
RESULT
- 과정 없이 바로 결과가 궁금하다면
[결과 보기]
Object
- 서울 지역마다 1시간마자 초,미세먼지 수치를 측정한 데이터를 mySQL 테이블에 불러와서 입력
- 간단한 DQL문으로 데이터 뽑기
- 어떤식으로 데이터를 불러내고 테이블을 관리하는지 메커니즘 이해하기
Before using SQL
>>> Required information
-
About standards

-
Data is csv
CREATE TABLE
데이터를 사용하기전에 우선 사용할 데이터베이스를 만들어 준다
CREATE DATABASE IF NOT EXISTS [데이터베이스_이름];
Enter...
Then, USE [데이터베이스_이름];USE 데이터베이스 를 한 뒤, 테이블을 생성해주어야 하는데
입력받을 데이터의 컬럼들이 어떤 유형인지 우선 파악해야 한다.
[테이블 컬럼 유형]
일시 데이터를 담을 적절한 Type - DATETIME
구분은 문자열이기 떄문에 VARCHAR
미세먼지, 초미세먼지를 단순 정수로 표현하기 때문에 INT
CREATE OR REPLACE TABLE [테이블_이름(airdata)]
( 일시 DATETIME, 구분 VARCHAR(50), 미세먼지 INT, 초미세먼지 INT);그리고 해당 데이터.csv 파일을 불러온다.
LOAD DATA LOCAL INFILE '파일경로/파일.csv'
REPLACE INTO TABLE airdata
COLUMNS TERMINATED BY ',' // 각 필드의 구분문자 ','
LINES TERMINATED BY '\n'
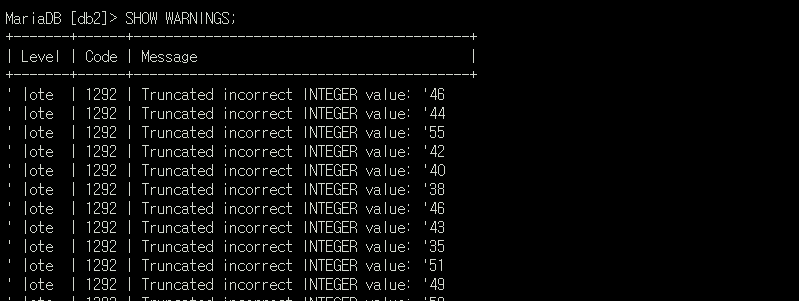
IGNORE 1 LINES; // 필드를 담은 행 무시근데 여기서 WARNINGS 가 뜬다.
csv파일에 공백('')이 존재하는 데이터가 있기 때문에 이러한 현상이 일어나는 것이다.
하지만 WARNING인 거지 데이터 입력은 전부 잘 됐을 것이다.
SELECT * FROM airdata;
데이터가 일단은 잘 들어간 것 같아 보인다.
확실하게 알기 위해서 WARNING에 관련한 데이터가 어떻게 들어갔는지 확인해보려고 한다.
csv로 부터 ''(작은 따옴표 2개) 으로 값을 받은 부분은 NULL로 돼 있을 것이기 때문에
해당 WHERE 조건으로 SELECT 해본다.
SELECT * FROM airdata WHERE
미세먼지 IS NULL OR 초미세먼지 IS NULL;
WARNING의 주인공인 '' 부분이 어떤 형태로 저장 됐는지 확인EMPTY SET
아무런 ROW도 SELECT 되지 않는다.
WHERE 안에서 NULL 값인것을 찾는게 아닌 csv 파일의 빈 값 '' 데이터를 SELECT 해봤더니, 그제서야 나온다.
- 해당 이미지에서 미세먼지 = NULL 로 표현했는데, 그렇게 하면 안된다.
NULL은 비교연산할때 IS NULL 로 해준다.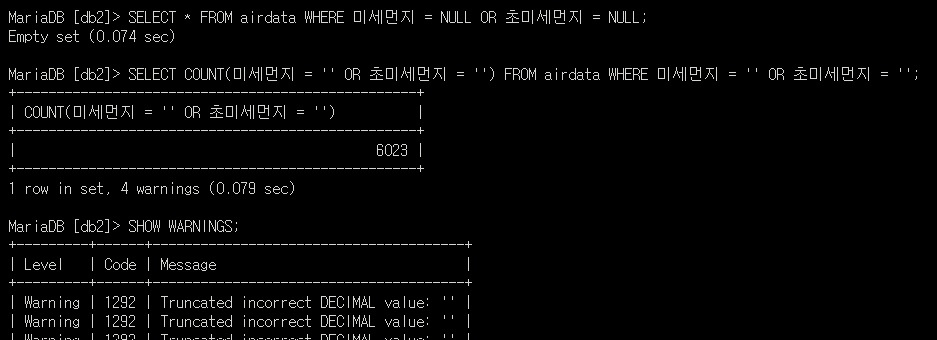
mySQL에선 ''을 NULL 처리 하는것이 아니라, '' 있는 그대로 받는다는 사실을 깨달았다.
