확률 표본 추출 (probabillity sampling)
모집단을 구성하는 모든 추출단위에 대해 표본으로 추출된 확률을 알 수 있는 추출법
=> 표본추출틀(sampling frame, 표집틀) 필요
예) 모집단 : {1,2,3,4,5} => 2개의 표본
어떤 개체가 표본으로 뽑힐 확률 = 2/5
1. 단순확률 추출 (simple random sampling) SRS
- 크기가 N인 모집단에서 크기 n인 표본을 무작위로 추출
- 모든 단위들이 표본에 선택될 확률이 동일
예) 가구조사: P(이니네 집 추출) = n/N - 실제 대규모 조사에서는 거의 사용되지 않지만, 다른 모든 표본추출방법의 기초 (표본추출 기초 이론)
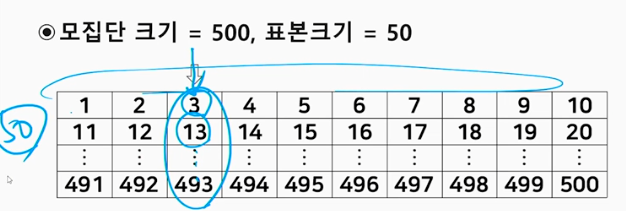
2. 계통 추출 (systematic sampling)
- 표집틀에서 처음 1~k번째 단위들 중 하나를 랜덤하게 선택한 다음, 매 k 간격(같은 간격)으로 단위들을 표본으로 추출

- 계통표본 추출과정
추출간격 k의 결정: N/n 또는 정확도를 고려 결정.
예) 500개에서 같은 간격으로 50개를 뽑는다고 했을 때, 간격은 500/50인 10이 된다.
그 간격내에서 무작위로 표본 1개를 추출한다.
(1) 1~k에서 난수 하나를 선택해서 시작점 선정
(2) 시작점에 k를 반복적으로 더해서 표본 추출
-> 표집틀이 없어 고유번호 부여, 난수발생 등 단순확률 추출법을 적용하기 어려운 실제 조사현장에서 폭 넓게 활용
예) 선거출구조사, 주차장 출입 차량에 대한 조사
3. 집락 추출 (cluster sampling)
- 서로 인접한 조사단위들을 묶어 구성한 집락(cluster)을 추출하고, 이들 집락 내의 조사단위들을 조사.
예) 서울시 고등학생 월평균 사교육비 추정
-
SRS(단순확률추출법)
-> 추출틀: 서울시 전체 고등학생 명단 -> 작성비용 과다
-> 조사대상: 서울 전역에 산재됨 -> 조사비용 과다 -
집락추출:
1단계: 고등학교추출 (PSU, promary sampling unit)
2단계: 학생추출 (학급 => 학생)
고등학교 -> 학급 -> 학생 순으로 추출 -
집락추출법 활용 이유
-> 조사단위에 대한 표집틀 확보에 어려움 => 상대적으로 집락에 대한 표집틀 확보는 쉬움
-> 조사단위들이 산재되어 관측비용 증가 => 지역적으로 집중되도록 표본추출
4. 층화 추출
-
일반적으로 가장 많이 사용되는 방법
-
모집단을 서로 중복되지 않는 여러 개의 층(strata)으로 나누고, 각 층에서 단순확률추출에 의해 표본을 추출
-
부 모집단(subpopulation)의 구성 내역을 알고 있음.
-
부 모집단 간 특성에 차이가 있음.
-
층화 표본추출 과정
(1) 층의 구성 (성별, 연령, 지역 등)
(2) 각 층에서 독립적으로 표본 추출 => 단순 확률추출법 사용
예) 서울시내 서점의 월 매출액 추정을 100개 서점 표본 추출
- 100개 중 대형 서점이 10개인 경우와 20개인 경우 -> 추정치 변동이 큼
- 대형, 중형, 소형으로 분류 후 각 층에서 일정 수 표본 추출
-> 층의 비율에 맞게 추출
-> 층의 비율에 맞지 않으면 가중치 반영
비확률 표본 추출
특정 표본이 선정될 확률을 알 수 없음
=> 추론 결과의 정확도 = 파악 불가
예) 편의 추출, 유의 추출
- 편의 추출: 자발적 참여, 백화점 앞, 포털사이트 인터넷 조사
- 유의 추출: 전문가 선택
- 할당 추출: 그룹 조사대상 선택에서 랜덤화 과정 없음 -> 조사자가 조사대상을 임의로 선택함.
=> 간편하고 비용이 적게 든다는 이유로 사회조사에서 광범위하게 사용됨.
목표모집단 vs 조사모집단
목표모집단(target population)
- 관심대상이 되는 모든 기본단위들의 집합
- 시공간상 명확하게 정의된 대상 집단
예)
- 조사시점, 지리적인 경계, 연령 기준 등
- 수도권 거주 고등학생 학부모 대상 기준
= 단점: 표본틀이 없기 때문에 대상에 대한 기준이 모호함.
조사모집단(survey population) ; 조사가능 모집단(acessible population)
- (현실적인 제약 고려) 표본추출 대상 기본 단위들의 집합
- 표본 추출틀을 통해 추출될 수 있는 기본단위들의 집합
예) - 전화여론조사: 전화번호부(표본 추출틀에 등재된 전화보유 가구의 성인)
결론
실질적으로 모집단을 대표할 수 있는 표본을 추출하는 방법은 확률표본추출밖에 없음.
