
들어가기
c++를 사용하여 opencv를 통해 Histogram Stretching, Histogram Equalization, Histogram Matching을 구현하고 작성한 보고서를 포스팅했다.
참고
삽입된 히스토그램은 python을 사용하여 분산도로 나타낸 그림이다.
헤더 파일은 메인에서 불려올 때 연관 함수를 설명했다. 따로 목차를 추가해 설명하진 않았다.
hist_func.h
#pragma once
#include <opencv2/opencv.hpp>
#include <stdio.h>
#define L 256 // # of intensity levels
#define IM_TYPE CV_8UC3
using namespace cv;
// Image Type
// "G" for GrayScale Image, "C" for Color Image
#if (IM_TYPE == CV_8UC3)
typedef uchar G;
typedef cv::Vec3b C;
#elif (IM_TYPE == CV_16SC3)
typedef short G;
typedef Vec3s C;
#elif (IM_TYPE == CV_32SC3)
typedef int G;
typedef Vec3i C;
#elif (IM_TYPE == CV_32FC3)
typedef float G;
typedef Vec3f C;
#elif (IM_TYPE == CV_64FC3)
typedef double G;
typedef Vec3d C;
#endif
// generate PDF for single channel image
float *cal_PDF(Mat &input) {
int count[L] = { 0 };
float *PDF = (float*)calloc(L, sizeof(float));
// Count
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
count[input.at<G>(i, j)]++;
// Compute PDF
for (int i = 0; i < L; i++)
PDF[i] = (float)count[i] / (float)(input.rows * input.cols);
return PDF;
}
// generate PDF for color image
float **cal_PDF_RGB(Mat &input) {
int count[L][3] = { 0 };
float **PDF = (float**)malloc(sizeof(float*) * L);
for (int i = 0; i < L; i++)
PDF[i] = (float*)calloc(3, sizeof(float));
// Count
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++) {
for (int k = 0; k < 3; k++) {
count[input.at<C>(i, j)[k]][k]++;
}
}
// Compute PDF
for (int i = 0; i < L; i++) {
for (int k = 0; k < 3; k++){
PDF[i][k] = (float)count[i][k] / (float)(input.rows * input.cols);
}
}
return PDF;
}
// generate CDF for single channel image
float *cal_CDF(Mat &input) {
int count[L] = { 0 };
float *CDF = (float*)calloc(L, sizeof(float));
// Count
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
count[input.at<G>(i, j)]++;
// Compute CDF
for (int i = 0; i < L; i++) {
CDF[i] = (float)count[i] / (float)(input.rows * input.cols);
if (i != 0)
CDF[i] += CDF[i - 1];
}
return CDF;
}
// generate CDF for color image
float **cal_CDF_RGB(Mat &input) {
int count[L][3] = { 0 };
float **CDF = (float**)malloc(sizeof(float*) * L);
for (int i = 0; i < L; i++)
CDF[i] = (float*)calloc(3, sizeof(float));
// Count
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
for (int k = 0; k < 3; k++)
count[input.at<C>(i, j)[k]][k]++;
// Compute CDF
for (int i = 0; i < L; i++)
for (int k = 0; k < 3; k++) {
CDF[i][k] = (float)count[i][k] / (float)(input.rows * input.cols);
if (i != 0)
CDF[i][k] += CDF[i - 1][k];
}
return CDF;
}ㅤ
Histogram Stretching
hist_stretching.cpp
#include "hist_func.h"
void linear_stretching(Mat &input, Mat &stretched, G *trans_func, G x1, G x2, G y1, G y2);
int main() {
Mat input = imread("input.jpg", CV_LOAD_IMAGE_COLOR);
Mat input_gray;
cvtColor(input, input_gray, CV_RGB2GRAY); // convert RGB to Grayscale
