KoELECTRA라는 자연어 모델로 MRC API를 만들어보고자합니다.
본격적인 API 개발에 앞서 간단하게 기본 개념들을 설명합니다.
KoELECTRA
ELECTRA는 BERT와 유사한 자연어 모델이며, 한국어로 pre-train한 한국어 자연어 모델이 KoELECETRA입니다.
https://github.com/monologg/KoELECTRA/tree/master/finetune
https://monologg.kr/2020/05/02/koelectra-part1/
monologg(박장원)님께서 한국어 ELECTRA 모델을 학습하셨으며, 오픈소스로 공개되어 있어 누구나 사용이 가능합니다.
pre-train과 finetune 소스코드도 함께 공개되어 있어, 소스코드를 참조하여 직접 finetune할 수 있습니다.
https://huggingface.co/monologg
monologg님이 huggingface에 업로드해 놓은 수 많은 모델들이 있습니다. 이 중에 KorQuad로 MRC 파인튜닝한 모델도 공개가 되어 있어, API형태로 간단하게 다운받아 사용할 수 있습니다.
오늘은 이 모델을 활용해서 기계독해 API를 개발하고자합니다.
MRC
MRC는 Machine Reading Comprehension의 약자로, 기계독해라고 해석됩니다. 기계독해는 질문과 질문에 대한 답이 있는 지문(문서)이 주어지면, 질문에 대한 답을 제시하는 기술을 의미합니다. 기계독해의 성능을 평가할 수 있는 도구로써 SQuAD가 대표적이며, 한국어로 제작된 KorQuAD가 있습니다.
개발 환경
python==3.7
pytorch==1.7.0
transformers==3.3.1
flask==2.1.2
flask-restful==0.3.9
gunicorn
KoELECTRA는 1.7.0의 pytorch에서 개발되어 버전을 동일하게 맞췄습니다.
pytorch는 아래 링크에서 설치 명령어가 있습니다.
https://pytorch.org/get-started/previous-versions/
각자의 시스템 환경에 맞춰서 설치하시면 됩니다. 저는 cpu만 사용하기 때문에 아래 명령어로 설치했습니다.
pip install torch==1.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.htmlAPI 프레임워크는 Flask를 사용합니다.
MRC 소스 코드
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class MRC(object):
def __init__(self):
self.tokenizer = AutoTokenizer.from_pretrained("monologg/koelectra-base-v3-finetuned-korquad")
self.model = AutoModelForQuestionAnswering.from_pretrained("monologg/koelectra-base-v3-finetuned-korquad")
def convert_to_token(self,
question: str,
context: str) -> [list, list, list, list, list, list]:
"""
질문, 본문를 토큰으로 변환
koelectra모델의 최대 토큰 수는 512
## Model Input
token_id: "[CLS] 질문 [SEP] 본문 [SEP]"의 토큰 형태로 모델에 input
토큰의 길이가 512보다 작은 경우, padding [0] 으로 512로 자릿수를 채움
