1. 파이썬 개념 정리
코딩도장 Unit 39, 40을 보고 정리한 부분
이터레이터, 제너레이터 > 데이터 셋이 클 때 활용함. 메모리 차이가 많이 남
1) 이터레이터
- 의미
값을 차례로 꺼낼 수 있는 객체 - 지연 평가
데이터 생성을 뒤로 미루는 것
▶ 이터레이터만 생성하고 값이 필요할 때 값을 만드는 방식 - 확인 방법
dir 함수를 이용해 객체에__iter__메소드 있는지 확인 - 동작 방법
for에서 range의 동작 과정
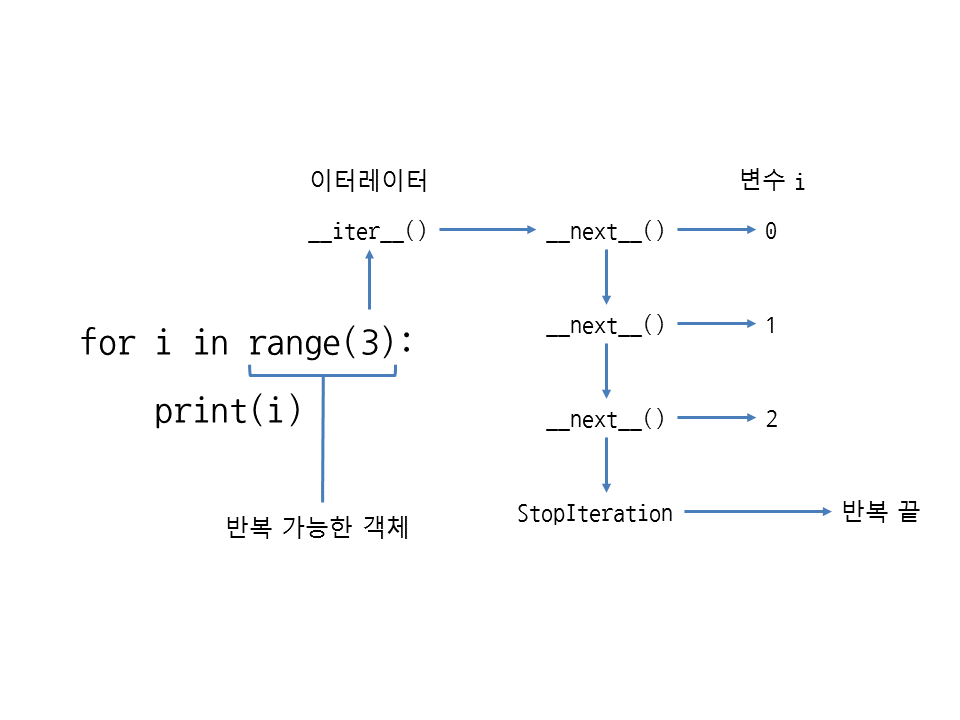
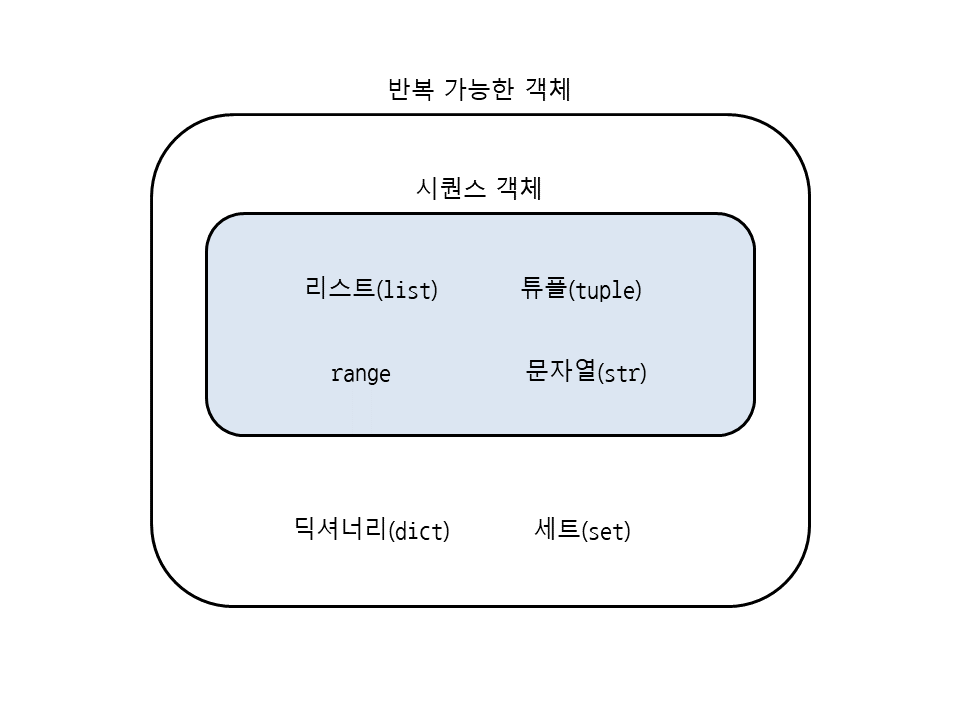
- 반복 가능한 객체와 시퀀스 객체
- 이터레이터 생성
class 이터레이터이름:
def __iter__(self):
코드
def __next__(self): # 조건에 따라 숫자를 만들거나 StopIteration 예외를 발생시킴
코드
def __getitem__(self, 인덱스):
# 인덱스로 접근할 수 있는 이터레이터 생성
# 이것만 구현해도 이터레이터 됨. iter, next 생략 가능
코드+) 이터레이터는 언패킹이 가능하다. map 또한 이터레이터