Mat stretched = input_gray.clone();
// PDF or transfer function txt files
FILE *f_PDF;
FILE *f_stretched_PDF;
FILE *f_trans_func_stretch;
fopen_s(&f_PDF, "PDF.txt", "w+");
fopen_s(&f_stretched_PDF, "stretched_PDF.txt", "w+");
fopen_s(&f_trans_func_stretch, "trans_func_stretch.txt", "w+");
G trans_func_stretch[L] = { 0 };
float *PDF = cal_PDF(input_gray);
linear_stretching(input_gray, stretched, trans_func_stretch, 50, 110, 10, 110); // histogram stretching (x1 ~ x2 -> y1 ~ y2)
float *stretched_PDF = cal_PDF(stretched); // stretched PDF
for (int i = 0; i < L; i++) {
// write PDF
fprintf(f_PDF, "%d\t%f\n", i, PDF[i]);
fprintf(f_stretched_PDF, "%d\t%f\n", i, stretched_PDF[i]);
// write transfer functions
fprintf(f_trans_func_stretch, "%d\t%d\n", i, trans_func_stretch[i]);
}
// memory release
free(PDF);
free(stretched_PDF);
fclose(f_PDF);
fclose(f_stretched_PDF);
fclose(f_trans_func_stretch);
////////////////////// Show each image ///////////////////////
namedWindow("Grayscale", WINDOW_AUTOSIZE);
imshow("Grayscale", input_gray);
namedWindow("Stretched", WINDOW_AUTOSIZE);
imshow("Stretched", stretched);
//////////////////////////////////////////////////////////////
waitKey(0);
return 0;
}
// histogram stretching (linear method)
void linear_stretching(Mat &input, Mat &stretched, G *trans_func, G x1, G x2, G y1, G y2) {
float constant = (y2 - y1) / (float)(x2 - x1);
// compute transfer function
for (int i = 0; i < L; i++) {
if (i >= 0 && i <= x1)
trans_func[i] = (G)(y1 / x1 * i);
else if (i > x1 && i <= x2)
trans_func[i] = (G)(constant * (i - x1) + y1);
else
trans_func[i] = (G)((L - 1 - x2) / (L - 1 - y2) * (i - x2) + y2);
}
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
stretched.at<G>(i, j) = trans_func[input.at<G>(i, j)];
}1. 코드에 대한 설명
1) 개요
hist_stretching.cpp 코드는 input으로 사진을 읽어 RGB와 그레이 형태로 변수에 저장한 후, 그레이 사진을 0에서 255까지 정의된 256개의 intensity 분포 상태를 확률 밀도 함수로 변환하여 PDF에 저장하고, linear stretching을 통해 원본의 PDF의 분산도를 높여 stretched에 저장한 후 txt 파일 형태로 히스토그램을 정의한 함수이다. 코드가 실행되면 PDF.txt, stretched_PDF.txt, trans_func_stretch.txt 파일이 생성된다.
2) 상세
main 함수
trans_func_stretch라는 배열을 0으로 초기화하며 선언하는데, 앞에 붙은 G 자료형은 hist_func.h 헤더 파일에 정의된 자료형이다. 이미지 타입에 따라 uchar, short, int, float, double 형의 흑백 사진은 G로 정의되고 채널이 세 개인 컬러 사진은 C로 정의된다.
linear_stretching을 통해 input_gray를 trans_func_stretch를 통해 stretched로 만들어준다. 자세한 설명은 아래에서 하겠다. 만들어진 stretched 변수를 사용해 stretched_PDF에 PDF 형태로 저장한다.
for문을 통해 PDF.txt, stretch_PDF.txt, trans_func_stretch.txt를 생성하고 할당 받은 동적 메모리를 free 하고 파일 함수를 닫는다.
linear_stretching 함수
linear_stretching 함수의 인자는 Mat &input, Mat &stretched, G *trans_func, G x1, G x2, G y1, G y2가 있다. x1, x2, y1, y2는 각각 자료형 G로 정의된 좌표를 의미한다.
(x1, y1) = (50, 10), (x2, y2) = (110, 110)
위 좌표는 CDF의 개형을 참고해 직선으로 펴줄 때, 기울기가 변하는 부분의 시작과 끝을 의미한다. 좌표를 정하는 건 사용자의 판단에 의한 것이다. 실수형의 constant는 지정한 좌표를 직선으로 잇는 방정식의 기울기다. (y2-y1)/(x2-x1)으로 계산한다.
