- 필요한 모듈 import
- 먼저 numpy와 pandas를 사용한다.
import numpy as np
import pandas as pd- 데이터 읽기
# 데이터 읽기
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr") # thousands 숫자값을 문자로 인식할 수 있어서 설정
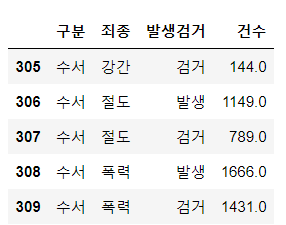
crime_raw_data.head()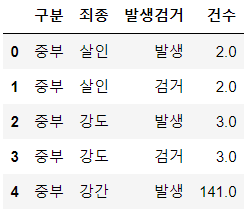
숫자들이 콤마(,)를 사용하고 있어서 문자로 인식될 수 있다.
따라서 천단위 구분(thousands-',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽는다.
- 데이터 정보 확인하기
crime_raw_data.info()
- info(): 데이터의 개요 확인하기
- RangeIndex가 65534인데, 310개이다.
- 특정 칼럼에서 unique 조사
crime_raw_data["죄종"].unique()nan 값이 들어가 있다.
- NaN값 확인하기
crime_raw_data["죄종"].isnull()
#isnull이라는 메서드를 이용하면 null값들이 얼마나 있는지 boolean 타입으로 나옴
- 데이터 프레임 형태로 NaN값 나타내기
crime_raw_data[crime_raw_data["죄종"].isnull()]
# 원래 crime_raw_data에 마스킹을 씌어주면 데이터 프레임 형태로 나옴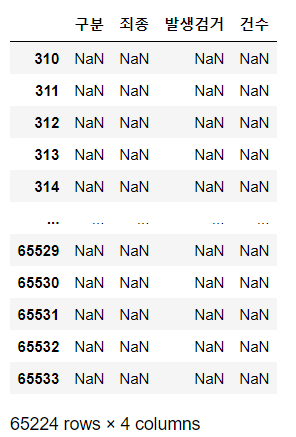
nan값이 훨씬 더 많으니 nan 값이 아닌 값들만 가져와서 데이터 분석을 하도록 판단해야 한다.
- null 값이 아닌 데이터만 불러오기
crime_raw_data[crime_raw_data["죄종"].notnull()]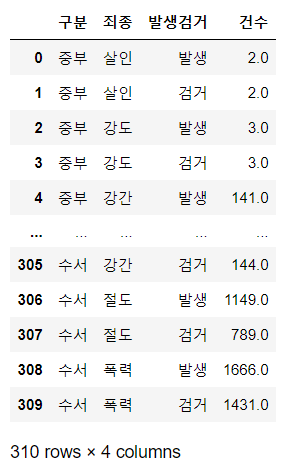
- null이 없는 즉, 조건에 맞는 데이터들만 crime_raw_data에 담기
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]- null이 없는 데이터의 개요 확인하기
crime_raw_data.info()
아무 문제 없는 것을 확인할 수 있다.
- 데이터 탐색하기
crime_raw_data.head()
crime_raw_data.tail()