
1. 셀레니움 설치
- 윈도우, mac(intel)
- conda install selenium
- mac(m1)
- pip install selenium
- chromedriver
!pip install selenium
!pip list | grep sele
from selenium import webdriver
driver = webdriver.Chrome("../driver/chromedriver.exe") # "../driver/chromedriver.exe"
driver.get("https://www.naver.com")
driver.quit()2. 셀프 주유소가 정말 저렴하나요? - 데이터 확보하기 위한 작업
- https://www.opinet.co.kr/searRgSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
3. 셀레니움으로 접근
from selenium import webdriver
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../driver/chromedriver") # windows .exe
driver.get(url)문제
해당 URL로 한 번에 접근이 안됩니다.
메인페이지로 접속이 되고, 팝업창이 하나 나옵니다.
- 문제 해결: time 셋팅을 통해 천천히 하나씩
import time
def main_get():
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../driver/chromedriver") # windows .exe
driver.get(url)
time.sleep(3)
# 팝업창으로 전환
driver.switch_to_window(driver.window_handles[-1])
# 팝업창 닫아주기
driver.close()
time.sleep(3)
# 메인화면 창으로 전환
driver.switch_to_window(driver.window_handles[-1])
# 접근 URL 다시 요청
driver.get(url)
main_get()- 첫번째 선택창: 시/도 중에 서울시 선택하기
# 지역: 시/도
sido_list_raw = driver.find_element_by_id("SIDO_NM0")
sido_list_raw.text
sido_list = sido_list_raw.find_elements_by_tag_name("option")
# 1.
sido_names = []
for option in sido_list:
sido_names.append(option.get_attribute("value"))
# 2. (위의 내용을 한줄로 쓰면)
sido_names = [option.get_attribute("value") for option in sido_list]
# 빈칸 삭제
sido_names = sido_names[1:]
sido_names[0]
sido_list_raw.send_keys(sido_names[0])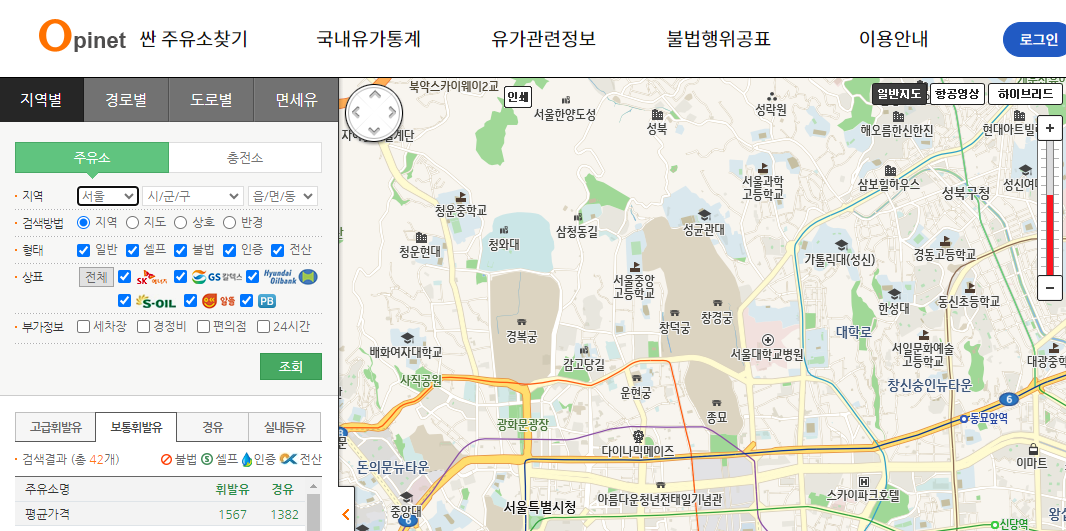
- 두번째: 구별 주유소 엑셀리스트 얻기