그렇다면 어떻게 해결해야 할까??
테이블로 데이터를 입력받을때 데이터가 '' 일 경우를 처리해주면 된다.
우선 airdata의 데이터를 삭제하고 다시 csv 파일을 입력한다
DELETE FROM airdata;
// airdata의 모든 row 삭제
LOAD DATA LOCAL INFILE '파일경로/파일.csv'
REPLACE INTO TABLE airdata
COLUMNS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@일시, @구분, @미세먼지, @초미세먼지) SET
일시 = @일시, 구분 = @구분, 미세먼지 = NULLIF(CONVERT(@미세먼지, INT) ,''),
초미세먼지 = NULLIF(CONVERT(@초미세먼지, INT), '');COVERT로 해주면서 INT외 다른 값을 받아서 제대로 된 데이터를 못받는 상황을 방지하였고, (초)미세먼지 COLUMN들에 입력받는 데이터가 '' 일 경우 NULL 값으로 치환하게끔 설정해주었다.
1. SELECT COUNT(*) FROM airdata WHERE 초미세먼지 IS NULL;
2. SELECT * FROM airdata WHERE 미세먼지 IS NULL OR 초미세먼지 IS NULL;
3. SELECT * FROM airdata;해당 SQL문으로 데이터들이 문제없이 전부 잘 들어간 것을 확인 할 수 있다.
위와 같이 2022데이터.csv를 입력 받은 방식으로 테이블 한개를 더 만들어서 2021자료.csv를 입력받는다.
CONCLUSION
- INSERT CSV를 할때 테이블 유형과 맞지않는 잘못된 데이터가 들어온 경우를 처리해줘야한다.
DQL WITH AIRDATA
REQUIRED)
