이전에 수집한 데이터들을 'mywebtoon_data.csv' 와 'mycomment_data.csv'에 저장하였다.
🔎 수집한 데이터
아래는 'mywebtoon_data.csv' 의 columns 정보이다.
- titleId : 각 웹툰의 고유번호
- isPublic : 정식연재 승격 여부
- totalStar : 전체별점
- heart : 하트수
- contentGenre : 내용장르 10개 중 n개
daily/comic/fantasy/action/drama/pure/sensibility/thrill/historical/sports- typeGenre : 형식장르 3개 중 1개
에피소드/옴니버스/스토리- star(i) : i번째 회차의 별점 *(i = 1,2,3,-3,-2,-1)
- starPar(i) : i번째 회차의 별점참여수
- day(i) : i번째 회차의 등록일
- views(i) : i번째 회차의 조회수
아래는 'mycomment_data.csv' 의 columns 정보이다.
- titleId : 각 웹툰의 고유번호
- isPublic : 정식연재 승격 여부
- comment : 댓글 내용
- like : 해당 댓글의 좋아요 수
- hate : 해당 댓글의 싫어요 수
📄 데이터 정리
연재 시작 날짜로 웹툰 선택
지금까지는 모든 웹툰을 수집하였다. 급격히 바뀌는 트렌드를 반영하여 너무 오래된 웹툰들은 분석 데이터에서 제외하자는 판
단을 하였다.
webtoon['day1'] = pd.to_datetime(webtoon['day1'])
webtoon['day1'].dt.year.value_counts().plot.bar()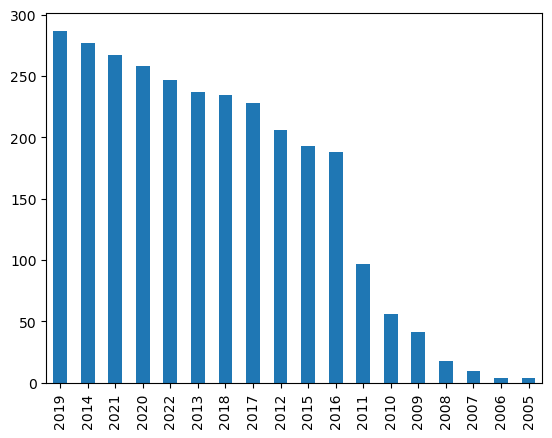
2012년에 베스트도전 웹툰의 수가 급격히 늘었다. 따라서 2012년 전의 웹툰들은 삭제하였다.
webtoon = webtoon[webtoon['day1'].dt.year >= 2012]
webtoon.reset_index(drop= True, inplace= True)
# 댓글 데이터에서도 제외
titleId = webtoon['titleId'].unique()
for id in comment['titleId']:
if id not in titleId:
comment.drop(comment[comment['titleId'] == id].index, inplace=True)
comment.reset_index(drop= True, inplace= True)그 결과, 전체 웹툰의 수는 2623개, 공식연재(isPublic == 1) 웹툰의 수는 153개였다.
4화, 5화밖에 없는 웹툰 정리
회차의 등록일을 기준으로 4개 또는 5개의 회차만 존재하는 웹툰을 정리하였다. 예를 들어, 4개의 회차만 존재한다면, 데이터 수집 순서가 (-1) -> (-2) -> (-3) -> 1 -> 2 -> 3 이므로, 2와 3은 비어있어야 한다. 5개의 회차만 존재한다면, 3이 비어있는 데이터여야 한다.
