
맛집 리뷰 감성 분류기를 다른 곳에서 사용할 수 있도록 모듈의 형태로 만들었습니다.
- 리뷰 데이터와 긍정적 리뷰인지 부정적인지에 대한 데이터를 인터넷에서 수집합니다.
- 한국어 형태소 분석기 라이브러리로 글을 적절히 전처리하고 이를 정수 인코딩하고 정규화를 합니다.
- keras 라이브러리를 이용해서 학습을 하고 모델을 만들어 냅니다.
- 모델 평가와 튜닝을 끝내고 나면 재사용, 확장이 가능하도록 모듈로 만듭니다.
🥚 데이터 수집
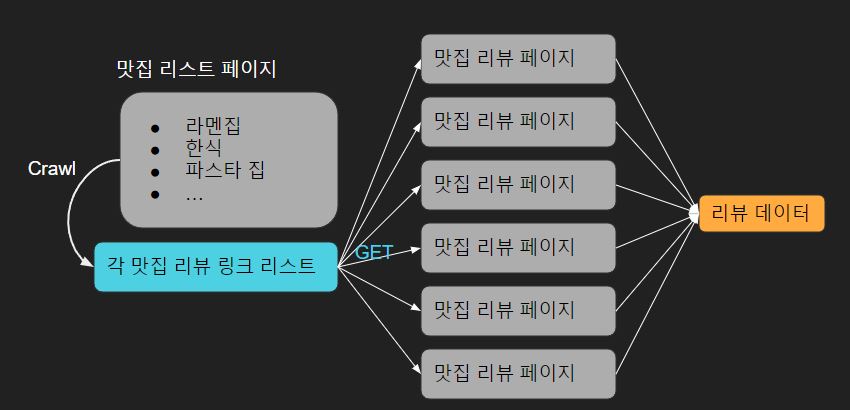
맛집 리뷰는 selenium로 크롤링해서 데이터를 얻었습니다.
- 맛집 사이트에 각 맛집들에 대한 리스트가 나열되어 있는 페이지로 접속합니다.
- 리스트에 있는 각 맛집들의 링크를 받아와서 리스트의 형태로 저장합니다.
- 받아온 링크 리스트에서 하나씩 접속해서 해당 리뷰 페이지에 있는 리뷰 텍스트들을 수집합니다.
받아온 데이터입니다.
| review | label | |
|---|---|---|
| 0 | 순대국밥에 진심인 내가, 감히 최고라고 추천하고픈 곳\n\n1. 사실 국밥 분야는 ... | 1 |
| 1 | 수육과 깍두기가 맛있는 국밥집\n\n국밥정식을 주문했다\n\n놀랍게도 이집을 대치동... | 1 |
| 2 | 선릉-역삼을 혼자 가야만 하는 이유. 둘 이상 가면 무한대기를 해야함. 어차피 순대... | 1 |
| 3 | 평일 오후 6시에도 웨이팅이 있는, 순대국의 전통강자. 강남점도 가봤는데 여기가 훨... | 1 |
| 4 | 한국인의 소울푸드, 순대국밥의 맛을 가장 잘 나타내는 곳이 바로 농민백암순대 본점이... | 1 |
| ... | ... | ... |
| 6389 | 널찍한 실내와 편안한 의자와 분위기\n\n코지한 분위기는 아니지만 힙하고 큼직하다\... | 1 |
| 6390 | 초코초코한데 비쥬얼 만큼 달지않아요. | 1 |
| 6391 | 분위기가 힙스럽다. 층고는 한껏 높고, 앞에는 캠핑 의자가 놓여있다. 포틀랜드의 코... | 1 |
| 6392 | 기존 위치에서 스투시 2층으로 이전하면서 컨셉을 싹 바꿨네요.. 기존의 포틀랜드 감... | 0 |
| 6393 | 진심으로 평점이 왜 이렇게 높은지 모르겠음. 위치도 별로 좋은 거 같지도 않고 커피... | 0 |
6394 rows × 2 columns
label이 0인 데이터는 부정적인 리뷰이고 1인 데이터는 긍정적인 데이터입니다.
