
< Supervised learning >
: 지도 학습. 인공지능 모델의 정답과 학습 문제를 알려줌
1. Machine learning
: 데이터로부터 내재된 패턴을 학습하는 과정.
사람이 어렸을 때부터 보고 자란 책과 미디어, 교육에 의한 내용에 따라서 갈기가 있고 이빨이 날카로운 동물을 사자라고 인식하는 것과 같음.
2. Supervised learning
: 입력 x 와 출력 y의 쌍으로 구성이 된 데이터 셋.
y를 label(레이블), 정답이라고 한다.
지도학습의 목적은 x->y 로 가는 함수 h를 학습하는 것이다.
새로운 영상이 들어왔을 때 그 영상의 category label을 맞추는 것이 목적이다.
(1) training : 정답과 model output과의 차이인 error를 통해 이 값을 줄여가는 방향으로 학습이 된다.
(2) test : 완전히 새로운 입력으로 모델의 성능을 평가할 수 있다.
(입력 feature -> 도메인에 대한 지식이 필요함. Ex. 차량 sample에서 엔진power와 price의 상관관계)
3. Target function
: 정답 함수
X->Y 입력 X를 정답 Y로 매핑되게 하는 정답 함수이며, 완벽하게 구현할 수 없다. (모든 데이터셋을 다 가지고 정답을 말해야 하므로)
그래서 데이터셋을 가지고 정답 함수에 가깝게 다가가게 하는 것이 목적이다.
4. 지도학습의 로드맵
(1) target function을 만드는 것이 목적
(2) training set을 활용한다
(3) learning model : 학습시키는 과정에서 세가지를 수행한다.
- Feature selection : 특징을 잡아내는 것인데 도메인에 대한 지식이 필요할 때도 많다.
- Model selection : 적절한 모델을 찾아내는 일
- Optimization : 오류를 최소화하도록 하이퍼파라미터 값을 조정하여 최적화시키는 작업
Hypothesis 함수의 학습 과정이란? 우리가 지도학습을 사용하는 목적은 정답 함수 f를 모사하는 것이고, 실제 세계에서 존재하는 sample들의 realization으로서의 data set을 활용한다.
5. Generalization
: Machine learning은 그 자체로 데이터의 결핍으로 인한 불확실성을 포함하고 있다.
-> Generalization 일반화과정이 중요하다 : 학습과정에서 관찰하지 못한 sample에 대해서도 우수한 성능을 제공할 수 있어야 한다. -> generalized E (error)를 최소화시키는 것이 중요하다. Training error, validation error, test error를 통해 generalized error를 줄여야 한다.
6. Error
: squared error, binary error, loss function(cost function)
오차를 어떻게 줄일 수 있을까?
(1) test셋의 에러를 training셋의 에러와 비슷하게 만든다.
(2) training셋의 에러를 0에 가깝게 만든다.
7. Bias
- variance의 tradeoff 관계
High bias -> underfitting -> 모델이 쉬워짐 (low variance) -> 우수한 성능을 제공하기 어려움
Low bias -> overfitting -> 모델이 복잡 (high variance) -> 일반적인 성능을 제공하기 어려움
이 두가지를 균형있게 맞춰서 generalization error를 적게 만들어야 한다. 모델의 일반성을 높여야 한다.
8. Curse of dimension
: 요즘은 미디어같은 비정형 데이터, 즉 복잡한 데이터를 많이 다루는데 그에 반해 학습시킬 데이터는 많이 없어서 overfitting 문제가 많아지고 있다.
: 입력 데이터 또는 입력 피쳐의 차원이 증가한다면 지수적으로 샘플 숫자가 늘어나야 하는데 실제로는 그렇게 하기 어렵다.
- 데이터를 어떻게 늘릴 수 있을까?
9. Data augmentation
: 샘플 데이터의 숫자를 높인다.
- CV : cross-validation
학습 데이터셋을 k개의 그룹으로 나누어 k-1개만 학습에 사용하고 k개를 validation으로 사용한다.
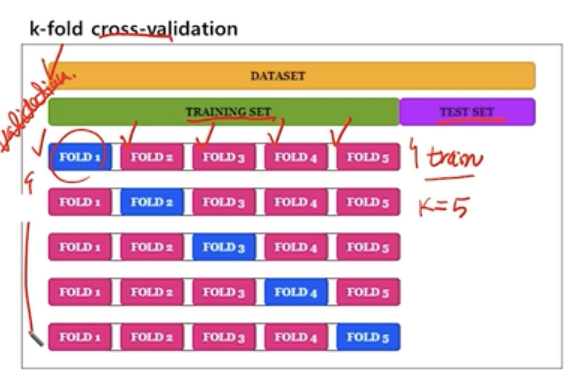
Ex) K = 5인 경우
* 퀴즈
-> 다음 중 classification 문제는
1. 날씨 데이터에 따라서 언제 히터를 켜고 끄는 지 결정하는 문제
2. 손글씨를 아스키코드로 변환하는 문제
3. 히터 레벨과 실제 온도 사이의 수학적 관계를 찾아내는 문제
-> 이 중 1,2 가 분류 (classification) 문제라고 할 수 있다.
: 왜? 3번은 regression임. 관계식을 찾아내는 것. 1은 binary classification, 2도 단일한 정답에 맞도록 하는 것이므로.
- 퀴즈
-> 지도학습에 대한 옳은 말은
- 레이블링 된 데이터를 요구한다.
- 트레이닝 셋과 테스트 샘플은 오버랩될 수 없다. (다른 데이터여야만 한다)
- 정리
지도학습에는 크게 classification(분류)와 regression(회귀) 문제가 존재한다.
키포인트는 레이블과 비교하여 에러를 줄여가는 것이다. 오버/언더피팅이 되지 않는 선에서!