# 4화만 있는 웹툰 : 2,3 삭제
only4 = data[data['day2'] == data['day(-2)']].index
data.loc[only4, ['star2','starPar2','views2','day2']] = np.NaN
data.loc[only4, ['star3','starPar3','views3','day3']] = np.NaN
only4 = data[data['day2'].isnull()].index
# 5화만 있는 웹툰 : 3 삭제
only5 = data[data['day3'] == data['day(-3)']].index
data.loc[only5, ['star3','starPar3','views3','day3']] = np.NaN
only5 = data[data['day3'].isnull()].index📊 데이터 eda 및 변수화
---고려해본 것!---
1. 초반 회차 데이터와 후반 회차 데이터를 하나의 변수로 나타내기
2. 분포가 편향된 변수들에 로그변환, 역변환, Box-cox 변환 등 반영하기
패키지 import
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
from datetime import datetime
import time
data = pd.read_csv('mywebtoon_data.csv')종속변수 isPublic
print(data['isPublic'].value_counts())
plt.figure(figsize= (5,4))
data['isPublic'].value_counts().plot(kind = 'bar')
plt.show()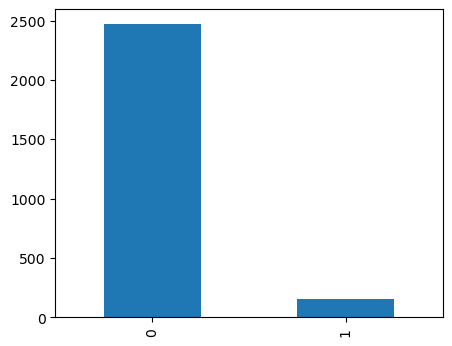
정식연재 웹툰(isPublic == 1)이 매우 적으므로 (약 5%) 이를 고려하여 모델링에 참고하였다.
totalStar
plt.figure(figsize= (6,3))
sns.distplot(data['totalStar'])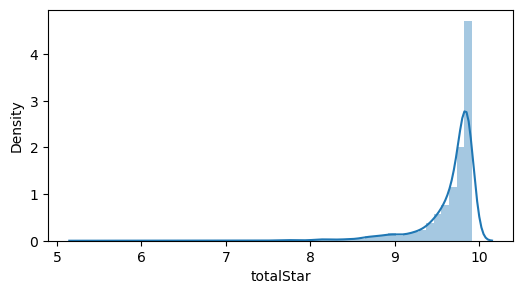
대부분의 별점이 9점대에 몰려있다. 이렇게 한쪽으로 몰려있는 데이터는 이후 모델링의 성능에 악영향을 끼칠 수 있다. 따라서 다양한 변환을 이용해 정규분포에 가까운 모양을 나타내거나 데이터를 분산시키는 방법을 선택하였다.
fig, ax = plt.subplots(ncols=2)
# 로그변환
sns.distplot(np.log(data['totalStar']), ax=ax[0], color='red')
# boxcox 변환
y, lambda_optimal = stats.boxcox(data['totalStar'])
sns.distplot(y, ax=ax[1], color='red')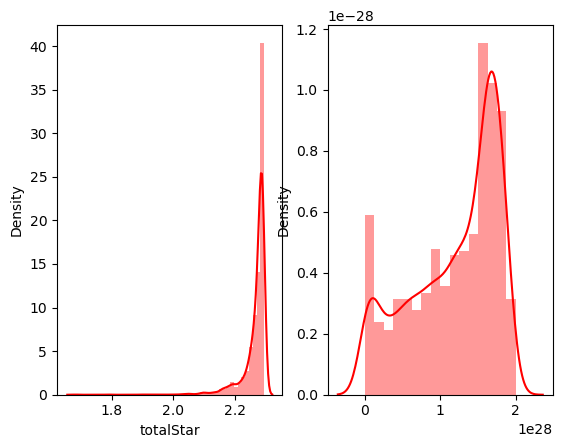
왼쪽은 로그변환, 오른쪽은 Box-cox 변환 후 분포이다. totalStar 변수는 box-cox 변환이 데이터를 잘 분산시켰지만, 값이 너무 커지는 이유로 선택하지 않았다. 그러나 다른 변수들의 변환 및 변수화 결과, 값이 0 근처에서 그게 벗어나지 않아 각 데이터에 최솟값을 빼준 값을 새 데이터로 설정하였다.