이어지는 for문으로 transfer function을 만든다. i의 범위는 [0, 256)이다. 만약 i, 즉 x의 값이 x1이하인 구간에서는 transfer function은 원점에서 (x1, y1)을 이은 직선을 따른다. i가 (x1, x2]인 구간에서는 (x1, y1)과 (x2, y2)를 이은 직선의 방정식 (y2-y1)/(x2-x1)(i-x1)+y1를 따른다. i가 x2보다 큰 구간에서는 (x2, y2)과 (L-1, L-1)을 이은 직선의 방정식 (L-1-x2)/(L-1-y2)(i-x2)+y2를 따른다.
if 0≤i≤x1,
trans_func=y1/x1*i
if x1<i≤x2,
trans_func=(y2 - y1)/(x2 - x1)*(i- x1)+ y1
if i>x2,
trans_func=((L-1- y2))/((L -1- x2))*(i- x2)+ y2
그리고 아래 중첩 for문에서 각 좌표에 transfer function을 적용해 intensity를 조정한 결과를 stretched 행렬에 저장한다.
2. 실험 결과 및 분석
1) 사진
 색의 대비가 강해져 검은색은 더 검게, 흰색은 더 하얗게 변한 것을 관찰할 수 있다. 이 경우 사진의 디테일이 지워지는 현상을 확인할 수 있다.
색의 대비가 강해져 검은색은 더 검게, 흰색은 더 하얗게 변한 것을 관찰할 수 있다. 이 경우 사진의 디테일이 지워지는 현상을 확인할 수 있다.
2) PDF, Stretched PDF 히스토그램
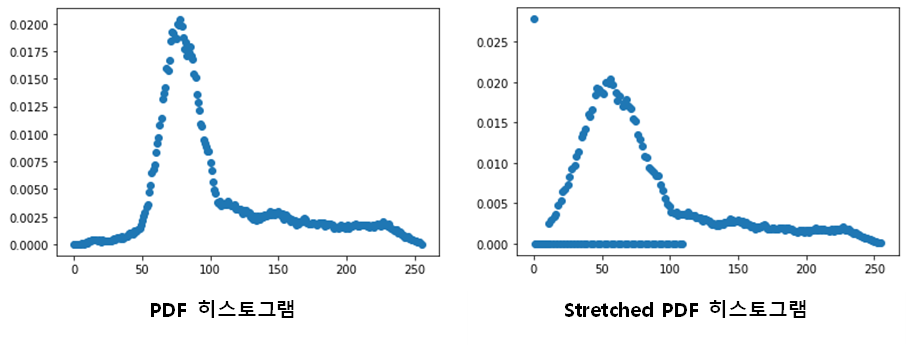 둘을 비교하면, 분산도가 많이 완화되었음을 알 수 있다. 최댓값의 높이도 다르고, 분포 구간이 조정되었으며 분산이 낮아졌다.
둘을 비교하면, 분산도가 많이 완화되었음을 알 수 있다. 최댓값의 높이도 다르고, 분포 구간이 조정되었으며 분산이 낮아졌다.
3) Transfer Function 히스토그램
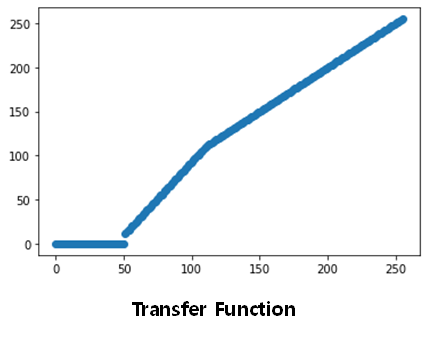 50부터 110까지의 기울기를 조정해 linear stretching에 사용하는 transfer function을 만든다.
50부터 110까지의 기울기를 조정해 linear stretching에 사용하는 transfer function을 만든다.
