1. 개요
Redis 캐싱을 활용하여 데이터 조회 성능을 개선할 수 있다.
하지만 이것 하나만으로 Redis 캐싱을 사용하기엔 너무 단순한 접근이 될 것이며, 모든 조회 서비스에 캐싱을 적용한다는 것은 비효율적이고 오히려 불필요한 비용소모가 발생할 것이다.
그리고 무엇보다 단순히 @Caching 어노테이션을 사용하고 "Redis 캐싱 사용했다!"라고 한다면 그것을 개발로 볼 수 있겠는가..그런 생각을 가지고 개발자라 할 수 있겠는가..
단순히 Redis 캐싱을 사용하여 조회성능을 개선하는 것을 기대하는 것 보다, 인덱스와 Redis 캐싱을 조합하여 적절한 전략을 생각하고 상황에 맞게 적용하는 것이 중요할 것이다.
어노테이션을 사용한 것에 그치지 않고, "어떠한 전략을 생각할 수 있고, 어떠한 상황에 적용 가능할 지" 고민해본 과정을 기록하였다.
2. Redis가 유일한 캐싱 방안은 아니다.
캐싱전략을 사용한다면 Redis말고도 다른 다양한 데이터베이스 혹은 저장소를 활용할 수 있다.
- 애플리케이션에서 사용하는 인메모리 데이터베이스를 사용할 수 있다(대표적으로 H2).
- 분산 환경에서 사용라는 외부 데이터베이스(저장소)를 사용하며, nginx를 비롯하여 redis나 cdn 등 다양한 방안을 활용할 수 있다.
3. Redis만으로도 효과적인 부하 분산 전략을 세울 수 있다.
다만 redis가 가장 다루기 쉽고 spring 프레임워크에서 지원을 해주는 강력한 도구이기에, redis를 활용하는 것만으로도 유의미한 성능 개선을 기대할 수 있다.
또한 다양한 자료구조를 지원하기도 하고 여러모로 효과적인 DB부하 분산 방안을 마련할 수 있고, 이에 대해 다양한 전략을 세울 수 있다.
3-1. 캐싱 전략
- 캐싱 전략(@Cacheable):
자주 사용되는 데이터나 쿼리 결과 (예: 게시글 리스트, 사용자 정보 등)를 레디스에 캐싱하여 저장한다(즉, "데이터"를 "레디스"에 저장). 이후 레디스에 데이터가 있으면 바로 반환하여 불필요한 DB I/O를 줄이고 비용 소모를 그만큼 절약할 수 있다.
우리가 흔히 알고있는 전략이지만, 자세히 살펴보면 캐싱 전략도 내부적으로 다양하게 세울 수 있다.
데이터가 없으면 데이터베이스에서 데이터를 가져와 레디스에 저장하되, 이 시점에서 레디스에 있는 캐싱 데이터를 어떻게 처리할 것인지가 주된 전략이 된다.
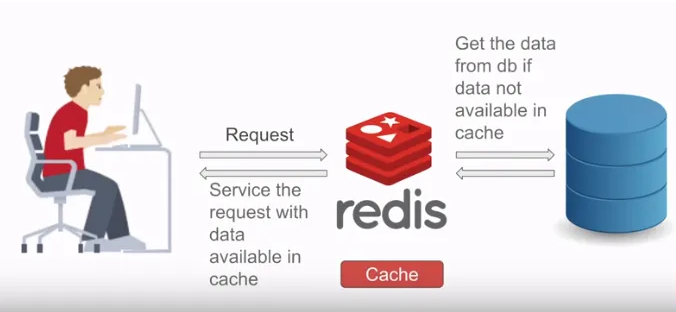
- Read Through
데이터를 캐시에서 먼저 조회한다. 이때 캐시에 데이터가 없다면(cache miss) 데이터베이스를 경유(I/O)하여 데이터를 가져오고 동시에 캐시에 해당 데이터를 저장한다.
이때 캐시를 다루는 전략도 세부적으로 나눌 수 있기에, 무작정 어노테이션을 사용하는 것이 아니라 상황에 맞게 캐싱 전략을 채택하도록 한다.
1) @CacheEvict, 데이터를 조회하는 시점에서 캐시를 지운다.
1-1) 캐시를 지운 후에 바로 데이터를 업데이트 한다.
1-2) 캐시를 일단 지우고 이후 주기적으로 스케쥴러를 작동하여 캐시에 데이터를 채워 넣는다(반대 전략도 있음).