heart
data['heart'] = data['heart'].str.replace(',','') # 천단위 콤마 제거
data['heart'] = data['heart'].astype(int)
plt.figure(figsize= (6,3))
sns.distplot(data['heart'])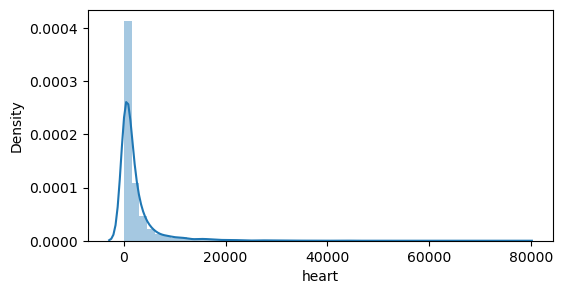
로그변환!
sns.displot(np.log(data['heart']), color='red')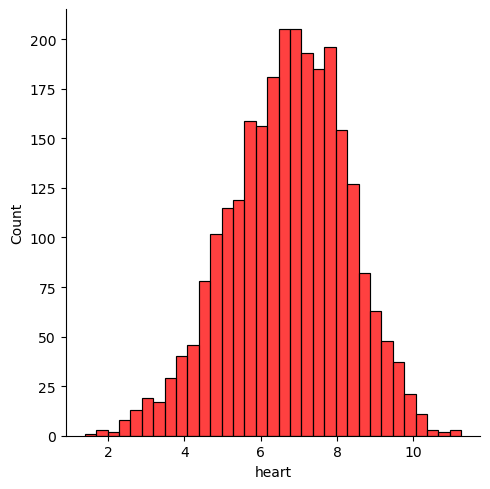
star
star1, star2, star3와 star(-3), star(-2), star(-1)의 평균으로 초반, 후반 별점을 구하여 분포를 확인하였다. 이때, 4개 또는 5개 회차밖에 존재하지 않는 웹툰은 존재하지 않는 데이터를 제외하고 평균을 구하였다.
# 3개 화의 평균을 이용해 초반, 후반으로 나눔.
data['starEarly'] = (data['star1'] + data['star2'] + data['star3'])/3
data['starLater'] = (data['star(-1)'] + data['star(-2)'] + data['star(-3)'])/3
data.loc[only5,'starEarly'] = (data['star1'] + data['star2'])/2
data.loc[only4,'starEarly'] = data['star1']
# 초반과 후반 분포
fig, ax = plt.subplots(ncols=2)
sns.distplot(data['starEarly'], ax=ax[0])
sns.distplot(data['starLater'], ax=ax[1])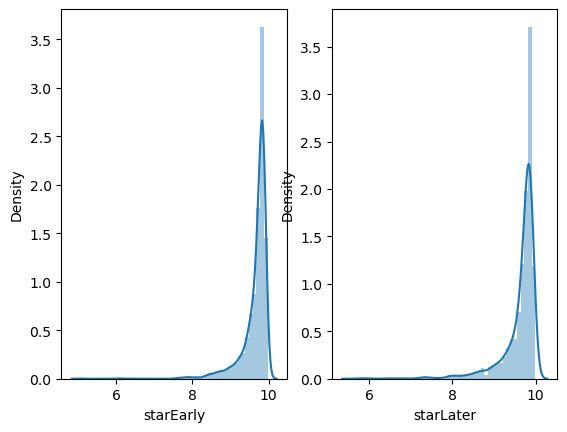
변환 후 파생변수를 만들고자 하였으나, 변환 후 데이터의 분포에서 크게 효과를 보지 못하였다. 따라서 초반과 후반 별점의 차이(후반별점 - 초반별점) 또는 비율(후반별점 / 초반별점)을 구하여 파생변수로 만들었다.
