얘도 다른 논문에서 인용되는걸 좀 많이 봐서 내적 친목이 어느정도 쌓여있는 논문이다.. 계절학기 마무리하고 기존에 연구하던거 회사미팅 준비하고 하느라 논문 읽는 걸 좀 게을리했지만... 다시 한다 2일 1논문 ..
1. Introduction
확실히 컴퓨터 비전에서 pose estimation은 확실하게 활발히 연구되고 있는 분야이다. 이미지에서 사람들이 어떤 자세로 있는지 파악하는 일은 몸의 joint들을 2D에서 localization하는 문제로 해석할 수 있다.
하지만 기존의 human pose estimation은 단조로운 배경의 이미지 중간에 사람 한명이 서 있고, 이를 예측하는 데에 초점이 맞춰져 있었다. 하지만 이런 식을 예측하는것은 실제 생활에 그렇게 크게 쓸모 있지는 않다. 왜냐하면 우리가 일반적으로 마주하는 상황들은 사람들이 많고 뭉쳐있거나, 배경이 복잡한 경우가 대다수이기 때문이다.
그래서 이 논문에서는 'in the wild'에서도 잘 예측할 수 있는 multi-person detection과 2D pose estimation을 위한 모델을 제안한다. 여기에서 제안하는 아키텍처는 top-down approach의 2 stage로 이루어져 있는 간단하고 효과적인 아키텍쳐이다.
Top-down approach란 먼저 사람이 있는 부분을 찾아내고, 그 다음에 그 사람의 키포인트들을 에측하는 구조를 의미한다. 반대로 bottom-up approach가 있는데, 이는 먼저 keypoints들을 찾아 낸 후 그 key point들을 묶어 하나의 사람을 만들어 내는 방법이다.
또한 기존의 선행연구들에서는 주로 bottom-up approach를 사용하며 top-down approach가 bottom-up에 비해서 성능이 떨어진다고 말했는데, 이 논문에서는 top-down approach 역시 굉장히 효과적일 수 있음을 강조한다.
마지막으로, 새로운 confidence score estimator을 제안한다. 이 estimator를 이용했을 때 단순히 Faster RCNN을 사용했을 때보다 성능(AP)이 향상되었다.
2. Towards Accurate Multi-person Pose Estimation in the Wild
앞서 언급했듯이 이 논문에서 제안하는 네트워크는 여러 사람의 key points를 예측하기 위해서 2 stage로 이루어져 있다. 먼저 첫번재 스테이지에서는 사람이 있을 것 같은 bbox를 예측한다. 이 논문에서는 Faster R-CNN을 이용한다. 그리고 두번째 스테이지에서는 예측한 각 bbox에 대해서 사람들의 key points를 예측한다.

위의 사진은 논문에서 제안한 approach를 그림으로 나타낸 것이다. 사실 보면 직관적으로 이해할 수 있는데, 주어진 이미지에서 사람이라고 생각되는 부분을 자르고, 그 각 부분부분에서 key point라고 생각되는 joint들을 또 찾아내는 것이다.
1) Person Box Detection
앞서 언급했듯이 여기에서는 기본 human detector로 Fast R-CNN을 사용한다. ResNet-101 backbone을 사용했고, atrous convolution을 modify했다는 디테일들도 설명되어 있다.
당연한 소리겠지만 ResNet backbone은 이미지넷으로 학습되었고, Faster R-CNN의 구현은 그냥 논문 저자들에 구현해둔 것을 가져와서 썼다고 한다.
2) Person Pose Estimation
두번째 스테이지에서는 검출된 각각의 human bbox에 대해서 joint를 에측한다. 이때 각각의 joint를 예측하는 문제를 localization problem이 아닌 combined classification and regression problem으로 해석한다.
