[Paper Review] Fine-grained Sentiment Classification using BERT
Manish Munikar, Sushil Shakya, Aakash Shrestha. 2019. Fine-grained Sentiment Classification using BERT. Pulchowk Campus, Institute of Engineering, Tribhuvan University.
앞서 포스팅했던 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문을 이해한 후 본 논문을 읽으면 좋을 것이다.
1. Introduction
sentiment classification은 단어, 문장 등의 텍스트를 사전에 정의한 sentiment 클래스로 분류하는 supervised machine learning task이다.
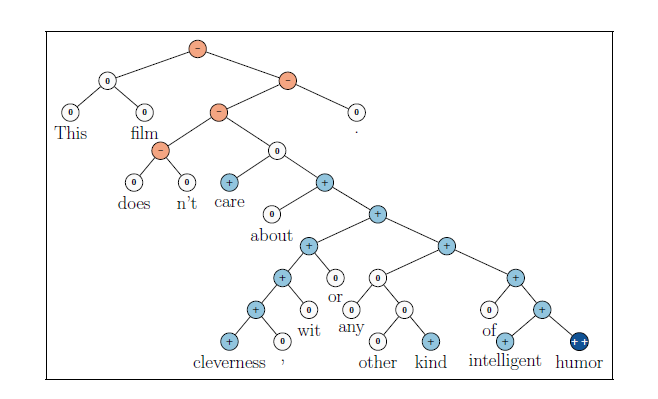
흔히 알려진 binary sentiment classification은 텍스트를 positive 또는 negative 2가지로만 분류하지만, fine-grained sentiment classification에서는 아래 그림과 같이 5가지의 클래스로 텍스트를 분류한다.

다른 언어 모델과 마찬가지로 sentiment classification 모델은 정해진 크기의 숫자 벡터를 input으로 가진다. 그동안 텍스트의 유의미한 정보를 숫자 벡터에 잘 담을 수 있도록 하는 다양한 NLP 모델이 개발되었는데, 대표적으로 구글이 만든 BERT가 있다. BERT는 양방향에서 문맥을 이해하는 transformer 구조 기반의 모델로 많은 NLP task들을 성공적으로 잘 수행한다.
선행 연구에 따르면 BERT는 binary sentiment classification task인 SST(Stanford Sentiment Treebank)-2 dataset에서 좋은 성능을 보였다. 따라서 본 논문에서는 BERT가 fine-grained sentiment classification도 잘 수행할 수 있는지를 확인하고자 했다.
2. Dataset
실험을 위한 dataset으로는 11,855개의 영화 리뷰 문장을 포함하고 있는 SST를 사용했다. SST는 약 21만 개의 labeled text를 가지고 있어 단어, 구문, 문장의 sentiment를 학습하기 좋을 것이라고 판단했기 때문이다.
SST의 각 문장은 Stanford constituency parser에 의해 트리 구조로 쪼개진다. 이때 root node에는 문장 전체가 존재하게 되고, leaf node에는 문장을 이루는 단어들이 들어간다. 그리고 각 node는 수작업으로 labeling이 되어있다.
아래 그림은 SST dataset의 한 리뷰 문장을 트리 구조로 나타낸 것이다.

SST-5에는 5개의 sentiment label(very negative, negative, neutral, positive, very positive)이 있는데, 각각 0에서 4까지의 숫자로 표현된다. 만약 이를 positive/negative로만 분류를 하면 SST-2 dataset이 된다.
실험을 위해, SST-2와 SST-5 각각의 모든 node의 label을 예측하는 task와 root node의 label을 예측하는 총 4가지 task를 수행하였다.
3. Methodology
3.1 BERT
BERT는 unlabeled text로부터 bidirectional representation을 학습할 수 있는 사전 훈련 모델이다. Masked word prediction과 Next sentence prediction을 거치며 양방향에서 문맥을 파악할 수 있게 되고, 사전 훈련된 파라미터에 downstream task의 종류에 따른 하나의 layer가 추가되어 fine-tuning이 이루어진다.
BERT의 구조는 아래 그림과 같다.
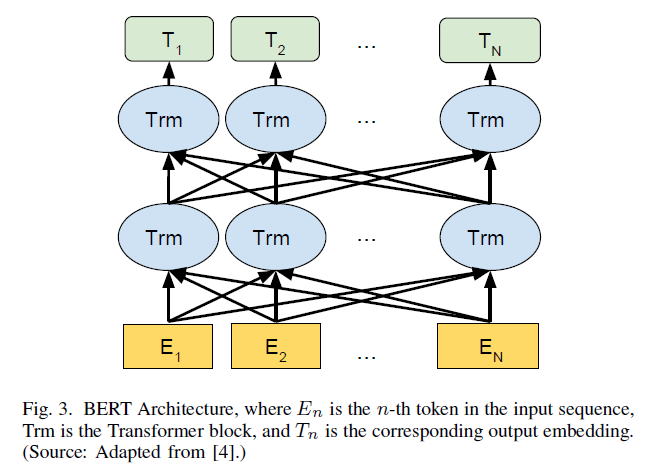
BERT의 input에는 특별한 token이 필요하다. 각 sequence의 시작에는 분류 token인 [CLS] token이 있어야 한다. 그리고 문장을 구분하는 역할을 하는 [SEP] token도 매 문장의 끝에 와야 한다.
실험을 위해 BERT Base와 BERT Large 모델을 사용하였는데, 두 모델에 대한 세부 정보는 아래 표와 같다.

