- CVPR 2016
- ILSVRC 15 (ImageNet 대회)
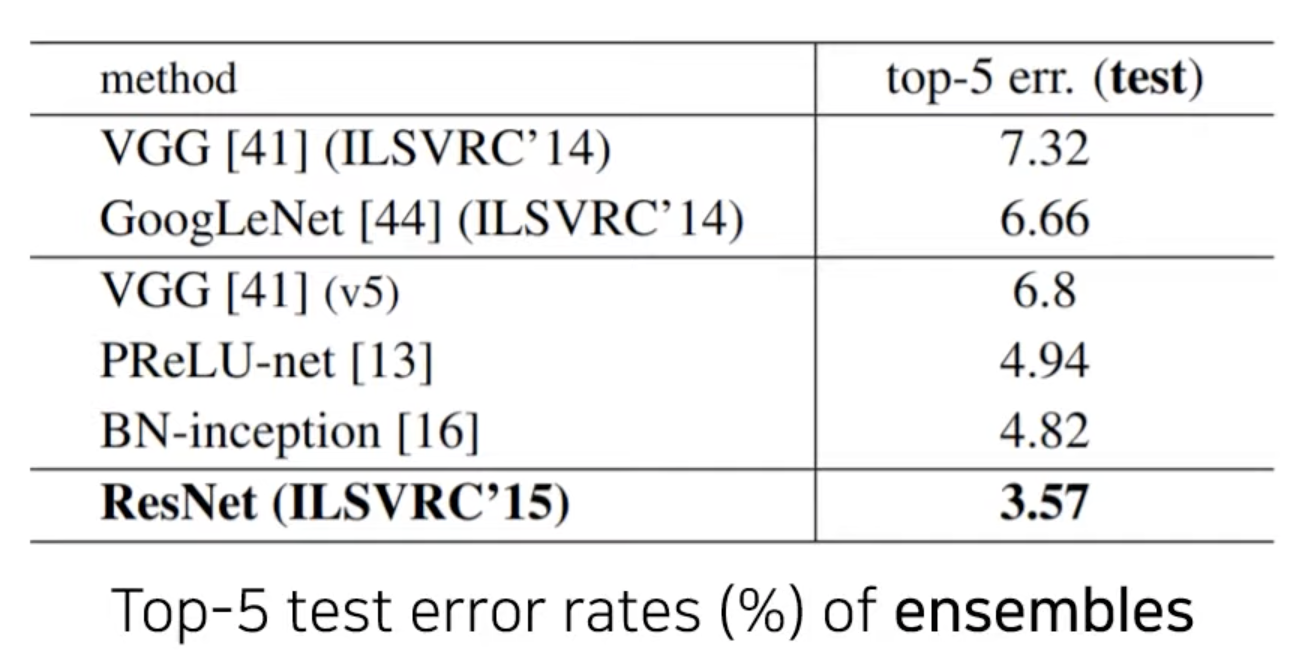
- top-5 error rate : 3.57%

이 논문이 좋은 평가를 받는 이유
1. 성능이 뛰어났다
2. 논문에서 제안한 아이디어가 쉽다.
1. 기존 CNN의 문제점
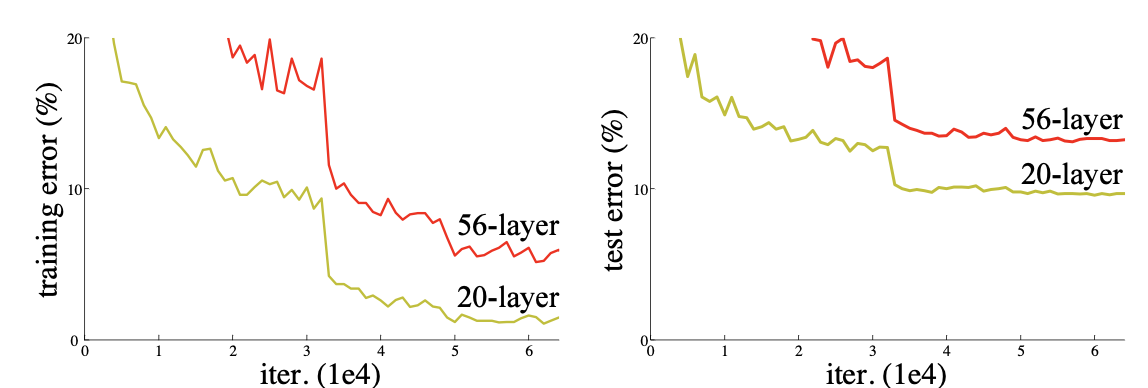
-
Is learning better networks as easy as stacking more layers?