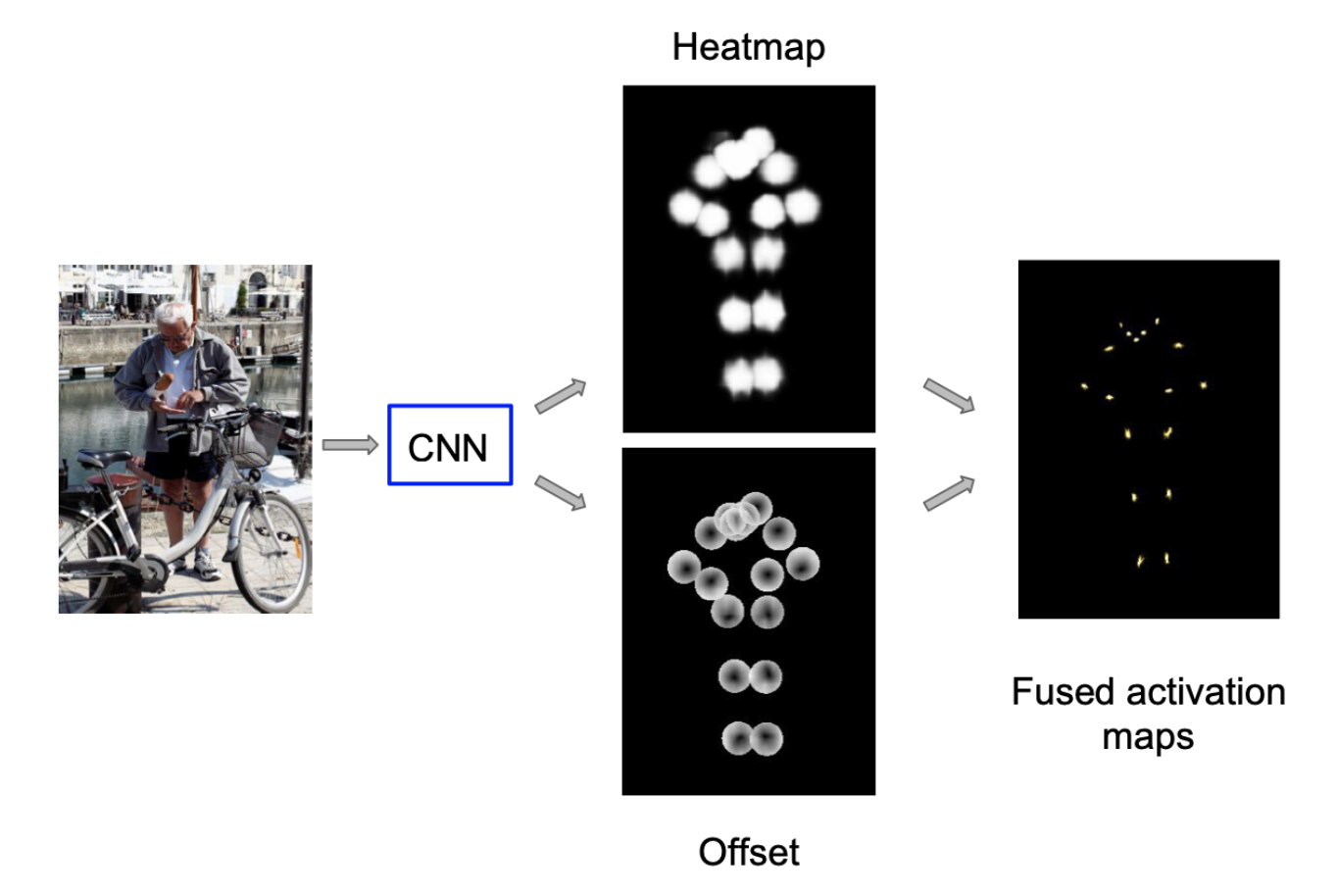
 상단의 이미지에서도 알 수 있듯이, 각각의 target joint들은 heatmap으로 표현되며 여기에서 한 point가 포함 되냐 되지 않냐를 classify하고, 동시에 L2 manitude offset field를 이용해 얼마나 offset이 떨어져 있냐를 예측한다.
상단의 이미지에서도 알 수 있듯이, 각각의 target joint들은 heatmap으로 표현되며 여기에서 한 point가 포함 되냐 되지 않냐를 classify하고, 동시에 L2 manitude offset field를 이용해 얼마나 offset이 떨어져 있냐를 예측한다.
