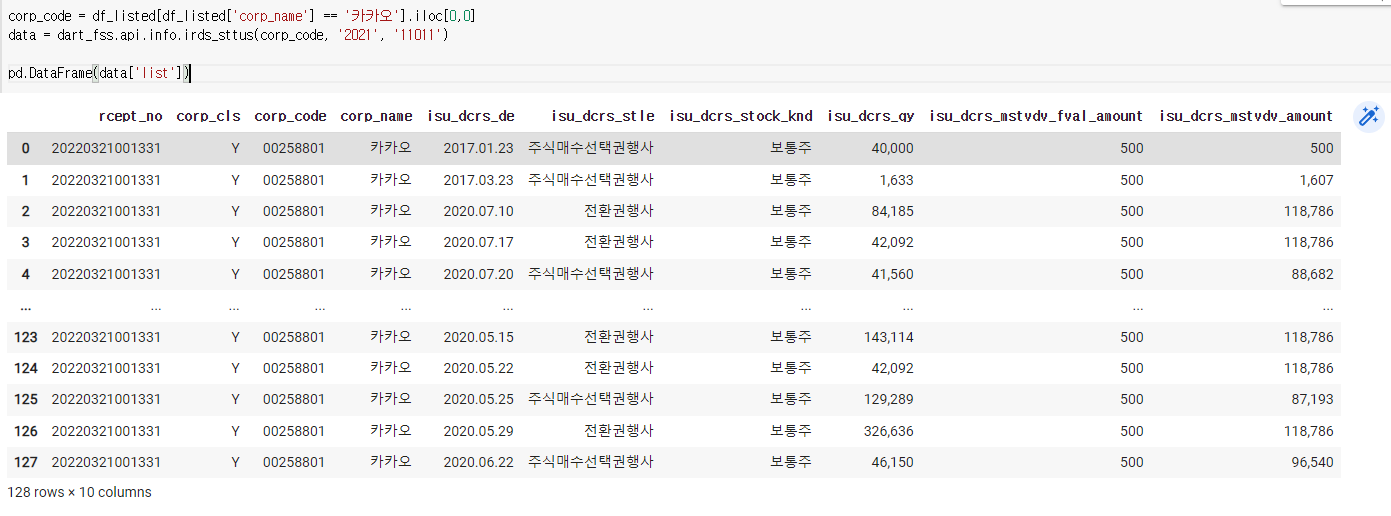
5) 배당 현황
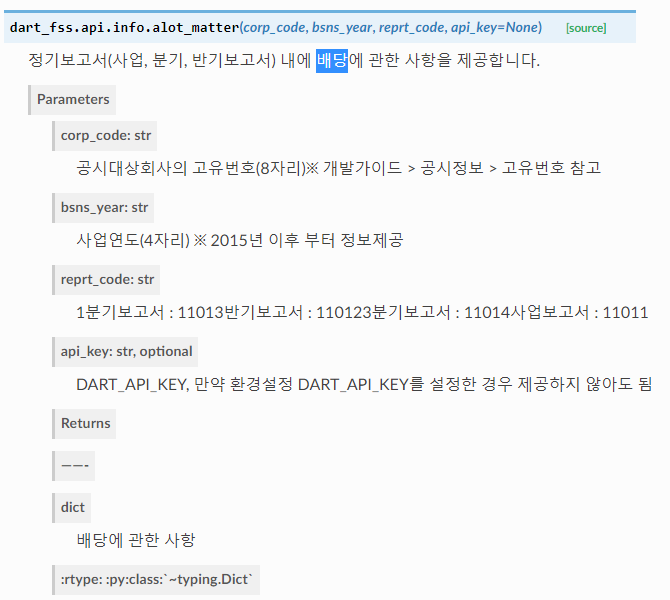
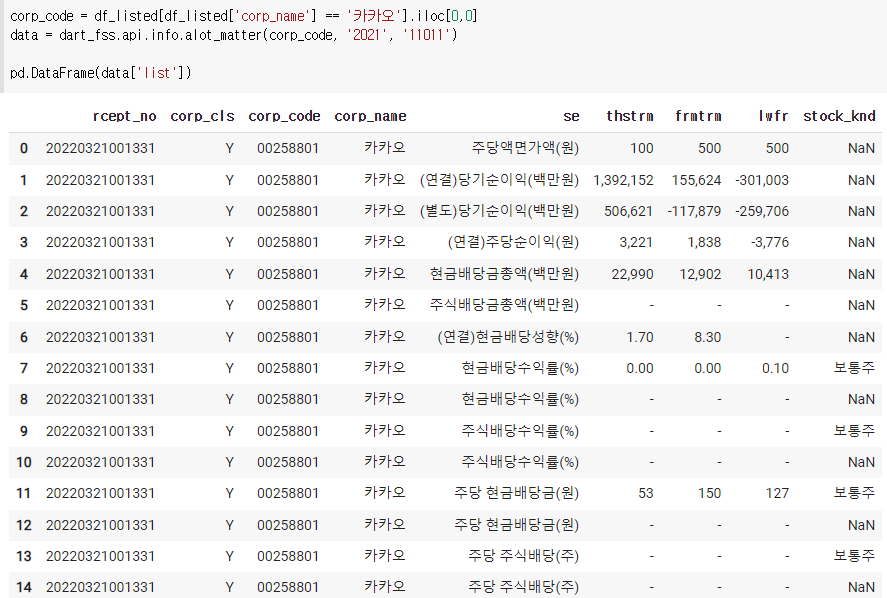
6) 최대주주 현황