2) 제너레이터
- 의미
이터레이터를 생성해주는 함수 - 생성
yield를 사용 - 이터레이터와 차이점
| 이터레이터 | 제너레이터 | |
|---|---|---|
__next__ 반환값 | __next__ 메소드 안에서 직접 return으로 값을 반환 | yield에 지정한 값이 __next__메소드의 반환값 |
| StopIteration | raise로 직접 발생시킴 | 자동으로 발생 |
-
for문에서 제너레이터
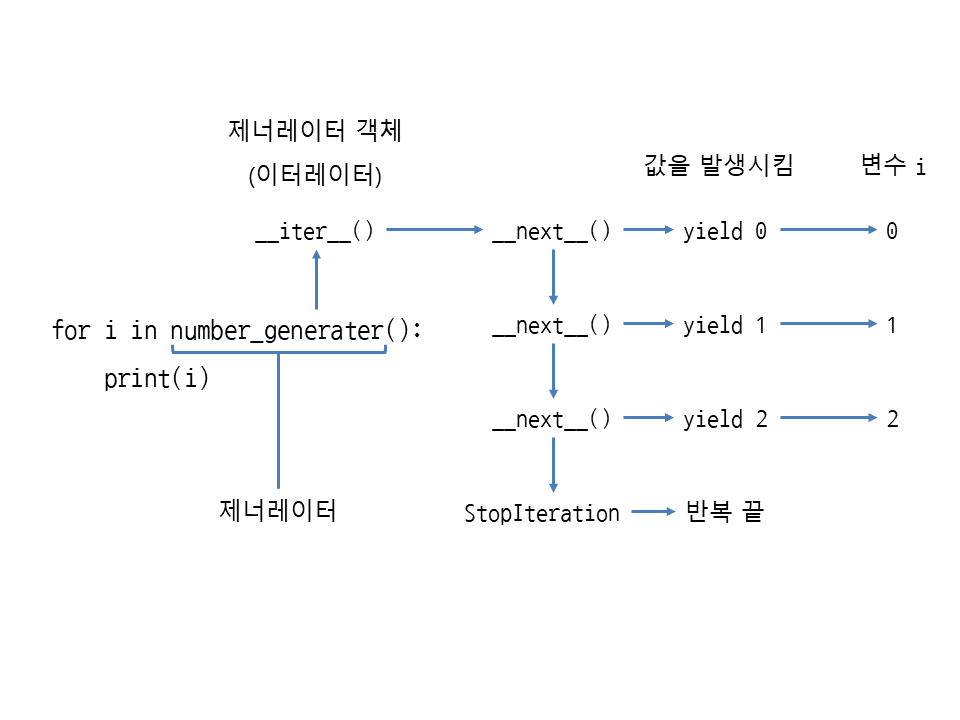
-
yield 양보 원리 ✔✔✔🤔
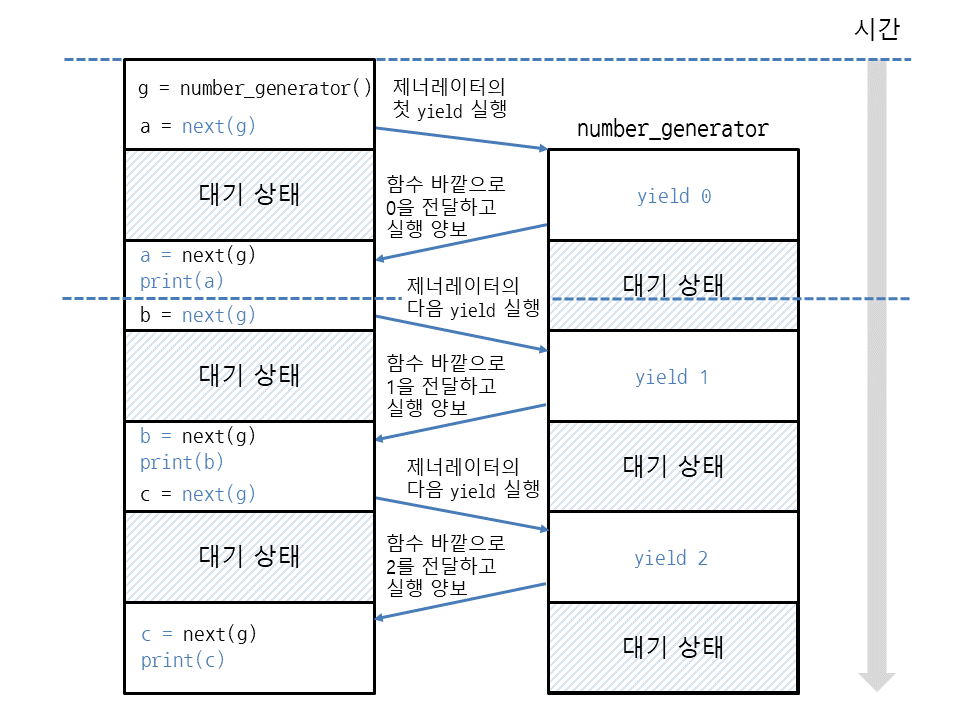
yield에 무엇을 지정하든 결과만 바깥으로 전달 -
yield from
- from 뒤에 반복 가능한 객체를 지정, 여러 번 실행 가능
2. 머신러닝 개념 정리
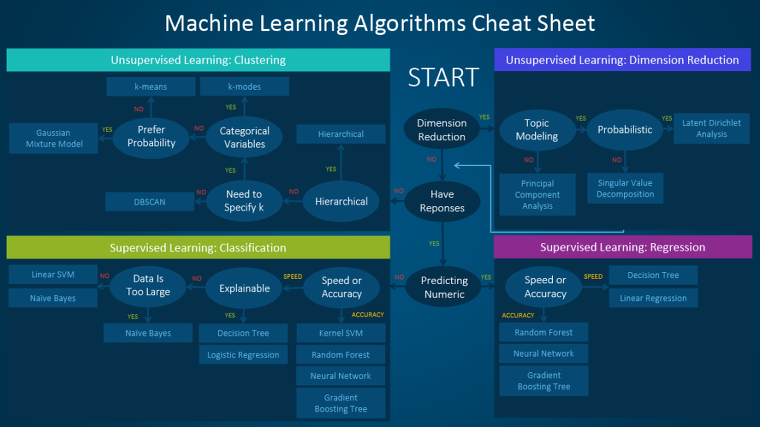
1) 지도학습, 비지도 학습
라벨이 있으면 지도 학습, 없으면 비지도 학습
