NEURAL MACHINE TRANSLATION by jointly learning to align and translate 논문 정리
오늘은 랩실에서 논문 스터디가 있었던 NEURAL MACHINE TRANSLATION by jointly learning to align and translate 를 가져왔다. Transformer나 NMT는 정말 많이 쓰이는 구조이다보니까 논문을 읽지는 않았어도 어디서 정말 많이 들어본 구조였는데, 막상 논문을 읽어보는 건 처음이었다.
1. Introduction
보통 기존의 전통적인 번역 방식은 phrase-based translation system을 사용해왔다. 문장을 작은 구성요소들로 나누고, 각각을 최적화 하는 방식이었는데 한계가 있었다고 한다. 그 이후에 등장하게 된 대부분의 NMT는 encoder + decoder의 형태를 가진다. Encoder network가 들어온 인풋을 보고 문장을 일종의 feature vector (context vector)로 나타내고, decoder network가 이 feature vector를 다시 문장의 형태로 풀어내는 것이다.
이렇게 생긴 애들은 한계가 존재했는데 먼저 encoder network가 들어온 source sentence를 context vector로 압축할 때 단어 5개짜리 문장이 들어오던, 10개짜리 문장이 들어오던, 50개짜리 문장이 들어오던 동일한 길이의 context vector로 압축하다보니까 문장의 길이가 길어질 수록 성능이 떨어지는 양상을 보였다. 특히 이 성능 저하는 training 문장들에 있는 길이보다 더 긴 길이의 문장에 대해서 두드러졌다.
이 논문에서 지적하는 또 하나의 한계는 기존의 encoder는 문장을 순차적으로 받기 때문에 중간의 단어를 encoding할 때 이전에 들어온 단어의 정보에 의지해서 encoding해야한다는 것이다. 그리고 이 두가지의 한계를 극복할 수 있는 새로운 네트워크 구조 RNNsearch를 제안한다.
이 RNNsearch는 매번 word를 예측할 때마다 source sentence의 단어들에서 예측하려는 단어와 가장 연관이 높아보이는 단어를 찾고, 그 단어의 context vector와 이전에 예측했던 단어들을 이용해 현재 타임의 단어를 예측한다. 간단하게 다시 말하자면, 기존의 seq2seq에서는 인풋에 대한 하나의 fixed-length vector를 만들고 여기에서 차례차례 아웃풋 단어들을 뽑아냈다면, 이 논문에서는 각 단어에 상응하는 vector(annotation)를 만들어두고 이 벡터를 적절하게 조합해서 아웃풋을 예측한다.
2. Learning jointly to align and translate
논문에서는 짧게 기존의 neural machine translation에 대해서 간단하게 설명해준다. 사진을 넣어서 설명을 추가하고 싶지만 사진을 만들기 너무 귀찮으니까 패스..ㅎㅎ
간단하게 요약을 하자면, 초기의 translation task는 하나의 확률론적인 관점에서 source sentence x가 주어졌을 때 y의 조건부 확률을 최대화 하는 로 해석할 수 있었다고 한다. 그래서 이 확률을 크게 하도록 모델의 파라미터를 학습했다고 하는데, 최근에는 딥러닝을 이용하면서 이 조건부 확률의 분포 자체를 학습하는 방향으로 변화하게 되었고 그 중 가장 대표적인 게 RNN 기반의 encoder - decoder 이다.
이 논문에서는 기존의 encoder - decoder를 개선한 새로운 아키텍처를 제안한다. Encoder network에서는 bidirectional RNN을 사용했고, decoder network에서는 source sentence에서 target word에 영향을 많이 준 단어를 soft searching하면서 예측한다.
1) Encoder
 Encoder 부분은 상대적으로 기존의 Encoder 모듈과 유사하다.
다만 아까 introduction에서 잠깐 언급했었는데 기존 RNN 기반 encoder - decoder 의 문제점 중 하나가 vanilla RNN을 사용하기 때문에 현재 위치 이전의 정보만 가지고 있는 context가 나올 수 밖에 없다는 것이었다. 이러한 문제를 해결하기 위해서 bidirectional RNN을 도입한다. 기존의 Encoder가 받았던 정보와는 다르게 앞뒤의 정보가 잘 담겨있게끔 bidirectional RNN을 이용해서 양방향의 정보를 가지고 있는 annotation을 만들어낸다.
Encoder 부분은 상대적으로 기존의 Encoder 모듈과 유사하다.
다만 아까 introduction에서 잠깐 언급했었는데 기존 RNN 기반 encoder - decoder 의 문제점 중 하나가 vanilla RNN을 사용하기 때문에 현재 위치 이전의 정보만 가지고 있는 context가 나올 수 밖에 없다는 것이었다. 이러한 문제를 해결하기 위해서 bidirectional RNN을 도입한다. 기존의 Encoder가 받았던 정보와는 다르게 앞뒤의 정보가 잘 담겨있게끔 bidirectional RNN을 이용해서 양방향의 정보를 가지고 있는 annotation을 만들어낸다.