-> 가장 큰 문제는vanishing/exploding gradients
->normalized initialization로 사실상 크게 해결 (He initialization) -
그러나 layer를 많이 쌓았을 때 위 그림처럼
training error자체가 적게 쌓았을 때보다 높은 결과가 발생. (test error를 보면 overfitting의 문제가 아님.)
-> 논문이 설명하는 이유 : 단순 layer를 깊게 쌓는다면 모델의 학습 난이도가 높아짐(정확히는, 우리가 의도 했던대로 최적화를 시키는 것이 쉽지 않음.)
2. 핵심 아이디어 - Residual Learning
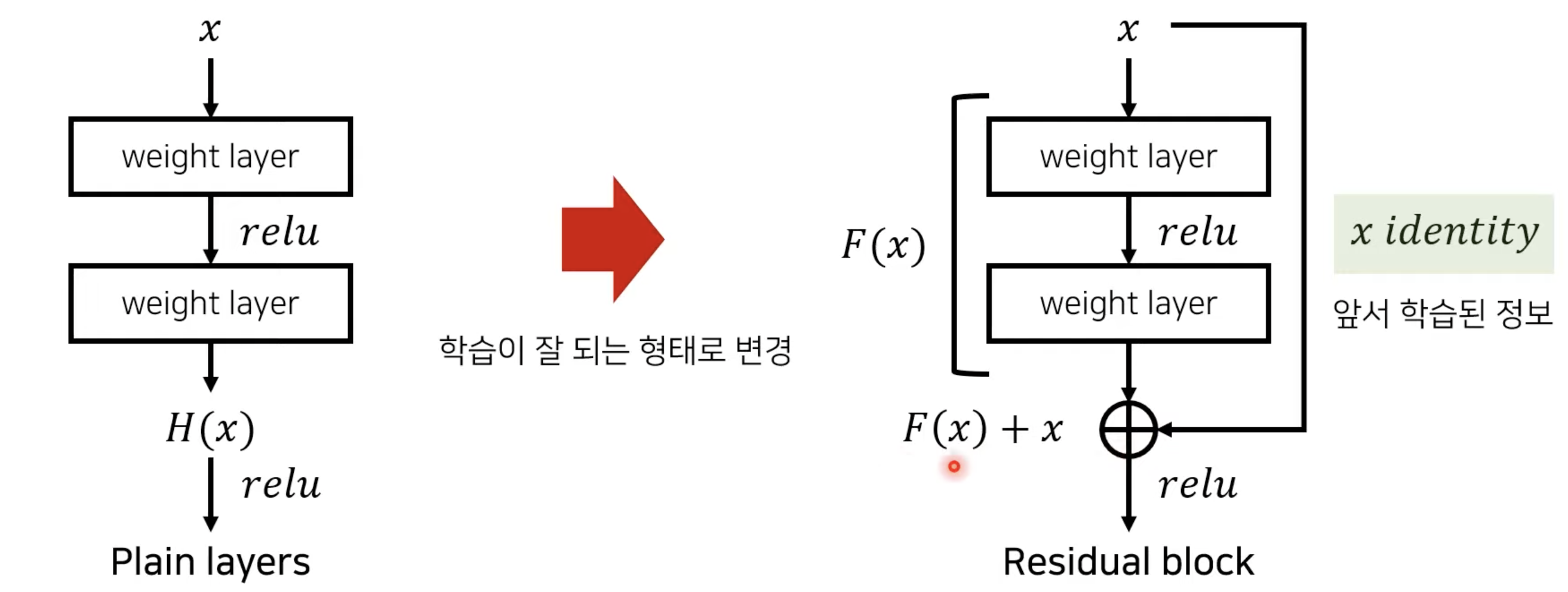
- H(x) = F(x) + x
-> F(x) = H(x) - x
- F(x) 는 weight layer(정확히는 3x3 conv) 한 번, activate function 한 번, 그리고 다시 weight layer 통과하고 나온 값을 말함. 두번째 activate function 들어가기 전.
- H(x)는 이상적인 함수를 말함. 우리가 학습시키는 목표
이때, F(x)를 H(x)에 맞추는 것보다, F(x)+x를 H(x)에 맞추는 것이 더 쉽다는 것이 논문의 기본 아이디어. (가설)
-- 일단 여기서 x를 그대로 더해주는 것을 identity mapping이라고 부른다.
-- 두번째 nonlinear layer 에 들어가는 값이 F(x)+x이기 때문에 결국 우리는 x와 F(x)+x의 차이인 F(x)만 잘 학습시켜주면 되는 것이고 그렇기 때문에 Residual Learning이라고 부름.