ㅤ
Histogram Equalization
hist_eq_YUV.cpp
#include "hist_func.h"
void hist_eq(Mat &input, Mat &equalized, G *trans_func, float *CDF);
int main() {
Mat input = imread("input.jpg", CV_LOAD_IMAGE_COLOR);
Mat equalized_YUV;
cvtColor(input, equalized_YUV, CV_RGB2YUV); // RGB -> YUV
// split each channel(Y, U, V)
Mat channels[3];
split(equalized_YUV, channels);
Mat Y = channels[0]; // U = channels[1], V = channels[2]
// PDF or transfer function txt files
FILE *f_equalized_PDF_YUV, *f_PDF_RGB;
FILE *f_trans_func_eq_YUV;
float **PDF_RGB = cal_PDF_RGB(input); // PDF of Input image(RGB) : [L][3]
float *CDF_YUV = cal_CDF(Y); // CDF of Y channel image
fopen_s(&f_PDF_RGB, "PDF_RGB.txt", "w+");
fopen_s(&f_equalized_PDF_YUV, "equalized_PDF_YUV.txt", "w+");
fopen_s(&f_trans_func_eq_YUV, "trans_func_eq_YUV.txt", "w+");
G trans_func_eq_YUV[L] = { 0 }; // transfer function
// histogram equalization on Y channel
hist_eq(Y, Y, trans_func_eq_YUV, CDF_YUV);
// merge Y, U, V channels
merge(channels, 3, equalized_YUV);
// YUV -> RGB (use "CV_YUV2RGB" flag)
cvtColor(equalized_YUV, equalized_YUV, CV_YUV2RGB);
// equalized PDF (YUV)
float** equalized_PDF_YUV= cal_PDF_RGB(equalized_YUV);
for (int i = 0; i < L; i++) {
// write PDF
fprintf(f_PDF_RGB, "%d\t%f\t%f\t%f\n", i, PDF_RGB[i][0], PDF_RGB[i][1], PDF_RGB[i][2]);
fprintf(f_equalized_PDF_YUV, "%d\t%f\t%f\t%f\n", i, equalized_PDF_YUV[i][0], equalized_PDF_YUV[i][1], equalized_PDF_YUV[i][2]);
// write transfer functions
fprintf(f_trans_func_eq_YUV, "%d\t%d\n", i, trans_func_eq_YUV[i]);
}
// memory release
free(PDF_RGB);
free(CDF_YUV);
fclose(f_PDF_RGB);
fclose(f_equalized_PDF_YUV);
fclose(f_trans_func_eq_YUV);
////////////////////// Show each image ///////////////////////
namedWindow("RGB", WINDOW_AUTOSIZE);
imshow("RGB", input);
namedWindow("Equalized_YUV", WINDOW_AUTOSIZE);
imshow("Equalized_YUV", equalized_YUV);
//////////////////////////////////////////////////////////////
waitKey(0);
return 0;
}
// histogram equalization
void hist_eq(Mat &input, Mat &equalized, G *trans_func, float *CDF) {
// compute transfer function
for (int i = 0; i < L; i++)
trans_func[i] = (G)((L - 1) * CDF[i]);
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
equalized.at<G>(i, j) = trans_func[input.at<G>(i, j)];
}1. 코드에 대한 설명
1) 개요
hist_eq_YUV.cpp 코드는 input으로 사진을 읽어 RGB와 YUV 형태로 변수에 저장한 후, Y 채널의 0에서 255까지 정의된 intensity 분포 상태를 확률 밀도 함수로 변환하여 PDF에 저장하고, equalization을 통해 원본의 Y PDF의 분산도를 높여 equalized_YUV에 저장한 후 txt 파일 형태로 히스토그램을 정의한 함수이다. 코드가 실행되면 PDF_RGB.txt, equalized_PDF_YUV.txt, trans_func_eq_YUV.txt 파일이 생성된다.