| 지도학습 | 비지도 학습 | |
|---|---|---|
| 특징 | - 사례를 기반으로 예측을 수행함 - 훈련하기 위한 데이터와 정답이 필요 - 입력 변수와 출력변수를 매핑시키는 함수를 찾음 | - 타깃 없이 입력 데이터(미분류 데이터)만 사용 - 정답을 사용하지 않음, 알아서 분류 |
| 필요한 데이터 | training data: input(feature) + target | input data |
| 종류 | ✔ 분류 - 범주형 변수를 예측하기 위해 데이터를 사용할 때 - 특정 데이터에 레이블 또는 지표를 할당하는 경우 → 이진 분류, 다중 클래스 분류 - 회귀 연속 값을 예측할 때 ✔ 예측 - 과거, 현재 데이터 기반으로 미래 예측 - 동향을 분석하기 위해 사용 | ✔ 클러스터링 - 특정 기준에 따라 유사한 데이터 사례를 하나의 세트로 그룹화 ✔ 차원 축소 - 변수의 개수를 줄이는 과정 |
| 예시 | 과거 매출 이력을 이용해 미래 가격 추산 | 데이터의 기저를 이루는 고유 패턴을 발견하도록 함 |
알고리즘 선택시 고려 사항
- 정확성
- 학습성