중복되는 데이터와 리뷰가 1글자 밖에 안되는 의미없는 데이터들을 삭제합니다.
data = data.drop_duplicates(subset=['review'])
df = data.drop(data[data['review'].map(lambda x: len(x)<2)].index)
df.shape
# output:
# (5392, 2)마지막으로 csv 파일로 저장합니다.
df.to_csv('review.csv', index=False)🍳 데이터 정제하기
데이터를 학습하기 좋은 형태로 만들어 주어야 합니다. 한국어 형태소 분석, 토큰화, 정수 인코딩, 패딩 등을 해서 학습할 수 있는 형태로 만들어보겠습니다.
사용한 라이브러리입니다.
import pandas as pd
import numpy as np
import re
from konlpy.tag import Okt
from tqdm.notebook import tqdm
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences데이터를 불러와서 확인해보겠습니다.
df = pd.read_csv('review.csv')
df['review'][666]
#output:
#'정말정말 가고싶었던 세시셀라!! 판교점을 가게 될 줄은 몰랐는데 ㅠㅠ
#결과는 실망입니다 머그포래빗 당근케익이 차라리 맛있었던 거 같아요\n
#음료로 시킨 애플레몬티는 맛있었어요'👨🍳 한국어 전처리
먼저 한국어를 제외한 영어, 숫자, 특수문자 등을 제거하고 한글과 공백만 남깁니다.
# 한글 제외한 문자 삭제
df['review'] = df.review.map(lambda x: re.sub('[^ㄱ-ㅎㅏ-ㅣ가-힣]', ' ', x))
df['review'] = df.review.map(lambda x: re.sub('\s{2,}', ' ', x))
df['review'][666]
#output:
#'정말정말 가고싶었던 세시셀라 판교점을 가게 될 줄은 몰랐는데 ㅠㅠ
#결과는 실망입니다 머그포래빗 당근케익이 차라리 맛있었던 거 같아요
#음료로 시킨 애플레몬티는 맛있었어요'출력 결과를 확인해보면 위의 데이터에서는 \n가 제거되었습니다.
한국어만 남았으므로 형태소를 추출할 차례입니다. 저는 오픈 소스 한국어 분석기(과거 트위터 형태소 분석기)를 사용해서 형태소를 추출했습니다.
tagger = Okt()
X_data = []
#불용어 사전
s_w = set(['은', '는', '이', '가', '를', '들', '에게', '의', '을', '도', '으로', '만', '라서', '하다',
'아', '로', '저', '즉', '곧', '제', '좀', '참', '응', '그', '딱', '어', '네', '예', '게', '고',
'하', '에', '한', '어요', '것', '았', '네요', '듯', '같', '나', '있', '었', '지', '하고', '먹다',
'습니다', '기', '시', '과', '수', '먹', '와', '적', '보', '에서', '곳', '너무', '정말', '진짜',
'있다', '다', '더', '인', '집', '면', '내', '라', '원', '요', '또', '하나', '전', '거', '엔',
'이다', '되다', '까지', '인데', '정도', '나오다', '주문', '시키다'])
for i in tqdm(df['review']):
tk_d = tagger.morphs(i, stem=True) # clean_X의 형태소 추출
tk_d = [w for w in tk_d if w not in s_w] # 불용어 제거
X_data.append(' '.join(tk_d)) # 공백을 기준으로 문자열로 조인
X_data[666]
#output:
#'가다 세시 셀라 판교 점 가게 줄 모르다 ㅠㅠ 결과 실망 머그 포 래빗 당 근
#케익 차라리 맛있다 같다 음료 애플 레몬 티 맛있다'👨🍳 토큰화와 정규화
토큰화를 하기 Tokenizer의 fit_on_texts 메서드를 사용하겠습니다.