2) 상세
메인 함수의 골자는 I. Histogram Equalization의 상세 설명과 거의 비슷하다. Histogram Equalization의 메인 함수에서 Y 채널만 분리해 transfer funtion으로 equalization 하고 Y 채널을 YUV에 합친 후 RGB로 변환하여 만든 것이므로 transfer function 정의와 적용은 동일하다. 중복 설명은 생략한다.
channel 분리 후 합치기
우선 equalized_YUV에 input을 RGB에서 YUV로 타입 변환하여 저장한다. cvtColor을 사용하면, 첫 번째 인자에 변환할 입력 변수, 두 번째 인자에 결과를 저장할 출력 변수, 세 번째 인자에 형 변환 타입을 넣어 컬러 타입을 변환할 수 있다.
그리고 길이가 3인 배열 channels를 만들어 split 함수를 통해 equalized_YUV 저장된 YUV 형태의 이미지 Mat을 세 개의 채널로 분리한다. split을 사용하면, 첫 번째 인자에 분리할 입력 변수, 두 번째 인자에 결과를 저장할 출력 변수를 넣어 배열을 분리할 수 있다. split 함수는 opencv 헤더에 내장된 함수 같다. 별도로 채널을 인식해 분리하는 메커니즘이 있는 듯하다. Mat 변수 Y에 channel[0]을 저장한다. 0, 1, 2 인덱스 순서로 Y, U, V다. 만약 RGB를 분리했다면 0, 1, 2 순서로 R, G, B다. Y는 channel[0]을 가리키는 포인터 변수로, Y가 변하면 channel도 같이 변한다. 배열은 기본적으로 포인터 변수이므로 따로 포인터 선언을 할 필요가 없다.
PDF_RGB에 cal_PDF_RGB를 통해 input의 RGB PDF를 저장한다. CDF_YUV에 cal_CDF를 통해 input의 Y 채널의 CDF를 저장한다.
hist_eq를 호출할 때, 전달하는 입력과 출력 Mat 배열 모두 Y다. input의 Y를 equalize하는 transfer function은 trans_func_eq_YUV이고, CDF_YUV, 즉 input이 Y 채널의 CDF 정보를 받아 transfer한다.
그리고 merge 함수로 channels의 3열을 다시 합쳐 equalized_YUV에 저장한다.
cvtColor을 통해 equalized_YUV에 RGB 타입으로 변환된 자신의 정보를 저장한다. CV_RGB2YUV는 RGB에서 YUV를 뜻하고, CV_YUV2RGB는 YUV에서 RGB를 뜻한다.
새로운 이중 포인터 변수 equalized_PDF_YUV를 선언하고 cal_PDF_RGB 함수를 통해 equalized_YUV를 PDF로 변환하여 equalized_PDF_YUV에 저장한다. hist_eq_RGB.cpp와 다르게 transfer function은 1개다. Y 채널 하나로만 equalization을 진행했기 때문이다.
2. 실험 결과 및 분석
1) 사진
 RGB의 correlation을 고려하여, YUV로 전환하고 UV와 correlation이 0인 Y 채널의 밝기 정보로 equalization을 진행하여 선명한 이미지를 얻을 수 있었다. 하지만 이미지 디테일이 일부 손실된 것으로 보인다. 여우의 미간의 털 묘사 디테일이 흐릿해져 washing-out 현상을 관찰 가능하다.
RGB의 correlation을 고려하여, YUV로 전환하고 UV와 correlation이 0인 Y 채널의 밝기 정보로 equalization을 진행하여 선명한 이미지를 얻을 수 있었다. 하지만 이미지 디테일이 일부 손실된 것으로 보인다. 여우의 미간의 털 묘사 디테일이 흐릿해져 washing-out 현상을 관찰 가능하다.