2022 서울 대기질 자료를 저장한 테이블 이름 : airdata2022
2021 서울 대기질 자료를 저장한 테이블 이름 : airdata2021
-
각 지역마다 미세먼지와 초미세먼지 평균 (2022), (2021)
SELECT 구분,AVG(미세먼지), AVG(초미세먼지) FROM airdata2022 GROUP BY 구분; //2022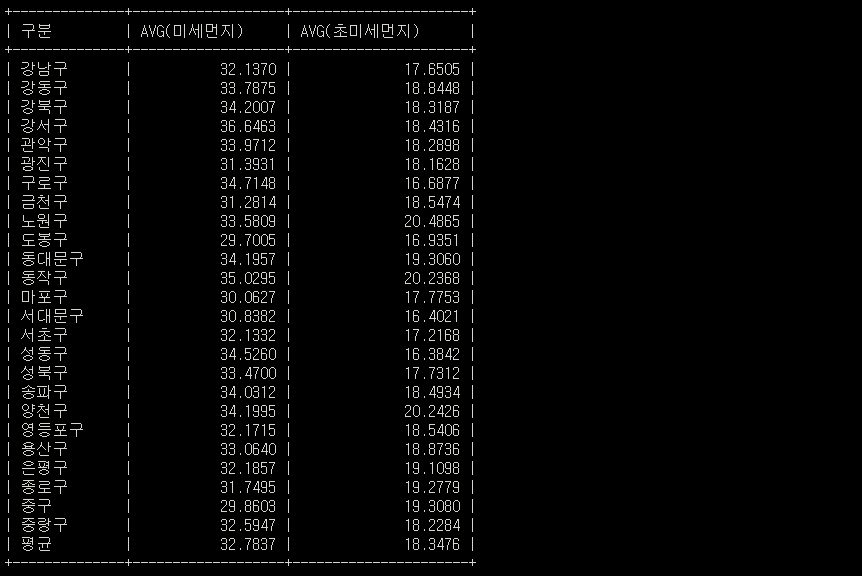
SELECT 구분,AVG(미세먼지), AVG(초미세먼지) FROM airdata2021 GROUP BY 구분; //2021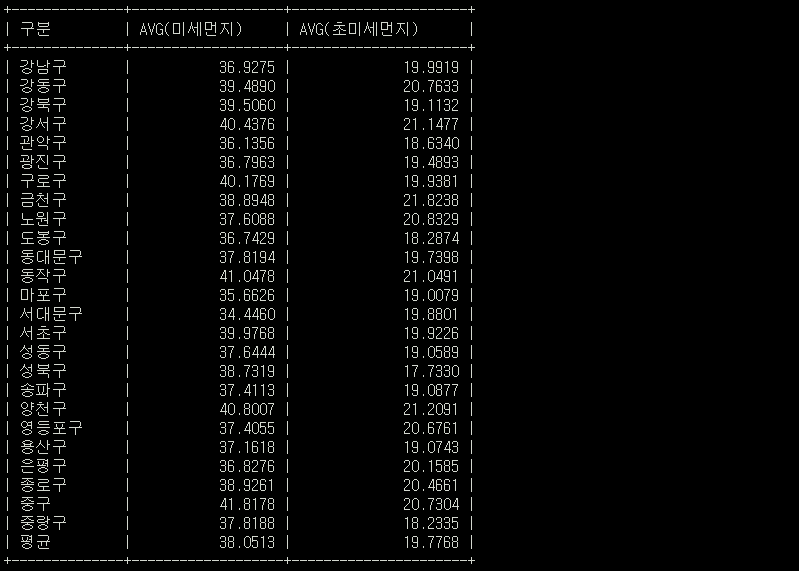
해당 두 결과 Relation Table을 이용해서 한눈에 간편하게 재작년 평균에 비해 작년의 대기질 수치가 얼마나 달라 졌는지 알아내보자
1년간 1시간마다 측정한 데이터인지라 JOIN할 두 데이터가 워낙 커서 현재 환경에선 아쉽지만 JOIN시 서버 셧다운이 일어난다. 그런 관계로 목적이 SQL 숙련 및 학습이기 떄문에 2022,2021 데이터에서 각 지역의 평균 미세먼지와 초미세먼지를 추출하여 2022,2021평균테이블에 입력하였다.👇👇CREATE OR REPLACE TABLE avgAIR1 ( 구분 VARCHAR(50), 미세먼지 INT, 초미세먼지 INT ); //2022평균 CREATE OR REPLACE TABLE avgAIR2 ( 구분 VARCHAR(50), 미세먼지 INT, 초미세먼지 INT ); //2021 평균 //2022,2021 평균 데이터 입력 INSERT INTO avgAIR1 (구분, 미세먼지, 초미세먼지) SELECT 구분, AVG(미세먼지), AVG(초미세먼지) FROM airdata2022 GROUP BY 