2) @Cacheput - 데이터 조회 후 캐시 데이터를 업데이트 한다.
읽기에 대한 캐싱 전략 뿐만 아니라 쓰기에 대한 캐싱 전략도 있다.
- Write Through
쓰기 처리를 할때 동시에 캐시에도 데이터를 저장한다.
다만 무작정 모든 데이터에 대해 저장을 하는 것이 아니라, 사용자 정보나 주문 상태 등 변경이 거의 일어나지 않는 정보성 데이터나 상태 정보를 대상으로 적용하는 것이 좋다.
캐시와 데이터베이스 간의 정합성/일관성을 유지하는 것이 핵심이며 cache hit를 극대화한다는 방향으로 접근하는 전략이다.
다만 마구잡이로 사용하다보면 그만큼 쓰기 성능 저하 및 불필요한 데이터가 캐시에 쌓일 수 있다.
- Write Around
쓰기 처리 시 캐싱에 반영하지 않고 그 이후에 해당 데이터를 조회하는 시점에 캐싱에 반영하는 우회(around) 전략이다. 바로 캐싱에 적용하지 않고 조회 시 캐싱에 반영하므로 불필요한 데이터가 반영되는 것을 방지할 수 있다.
Write Around 전략 역시 자주 바뀌지는 않지만 조회를 자주 하여 Cache hit를 극대화하는 방향으로 접근하는 방법이다.
첫 조회 시에만 cache miss가 발생하여 성능이 저하된다는 점을 제외하고 가장 효율적인 캐싱 전략일 것으로 보인다.
- Write Back(Behind)
위에서 @CacheEvict 전략과 반대로, 캐시에 데이터를 저장하고 이후 주기적으로 DB에 반영하는 전략이다.
Redis를 main으로 바라보고 DB접근을 최소화하기에 쓰기 성능이 가장 빠르고, 데이터가 자주 변경된다 하더라도 성능이점을 기대할 수 있는 방안이다.
다만 DB동기화가 그만큼 어렵고 대용량 데이터보다는 소규모, 소모성 데이터에 해당 전략을 활용하는 것이 좋다.
결과적으로 어떠한 전략을 사용하든 DB 접근 및 읽기 부하에 대한 책임을 Redis와 같이 지게 되어 부하 분산, 성능 향상을 기대할 수 있다.
3-2. 읽기 성능을 극대화하기 위한 방안 - 인덱스와 캐싱 전략의 조합
하지만 Redis 단독 활용 방안, 자세하게는 Redis를 지원하는 라이브러리 의존적인 방안은 라이브러리를 사용하는 개발자의 재량을 많이 따를 것이다.
조금이나마 이러한 재량적 차이를 줄일 수 있는 방안은 테이블 및 인덱스 등의 전략들을 혼용해보는 것이 있겠다.
3-2-1. Cache miss에 대한 조회 성능 저하를 index 기반으로 최소화한다.
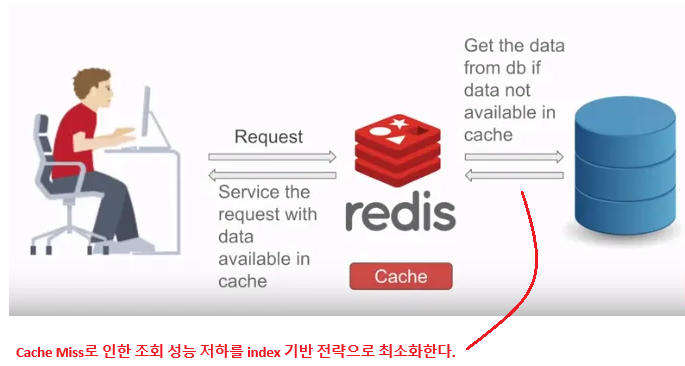
데이터베이스의 조회 성능을 의미있게 유지하기 위해선 쿼리튜닝과 함께 index 전략도 매우 중요할 것이다.
당연한 이야기이지만, 기본적으로 index 전략을 통해 DB의 조회 성능을 최대한 확보해놓는 것이 중요하다.
3-2-2. index 활용을 극대화할 수 있는 데이터베이스 구조를 설계한다.

index의 성능을 최대한 활용하기 위해선 Optimizer가 full scan을 유발할 수 있는 요건을 최소화하는 것도 방법이다.