- 사용 편의성
2) 강화학습
지도학습, 비지도학습과는 다른 종류의 알고리즘
1. 방식
- 환경에서 오는 피드백을 기반으로 행위자(target)의 행동을 분석, 최적화
- 기계는 최고의 보상을 산출하는 방향으로 다양한 시나리오를 시도
2. 기본 용어
- 에이전트(Agent): 학습 주체 (혹은 actor, controller)
- 환경(Environment): 에이전트에게 주어진 환경, 상황, 조건
- 행동(Action): 환경으로부터 주어진 정보를 바탕으로 에이전트가 판단한 행동
- 보상(Reward): 행동에 대한 보상을 머신러닝 엔지니어가 설계
3. 대표적인 알고리즘
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
3) Scikit-learn (사이킷런)
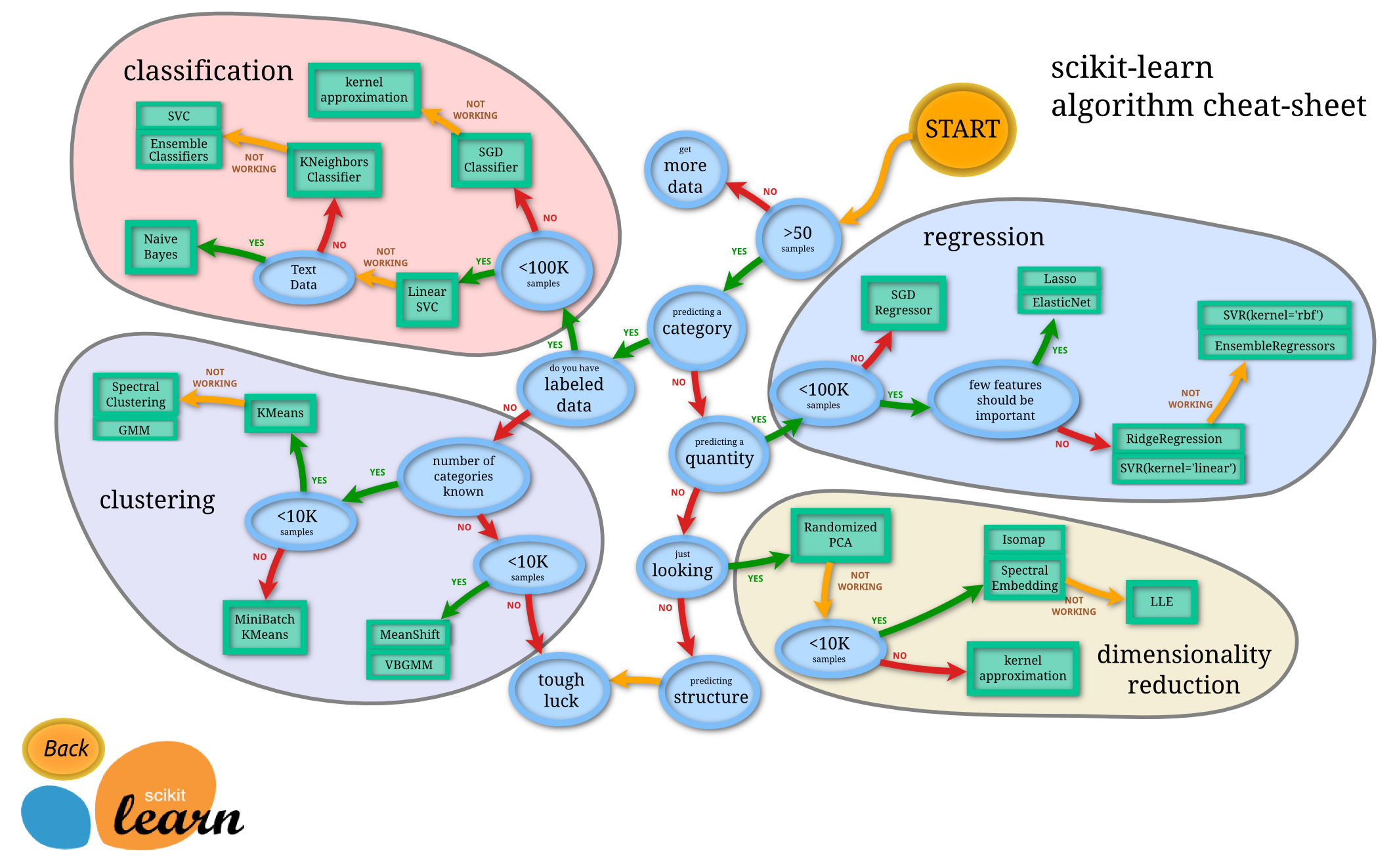
-
사이킷런의 알고리즘은 파이썬 클래스로 구현
-
데이터셋은 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 이용해 나타낼 수 있음
-
