- 리뷰 목적: Centerformer (2022)의 heatmap loss 이해
- 게재년도: 2020
- 게재지: IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS
- Open Source code: https://github.com/wangguojun2018/CenterNet3d
keywords:
- Point cloud, autonomous vehicles, deeplearning, 3D detection, anchor free
Abstract
- 기존의 one-stage 3D object detction methods들은 real-time 성능을 내는 것이 가능해졌다.
- 그러나, 앵커 기반의 네트워크들은 post-processing을 필요로 하여 학습 과정이 inefficient하다는 단점이 있다.
본 논문에서는 object의 Center point에 기반하여 anchors를 정의하지 않는 앵커 프리 방식의 network를 제안한다.
(NMS와 같은 post-processing을 사용하지 않기 때문에 좀 더 빠른 학습속도를 갖는다.)
Keypoints
1. Extra corner attention module
CNN backbone이 object boundaries에 더 집중하여 학습할 수 있도록 한다.
2. Efficient keypoint-sensitive warping operaion
predict된 bounding box들을 confidence에 따라 정렬한다.
3. 앵커를 사용하지 않기 때문에 NMS(non-maximum suppresion)과정을 거치지 않아 효율적이다.
4. KITTI Dataset으로 학습하였다.
5. 20FPS의 inference 속도를 입증하였다.
1. Introduction
본 논문에서 학습데이터로 사용한 LiDAR 데이터 셋의 특징은 다음과 같다.
LiDAR Data 특징
- Radar data와 비교하였을 때 high accuracy, resolution를 갖는다.
- Sparse, unordered -> 이러한 특성은 CNN이 lidar point들을 parse하기 어렵게 만든다.
이러한 문제를 해결하기 위해 Sparse한 point cloud를 다음과 같이 변환하여 학습하고자 하는 method들이 제안되어왔다.
Convert sparse point cloud for another 3d data methods
-
2D/3D voxelization -> VoxelNet [11], SECOND [12], SA-SSD, PointPillar [13]
-
2D/3D pseudo image -> PointPillar [13]
논문 아래 링크 참고
위 method들은 모두 anchor기반의 detector이다.
anchor기반의 detector 단점
-
hyperparameter setting, tuning 에 대한 부담
여기서 말하는 hyperparameter란 anchor ratio, scales, range, size, orientations등이다. -
IOU matching threshold 설정의 어려움
IOU matching threshold는 Object detection에서 적절한 positive samples과 negative samples을 얻기 위해 세밀하게 조정되어야 한다 (모델의 performance가 이에 민감함). -
Non-Maximum Suppression (NMS) 필요
NMS는 anchor-based methods에서 overlap된 바운딩 박스를 suppress하는 데 필요하다. 이는 막대한 computational cost를 초래한다.
anchor-free methods는 FPN [16], Focal loss [17], [18]-[21], [22]등장 이후에 더욱 발전되었다.
anchor를 정의하는 방법에는 다음 두가지 방법이 있다.
작성중......
[20] Cornernet: Detecting objects as paired keypoints, Proc. Eur. Conf. Comput., 2018.
[22] Objects as points, 2019.
논문 참고 링크:
2. Related Work
Related Work에서는 3D detector에 point cloud 데이터를 학습데이터로 representation하는 방식들을 소개한다.
point cloud detector의 경우, 첫번째로, Input data가 detector에 입력되는 형태에 따라 총 3가지 방식(point-based, voxel-based, Mixture), 두번째로, feature 추출과 RPN 단계에 따른 총 2가지 detect 방식(one-stage방식, two-stage방식 = 본 논문리뷰에서는 설명을 생략하였다.)으로 구분된다.
마지막으로 CenterNet3D의 가장 중요한 특징 중 하나인 Anchor free 3D Detection방식에 대해 소개한다.
CenterNet 3D의 경우 voxel-based respresentation방식과 one-stage방식을 사용하였다.
2-1. Point Cloud Representation
2-1-1. point-based representation
raw한 point cloud 데이터에 bounding box가 별다른 전처리 과정없이 그대로 적용된다.
2-1-2. voxel-based respresentation
point cloud 데이터가 Voxellizatio을 거쳐 더 compact한 방식으로 변환된다.
- 대표 논문:
[12] SECOND: Sparsely embedded convolutional detection, Sensors, 2018.
[13] PointPillars: Fast encoders for object detection from point clouds, IEEE Conf. Comput. Vis. Pattern Recognit, 2019.