2) Original RGB PDF 히스토그램
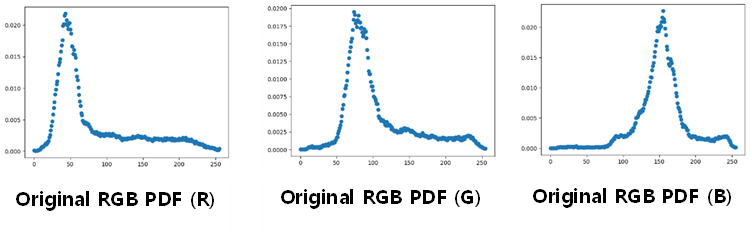
3) Equalized (YUV) RGB PDF 히스토그램
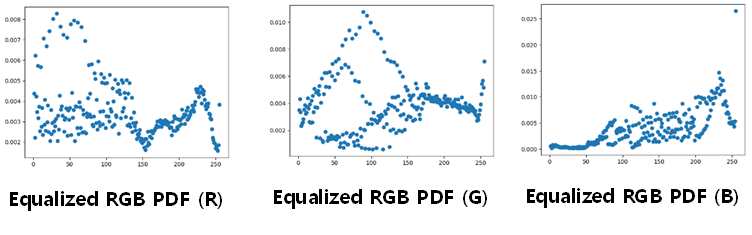 각 채널의 분산도가 원본에 비해 높아졌다.
각 채널의 분산도가 원본에 비해 높아졌다.
RGB Equalization과 Y Equalization의 비교
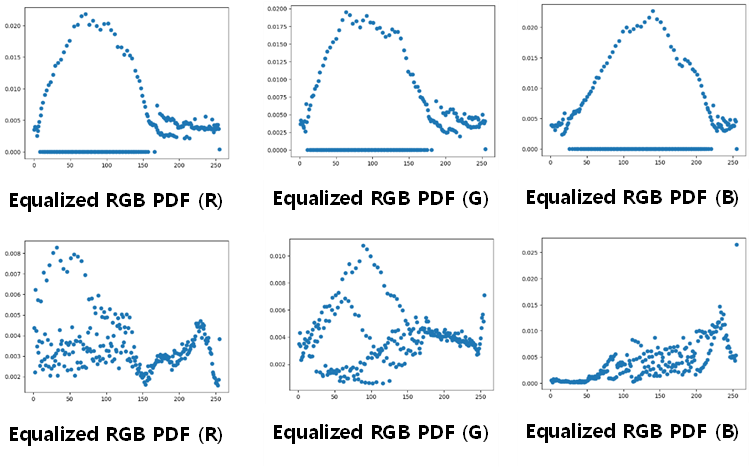
각각 Equalization 한쪽은 세 채널 모두 비슷한 개형을 보이지만, Y Equalization을 진행한 쪽은 개형이 다르다. 특히 B 채널의 변화를 관찰할 수 있다.
4) Transfer Function Equation 히스토그램
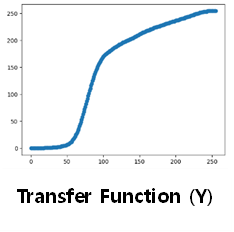
ㅤ
Histogram Matching - Gray Scale
hist_me_gray.cpp
#include "hist_func.h"
#include <iostream>
void hist_eq(Mat& input, Mat& equalized, G* trans_func, float* CDF);
void hist_me(Mat& input, Mat& matched, G* trans_func, G* trans_func_ref_eq);
int main() {
Mat input = imread("input.jpg", CV_LOAD_IMAGE_COLOR);
Mat ref_input = imread("input_ref.jpg", CV_LOAD_IMAGE_COLOR);
Mat input_gray, ref_input_gray;
// convert RGB to Grayscale
cvtColor(input, input_gray, CV_RGB2GRAY);
cvtColor(ref_input, ref_input_gray, CV_RGB2GRAY);
Mat equalized = input_gray.clone();
Mat ref_equalized = ref_input_gray.clone();
Mat matched = input_gray.clone();
// PDF or transfer function txt files
FILE* f_PDF;
FILE* f_matched_PDF_gray;
FILE* f_trans_func_me;
fopen_s(&f_PDF, "PDF.txt", "w+");
fopen_s(&f_matched_PDF_gray, "matched_PDF_gray.txt", "w+");
fopen_s(&f_trans_func_me, "trans_func_me.txt", "w+");
float* PDF = cal_PDF(input_gray); // PDF of Input image(Grayscale) : [L]
float* CDF = cal_CDF(input_gray); // CDF of Input image(Grayscale) : [L]
float* ref_CDF = cal_CDF(ref_input_gray); // CDF of reference image(Grayscale) : [L]
G trans_func_eq[L] = { 0 }; // transfer function (equation)
G trans_func_ref_eq[L] = { 0 }; // transfer function (reference equation)
G trans_func_me[L] = { 0 }; // transfer function (matching)
// histogram equalization on original image
hist_eq(input_gray, equalized, trans_func_eq, CDF); // histogram equalization on grayscale image
float* equalized_PDF_gray = cal_PDF(equalized); // equalized PDF (grayscale)
float* equalized_CDF_gray = cal_CDF(equalized); // equalized CDF (grayscale)
// histogram equalization on reference image
hist_eq(ref_input_gray, ref_equalized, trans_func_ref_eq, ref_CDF); // histogram equalization on grayscale reference image