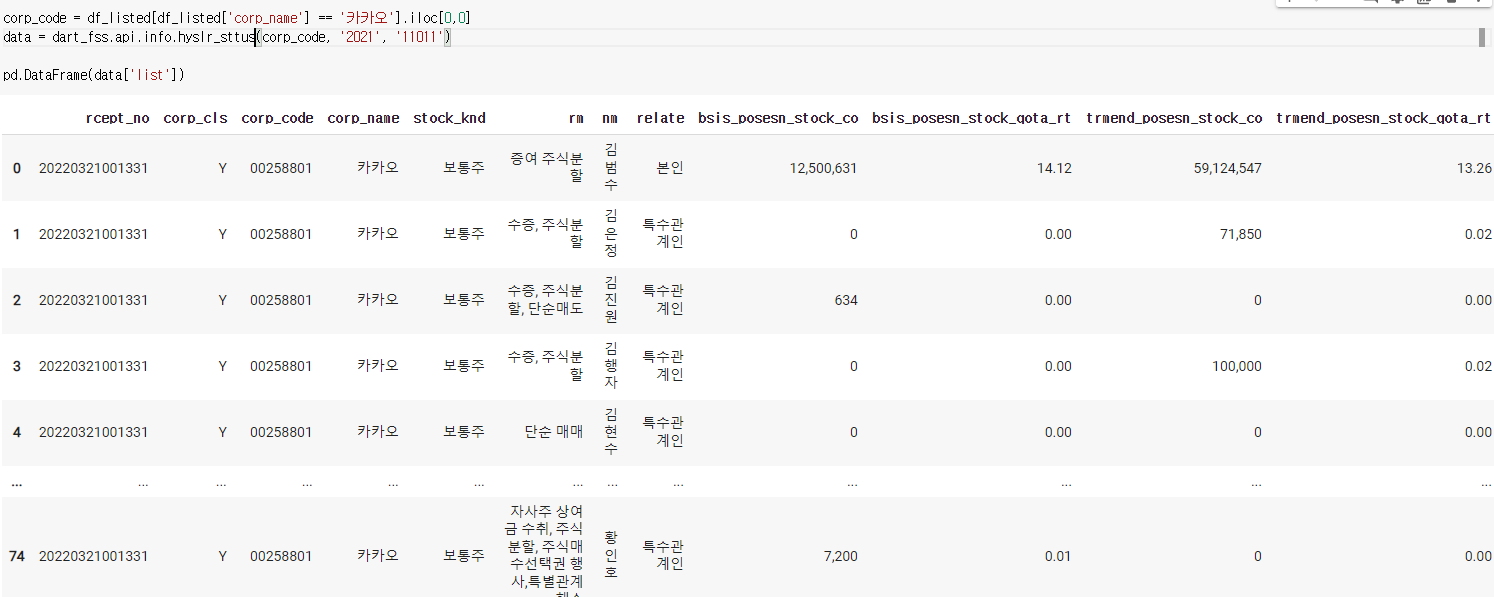
-나중에 볼때는 필요한 열만 가져와서 사용하면 된다.
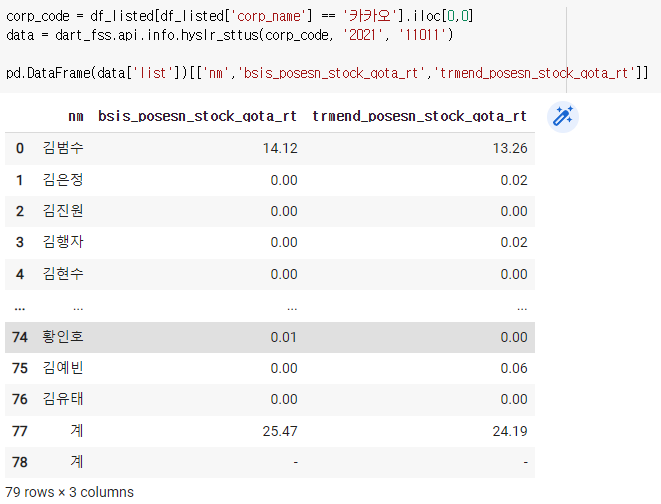
7) 직원 현황

8) 연봉 top 5