-> 왜 이 가설이 잘 맞을까? 논문에서 간단한 이유를 설명하는데, H(x)가 극단적으로 identity mapping과 똑같다고 해보자. 즉, H(x) = x 인 상황. 이 때 F(x) = x 가 되도록 weight를 조절하는 것보다 F(x) = 0 이 되도록 조절하는 것이 훨씬 쉬움. 또한 적어도 얕은 층에서 나온 결과 값에 단순히 identity mapping만을 해도 training error가 올라가지는 않음.
- 이 설명으로 미루어 보았을 때 깊게 쌓았는데 training error가 더 올라가는 이유를 유추해볼 수도 있을 것 같다.
3. 자세한 수식
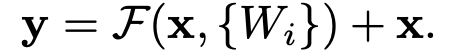
- 이 논문에서는 이렇게 사용.
- F(x)와 x의 차원이 일치해야함.
- 진정한 의미의 identity mapping
- Extra parameter 필요 없음. 계산 복잡도도 증가 안함.
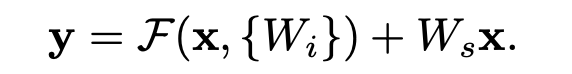
- F와 x의 차원이 다르다면 Ws로 projection도 할 수 있음. 완전 단순히 차원 맞추는 용도로.