tk = Tokenizer()
tk.fit_on_texts(X_data)등장 빈도 수가 낮은 형태소들은 제거하기 위해서 4번 이상 등장한 단어의 개수를 구합니다.
lesswordlen = 0
for i in tk.word_counts:
if tk.word_counts[i] > 4:
lesswordlen += 1
lesswordlen
#output:
#6639tokenizer로 텍스트를 정수 인코딩한 시퀀스 형태로 만듭니다. 그리고 시퀀스의 길이에 대한 정보를 출력해서 확인합니다.
tk.num_words = lesswordlen
trf_x = tk.texts_to_sequences(X_data)
pd.Series(map(lambda x: len(x), trf_x)).describe() # 시퀀스 길이 측정
#output:
#count 5392.000000
#mean 69.963279
#std 82.375268
#min 0.000000
#25% 22.000000
#50% 46.000000
#75% 90.000000
#max 1947.000000
#dtype: float6475%에 해당하는 시퀀스의 길이인 90을 패딩 길이로 설정해서 패딩합니다.
padded = pad_sequences(trf_x, maxlen=90)
padded.shape
#output:
#(5392, 90)토큰화를 진행하면서 모든 형태소 정보가 사라져서 시퀀스길이가 0인 데이터들은 제거해주어야 합니다. 따라서 시퀀스 길이가 0인 데이터를 탐색해서 제거한 후에 X 데이터를 만들어냅니다.
# 길이가 0이상인 인 시퀀스 탐색
zero_length = np.array(list(map(lambda x: len(x)>0, trf_x)))
#길이가 0이상인 데이터만 X_data에 저장
X_data = padded[zero_length]
X_data.shape
#output:
#(5361, 90)31개의 데이터가 제거되었습니다. y 데이터도 똑같은 작업을 해줍니다.
y_data = df['label'].to_numpy()[zero_length]🍽️ 데이터 나누기
학습 데이터와 테스트 데이터를 나누는건 사이킷런의 train_test_split 함수를 사용했습니다.
from sklearn.model_selection import train_test_split여기서 주의해야할 점이 있습니다. 요식업 리뷰는 대부분 긍정적인 리뷰가 많습니다. 그래서 지금 사용하는 데이터도 확인해보면 긍정리뷰가 더 많다는것을 볼 수 있습니다.
df['label'].groupby(df['label']).size()
#output:
#label
#0 1361
#1 4031
#Name: label, dtype: int64긍정 데이터가 3배 이상입니다. 따라서 학습 데이터와 테스트 데이터를 나눌 때 더 큰 편향이 발생하지 않도록 stratify 파라미터에 y 데이터를 넘겨줍니다.
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, shuffle=True, random_state=4, stratify=y_data)
X_train.shape, X_test.shape
#output:
#((4288, 90), (1073, 90))🎓 학습하기
케라스로 학습모델을 만듭니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.callbacks import EarlyStopping양방향 LSTM을 사용해서 학습모델을 만들었습니다.
model = Sequential()
model.add(layers.Embedding(lesswordlen + 1, 55, input_length=90))
model.add(layers.Bidirectional(layers.LSTM(64, dropout=0.25)))
model.add(layers.Dense(1, activation='sigmoid'))평가지표 metrics는 이진 분류 평가지표인 AUC를 사용하겠습니다.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['AUC'])AUC 값이 가장 높은 모델을 선택하고 조기종료 콜백함수를 파라미터로 주고 학습을 진행합니다.
e_st = EarlyStopping(monitor="val_auc", patience=2, restore_best_weights=True, mode='max')
model.fit(X_train, y_train, epochs=20, validation_split=0.2, batch_size=256, callbacks=[e_st])테스트 데이터로 모델을 평가해보았습니다.
model.evaluate(X_test, y_test)
#output:
#34/34 [==============================] - 0s 14ms/step - loss: 0.2556 -
#auc: 0.9450🧊 모델 파일로 저장하기
전처리를 할 때 필요한 토크나이저와 예측모델을 저장합니다.
import pickle
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tk, handle, protocol=pickle.HIGHEST_PROTOCOL)
model.save('review.h5')🍎 리뷰 감성 분류기 모듈 만들기
restaurant_review_classifier.py파일에 분류기를 클래스로 구현합니다.