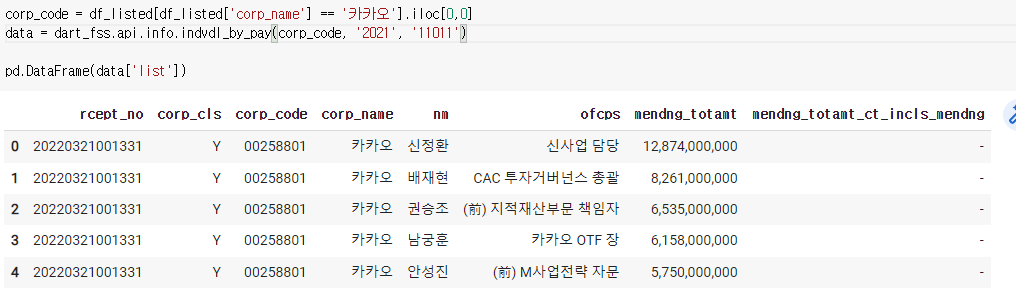
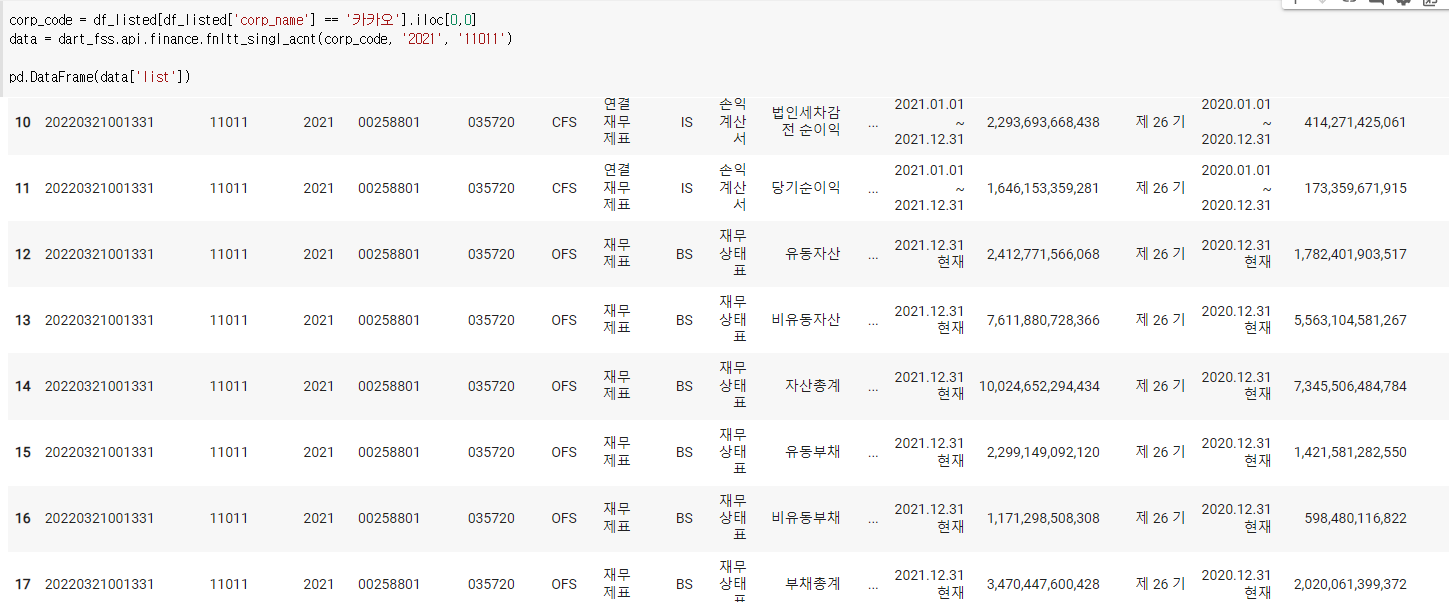
9) 상장기업 재무정보
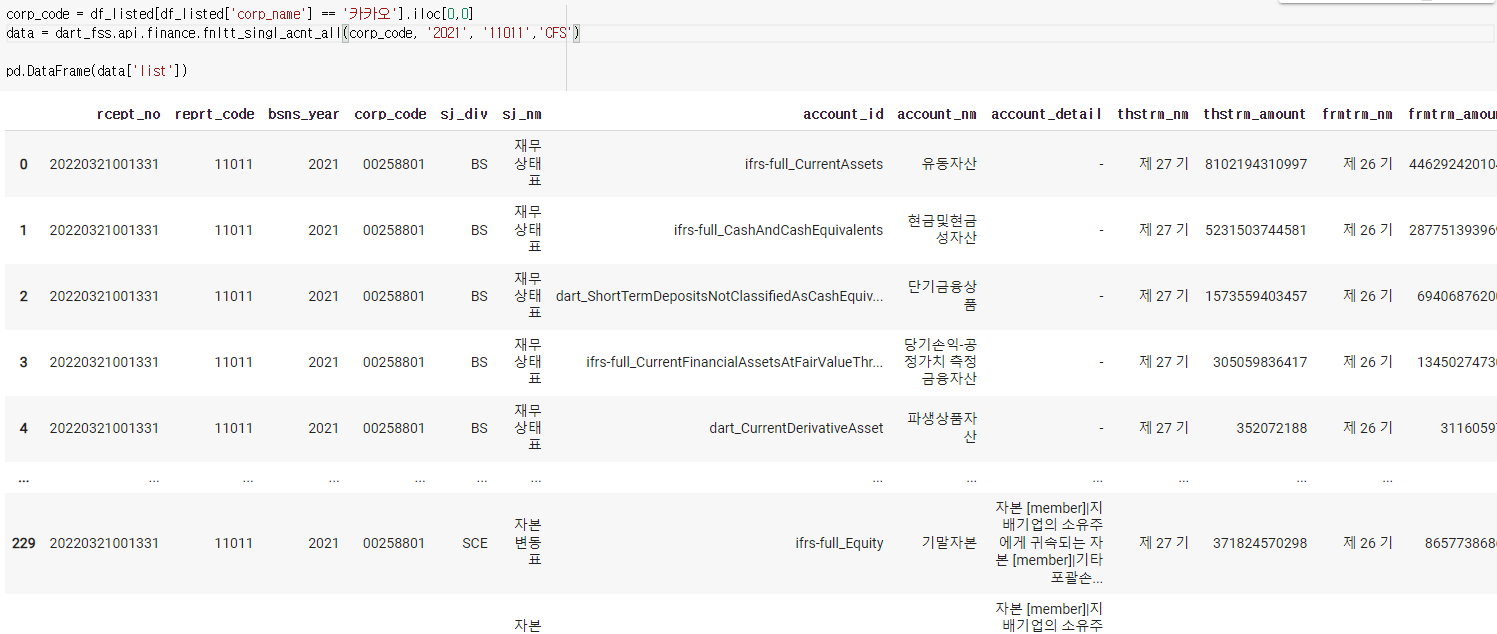
10) 상장기업 모든계정과목보기