테이블 구조를 너무 분리하다보면 JOIN이 많이 발생하거나 쓰기를 할 때도 불필요한 트랜잭션이 만들어진다.
원장테이블이나 기본 엔티티를 최대한 간결하고 단일 구성화하여, 조회 성능을 최대한 확보할 수 있는 방안도 생각해볼 수 있다.
3-2-3. DB의 인덱스 정책을 별도로 구성하고, 해당 정책을 Redis에 적용하여 논리적으로 부하를 분산한다.
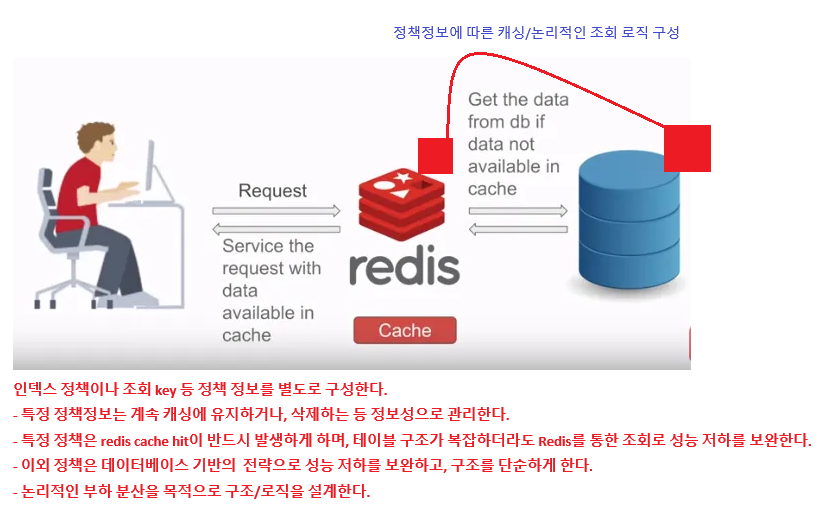
아래에 후술하겠지만, Redis 전략 중 인덱스를 별도로 구성하고, 해당 인덱스 정보에 따라 데이터를 분산 저장하는 방법이 존재한다.
여기에 착안하여, 테이블 구조가 거의 변경되지 않고 조회가 많이 이루어지는 원장테이블에 대해 인덱스 혹은 정책 정보를 별도로 설계한다.
이 정보에 따라 캐싱을 사용할지, 그대로 DB를 활용할지 논리적으로 결정한다.
기본적으로 원장테이블은 다른 처리성 테이블에 비해 간결한 구조이기에 정책정보를 별도로 구성하는 것이 비교적 수월할 것이고, 이 정책을 기준으로 Redis 캐싱을 적용여부를결정한다.
Redis 입장에서는 DB와 캐싱전략을 동일하게 가져가므로, 명확하게 캐싱된 데이터인지 아닌지 논리적으로 판단할 수 있게 된다. 정책구조를 key로 Redis에 같이 활용하여, 데이터를 찾을때 비용소모를 줄일 수 있을 것이다.
이 전략은 캐싱 데이터의 조회 성능은 최대로, 그렇지 않은 데이터는 포기하는 이분법적이 전략이라 할 수 있겠다.