float* ref_equalized_PDF_gray = cal_PDF(ref_equalized); // reference equalized PDF (grayscale)
float* ref_equalized_CDF_gray = cal_CDF(ref_equalized); // reference equalized CDF (grayscale)
// histogram matching on original image
hist_me(equalized, matched, trans_func_me, trans_func_ref_eq);
float* matched_PDF_gray = cal_PDF(matched);
for (int i = 0; i < L; i++) {
// write PDF
fprintf(f_PDF, "%d\t%f\n", i, PDF[i]);
fprintf(f_matched_PDF_gray, "%d\t%f\n", i, matched_PDF_gray[i]);
// write transfer functions
fprintf(f_trans_func_me, "%d\t%d\n", i, trans_func_me[i]);
}
// memory release
free(PDF);
free(CDF);
fclose(f_PDF);
fclose(f_matched_PDF_gray);
fclose(f_trans_func_me);
////////////////////// Show each image ///////////////////////
namedWindow("Grayscale", WINDOW_AUTOSIZE);
imshow("Grayscale", input_gray);
namedWindow("Reference Grayscale", WINDOW_AUTOSIZE);
imshow("Reference Grayscale", ref_input_gray);
namedWindow("Histogram Matched", WINDOW_AUTOSIZE);
imshow("Histogram Matched", matched);
//////////////////////////////////////////////////////////////
waitKey(0);
return 0;
}
// histogram equalization
void hist_eq(Mat& input, Mat& equalized, G* trans_func, float* CDF) {
// compute transfer function
for (int i = 0; i < L; i++)
trans_func[i] = (G)((L - 1) * CDF[i]);
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
equalized.at<G>(i, j) = trans_func[input.at<G>(i, j)];
}
// histogram matching
void hist_me(Mat& input, Mat& matched, G* trans_func, G* trans_func_ref_eq) {
// compute transfer function
int one = L - 2;
int two = L - 1;
while (one >= 0) {
// inverse mapping
for (int i = trans_func_ref_eq[one]; i <= trans_func_ref_eq[two]; i++) {
trans_func[i] = two;
}
two = one--;
}
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
matched.at<G>(i, j) = trans_func[(input.at<G>(i, j))];
}1. 코드에 대한 설명
1) 개요
histme_gray.cpp 코드는 input과 ref_input으로 사진들을 읽어 RGB와 그레이 형태로 각 변수에 저장한 후, 각 그레이 사진을 0에서 255까지 정의된 256개의 intensity 분포 상태를 확률 밀도 함수로 변환하여 각 PDF에 저장하고, equalization을 통해 원본과 참조 이미지의 PDF의 분산도를 높여 equalized, ref equalized에 저장한 후 matching을 진행해 원본의 분산도를 참조 이미지와 비슷하게 만들어 matched에 저장해 txt 파일 형태로 히스토그램을 정의한 함수이다. 코드가 실행되면 PDF.txt, matched_PDF_gray.txt, trans_func_me.txt 파일이 생성된다.