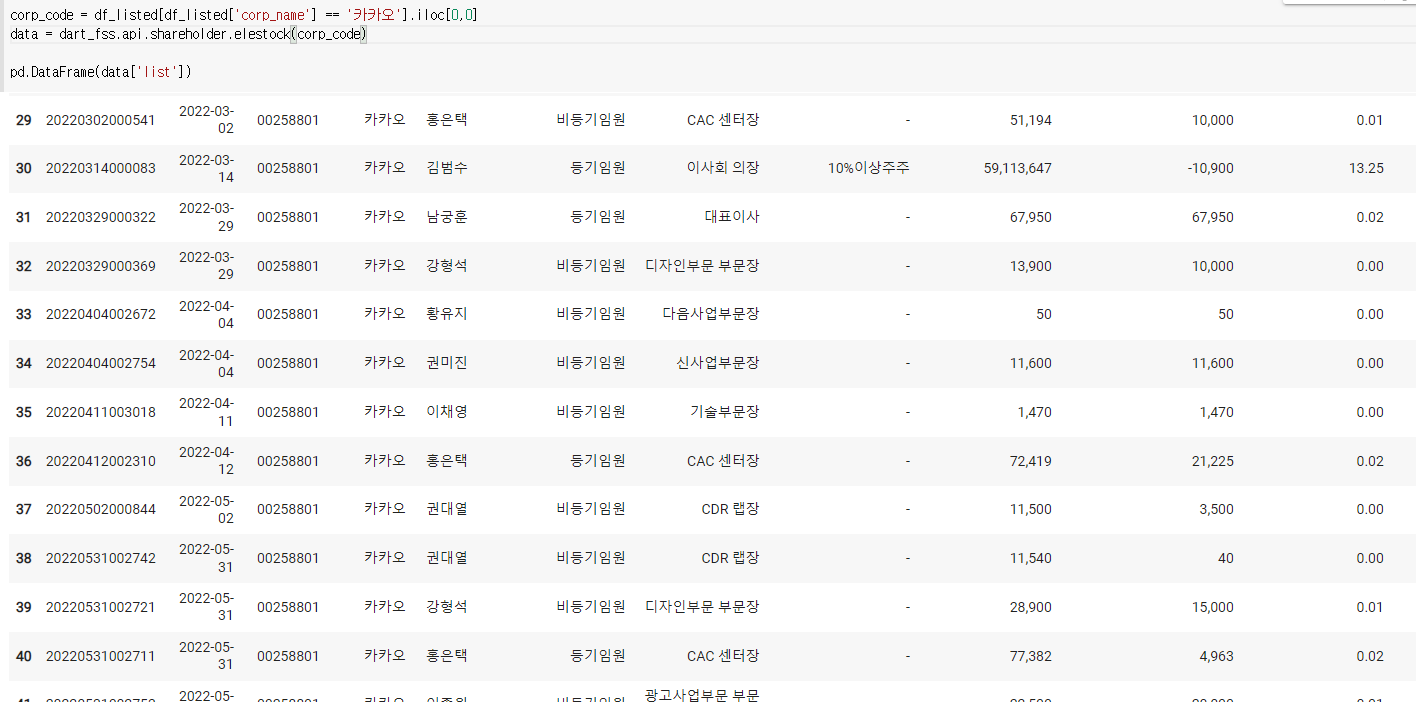
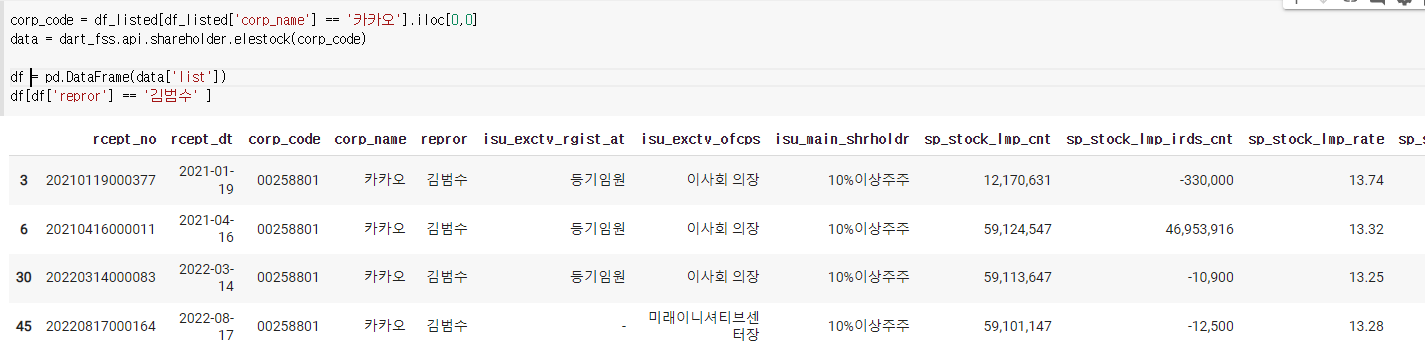
11) 지분공시 종합정보 내에 임원, 주요주주 소유 보고
-이중에서 한사람것만 보고싶으면?