data['starDif'] = data['starLater'] - data['starEarly'] # 차이
data['starRatio'] = data['starLater'] / data['starEarly'] # 비율
fig, ax = plt.subplots(ncols=2)
sns.distplot(data['starDif'], ax=ax[0])
sns.distplot(data['starRatio'], ax=ax[1])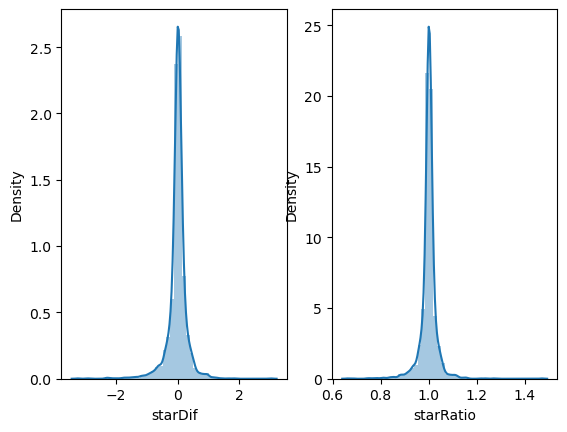
왼쪽은 차이, 오른쪽은 비율의 분포 그래프이다. 둘 중 isPublic 변수와 상관관계가 높은 '차이' 를 이용하였다. (차이 : 0.061, 비율 : 0.055, 상관관계로 변수를 선택한 것이 옳은 방법인지는 더 공부해볼 것.)
starPar
별점에서와 같은 방법으로, 초반 회차와 후반 회차의 별점참여수 평균의 로그변환 후, 비율을 파생변수로 만들었다.
data['starParEarly'] = (data['starPar1'] + data['starPar2'] + data['starPar3'])/3
data['starParLater'] = (data['starPar(-1)'] + data['starPar(-2)'] + data['starPar(-3)'])/3
data.loc[only5,'starParEarly'] = (data['starPar1'] + data['starPar2'])/2
data.loc[only4,'starParEarly'] = data['starPar1']
# 초반과 후반 분포
fig, ax = plt.subplots(ncols=2)
sns.distplot(data['starParEarly'], ax=ax[0])
sns.distplot(data['starParLater'], ax=ax[1])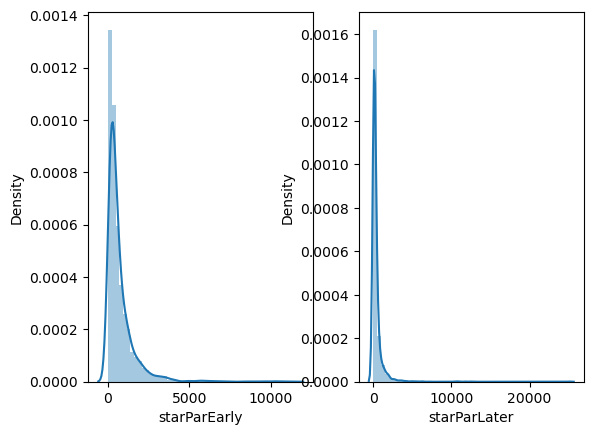
# 로그변환
fig, ax = plt.subplots(ncols=2)
sns.distplot(np.log(data['starParEarly']), ax=ax[0], color='red')
sns.distplot(np.log(data['starParLater']), ax=ax[1], color='red')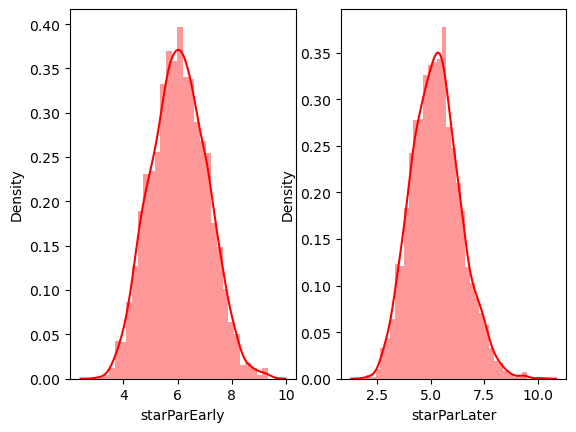
# 초반과 후반 로그변환의 비율 분포
data['starParRatio'] = np.log(data['starParLater']) / np.log(data['starParEarly'])
sns.distplot(data['starParRatio'])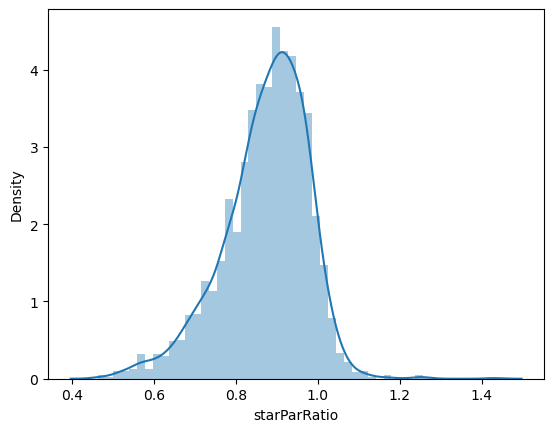
views
마찬가지로, 초반 회차와 후반 회차의 조회수 평균의 로그변환 후, 비율을 파생변수로 만들었다.
