1. Iris Dataset 활용
1) scikit-learn
- 머신러닝 라이브러리
- 머신러닝의 다양한 알고리즘과 편리한 프레임워크를 제공
- toy datasets, real-world datasets 제공
- 함수
X_train, X_test, y_train, y_test = train_test_split(data_feature, label, test_size, randomstate)-
train_test_split-
data_feature: 문제지, 결과를 내기 위해 입력 받는 특징
-
label: 모델이 맞혀야하는 정답값
✔✔✔🤔
- X에는 특징이, y에는 정답값(label)이 저장됨.
X 데이터셋을 머신러닝 모델에 입력하고, 그에 따라 모델이 내오는 예측 결과를 정답인 y와 비교하며 점차 정답을 맞히도록 학습을 시키는 것.
- X에는 특징이, y에는 정답값(label)이 저장됨.
-
test_size: 테스트를 할 때 이용할 데이터 크기
-
random_state: train 데이터와 test 데이터를 분리(split)하는데 적용되는 랜덤성을 결정
-
2) Iris Dataset
- 3개의 카테고리: setosa, versicolour, virginica
- 150개의 데이터
3) 머신러닝 개념
1. feature와 label
- 문제지: 머신러닝 모델에게 입력되는 데이터. feature라고 부르기도 한다. 변수 이름으로는 X를 많이 사용한다.
- 정답지: 머신러닝 모델이 맞혀야 하는 데이터. label 또는 target이라고 부르기도 한다. 변수 이름으로는 y를 많이 사용한다.
2. 지도학습과 비지도 학습
- 지도학습: 정답이 있는 문제에 대해 학습
- 분류: 입력받은 데이터를 특정 카테고리 중 하나로 분류하는 문제
- 회귀: 입력받은 데이터에 따라 특정 필드의 수치를 맞히는 문제
- ex) 집에 대한 정보(평수, 위치, 층수 등)를 입력받아 그 집의 가격을 맞히는 문제
- 비지도학습: 정답이 없는 문제에 대해 학습
3. Decision Tree
참고
- 데이터를 분리해나가는 모습이 나무를 뒤집어놓은 것과 같은 모양
- 분류, 회귀에 모두 이용 가능 (범주나 연속형 수치 모두 예상 가능)
- 결정경계가 데이터 축에 수직이어서 특정 데이터에만 잘 작동할 가능성이 있음
➕ 랜덤포레스트
Decision Tree의 단점을 보완하기 위해 나온 모델
여러 개의 Decision Tree를 사용해 그 결과를 종합, 예측 성능을 높임
4. SVM
- Support Vector와 Hyperplane(초평면)을 이용해서 분류를 수행하게 되는 대표적인 선형 분류 알고리즘
5. SGD (Stochastic Gradient Descent)
- 배치 크기가 1인 경사하강법 알고리즘
- '확률적(Stochastic)'이라는 용어는 각 배치를 포함하는 하나의 예가 무작위로 선택된다는 것을 의미
6. Logistic Regression
- 가장 널리 알려진 선형 분류 알고리즘
- 소프트맥스(softmas) 함수를 사용한 다중 클래스 분류 알고리즘
- 이름은 회귀이지만 분류 수행
7. 모델 평가 방법
- label이 불균형하게 분포되어있는 데이터를 다룰 때 accuracy만으로는 좋은 척도가 될 수 없음
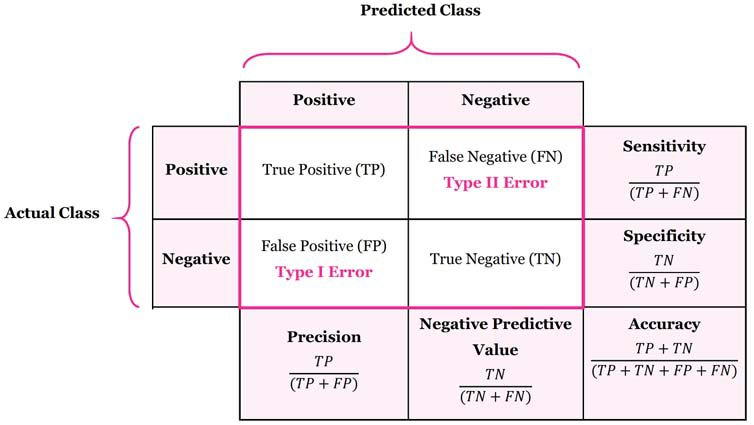
- TP: 실제 Positive, 판단 Positive
- FP: 실제 Negative, 판단 Positive
- TN: 실제 Negative, 판단 Negative
- FN: 실제 Positive, 실제 Negative

- 정밀도(Precision) ex) 스팸메일 분류 (FP가 중요)
- 재현율(Recall, Sensitivity) ex) 질병 양음성(FN이 중요)
- F1 스코어(f1 score): Recall과 Precision의 조화평균
- TP는 높고 FP또는 FN이 낮을수록 좋은 예측
- 모델.predict
참고
결정트리로 와인 분류
토닥토닥 파이썬 머신러닝 추가문제
2. 회고
잘하고 있는건지 모르겠다. 마지막에 유방암 데이터 분석하는 거에서 recall 값이 네 모델이 다 갖게 나와서.. 확인해보니 sgd를 random forest 이용해서 계산해놓음.. 다행히 고쳐서 제출했다. recall 값이 아주 높게 나오는 것도 과적합의 결과라고 볼 수 있을까? 문제를 푼 방법이 정확한지 모르겠는데 뭘 모르는지도 모르겠다. 일단 개념 확인하고 배운 데에 의의를 두고 여기서 마친다..

🐬 파이썬 / 인공지능 / 머신러닝