2) Decoder
Encoder part의 설명과 Figure 1에서 확인할 수 있듯이 input X에 대해서 hidden state가 앞에서 뒤로 가는 방향이 하나 있고, 뒤에서 앞으로 가능 방향이 하나 더 있는 것을 확인할 수 있다. 이렇게 만들어진 각 단어에 대한 annotation들을 만들고, input의 j번째 단어와 output의 i번째 단어가 얼마나 관련이 있는지 점수를 매기는 alignment model을 기반으로 만들어진 weight을 이용해서 annotation들을 weight sum한다.
수식은 논문에 나와있는데 그렇게 어렵지 않다. Softmax 수식이랑 vector의 weight sum 정도...?
Output의 이전까지의 state와 현재 hidden state를 이용해서 연관성을 찾아내는 alignment model의 경우에는 feedforward neural network를 사용해서, 다른 시스템과 함께 학습될 수 있도록 했다.
Alignment model이 직관적으로 이해가지 않을 수도 있는데, 아래 experimental 에서의 사진처럼 input과 output의 각 단어에서 input이 output에 얼마나 영향을 주는지를 수치화한 것이다. 다시 말해서, decoder가 output 단어를 만들어낼때 input 문장의 어떤 단어에 attention 해야할지를 알 수 있다.
3. Experimental
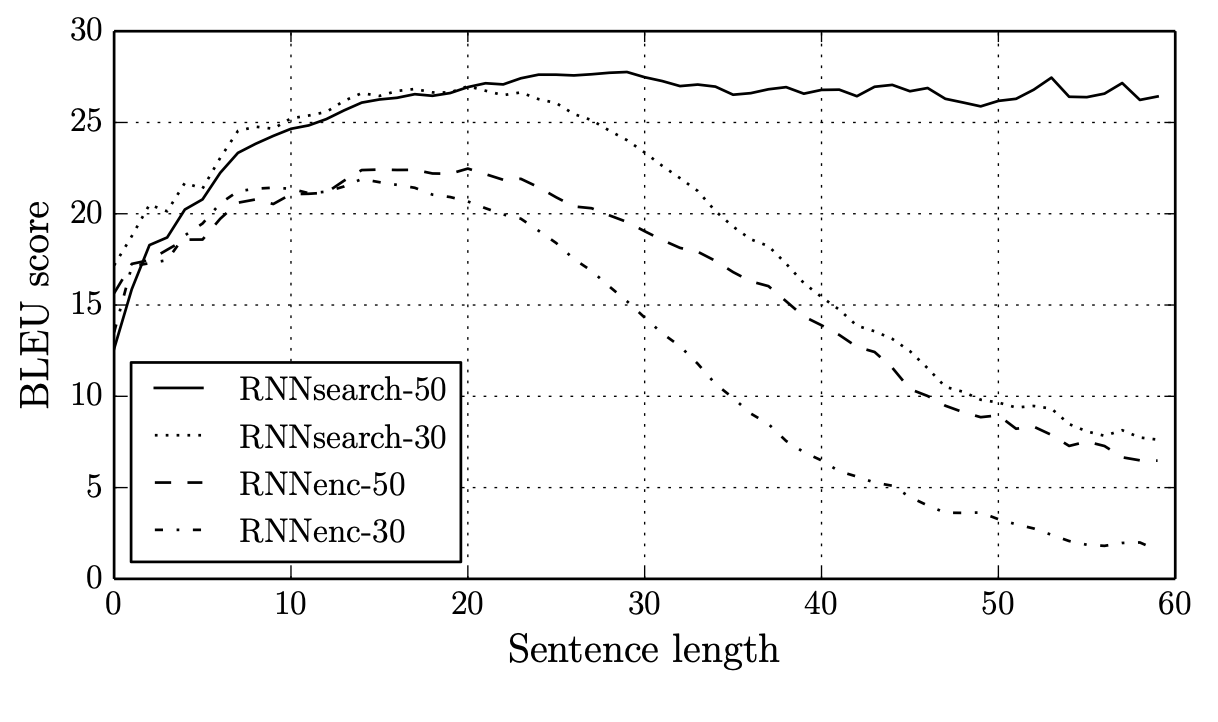
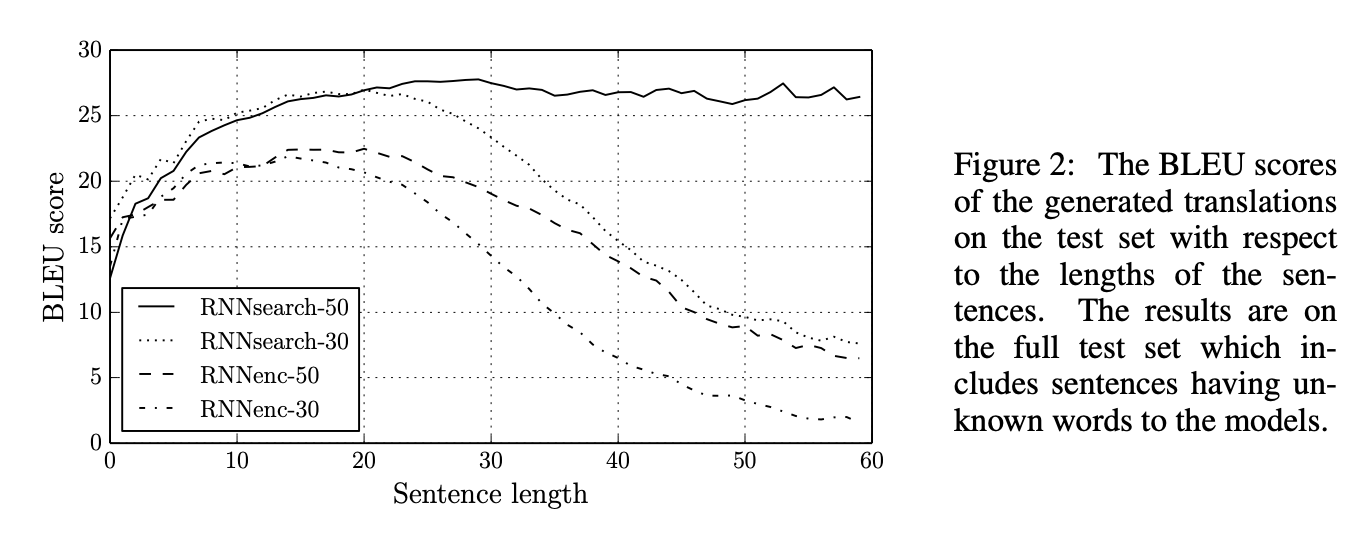
문장의 길이에 따른 모델의 성능 변화이다. 문장의 길이가 짧을때에도(10-20개) 성능이 높은 편이지만, 문장의 길이가 길어질수록 성능 차이가 엄청나게 벌어지는 것을 확인할 수 있다. 기존의 모델은 50개의 길이를 가지는 모델을 가지고 학습을 해도 문장의 길이가 길어질수록 성능이 급격하게 감소하지만, 여기에서 제안하는 RNNsearch의 경우에는 문장의 길이가 길어지더라도 성능을 그대로 유지하고 있다.
앞서 introduction에서 언급했던 기존 모델의 단점(context vector가 fixed-length vector로 표현되기 때문에 길어질수록 압축이 많이 되어버려 성능에 영향줄 수 있음)를 개선했음을 알 수 있다.