data['viewsEarly'] = (data['views1'] + data['views2'] + data['views3'])/3
data['viewsLater'] = (data['views(-1)'] + data['views(-2)'] + data['views(-3)'])/3
data.loc[only5,'viewsEarly'] = (data['views1'] + data['views2'])/2
data.loc[only4,'viewsEarly'] = data['views1']
# 초반과 후반의 분포
fig, ax = plt.subplots(ncols=2)
sns.distplot(data['viewsEarly'], ax=ax[0])
sns.distplot(data['viewsLater'], ax=ax[1])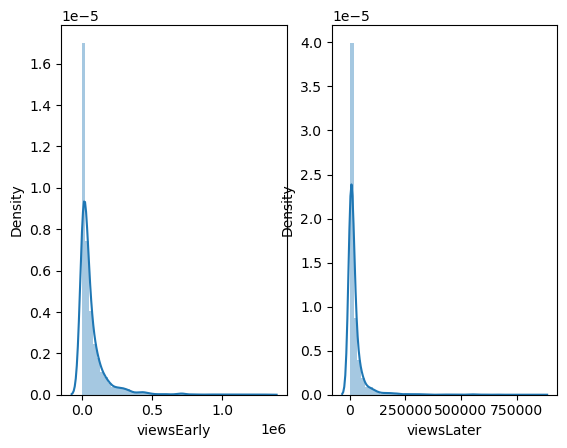
# 로그변환
fig, ax = plt.subplots(ncols=2)
sns.distplot(np.log(data['viewsEarly']), ax=ax[0], color='red')
sns.distplot(np.log(data['viewsLater']), ax=ax[1], color='red')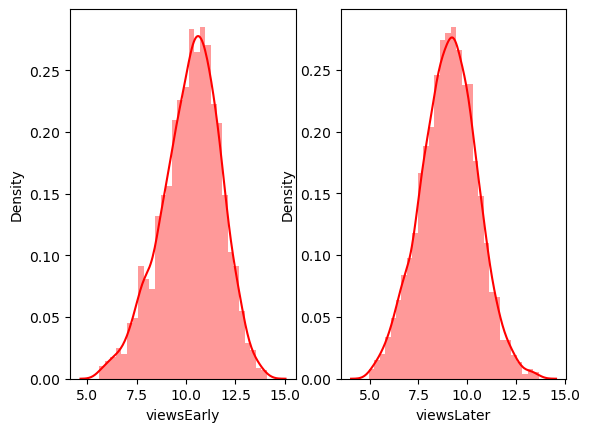
# 초반과 후반 로그변환의 비율 분포
data['viewsRatio'] = np.log(data['viewsLater']) / np.log(data['viewsEarly'])
sns.distplot(data['viewsRatio'])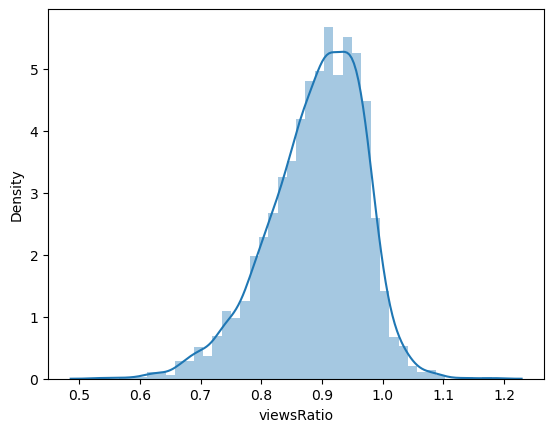
day
회차별 등록일 데이터는 각 회차의 날짜의 차이를 계산하여, 얼마나 자주 연재하였나를 변수로 넣고자 하였다.
