베도웹툰 정식연재 프로젝트
1.베스트도전 웹툰의 정식연재 승격 확률 예측 - 2. 회차 크롤링
selenium 을 이용한 웹툰 회차별 크롤링
2023년 2월 5일
2.베스트도전 웹툰의 정식연재 승격 확률 예측 - 3. 데이터 변수화
수치형, 범주형 데이터의 eda 및 변수화
2023년 2월 6일
3.베스트도전 웹툰의 정식연재 승격 확률 예측 - 4. 댓글분석
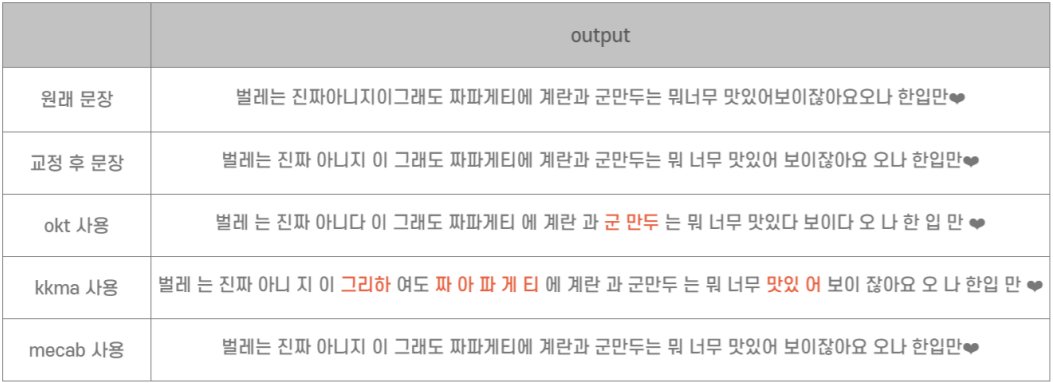
이전에 수집한 댓글 데이터를 확률 예측의 변수로 만드는 과정에서 많은 고민이 있었다. 그 과정을 간단히 설명하자면, 댓글 내용을 형태소별로 토큰화하여 정식연재와 비정식연재 웹툰의 빈도수가 높은 단어들을 비교하였다. 빈도수가 높은 단어들 중 정식 연재를 판가름할 수 있다
2023년 4월 8일
4.베스트도전 웹툰의 정식연재 승격 확률 예측 - 5. 모델링

정식연재 웹툰의 수가 비정식연재 웹툰의 수에 비해 매우매우 적어, 정확도만으로는 정확한 분류와 예측이 힘들었다. 따라서 분류의 명확성을 나타내는 AUC를 모델의 성능으로 선택하였다.데이터 불균형이 매우 심한 것을 알 수 있다.모델 성능 확인AUC : 0.9285ACC
2023년 4월 8일