3.2 Preprocessing
리뷰 텍스트를 모델에 투입시키기 전 다음과 같은 전처리 과정을 거친다.
1) Canonicalization
리뷰 텍스트의 숫자, 기호들을 제거하고 대문자를 모두 소문자로 바꾸어준다.
2) Tokenization
WordPiece tokenizer를 이용해 텍스트를 token들로 쪼갠다. 'playing'이라는 단어를 'play'+'##ing'로 분해하는 것처럼, 각 단어를 접두사와 접미사, 어근으로 쪼갠다.
3) Special token addition
마지막으로 [CLS]와 [SEP] token을 적절한 위치에 추가한다.
3.3 Proposed Architecture

논문에서 제안한 모델의 구조는 위 그림과 같다. 먼저 preprocessing을 거친 후, BERT를 통해 sequence embedding 값을 계산한다. 그 다음으로 dropout 층에서는 0.1의 확률로 몇몇 뉴런들을 dropout 시켜 과적합을 방지한다. 이 dropout 층은 훈련 단계에서만 사용되고, 추론 단계에서는 생략된다. 마지막으로 softmax classifier를 통과하여 input text가 어떤 class로 레이블링 될지를 예측한다.
4. Experiments and Results
4.1 Comparison Models
제안된 모델의 성능을 기존 모델과 비교하기 위해, 7개의 comparison model을 설정했다. 먼저 word embedding 모델 중 대량의 텍스트 corpus로 사전 훈련된 word vector와 paragraph vector가 sentiment classifier에 적용되었다. 그리고 RNN 모델 중에서는 standard RNN과 좀 더 정교한 RNTN을 사전 훈련 없이 사용했다. 또한 recurrent network를 대표하는 left-to-right LSTM과 bidirectional LSTM를 도입했고, 마지막으로 1차원 CNN이 feature extractor로써 사용되었다.
4.2 Evaluation Metric
SST는 dataset의 수가 각 클래스마다 균등하게 분포되어 있는 특징이 있다. 따라서 올바른 예측의 수를 전체 예측의 수로 나눈 accuracy measure를 모델 성능 평가의 지표로 이용하였다.

4.3 Results
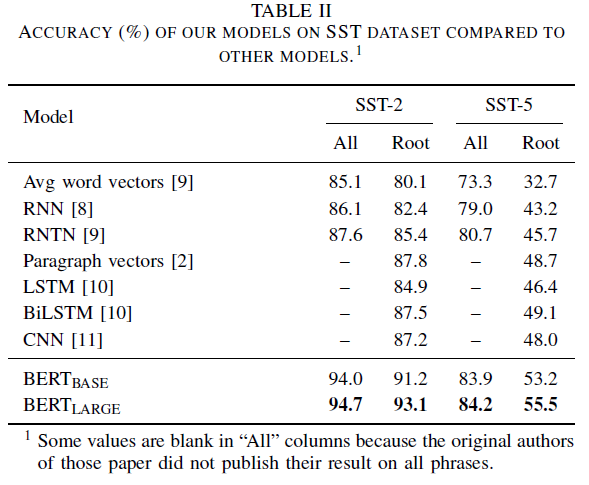
실험 결과, 아래 Table II에서 볼 수 있듯이 BERT Base와 BERT Large가 기존 모델들에 비해 훨씬 높은 accuracy measure를 가졌다. BERT가 선행 연구에서 다루지 않았던 SST-5 task에 대해서도 좋은 성능을 보인다는 것을 확인할 수 있었다.
BERT의 성능이 정말 뛰어났다는 것을 다시 한 번 느낄 수 있었다. 이 논문에서는 수작업을 통해 이미 labeling이 되어있는 SST data를 사용했는데, 데이터마이닝 랩에서 진행 중인 프로젝트의 data는 labeling이 되어있지 않은 것 같아서 이 문제에 대해 좀 더 고민해보기로 했다.