2. dart API 활용해보기
- 각 회사마다 연봉상위 5명 표시하기
1) 한 회사
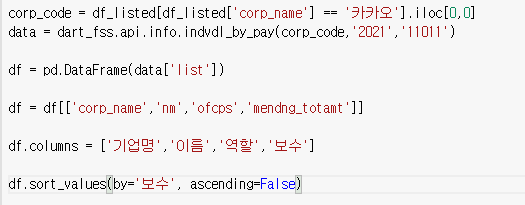
2) 보수 숫자열로 바꾸기
그냥 보기에는 숫자지만 문자열로 되어있다.
그냥 보면 모르기때문에
이렇게 해주면 된다.
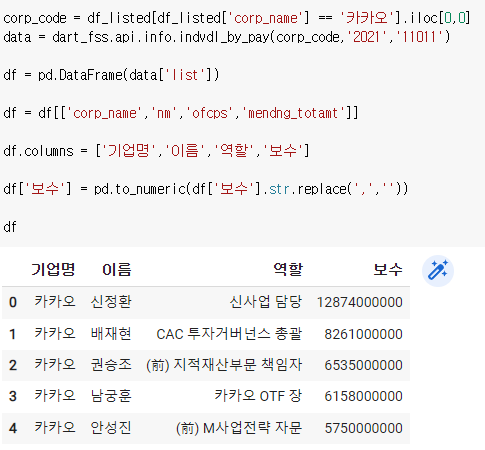
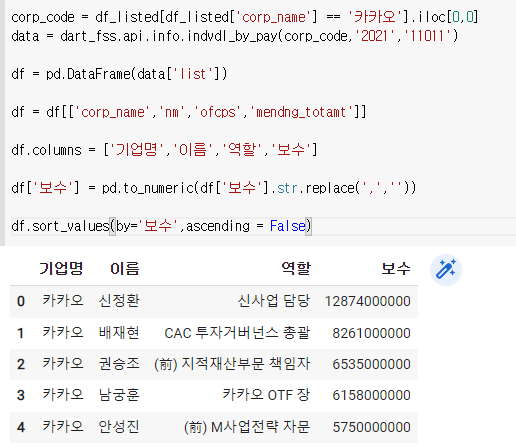
3) 여러회사에 적용시키기
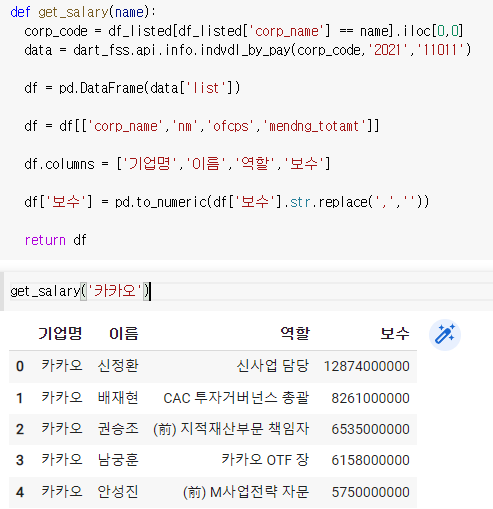
여기에서


위 사진대로 하면 계속 출력해야되는 시간이 걸리니 따로 만들어주면 편리하다
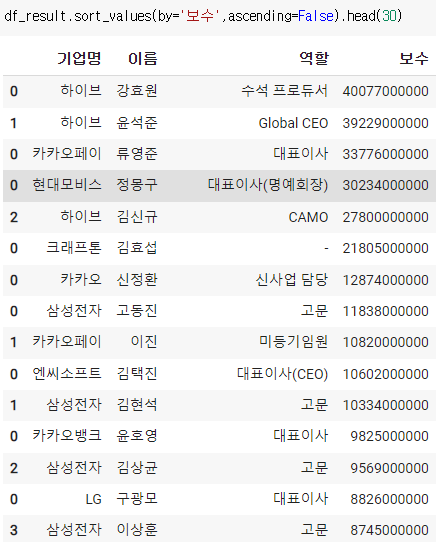
4) 최대주주의 주식변동
먼저
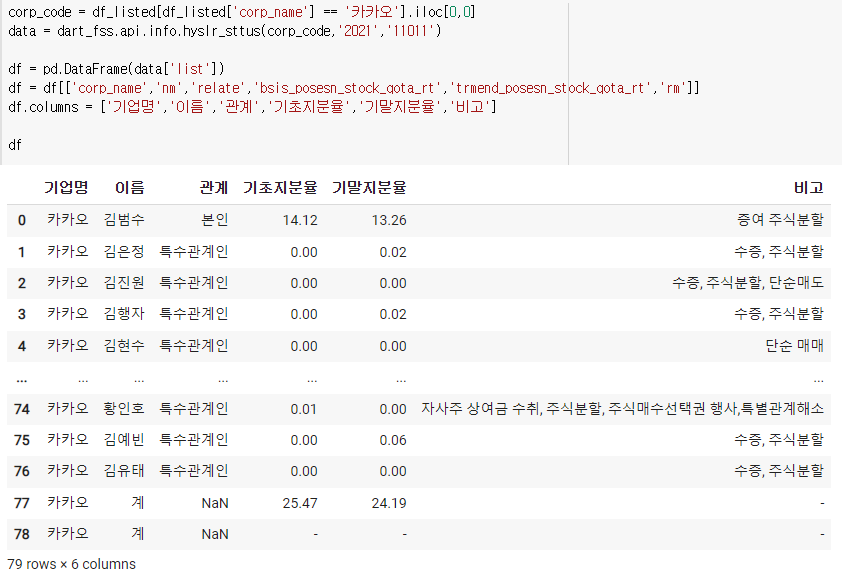
여기서 기초지분율이 문자열로 되어있으므로 바꿔줘야된다.