먼저 필요한 라이브러리들을 임포트합니다.
import numpy as np
import re
import pickle
from konlpy.tag import Okt
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences객체 생성자는 모델과 토크나이저를 파일로부터 읽고 predict 메서드에서는 전처리를 한뒤에 예측 모델로 예측을 한 결과를 출력합니다.
class RestarantReviewClassifier:
def __init__(self):
# 토크나이저와 예측 모델 불러오기
with open('tokenizer.pickle', 'rb') as handle:
self.tokenizer = pickle.load(handle)
self.model = tf.keras.models.load_model('review.h5')
self.tagger = Okt()
def predict(self, input_data):
# 한국어 전처리
input_data = list(map(lambda x: re.sub('[^ㄱ-ㅎㅏ-ㅣ가-힣]', ' ', x), input_data)) # 한글 제외한 문자 삭제
input_data = list(map(lambda x: re.sub('\s{2,}', ' ', x), input_data))
X_data = []
# 불용어 사전
s_w = set(['은', '는', '이', '가', '를', '들', '에게', '의', '을', '도', '으로', '만', '라서', '하다',
'아', '로', '저', '즉', '곧', '제', '좀', '참', '응', '그', '딱', '어', '네', '예', '게', '고',
'하', '에', '한', '어요', '것', '았', '네요', '듯', '같', '나', '있', '었', '지', '하고', '먹다',
'습니다', '기', '시', '과', '수', '먹', '와', '적', '보', '에서', '곳', '너무', '정말', '진짜',
'있다', '다', '더', '인', '집', '면', '내', '라', '원', '요', '또', '하나', '전', '거', '엔',
'이다', '되다', '까지', '인데', '정도', '나오다', '주문', '시키다'])
for i in input_data:
tk_d = self.tagger.morphs(i, stem=True) # clean_X의 형태소 추출
tk_d = [w for w in tk_d if w not in s_w] # 불용어 제거
X_data.append(' '.join(tk_d))
#시퀀스로 변환과 패딩작업
X = self.tokenizer.texts_to_sequences(X_data)
X = pad_sequences(X, maxlen=90)
X = np.array(X)
# 예측 결과를 반올림해서 출력
return np.array(list(map(lambda x: np.round(x, 0), self.model.predict(X))))예측결과를 반올림해서 출력하는데 그 이유는 0.5 기준으로 높으면 긍정리뷰1이고 낮으면 부정리뷰0로 출력했기 때문입니다. threshold 파라미터를 추가해서 임계값을 설정하도로 코드를 수정할 수도 있지만 여기서는 하지 않았습니다.
😃 모듈 사용 테스트
from restaurant_review_classifier import RestarantReviewClassifier
x_data = ['가면 갈수록 기분나빠지는 곳. 절대로, 두번 다시 안간다.',
'고기 맛은 최고!! 다만 정신놓고 먹다보면 지갑이 텅텅!',
'맛집이라고 해서 가봤는데 별로네요',
'가격에 비해 낙곱새에 낙지가 너무 적어요.']
clf = RestarantReviewClassifier()
clf.predict(x_data)
#output:
#array([[0.],
# [1.],
# [0.],
# [0.]], dtype=float32)두번 째 입력값은 긍정리뷰, 나머지는 부정리뷰로 분류한 결과를 볼 수 있습니다. 결과는 깃헙 레포지토리에 저장했습니다.
Reference
한국어 자연어 처리, 감성 분류에 대한 깊은 정보를 얻고 싶다면 다음 논문들을 참고하면 좋습니다.