구분; INSERT INTO avgAIR2 (구분, 미세먼지, 초미세먼지) SELECT 구분, AVG(미세먼지), AVG(초미세먼지) FROM airdata2021 GROUP BY 구분;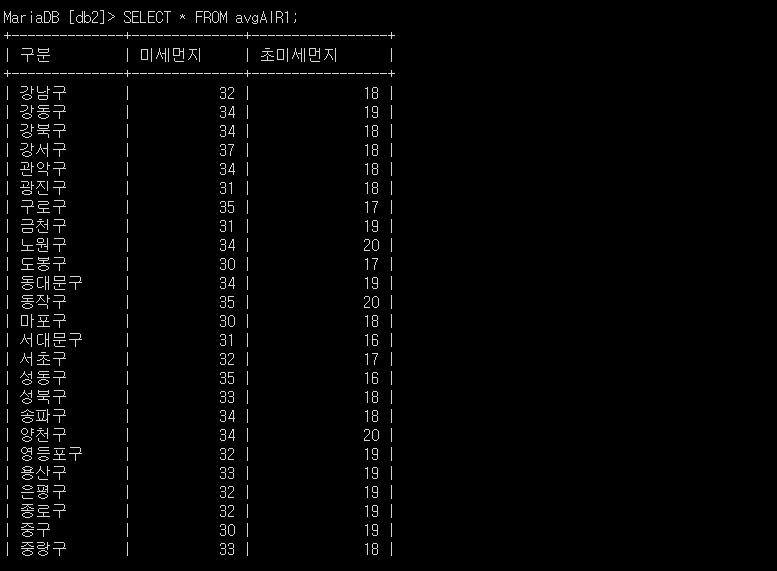
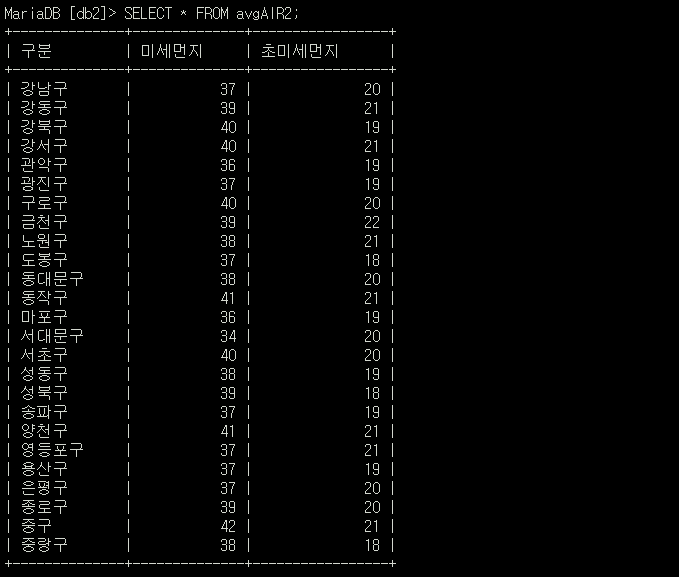
-
작년 (초)미세먼지 수치와 재작년 (초)미세먼지 수치의 변화율 구하기
JOIN을 활용하여 서로 다른 테이블에 있는 데이터들을 묶어준다
SELECT avgAIR1.구분, avgAIR1.미세먼지 AS 미세먼지평균_2022, avgAIR1 초미세먼지 AS 초미세먼지평균_2022, avgAIR2.미세먼지 AS 미세먼지평균_2021, avgAIR2.초미세먼지 AS 초미세먼지평균_2021 FROM avgAIR1 INNER JOIN avgAIR2 ON avgAIR1.구분 = avgAIR2.구분;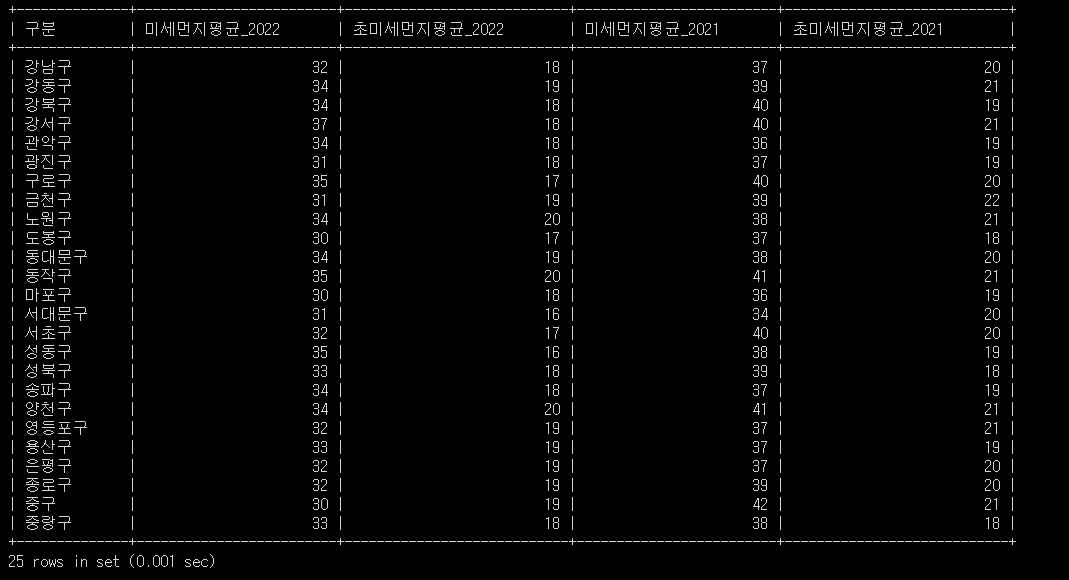
원하는 데이터를 SELECT 하기 위해 컬럼명을 조정해준다.
RESULT
SELECT avgAIR1.구분,
(avgAIR1.미세먼지-avgAIR2.미세먼지) AS 미세먼지변화율_2022,
(avgAIR1.초미세먼지 - avgAIR2.초미세먼지) AS 초미세먼지변화율_2022
FROM avgAIR1 INNER JOIN avgAIR2 ON avgAIR1.구분 = avgAIR2.구분;
해당 결과를 보면 2021년도에 비해 2022년도에 전체적으로 대기 상태가 나아진 것을 볼수있다.
그 수치 또한 많이 나아졌다.
전체적으로 동일하게 감소 했다는건 굉장히 의미 있는 것이라고 생각하는데, 코로나 때문인가..?
아무런 영향도 없다고는 생각하기 어려울듯 하다