df.sort_values(by='기초지분율',ascending=False).head(3)
그리고 관계가 없는 부분으로인해 오류가 발생할 수 있으니 그 부분을 없애주자.
df = df[df['관계'].notnull()]
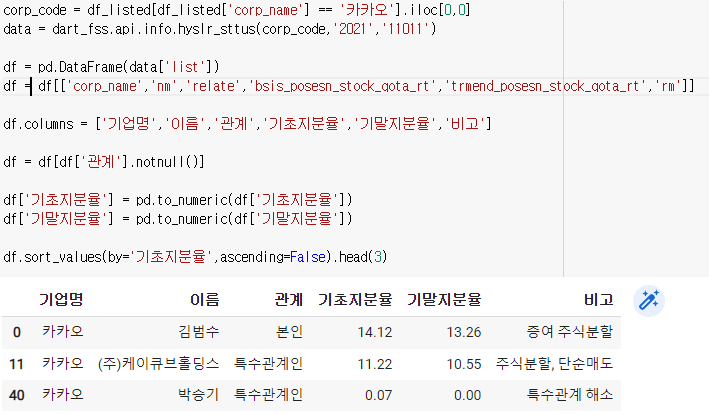
당연히 카카오로만 할게 아니므로 함수로 만들어주자
def get_shareholders(corp_code):

여러회사를 봐야하므로 회사 코드를 불러오자
'하루에 불러올 수 있는 양이 한정되 있으므로 샘플 10개로 줄여서 불러오자'
corp_codes = list(df_listed.sample(10)['corp_code'])
corp_codes
리스트가 있다? = for반복문
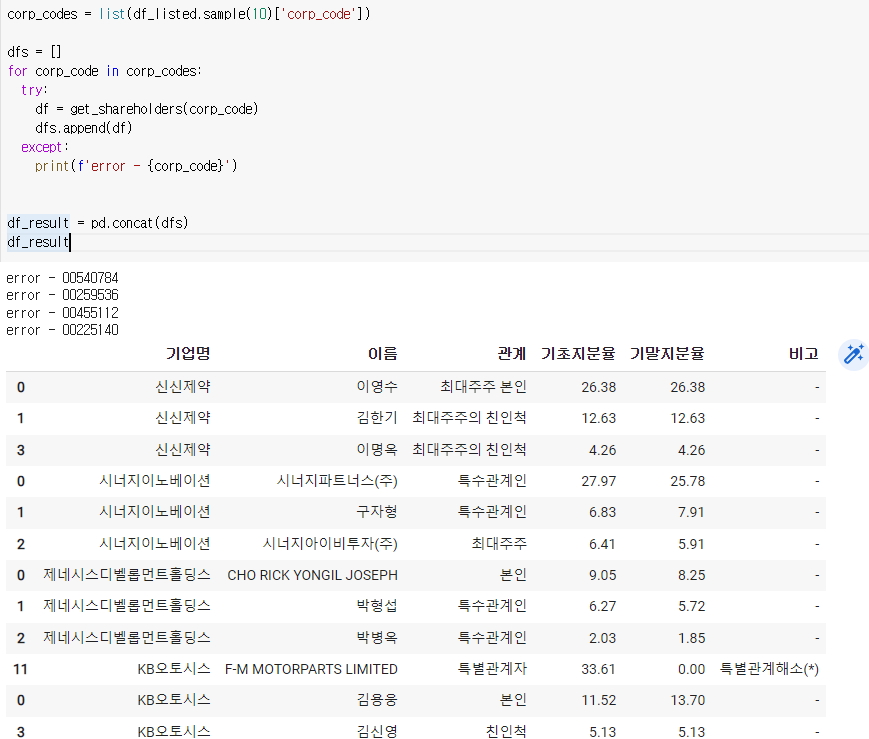
df_result = pd.concat(dfs)
df_result
이 부분이 들여쓰기가 되어있으면 반복문만 출력된다. 주의하자
증감(기말지분율 - 기초지분율)로 내림차순으로 정렬해보자
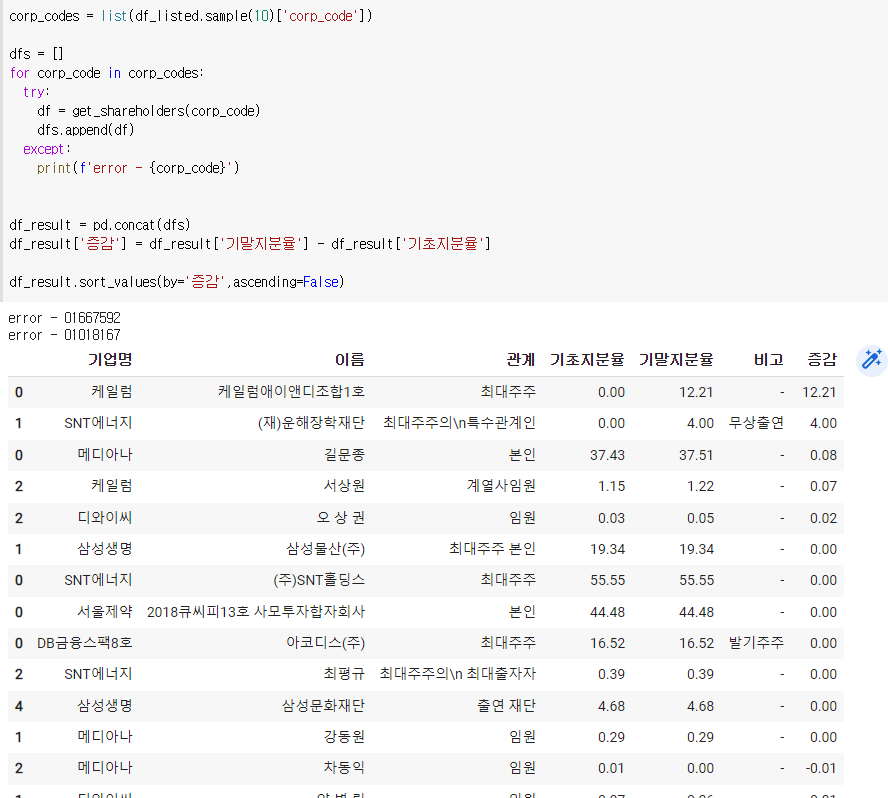
5) ‘돈 많이 번 회사’를 찾기
먼저 fs_div가 CFS이고 account_nm가 이익잉여금인 자료를 찾아보자