# 구
gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0") # 부모 태그
gu_list = gu_list_raw.find_elements_by_tag_name("option") # 자식 태그
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:]
gu_names[:5], len(gu_names)
# 차례대로 엑셀리스트 저장
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu)
time.sleep(3)
element_get_excel = driver.find_element_by_id("glopopd_excel").click()
time.sleep(3)
driver.close() 
4. 데이터 정리하기
import pandas as pd
from glob import glob
# 파일 목록 한 번에 가져오기
glob("../data/지역_*.xls")
# 파일명 저장
stations_files = glob("../data/지역_*.xls")
# 하나만 읽어보기
tmp = pd.read_excel(stations_files[0], header=2)
tmp.tail(2)
# 모두 붙이기(형식이 동일하고 연달아 붙이기만 하면 될 때는 concat)
tmp_raw = []
for file_name in stations_files:
tmp = pd.read_excel(file_name, header=2)
tmp_raw.append(tmp)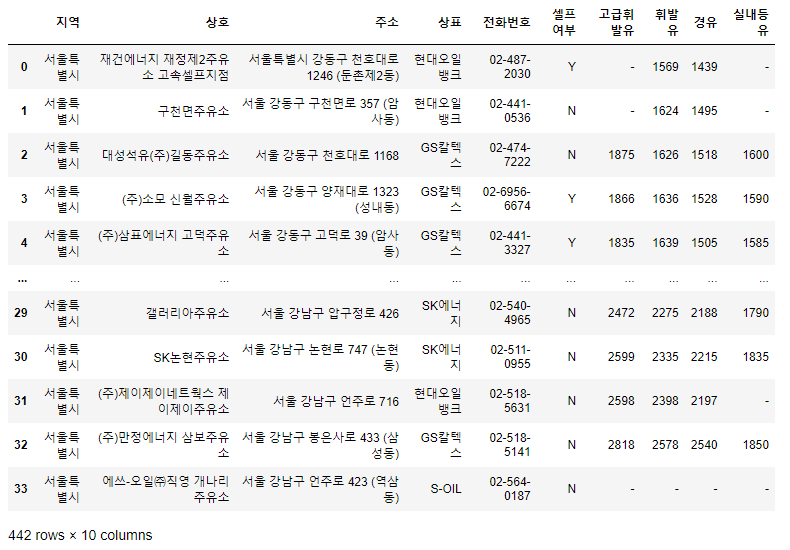
- 데이터프레임화
# 자료 확인하기
stations_raw.info()
stations_raw.columns
# 데이터프레임화
stations = pd.DataFrame({
"상호": stations_raw["상호"],
"주소": stations_raw["주소"],
"가격": stations_raw["휘발유"],
"셀프": stations_raw["셀프여부"],
"상표": stations_raw["상표"]
})
stations.tail()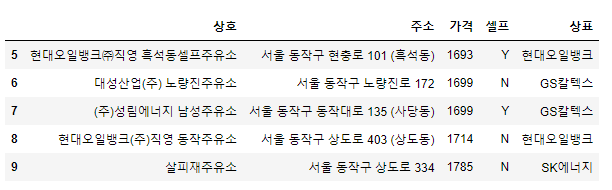
- 구별 정리
for eachAddress in stations["주소"]:
print(eachAddress.split()[1])
stations["구"] = [eachAddress.split()[1] for eachAddress in stations["주소"]]
stations
# 확인
stations["구"].unique(), len(stations["구"].unique())
- 가격 데이터형 변환
# 가격 데이터형 변환 object => float (에러!)
stations["가격"] = stations["가격"].astype("float")
# 가격 정보 없는 주유소
stations[stations["가격"] == "-"]
# 가격 정보가 있는 주유소만 사용
stations = stations[stations["가격"] != "-"]