# 날짜 데이터로 변환
data['day1'] = pd.to_datetime(data['day1'])
data['day2'] = pd.to_datetime(data['day2'])
data['day3'] = pd.to_datetime(data['day3'])
data['day(-3)'] = pd.to_datetime(data['day(-3)'])
data['day(-2)'] = pd.to_datetime(data['day(-2)'])
data['day(-1)'] = pd.to_datetime(data['day(-1)'])
# 등록일 차이 계산
dateInterval1 = data['day2'] - data['day1']
dateInterval2 = data['day3'] - data['day2']
dateInterval3 = data['day(-2)'] - data['day(-3)']
dateInterval4 = data['day(-1)'] - data['day(-2)']
data['dateInterval'] = (dateInterval1+dateInterval2+dateInterval3+dateInterval4)/4
data.loc[only5, 'dateInterval'] = (dateInterval1+dateInterval3+dateInterval4)/3
data.loc[only4, 'dateInterval'] = (dateInterval3+dateInterval4)/2
data['dateInterval'] = data['dateInterval'].dt.days
# 분포
sns.distplot(data['dateInterval'])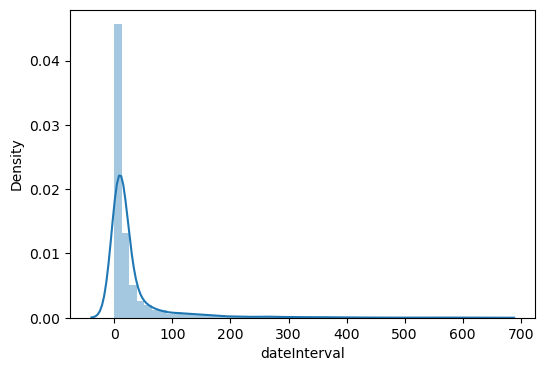
상당히 큰 값을 가진 데이터들이 존재하여 로그변환을 수행하였다. 값이 0인 데이터는 로그를 취할 수 없어 -1로 정의하였다.
# 로그변환
data['dateInterval'] = np.log(data['dateInterval'][data['dateInterval'] != 0.0])
data['dateInterval'][data['dateInterval'] == 0] = -1
sns.distplot(data['dateInterval'])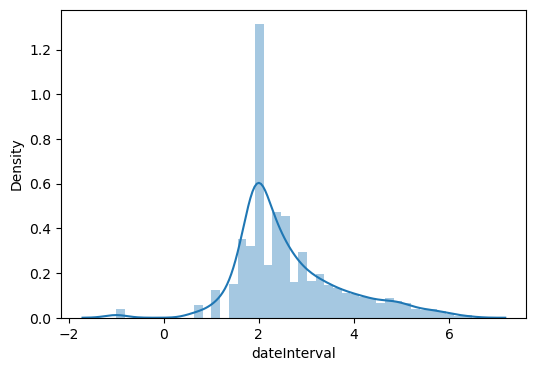
typeGenre
스토리, 에피소드, 옴니버스의 type장르는 원핫인코딩을 하였다. type_스토리 변수의 해당 웹툰이 스토리 장르이면 1, 아니면 0의 값을 갖는다.
pd.get_dummies(data['typeGenre'], prefix = 'type')
contentGenre
daily, comic, fantasy, action, drama, pure, sensibility, thrill, historical, sports의 content장르도 마찬가지로 변환하였다.
+) 실제 프로젝트에서는 R에서 glm(일반화 선형모델)을 돌려 중요도 기준으로 장르를 하나씩만 선택하였다. 아래는 R 코드이다. (이부분은 아직 공부가 더 필요하다.)