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])cond = (df['fs_div'] == 'CFS') & (df['account_nm']=='이익잉여금')
df = df[cond]df

이 중에 우리가 필요한 것만 골라보자.
df.columns = ['기업명','당기','전기']
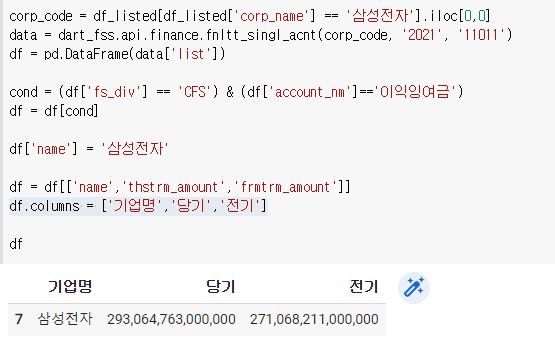
여기서 당기 전기를 숫자로 바꿔주자
df['당기'] = pd.to_numeric(df['당기'].str.replace(',',''))
df['전기'] = pd.to_numeric(df['전기'].str.replace(',',''))
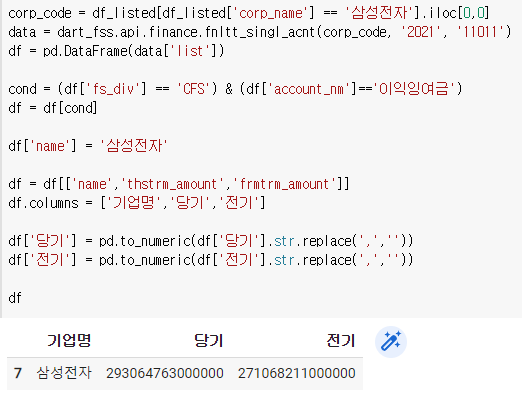
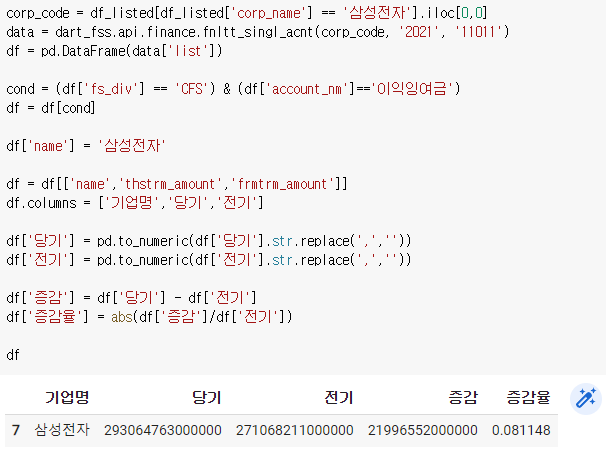
증감(단기-전기), 증감율(증감/전기)을 만들자.
참고 : 함수로 만들고나서 해도 되고 함수 들어가기 전에 미리 만들어도 된다.
함수로 만들어서 여러 기업에 돌려보자
먼저 함수로 만들어서 잘 돌아가는지 보면

잘 돌아간다.
이제 리스트를 가져오면 된다.
