단순 CCTV 수와 인구대비 CCTV 비율을 볼 때 CCTV가 많은 구는 강남, 양천, 서초, 관악, 은평, 용산이다. 반면, CCTV 비율이 높은 구는 종로, 용산, 중구가 1위 그룹이다.
비율로 데이터를 보아도 전체 경향과 함께 보지 않으면 데이터를 제대로 이해시키 여러울 듯 하다.
따라서 경향을 파악할 필요가 있다!!
경향을 파악하기 위해서 먼저,
- 데이터 확인하기
data_result.head()인구수와 소계 칼럼으로 scatter plot 그리기
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid()
plt.show()
drawGraph()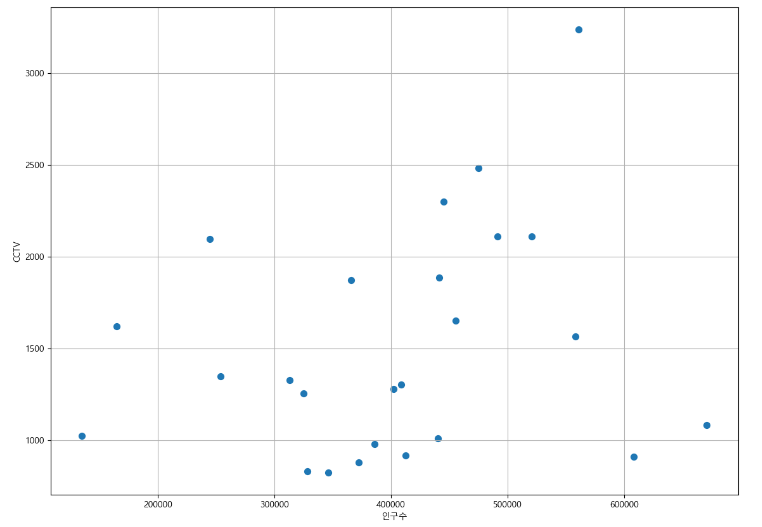
위의 그래프를 보면 인구 수가 높아질수록 CCTV가 증가하는 것이 보이긴 하다. (특별히 높거나 낮은 거를 제외하면)
이를 더 자세히 알아보기 위해서는 데이터를 하나의 직선으로 표현하여 확인해 불 수 있다. 이것을 '선형회귀(Linear Regression)'라고 한다.
선형회귀란?
데이터를 하나의 직선으로 표현하는 것을 의미한다.
선형회귀 numpy를 이용해 트렌드 파악하기
Numpy를 이용한 직선 만들기
numpy 가 제공하는 간단한 함수를 이용해서 1차 직선을 만들어 그래프로 비교해보자.
- np.polyfit(): 직선을 구성하기 위한 계수를 계산
- np.poly1d(): ployfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
import numpy as np- data_result["인구수"]가 x축, data_result["소계"]가 y축인 1차식이 만들기
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
fp1-> array([1.11155868e-03, 1.06515745e+03])
x기울기가 1.11155868e-03, y절편이 1.06515745e+03이다.
- polyfit 에서 찾은 계수를 넣어서 함수 완성하기
f1 = np.poly1d(fp1)
f1-> poly1d([1.11155868e-03, 1.06515745e+03])
f1에 polyfit 에서 찾은 계수를 넣어서 함수를 만들어 넣었기 때문에 변수가 아니라 함수가 된다.
- 인구가 40만인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV 수는?
f1(400000)-> 1509.7809252413338
- 경향선을 그리기 위한 X 데이터 생성
- np.linespace(a, b, n): a부터 b까지 n개의 등간격 데이터 생성
fx = np.linspace(100000, 700000, 100)=> 10만부터 70만까지의 사이에 100개의 데이터를 등간격으로 만들어라.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g") # 경향선 추가
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()fx: 앞에서 정한 100개의 데이터
f1(fx): polyfit으로 만든 직선의 결괏값
lw: linewidth로, 선 굵기
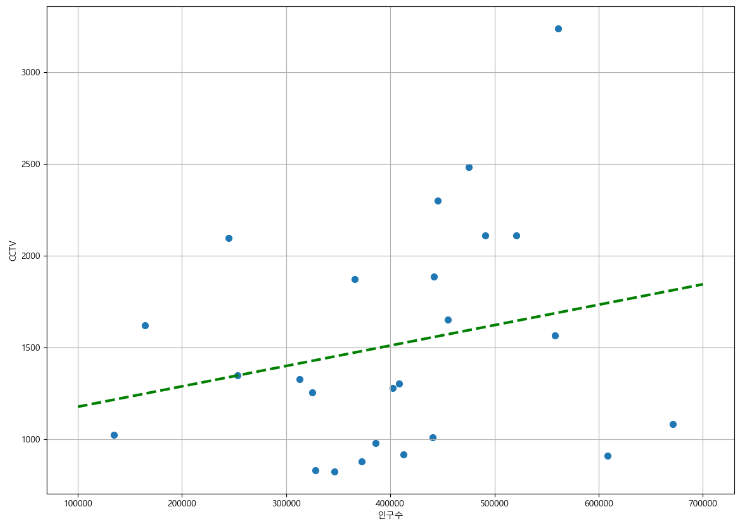
인구대비 CCTV 개수도 그리고 경향도 표현했지만, 그래프 자체로는 아직 부족하다!