주된 API

-
데이터 표현법
출처
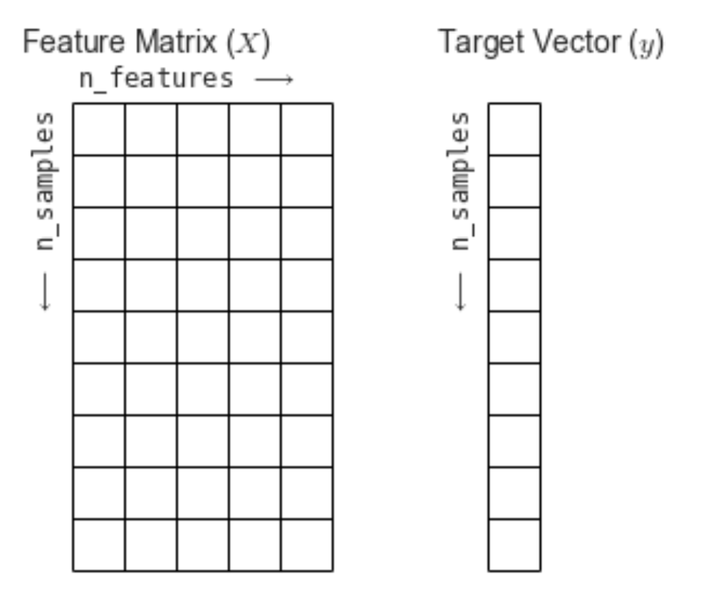
| 특성 행렬 | 타겟 벡터 | |
|---|---|---|
| 의미 | 입력 데이터 | 입력 데이터의 정답 |
| 행 | sample | 라벨의 수 |
| 열 | feature | - |
| 변수 | X | y |
4) Estimator 객체
- 데이터셋을 기반으로 머신러닝 모델의 파라미터를 추정하는 객체
- scikit learn을 이용해 모델을 생성하면 됨
- 비지도학습, 지도학습에 관계없이 학습과 예측을 할 수 있음
3. 회고
yield는 정말,, 모르겠다 함수 밖으로 양보한다는 표현이 잘 와닿지 않는다. 지금 당장 이해는 못할 거 같고 나중에 다시 봐야할 거 같다.
사이킷런 배우면서 지도학습, 비지도학습 다시 정리하니까 지난 학기에 기계학습을 얼마나.. 얼레벌레 대충 넘기면서 공부했는지 알겠다. 기본적인 분류 기준과 언제 어떤 모델을 쓰는게 일반적인지 등 기반을 알아둬야 응용도 된다는 걸 다시 한 번 깨달았다..

🐬 파이썬 / 인공지능 / 머신러닝