attention_mask : token_id는 1, padding은 0으로 변환하여 모델에 input
token_type_id : "본문 + [SEP]"만 1로, 나머지는 0로 변환하여 모델에 input
token_text : 토큰화한 "[CLS] 질문 [SEP] 본문 [SEP]" => 정답 텍스트를 추출하기 위해 사용
:param question: 질문 text
:param context: 본문 text
:return: token_id, attention_mask, token_type_id, token_text
"""
_token_question = self.tokenizer.tokenize('[CLS] ' + question + ' [SEP]')
_token_question_id = self.tokenizer.convert_tokens_to_ids(_token_question)
_token_context = self.tokenizer.tokenize(context + ' [SEP]')
_token_context_id = self.tokenizer.convert_tokens_to_ids(_token_context)
token_text = _token_question + _token_context
token_id = _token_question_id + _token_context_id
_pad_len = 512 - len(token_id)
token_type_id = [0] * len(_token_question_id) + [1] * len(_token_context_id) + [0] * _pad_len
attention_mask = [1] * len(token_id) + [0] * _pad_len
token_id += [0] * _pad_len
return token_id, attention_mask, token_type_id, token_text
def predict_answer(self,
token_id: list,
attention_mask: list,
token_type_id: list,
token_text: list) -> [str, float]:
with torch.no_grad():
_start_logit, _end_logit = self.model(torch.tensor([token_id]).to("cpu"),
torch.tensor([attention_mask]).to("cpu"),
torch.tensor([token_type_id]).to("cpu"))
_max_start = np.argmax(_start_logit)
_max_end = np.argmax(_end_logit)
_start_prob = sigmoid(_start_logit.max())
_end_prob = sigmoid(_end_logit.max())
mean_prob = (_start_prob + _end_prob) / 2
if _max_start > _max_end:
answer_text = "정답 없음"
else:
answer_text = self.tokenizer.convert_tokens_to_string(token_text[_max_start:_max_end + 1])
return answer_text, round(float(mean_prob), 3) if float(mean_prob) > 0 else 0
if __name__ == '__main__':
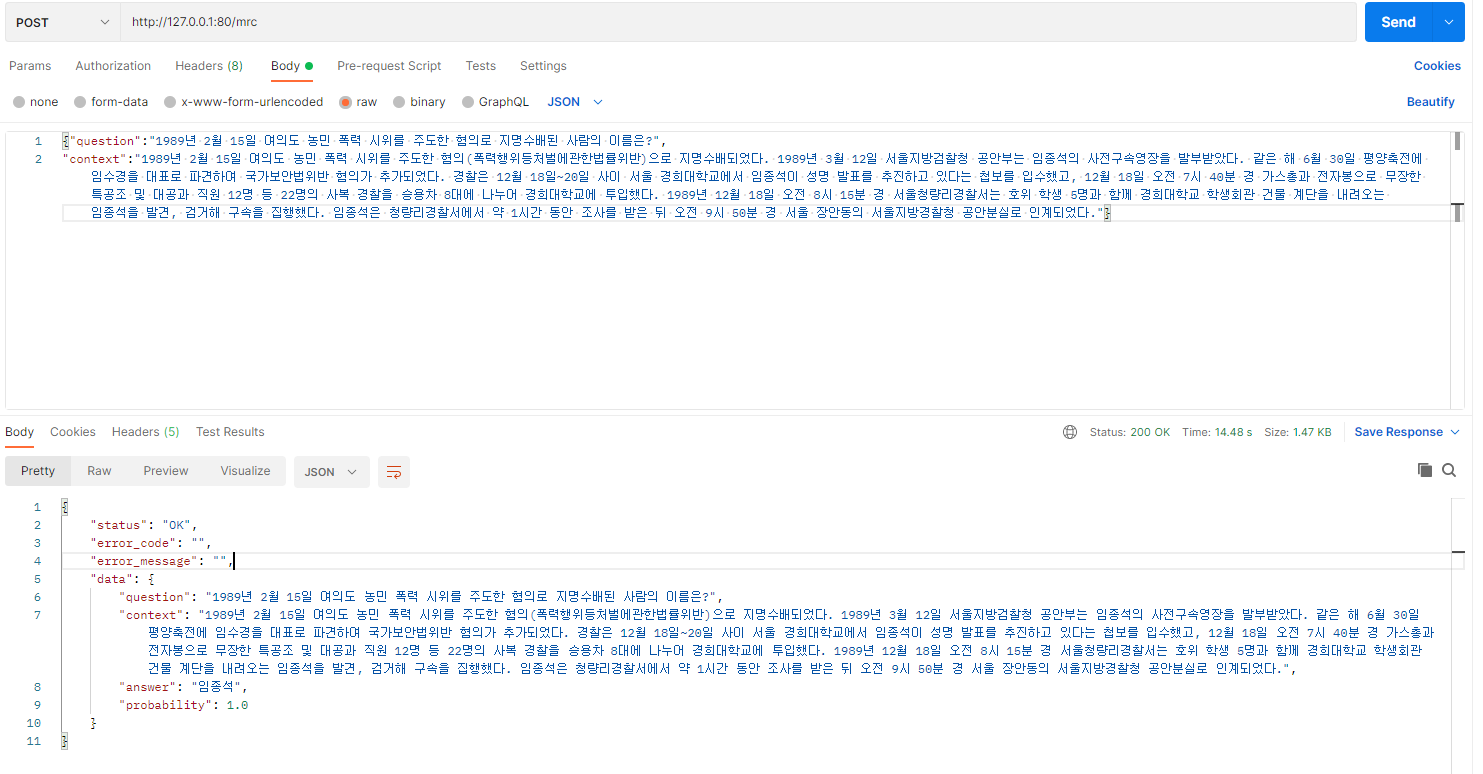
question = "1989년 2월 15일 여의도 농민 폭력 시위를 주도한 혐의로 지명수배된 사람의 이름은?"