- 위의 진정한 identity mapping도 square matrix Ws로 할 수 있으나 그냥 x 더하는 것도 충분히 경제적이라 함.
- 논문에서는 1x1 conv라고도 표현하는데 궁극적으로 같은것임.
4. 구현과 실험
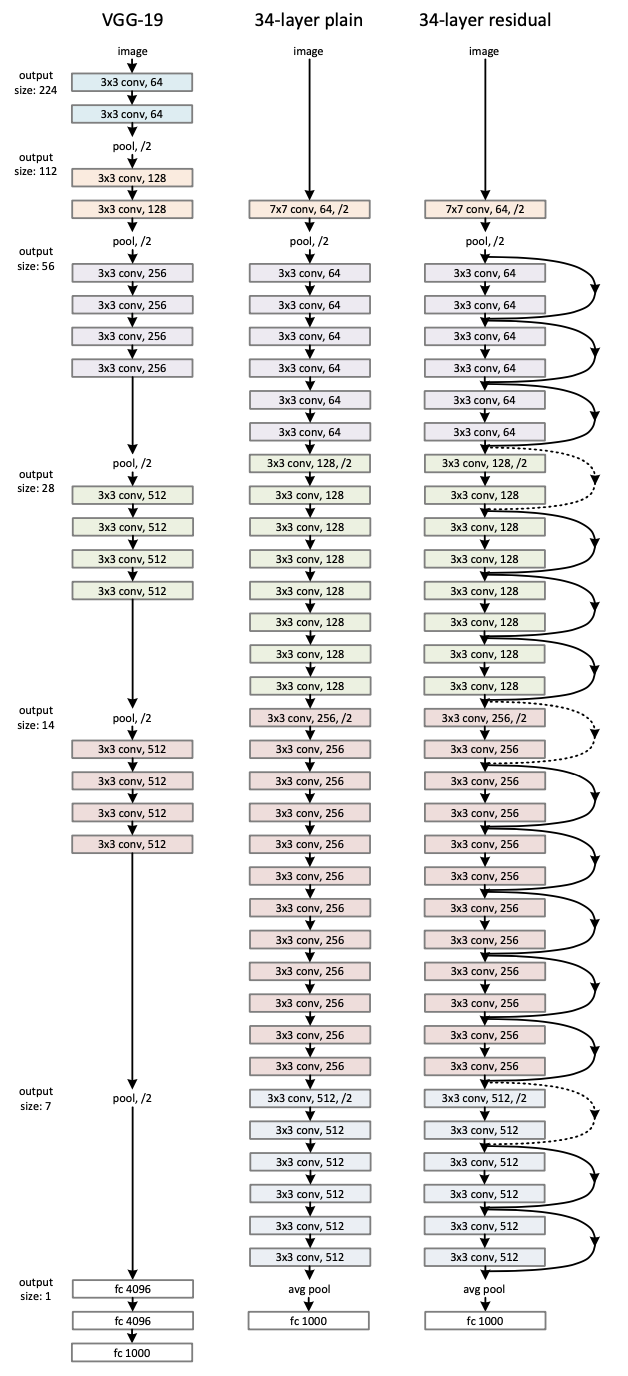
Plain network
- VGG를 본따서 만든 layer를 많이 쌓은 형태
Residual network
- 점선은 Identity mapping 하고, 0으로 padding 하던가 아니면 projection 하던가 둘 중 하나 선택
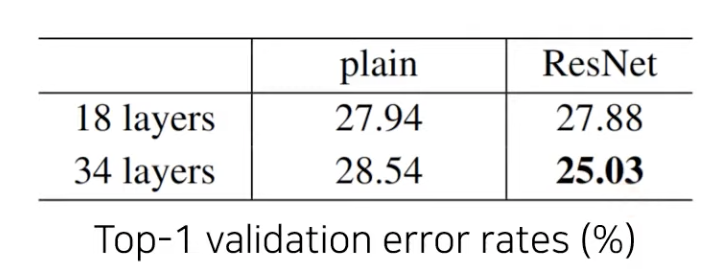
대회에서의 앙상블 모델
단순 single model
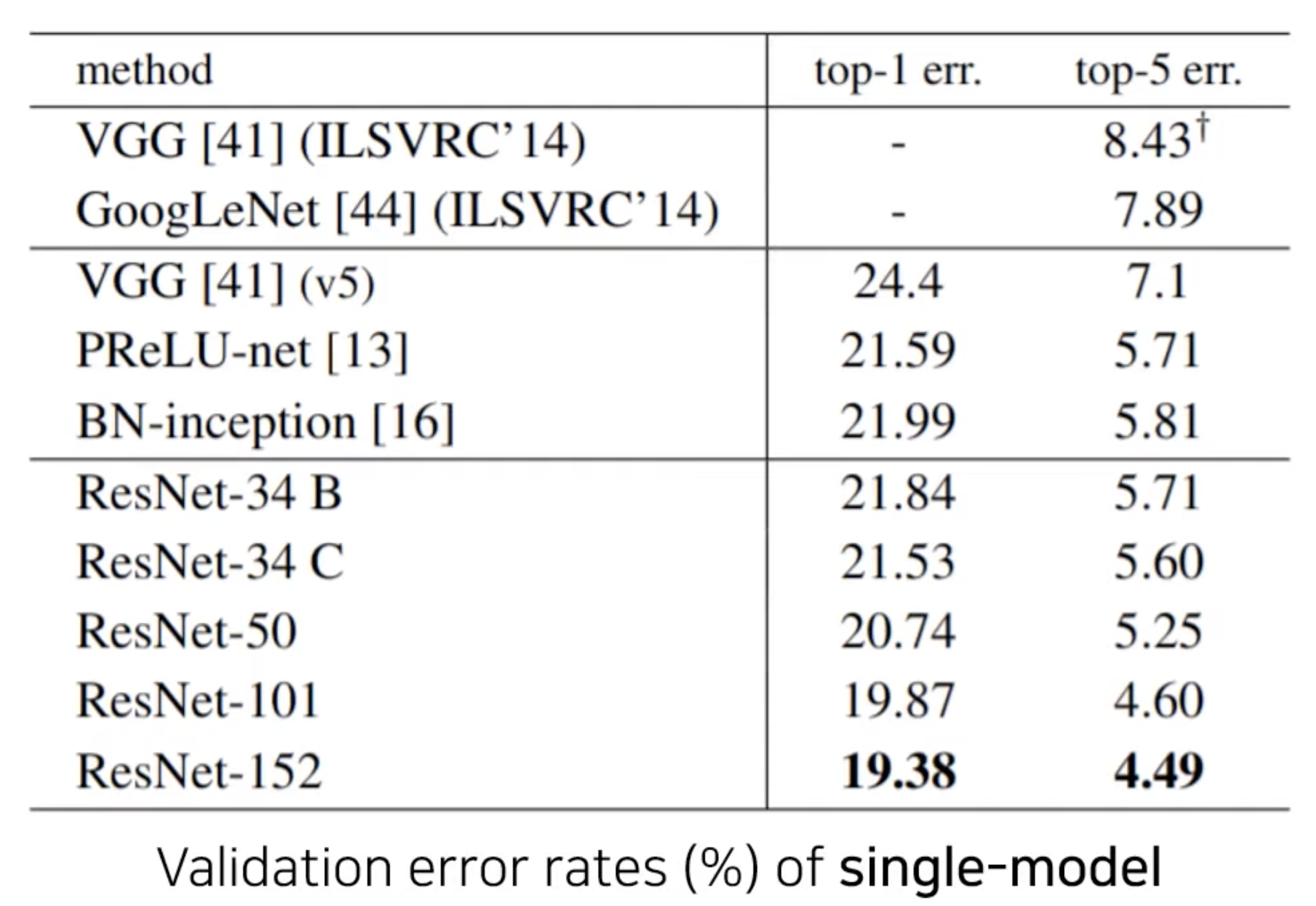
ImageNet dataset으로 152 layer를 쌓아 VGG보다 깊지만 적은 복잡도, 적은 파라미터, 높은 성능을 내게 됨. CIFAR-10도 마찬가지.
컴퓨터 비전에서 깊게 layer를 쌓는 것은 매우 중요. residual function을 사용해서 깊게 쌓은 경우 COCO dataset을 이용한 object detection, segmentation 같은 다른 분야에 대해서도 좋은 성능을 낸다.