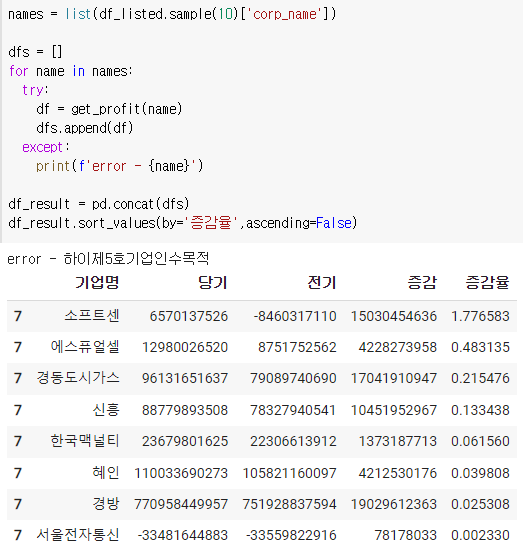
참고 : 함수를 만들고 나서 증감, 증감율의 위치

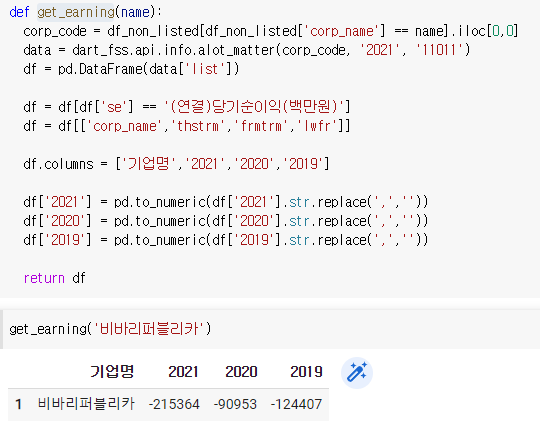
6)비상장 종목 분석하기
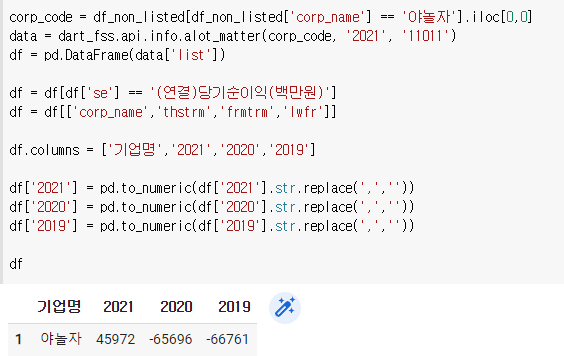
함수로 만들기
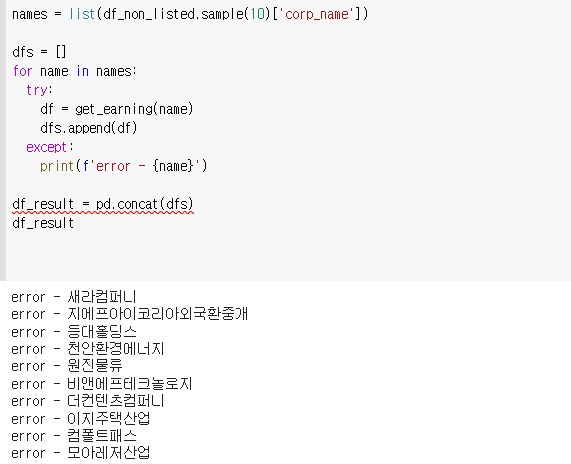
숙제
남녀 평균 급여 차이가 가장 ‘안’ 나는 회사를 찾아보기
corp_code = df_listed[df_listed['corp_name'] == '카카오'].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')pd.DataFrame(data['list'])
def get_salary(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')df = pd.DataFrame(data['list'])
df= df[['corp_name','sexdstn','jan_salary_am']]df_result = pd.DataFrame()
doc = {
'기업명' : name,
'연봉(남)' : df[df["sexdstn"]== '남'].iloc[-1,-1],
'연봉(여)' : df[df["sexdstn"]== '여'].iloc[-1,-1]
}
df_result = df_result.append(doc, ignore_index = True)df_result['연봉(남)'] = pd.to_numeric(df_result['연봉(남)'].str.replace(',',''))
df_result['연봉(여)'] = pd.to_numeric(df_result['연봉(여)'].str.replace(',',''))return df_result
names = list(df_listed.sample(10)['corp_name'])
dfs = []
for name in names:
try:
df = get_salary(name)
dfs.append(df)
except:
print(f'error - {name}')df_result = pd.concat(dfs)
df_result['차이(남-여)'] = df_result['연봉(남)'] - df_result['연봉(여)']
df_result['평균'] = (df_result['연봉(남)']+df_result['연봉(여)'])/2df_result.sort_values(by='차이(남-여)',ascending=True)
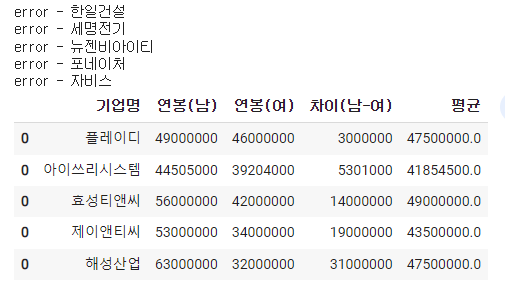
df_result = pd.concat(dfs)
df_result['차이(남-여)'] = df_result['연봉(남)'] - df_result['연봉(여)']
df_result['평균'] = (df_result['연봉(남)']+df_result['연봉(여)'])/2df_result.sort_values(by='차이(남-여)',ascending=True)
이부분에서 헤맸다.