context = """1989년 2월 15일 여의도 농민 폭력 시위를 주도한 혐의(폭력행위등처벌에관한법률위반)으로 지명수배되었다. 1989년 3월 12일 서울지방검찰청 공안부는 임종석의 사전구속영장을 발부받았다. 같은 해 6월 30일 평양축전에 임수경을 대표로 파견하여 국가보안법위반 혐의가 추가되었다. 경찰은 12월 18일~20일 사이 서울 경희대학교에서 임종석이 성명 발표를 추진하고 있다는 첩보를 입수했고, 12월 18일 오전 7시 40분 경 가스총과 전자봉으로 무장한 특공조 및 대공과 직원 12명 등 22명의 사복 경찰을 승용차 8대에 나누어 경희대학교에 투입했다. 1989년 12월 18일 오전 8시 15분 경 서울청량리경찰서는 호위 학생 5명과 함께 경희대학교 학생회관 건물 계단을 내려오는 임종석을 발견, 검거해 구속을 집행했다. 임종석은 청량리경찰서에서 약 1시간 동안 조사를 받은 뒤 오전 9시 50분 경 서울 장안동의 서울지방경찰청 공안분실로 인계되었다."""
predict_model = MRC()
token_id, attention_mask, token_type_id, token_text = predict_model.convert_to_token(question=question, context=context)
answer, prob = predict_model.predict_answer(token_id, attention_mask, token_type_id, token_text)
print("Answer :", answer)
print("Probability :", prob)
1. 모델 Load
monologg/koelectra-base-v3-finetuned-korquad의 모델 load 방법은 아래 링크에서 "use in Transformers"를 클릭하게 볼 수 있습니다. __init__ 에서 모델을 load해줍니다.
2. 질문 및 문장을 모델의 input형태로 변환
1) KoELECTRA모델은 3개의 input을 가지고 있습니다.
a. Token ID
b. Attention Mask
c. Token Type ID
2) 위 3개의 input을 만들기 위해 우선적으로 수행될 작업이 토큰화와 질문+지문 연결 작업입니다.
a. 질문과 지문을 연결할 때에는 "[CLS] 질문 [SEP] 지문 [SEP]" 형태로 연결 합니다. [CLS]와 [SEP]는 특수토큰으로 시작과 끝을 표시해줍니다.
b. 먼저 질문을 "[CLS] 질문 [SEP]" 형태로 만들고 tokenizer.tokenize로 토큰화 시켜줍니다. 그런 다음 tokenizer.convert_tokens_to_ids로 토큰화된 문자열 리스트를 숫자열 리스트로 변경해줍니다.
예를들어, "[CLS] 안녕하세요 [SEP]"라는 단어를 ["[CLS]", "안녕","##하","##세","##요","[SEP]"]로 토큰화하고 [2, 23, 3663, 2342 ,3]로 임베딩하는 과정입니다.
c. 지문도 질문과 같은 형태로 "지문 [SEP]" 형태로 만들고 토큰화 임베딩을 수행합니다.
d. 임베딩이 완료된 질문과 지문을 합쳐 "token id"에 저장합니다.
e. 일반적으로 BERT를 비롯한 koelectra에는 한번에 수용할 수 있는 최대 토큰 길이가 있습니다. 이 모델은 최대 토큰 길이가 512입니다. 최대 토큰 길이를 초과하면 답을 찾을 수 없으니, "[CLS] 질문 [SEP] 지문 [SEP]"의 토큰 길이가 512가 넘지 않도록 주의해주세요
더 긴 토큰 길이를 처리하고 싶다면, 지문을 여러 개로 나눈 뒤 "[CLS] 질문 [SEP] 지문 [SEP]"를 여러개 만들어 처리하는 것이 가능합니다.
3) input 생성
a. 512에서 token id의 길이를 빼서 padding할 사이즈를 구합니다.
b. token id의 길이를 512로 맞춰야하기 때문에 나머지는 padding [0]으로 채웁니다.
c. attention mask는 "[CLS] 질문 [SEP] 지문 [SEP]"과 padding을 구분하는 것입니다. "[CLS] 질문 [SEP] 지문 [SEP]"의 길이만큼 [1]로 채우고 나머지는 padding [0]으로 채웁니다.
d. token type id는 질문과 지문을 구분하기 위한 용도입니다. "지문 [SEP]"는 [1]로 채우고 나머지는 전부 [0]으로 채워 줍니다.