[28] PIXOR: Real-time 3D object detection from point clouds, IEEE Conf. Comput. Vis. Pattern
Recognit, 2018.
[29] Complex-YOLO: An euler-regionproposal for real-time 3D object detection on point clouds, Eur. Conf. Comput. Vis, 2018.
2-1-3. Mixture of representations (point + voxel)
- raw한 point와 voxel (voxelization된 point)가 detector의 Input data로 함께 사용되는 methods다.
- input feature들은 bounding box 예측을 위해 네트워크의 다른 stage들에서 fuse된다.
2-3. Anchor free detection
C. Anchor-Free 3D Detection
CenterNet3D는 Anchor를 사용하지 않는 Anchor-Free 3D Detection 방법을 사용하였다.
기존의 3D one-stage, two-stage detector의 경우 미리 정의된 anchors및 object sizes를 사용하여 학습 연산량이 많다는 특징이 있었다.
따라서 본 논문에서는 Lidar를 기반으로 한 point cloud데이터에 anchor-free 3d Detector를 적용하여 학습하였다.
관련된 논문은 중요하지 않아 넘어가겠다.
3. CenterNet3D Network
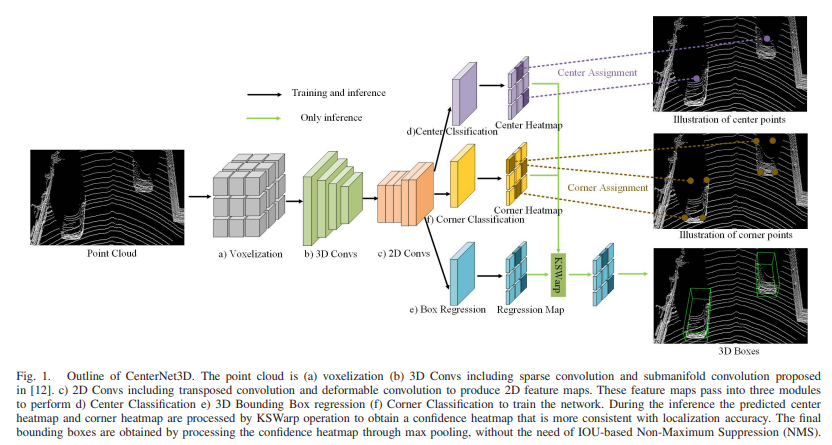
CenterNet3D Network의 전반적인 Architecture는 위 그림 Fig1과 같다.
주요 architecture는 다음과 같이 구성된다.
a) Voxelization
첫번째로, point cloud는 volelization을 거쳐 Sparse한 point에서 voxel로 표현이 된다.
b) 3D Convs (3D feature extractor)
3D Convs including sparse convolution and submanifold convolution
-> [12].(SECOND: Sparsely embedded convolutional detection, 2018) 논문에서 제안된 conv net 과 같다.
c) 2D Convs (2D feature extractor)
A. CenterNet3D Head
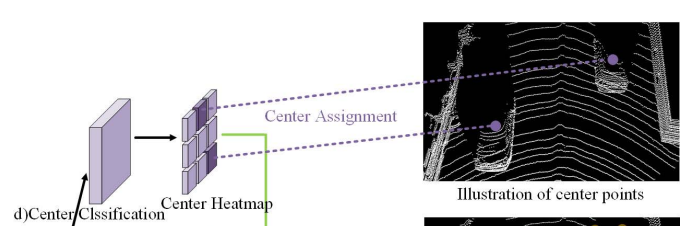
1. Center Classification
- centerpoint에 대한 probability를 예측한다.
그림 상의 Center Heatmap
2. Corner Classification
3. Box regression
참고: LiDAR vs Radar
LiDAR = Light Detection And Ranging
-> 출력 레이저 펄스를 발사해 레이저가 목표물에 맞고 되돌아오는 시간을 측정(이 때문에 비행시간거리측정; ToF·Time of Flight 기술이라고도 함.)하고, 이에 사물간 거리 및 형태를 파악하여 얻어지는 데이터
Radar = RAdio Detection And Ranging
-> 라이다와 동일한 방식으로 작동하지만 레이저 대신 전파를 이용한다는 점에서 다르다
특징 비교
- 정밀도: 라이다 > 레이더
- 가격: 레이더 > 라이다
- 외부환경 극복: 레이더 > 라이다
- 소형화: 레이더 > 라이다

이런 유용한 정보를 나눠주셔서 감사합니다.