일단 두번째 스테이지의 처음으로 돌아와서, 이전 스테이지로부터 사람이라고 생각되는 크롬 이미지를 받으면 ResNet-101에 크롭 이미지를 propagate한다. 이러면 아웃풋으로 나오는게 개의 채널인데(는 키포인트 개수), 한 키포인트 당 heatmap, offset 2개를 의미한다.
Propagation할 때
- atrous convolution
- bilinearly upsample
일단 이렇게 한 joint당 3개의 채널이 나오게 되면, 먼저 heatmap 채널에서는 target joint와 일정 범위보다 가까우면 1, 아니면 0이 되도록 학습시킨다. 그리고 2개의 offset 채널에서는 말 그대로 target offset(target - prediction)을 줄이도록 학습시킨다.
이렇게 하면 localization problem을 2개의 다른 문제로 쪼개어서 생각할 수 있다.
 위의 사진에서 볼 수 있듯이 우리가 예측한 heat map과 offset을 가지고 activation map을 구할 수 있다.
위의 사진에서 볼 수 있듯이 우리가 예측한 heat map과 offset을 가지고 activation map을 구할 수 있다.
모델을 학습시킬때는 모든 position과 key point들의 logistic loss의 합을 전체 loss로 두고 학습했다고 한다.
그리고 중요한 부분 중 하나가 여러 사람이 겹쳤을 때 heat map에 대한 로스를 어떻게 계산하느냐 였는데, 중간 레이어에서 heatmap loss를 계산할 때는 메인이 되지 않는 사람들은 그냥 무시하고, 마지막 레이어에서 처리할 때는 메인이 되는 사람의 heatmap disk만 맞다고 처리하고 크롭된 이미지에서 중간에 있지 않는 사람의 경우에는 마이너스로 처리했다.
3) New Keypoint Confidence Score Estimator
그리고 마지막으로 test time에서 human detector가 사람이라고 생각되는 부분을 크롭할 때 기준이 되는 pose detection score 기준을 새롭게 제시했다.
 위 수식에서 볼 수 있듯이, 단순히 person detector 에서 나오는 confidence score 뿐만 아니라 각 key point에 대한 confidence score까지 반영해, 실제로 성능(AP)이 확실하게 상승했다고 한다.
위 수식에서 볼 수 있듯이, 단순히 person detector 에서 나오는 confidence score 뿐만 아니라 각 key point에 대한 confidence score까지 반영해, 실제로 성능(AP)이 확실하게 상승했다고 한다.
3. Experimental
캡쳐해서 가져오지는 않았지만, 논문에서 제시하는 figure를 보면 사람들이 많이 붐벼있는 화면에서도 개개인을 굉장히 잘 찾고, 또 이 사람들의 key point을 굉장히 정확하게 찾아낸다. 다만 동물이나 인형, 또는 사람의 사진에서도 key point를 찾아내는 false positive도 여전히 있다.
 퍼포먼스를 보면 기존의 모델에 비해서 높은 성능을 보인다. Multi human pose estimation이라서 그런지는 모르겠지만 엔트리에 CMU-pose만 있어서 비교할 대상이 적어 아쉬웠다.
퍼포먼스를 보면 기존의 모델에 비해서 높은 성능을 보인다. Multi human pose estimation이라서 그런지는 모르겠지만 엔트리에 CMU-pose만 있어서 비교할 대상이 적어 아쉬웠다.
추가적으로 box detect module에서 어떤걸 사용해야 더 성능이 높게 나오는지에 대한 실험결과와, pose estimation module에서 뭐를 사용해야 성능이 높게 나오는지에 대한 실험결과가 나와있다.
4. Conclusion
이 논문에서는 사람들이 겹쳐있거나, 화면의 중앙에 사람이 위치하지 않은 "in wild" 에서 여러 사람의 key point를 잘 잡아낼 수 있는 2 stage detector를 제안한다.
개인적으로는 crowded scene에서 다른 모델들에 비해 이 논문에서 제안하는 모델의 성능이 좋다는 사실을 객관적으로 확인할 수 있었으면 좋았을 것 같다는 생각이 들었다. 물론 저 위의 experimental에서 가져온 내용도 성능이 좋기는 하지만 말이다 ,, ,
Reference