3-3. 구조적 분산 전략
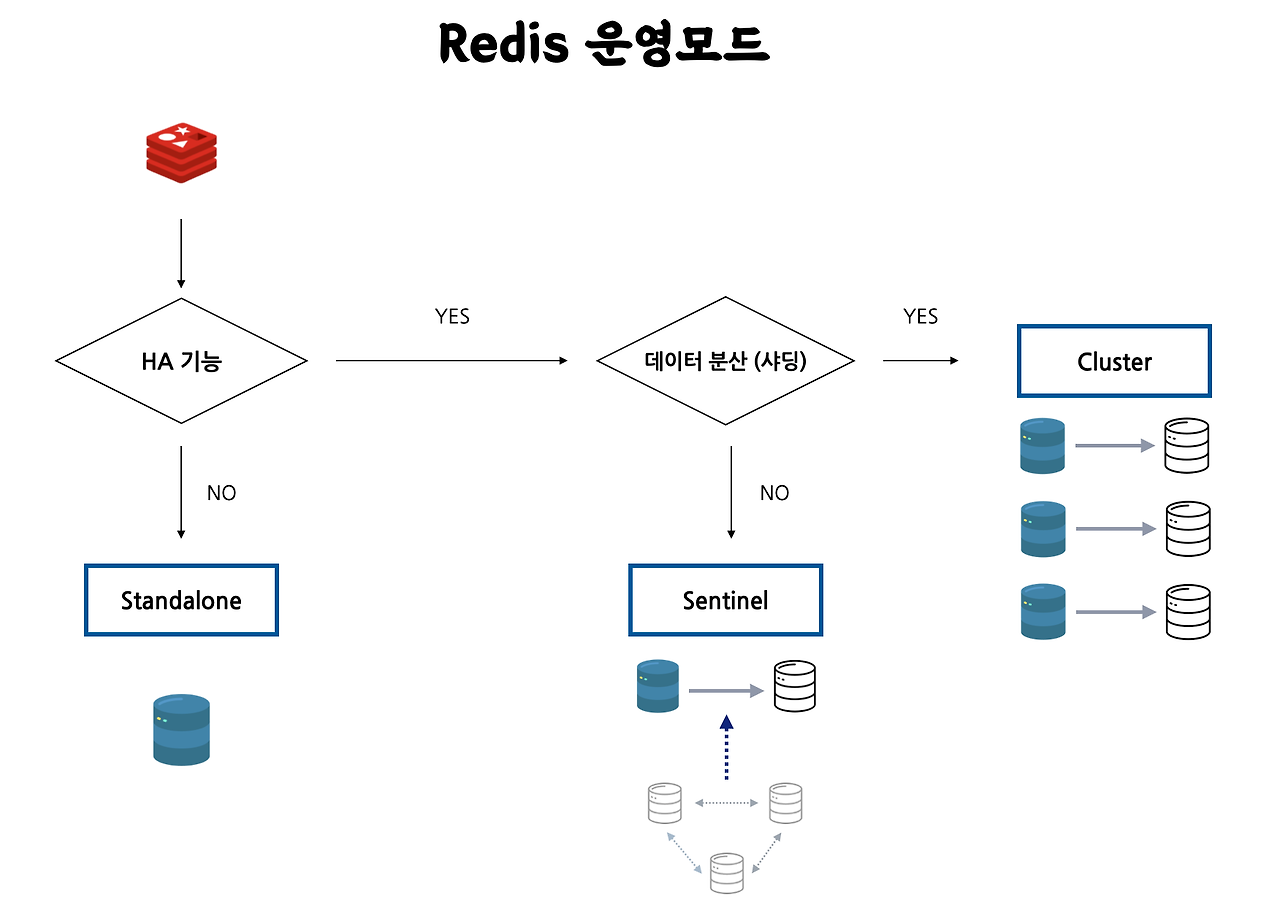
Redis를 운용하는 방법은 크게 3가지로 분류할 수 있다.
- 단일 Redis (Standalone)
- scale out 및 고가용성을 고려하여 이분화(Sentinel)
- 데이터까지 분산하여 저장(Shading)
이 중 데이터를 복제하여 저장하는가, 분산하여 저장하는가에 따라 샤딩과 레플리카 전략으로 세부화할 수 있다.
이러한 구조적 분산 전략을 채택하여 "요청", 즉 "부하" 자체를 분산하여 성능적 개선을 기대할 수 있을 것이다.
3-3-1. 레디스 샤딩
대용량 데이터 처리 시 데이터를 여러 군데의 레디스에 저장, 즉 샤딩한다.
레디스와 같은 nosql기반의 데이터베이스는 RDBMS에 비해 구조적 변경(샤딩 등)이 용이하여, scale up/scale out 전략이 비교적 수월한 점을 활용한다.
여러 인스턴스에 분산 저장할 수 있다는 의미와 동일하고, 샤딩을 통해 데이터의 분산 및 부하 분산을 기대할 수 있다.
3-3-2. 레디스 레플리카(복제)
Master Redis - Slave Redis를 구성하고, 주기적인 데이터 동기화 작업을 통해 동일한 레디스를 두 대이상 운용하는 "복제" 전략이다.
레플리카 노드를 활용하여 조회 부하 자체를 분산할 수 있고, 나아가 하나의 노드에 장애가 발생하더라도 다른 노드가 서비스를 유지할 수 있기도 한다.
3-3-3. 인덱스 서버 별도 분리(인덱스 샤딩)
인덱스를 별도의 서버에 저장해두는 것도 하나의 방법이다.
조회 요청에 대해 index 서버를 통해 가이드를 해주는 방법인데, 장애포인트가 늘어난다고는 하지만 잘 사용하면 성능개선을 기대할 수 있을 것 같아서 발췌하였다.
