10:00 ~ 13:00
우선 기존 실험(키워드 별 위키피디아 문서)에 Reasoning을 추가해 시도했다. 하지만 위키피디아 문서 중에 60000자 분량 문서가 있고, 문서 간 길이 격차가 커 실험을 중단했다. gpt 4o mini가 16000 토큰을 제한으로 두고 있으니, 문서 별 요약이 필요했다.
문서 별 요약 실험을 계속해서 시도했다. 문제를 포함해서 요약하면 문제 풀이 과정이 요약문에 드러났다. 문제를 포함하지만, 풀이 과정을 절대 담지 말라는 제한을 뒀는데, 요약문의 질이 떨어졌다. 모델에게 정보를 제공하고 제공한 정보를 배제하는 행위가 성능에 치명적인 영향을 주었다.
이번 프로젝트에서 정량적인 메트릭이 아닌, 20개를 샘플링해 직접 눈으로 확인하며 실험을 진행했다. 실험 결과를 토대로 다음 실험, 혹은 이전 실험과 비교할 때, 시각화할 수 있는 정보가 매우 부족했다. 일일히 실험 의도 혹은 가설의 반례를 찾고, 인사이트를 직접 도출하다보니 시간이 매우 많이 소요됐다.
13:00 ~ 16:00
외부 정보가 필요한 문제에 한해서 위키피디아 문서 요약을 진행했다. 약 650개 문제를 요약을 하니 4~5시간 정도 소요됐다. 키워드 추출 작업이 잘 진행됐다고 판단해, 프롬프트에 키워드와 위키피디아 문서 원본만 입력으로 줘 요약 프롬프트를 구성했다. 마음 같아서는 이 요약문을 1500~3000자 분량의 문서로 재가공하는 작업도 하고 싶었는데, 프로젝트 마감까지 모델에 학습이 불가능할 것이라 판단했다. 이전 실험에서 400 문제에 3시간 정도 소요됐기 때문에, 650 문제에는 대략 4시간 내외로 적용되고 베이스라인 모델에 데이터로 학습 실험을 진행하기에는 시간이 부족했다.
지문이 주어진 데이터셋이 없을까 찾아보다가 KoBEST 데이터셋을 발견했다. True/False로 답변하는 6000개 질의 응답이 있는 데이터셋이였다. 데이터셋을 훑어보니 Paragraph 데이터 질이 상당히 좋게 보였다. 길이도 길지 않았고, 문제와 선택지를 생성하기 위한 논문 리뷰도 완료했기 때문이다. 실험을 진행하면서 정답 도출이 가장 중요한 관건임을 발견했다. 모델이 직접 질문과 선택지를 만들다보니, 정답 오류가 많이 발생했다.
16:00 ~ 19:00
피어세션에서 다른 팀원 형이 RAFT 논문 리뷰 내용을 간단하게 공유해줬다. 잘못된 문서를 활용해 모델의 성능을 높이는 아이디어가 상당히 흥미로웠다. 논문에 제시된 실험 결과로 완전 오답의 비율을 60%로 설정하고, 잘못된 문서를 2개를 두는 판단은 정말 배울 점이 많다고 생각했다. 이제까지 프로젝트를 진행하면서 직관으로 판단했었다. 논문이랑 부스트캠프에서 배운 내용을 사용하긴 했지만, 진행이 막혔을 때 논문을 적극적으로 찾아볼 생각은 하지 않았었다. 이번 프로젝트를 진행하면서 객관적이고 분석적인 사고 방식이 많이 부족함을 느꼈다.
KoBEST 데이터 활용 증가 결과에 llm-as-judge를 소프트하게 도입했다. 생성된 문제-답 쌍을 프롬프트 입력으로 두고, 문제에 대한 정답 선지가 올바른지 판단하는 프롬프트로 실험을 진행했다.
처음에는 질문/선택지/정답 오류 3가지를 판단하는 실험을 진행했다. 평가한 데이터 중에서 절반이 문제에 오류가 있는 데이터로 걸러졌다. 실제로 데이터를 확인해보니, False Negative 데이터가 많았다. 하지만 False Positive 데이터는 없었다. 이는 무작위 선정된 20개 데이터에 한한 통계치여서 얼마나 신뢰도가 있을지 의문이다.
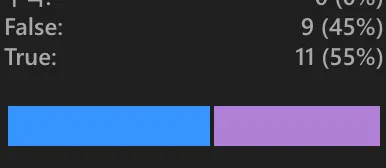
정답 오류 여부만 판단하는 실험을 진행했다. False Negative 데이터를 정상으로 걸러내기 위해서 프롬프트를 수정했다. 직접 확인해보니, 실제 False Positive 데이터가 발생했다. 좀 더 많은 문제가 정상으로 판명됐지만, 그 중에 오류가 발생하는 비율이 늘어난다는 결론에 도달했다.
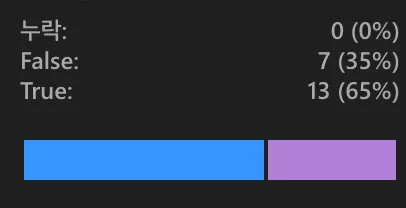
최종 데이터 증강은 질문/선택지/정답 오류 3가지를 기준으로 판단하여 걸러냈다. 파인 튜닝 시, 오류가 있는 데이터를 넣으면 성능에 악영향을 미칠 것이라는 판단이었다. 또한 외부 지식이 필요한 638개를 추가하니 약 1000개 데이터를 증강할 수 있었다.
실제로 리더보드에 제출해보니, 오히려 베이스라인 성능보다 떨어졌다. 그 이유를 다시 복기해보면, 베이스라인에서는 max_length가 2048로 고정되어있었다. 문제는 내 증강 데이터 중에는 6000~8000자 분량의 데이터가 많은 것이었다. 거의 10일이 넘게 데이터 증강을 시도했는데, 마지막에 결과가 안 좋아서 아쉬웠다. 생성된 데이터 품질은 괜찮다고 생각하지만, 이 또한 정량적으로 보여줄 방법이 없어서 아쉬웠다.
프로젝트 기간이 끝나도 작업을 계속하고 싶다고 생각했다. 우선, 수능 문제를 적용하지 못하는 제한과 여러가지 증강 기법을 적용하면 정확도가 높은 모델을 만들 수 있겠다는 자신감을 얻었다.