stations["가격"] = stations["가격"].astype("float")
# 인덱스 재정렬
stations.reset_index(inplace=True)
del stations["index"]
stations.tail()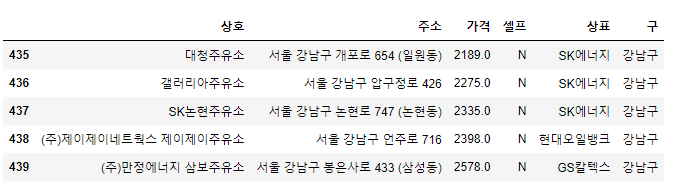
5. 주유 가격 정보 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
import koreanize_matplotlib- pandas boxplot
# boxplot(feat. pandas)
stations.boxplot(column="가격", by="셀프", figsize=(12, 8));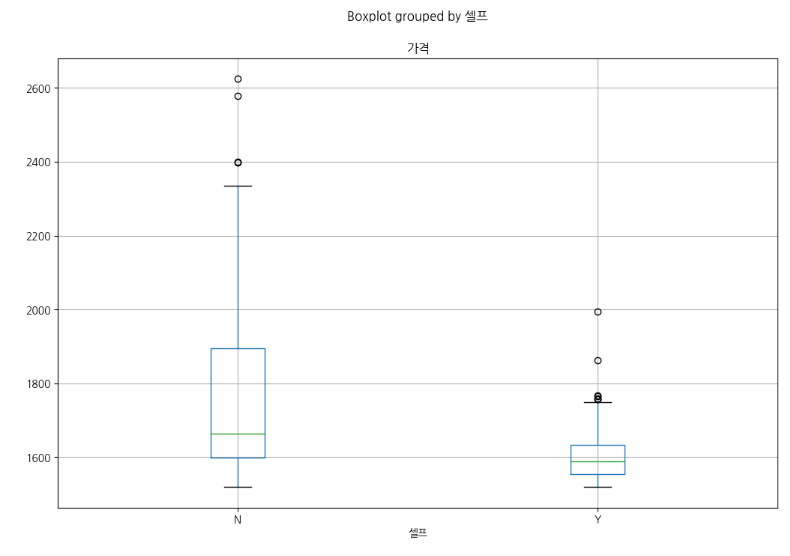
- seaborn boxplot
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="셀프", y="가격", data=stations, palette="Set1")
plt.grid(True)
plt.show()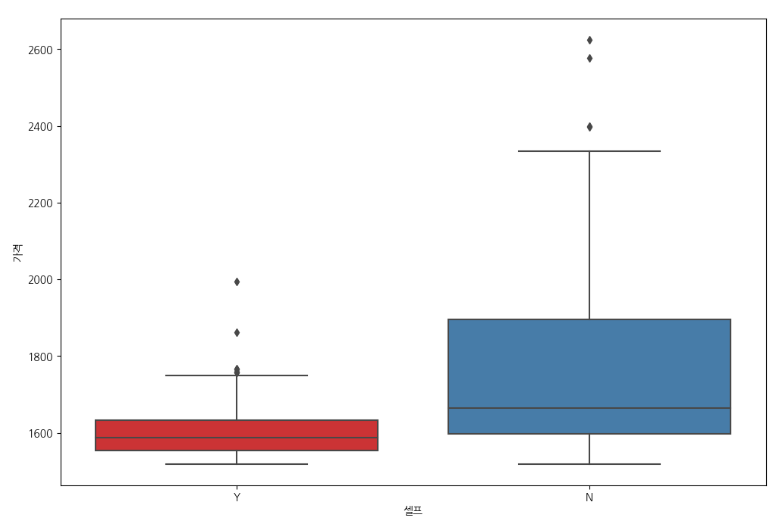
# boxplot(feat. seaborn)
plt.figure(figsize=(12,8))
sns.boxplot(x="상표", y="가격", hue="셀프", data=stations, palette="Set3")
plt.show()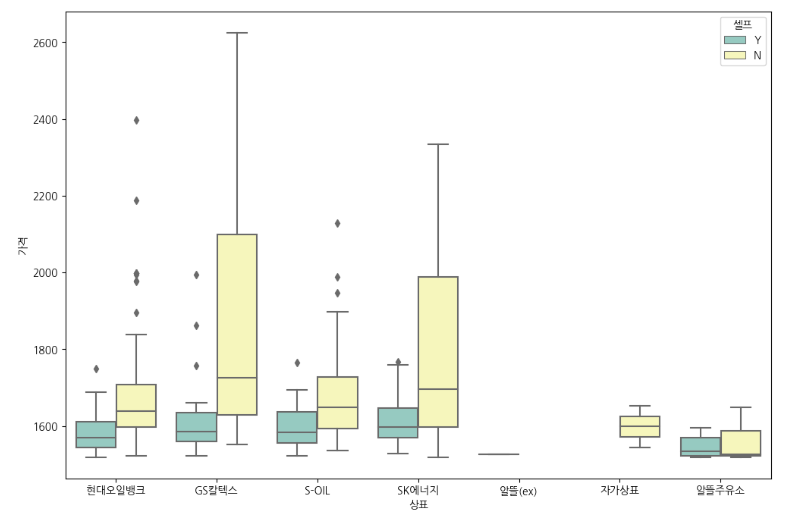
- 지도 시각화
import json
import folium
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
# 가장 비싼 주유소 10개
stations.sort_values(by="가격", ascending=False).head(10)
# 가장 값싼 주유소 10개
stations.sort_values(by="가격", ascending=True).head(10)
# 구별 평균가격 구하기
import numpy as np
gu_data = pd.pivot_table(data=stations, index="구", values="가격", aggfunc=np.mean)
gu_data.head()
geo_path = "../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="Stamen Toner")
my_map.choropleth(
geo_data=geo_str,
data=gu_data,
columns=[gu_data.index, "가격"],
key_on="feature.id",
fill_color="PuRd"
)
my_map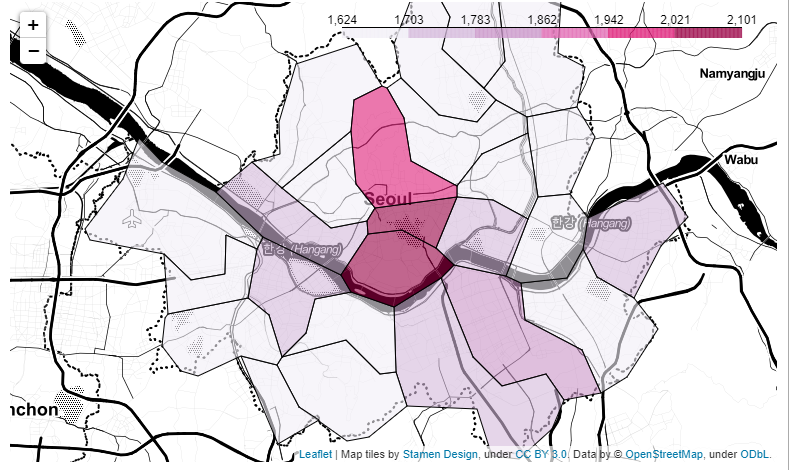
🎅오늘의 한마디
지난 시간에 이어 웹에서 데이터를 수집하는 Selenium 을 배웠다. 수집을 위해 웹에 대한 기본 구조를 알고 활용할 줄 알아야 한다는 것 다시 한 번 메모. 그리고 강의 중간에 "내가 무엇을 하고 있는지... 길을 잃지 말아야 한다"는 강사님 말씀이 있었는데 - 원래도 중요하다고 생각하는 말이어서 내적 친밀감 상승과 공감 백번!