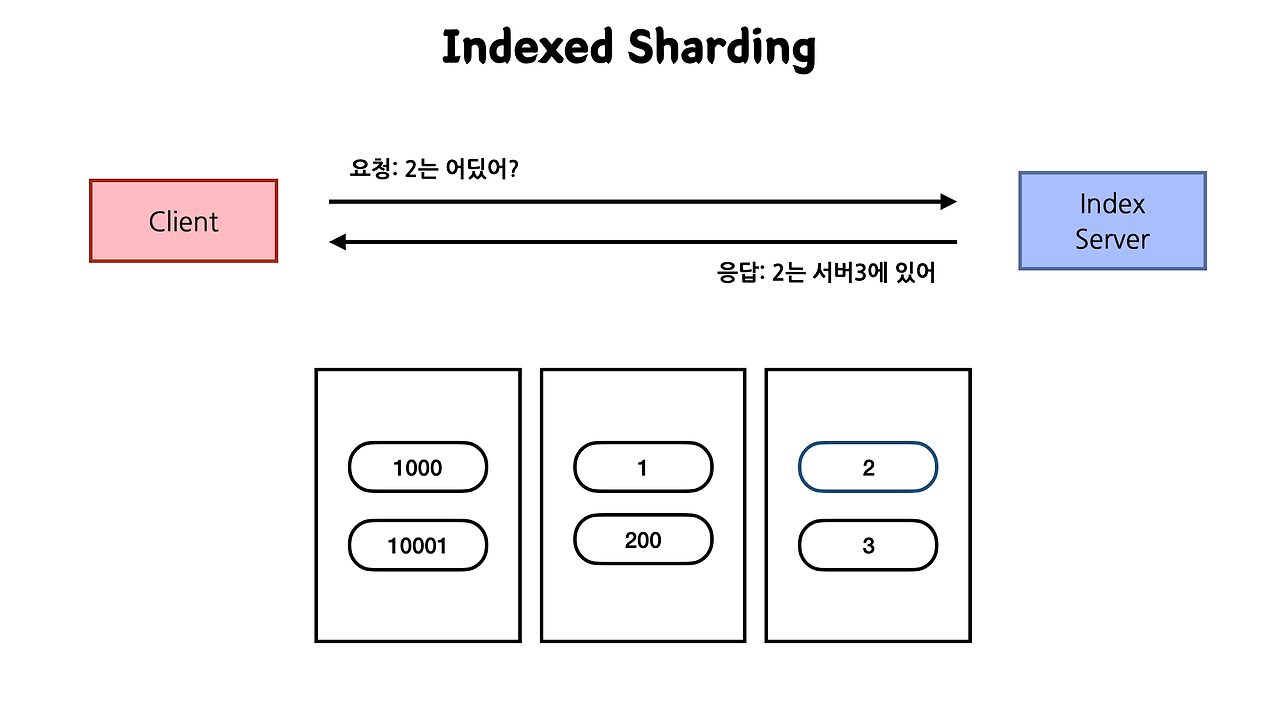
이 아이디어에 기반해서 Redis와 RDBMS의 정책을 잘 관리한다면, 논리적으로 조회 성능을 개선하고 부하도 분산할 수 있지 않을까 생각한다(-> 3-2-3, 인덱스와 Redis 전략 혼용).
결국 핵심은 논리적으로도 부하를 분산할 수 있다는 점이다.
4. 정답은 없다.
추가 전략은 얼마든지 생길 수 있을 것이라 생각한다.
개발에 정답은 없듯이, 성능을 유의미하게 개선하는 것도 정답은 없다.
5. 참고자료
Redis 개요 - https://f-lab.kr/insight/efficient-redis-usage-20241213
캐싱 - @cacheable @cacheevict @cacheput
캐싱 전략(*샤딩) - https://blog.devops.dev/redis-powered-api-caching-d58a388feca
DB병목해결방안 및 Redis 적용 - https://velog.io/@xogml951/DB-%EB%B3%91%EB%AA%A9-%EB%B6%84%EC%82%B0-%EC%BA%90%EC%8B%9CRedis-%ED%95%B4%EA%B2%B0-%EA%B8%B0%EB%A1%9D
구조적으로 부하를 분산하는 방법과 인덱스 샤딩 등 여러 DB 운용 전략 - https://loosie.tistory.com/820