 이 사진은 영어와 불어 사이 각 단어의 alignment model 결과이다. 보면 어느정도 linear하게 연관이 있는 것을 확인할 수 있는데, 문장의 구성이 보통 주어 - 동사 - 목적어 의 구성으로 이루어진다는 걸 생각하면 이상한 일은 아니다. 우리나라 말로 생각해봐도 "내 이름은 해주야." 랑 "My name is haejoo."은 서로 영향을 주는 단어가 비슷한 곳에 위치함을 알 수 있다.
이 사진은 영어와 불어 사이 각 단어의 alignment model 결과이다. 보면 어느정도 linear하게 연관이 있는 것을 확인할 수 있는데, 문장의 구성이 보통 주어 - 동사 - 목적어 의 구성으로 이루어진다는 걸 생각하면 이상한 일은 아니다. 우리나라 말로 생각해봐도 "내 이름은 해주야." 랑 "My name is haejoo."은 서로 영향을 주는 단어가 비슷한 곳에 위치함을 알 수 있다.
다만 experimental에서 다루지 않아서 아쉬웠던 부분은 RNNsearch의 성능 개선에서 attention mechanism과 bidirectional RNN이 미치는 영향이 각각 어느정도였는지를 수치적으로 확인할 수 없었던 것이었다. 아무래도 birectional RNN보다는 alignment를 계산하는 attention이 더 성능 개선에 큰 영향을 미쳤을 것 같기는 하지만.. NMT/NLP 논문을 많이 못 읽어봐서 이건 더 공부를 해봐야 겠다..
그리고 computing time이나 메모리 소비량 등의 비교가 없는 것도 아쉬웠다. 내가 너무 object detection이나 human pose estimation 쪽만 읽어서 그런건지는 모르겠지만...^^ ;
4. Conclusion
이 논문에서는 기존의 neural machine translation에서의 문제를 해결하기 위한 새로운 아키텍쳐 RNNsearch를 제안한다. 먼저 encoder network에서는 bidirectional RNN을 이용해서 앞뒤 문맥을 모두 가지고 있는 annotation을 생성할 수 있도록 했다. 그리고 decoder network에서는 input이 output에 얼마나 영향을 미치는지를 계산하는 alignment model을 추가해 weight sum의 형태로 context vector를 만들어내고 이를 기반으로 단어를 생성한다.
하지만 아직 한계가 남아있는데, 잘 알려지지 않은 단어나 흔하지 않은 단어에 대해서는 모델이 잘 동작하지 않는다는 것이다.. 근데 진짜 이건 어떻게 해결해야할까? 현실적으로 모든 단어를 사용하는 training dataset을 만들 수도 없고, inference할때 confidence가 낮으면 무시하는 방향으로 가야하나..?
Reference