3. 모델 예측값 생성
a. model에 token id, attention mask, token type id를 순서대로 넣게 되면, 정답이라고 예상되는 토큰들의 확률이 나옵니다. _start_logit은 정답 시작 토큰들의 확률 값들이고, _end_logit은 정답 끝 토큰들의 확률 값들입니다.
b. np.argmax를 활용해 시작과 끝의 max 확률들의 위치를 찾습니다.
c. 정답 시작 위치가 정답 끝 위치보다 작은 경우는 없기 때문에, "정답 없음"이라고 라벨링합니다. 정상적인 경우에는 "[CLS] 질문 [SEP] 지문 [SEP]"의 토큰에서 정답 토큰들을 추출하여 문자열 형태로 변환해줍니다.
d. 정답 확률은 sigmod를 활용해서 계산했습니다.
MRC API 소스 코드
import os
import json
import traceback
import socket
from flask import Flask, request, Response
from flask_restful import Api
from flask.views import MethodView
from module.mrc import MRC
## 인스턴스 생성
app = Flask(__name__)
api = Api(app)
model = MRC()
# 한글 설정
app.config['JSON_AS_ASCII'] = False
mandatory_key = ['question', 'context']
class Main(MethodView):
def get(self):
return "Hello World"
def post(self):
data = request.get_json()
output = {"status": "OK",
"error_code": "",
"error_message": "",
"data": ""}
try:
for m_key in mandatory_key:
if m_key not in data.keys():
output['status'] = "ERROR"
output['error_code'] = "ERROR-01"
output['error_code'] = "{} 키 없음".format(m_key)
raise Exception("get data error")
if len(str(data[m_key]).strip()) == 0 or data[m_key] is None:
output['status'] = "ERROR"
output['error_code'] = "ERROR-02"
output['error_code'] = "{} 값 없음".format(m_key)
raise Exception("get data error")
token_id, attention_mask, token_type_id, token_text = model.convert_to_token(question=data["question"], context=data["context"])
answer, prob = model.predict_answer(token_id, attention_mask, token_type_id, token_text)
output_data = {}
output_data["question"] = data["question"]
output_data["context"] = data["context"]
output_data["answer"] = answer
output_data["probability"] = prob
output['data'] = output_data
return Response(response=json.dumps(output, ensure_ascii=False), mimetype='application/json')
except Exception as e:
if output['error_code'] == "":
output['status'] = "ERROR"
output['error_code'] = "ERROR-99"
output['error_message'] = "UNKNOWN"
return Response(response=json.dumps(output, ensure_ascii=False), mimetype='application/json')
api.add_resource(Main, '/mrc')
if __name__ == '__main__':
port = 8000
print('Start Server.... port=',port)
app.run(host='0.0.0.0', port=port, debug=True)Post 방식 API 생성
question과 context로 구성된 json형태의 데이터를 받아 기계독해를 실행하는 API를 생성합니다.
a. data = request.get_json()로 데이터를 받아, data(dict)안에 question과 context의 key와 value가 있는지 확인하고 없으면 에러를 밷어줍니다.
b. 데이터에 이상이 없으면, 위에서 생성한 MRC 클래스를 활용하여 정답을 예측하는 스크립트를 작성합니다. 결과데이터는 output에 data에 넣어 리턴해줍니다.
c. try문으로 혹시 모를 에러가 발생한 경우, internal server에러 대신 에러코드값을 리턴합니다.
d. app.config['JSON_AS_ASCII'] = False을 사용하면 데이터도 한글이 있어도 깨지지 않습니다.
테스트
postman으로 간단하게 테스트를 진행해보겠습니다.
Docker Compose로 배포
nignx + gunicorn + flask + pytorch를 docker compose로 배포 소스코드는 아래 git을 참조해주세요
https://github.com/gyounghwan1313/mrc_flask_api
flask api 단독으로 prodcution에 배포할 수 없습니다. nginx를 앞에 두어 loadbalancer용도로 사용됩니다. nginx는 들어온 요청에 대해 flask api로 전달해줍니다. 이를 중개하는 것이 gunicorn(wsgi)입니다.