결과만 말하자면, 장르의 중요도는 thrill > daily > fantasy > comic > drama > pure > action > sensibility > sports > historical 이었다.
library(data.table)
library(dplyr)
library(MASS)
library(stringr)
webtoon = read.csv('./mywebtoon_data.csv', header=T, fileEncoding='utf-8')
webtoon$isPublic <- as.factor(webtoon$isPublic)
# 장르 개수 입력
webtoon$numGenre <- 1
for (i in 1:length(webtoon$contentGenre)) {
genre = strsplit(webtoon$contentGenre, split=",")[i][[1]]
while (length(genre) > webtoon$numGenre[i]) {
webtoon$numGenre[i] <- webtoon$numGenre[i] + 1
}
}
# 중요도 계산
cont_list = c('action','comic','daily','drama','fantasy','historical','pure','sensibility','sports','thrill')
fit_genre_thrill <- glm(isPublic ~ factor(webtoon$contentGenre[webtoon$numGenre==1], levels=cont_list[c(10,1:9)]),
family=binomial, data=webtoon[webtoon$numGenre==1,])
fit_genre_thrill %>% summary()
# p-value 가 작은 순서대로 지정
webtoon$oneGenre <- webtoon$contentGenre
cont_pval_list = c('thrill','daily','fantasy','comic','drama', 'pure','action','sensibility','sports','historical')
for (i in 1:length(webtoon$oneGenre)){
for (cont in cont_pval_list) {
genre = str_detect(webtoon$contentGenre[i], cont)
if (genre) {
webtoon$oneGenre[i] <- cont
break
}
}
}❓초반과 후반 데이터의 파생변수를 고려한 이유
초반과 후반 회차 데이터을 그대로 변수로 사용하지 않고, 차이 혹은 비율의 파생변수를 고려한 이유는 다음과 같다. 첫번째 이유는, 후반 회차의 데이터의 수집 목적이 뒤늦게 인기를 얻는 웹툰과 타 웹툰의 차이를 줄이고자 하는 것이었기 때문이다. 즉, 초반 회차의 데이터 그 자체보다 후반에 비해 초반에 얼마나 큰 주목을 끌었나를 변수화시키고 싶었다. 두번째 이유는 아래 그래프(초반과 후반의 조회수 산점도)를 통해 '조회수가 높은 것보다, 조회수를 후반까지 유지하는 것이 더 중요함'을 발견했기 때문이다.
# viewsEarly vs. viewsLater
dt1 = data[data['isPublic'] == 0][['viewsEarly','viewsLater']]
dt2 = data[data['isPublic'] == 1][['viewsEarly','viewsLater']]
plt.scatter(dt1['viewsEarly'], dt1['viewsLater'], c='green')
plt.scatter(dt2['viewsEarly'], dt2['viewsLater'], c='red')
plt.xlabel('viewsEarly')
plt.ylabel('viewsLater')
plt.show()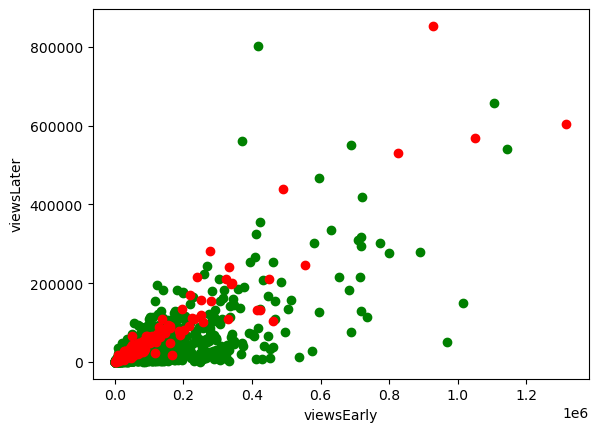
그래프에서 빨간색은 정식연재, 초록색은 정식연재가 아닌 웹툰이다. 빨간색 점들은 y=x 그래프꼴로 선형관계를 보이는 반면, 초록색 점들은 아래로 처지는 점들이 많이 보인다. 이를 통해 조회수가 초반이 높고 후반은 낮은 웹툰들은 정식연재로 승격되지 않는 것을 알 수 있다.