2) 상세
main
ref_input에 imread 함수로 input_ref.jpg라는 이미지를 컬러로 읽었다. input_ref.jpg는 구글링해서 찾은 사막여우 사진으로, 색감과 물체가 비슷한 분위기라 참조 사진으로 적합해 보여 선정했다.
Mat 변수 ref_input gray를 선언하고 cvtColor 함수를 통해 RGB에서 Gray로 바뀐 배열을 변수에 저장했다.
Mat 변수 ref_equalized에 ref_input_gray와 같은 배열을 clone 함수를 통해 복사해 같은 크기를 할당했다. 또한 Mat 변수 matched에 input_gray와 같은 배열을 clone 함수를 통해 복사해 같은 크기를 할당했다. ref_equalized와 matched의 크기는 서로 다르므로 유의해야 한다.
필요한 정보는 f_PDF, f_matched_PDF_gray, f_trans_func_me므로 FILE 태그를 사용해 파일을 선언하고, fopen_s 함수를 사용해 각 변수들의 주소를 생성할 txt 파일과 연결한다. 모드는 파일을 생성할 때 쓰는 w+모드로 선언한다.
float 포인터 변수 선언해 필요한 PDF, CDF 배열을 얻는다. ref_CDF 변수는 참조 이미지를 HE 할 때 필요하므로 선언한다.
G 자료형의 transfer function 정보를 담을 각각의 변수 세 개를 선언한다. input_gray를 HE하는 trans_func_eq, ref_input_gray를 HE하는 trans_func_ref_eq, equalized를 HE하는 trans_func_me. Gray Scale이므로 trans_func들은 일차원 배열이다.
input_gray를 HE한 결과를 equalized에 저장한다. 이때, CDF에 저장된 input_gray의 CDF 정보가 사용된다. transfer function 정보는 trans_func _eq에 저장됐다.
ref_input_gray를 HE한 결과를 ref_equalized에 저장한다. 이때, ref_CDF에 저장된 ref_input_gray의 CDF 정보가 사용된다. transfer function 정보는 trans_func_ref_eq에 저장됐다.
hist_me 함수를 통해 equalized를 ME한 결과를 matched에 저장한다. 이때, CDF에 저장된 trans_func_ref_eq의 정보가 사용된다. transfer function 정보는 trans_func_me에 저장됐다.
float 포인터 변수 matched_PDF_gray에 cal_PDF 함수를 통해 matched의 PDF 정보를 저장한다.
for문 내에서 PDF, matched_PDF_gray, trans_func_me의 정보를 f_PDF, f_matched_PDF_gray, f_trans_func_me에 저장해 txt 파일을 채워넣는다.
그리고 메모리를 release하고 파일 함수를 닫은 후 세 개의 새 창에 Grayscale, Reference Grayscale, Histogram Matched 타이틀에 맞는 각 이미지 input_gray, ref_input_gray, matched를 띄운다.
hist_me 함수
인자는 입력 변수 input, 출력 변수 matched, 출력 변수 trans_func, 입력 변수 trans_func_ref_eq 네 개를 받는다. 구조는 최대한 hist_eq와 유사하게 구성했다. 리턴 값은 hist_eq와 마찬가지로 없다. 구조가 유사한 이유는 ME와 HE의 본질적인 메커니즘이 같기 때문이다. transfer function을 정의하고, transfer function을 적용하는 두 단계로 나뉘어졌다는 공통점이 있다.
1) compute transfer function
ME의 T(r)은 ref_input_gray와 ref_CDF의 상관관계를 반전시킨 역함수다. 그리고 이 정보는 trans_func_eq에 들어 있다. 즉, trans_func_eq의 역함수가 trans_func가 된다. 역함수를 구하는 방법은 다음과 같다.
단조함수의 역함수의 경우, 완벽한 일대일 대응은 되지 않지만 적어도 결과값이 감소하지 않는다는, 단조함수의 특성을 갖고 있다. 함수를 이루기 위해서는 일대일 대응이 되도록 조정해야 하는데, 일대일 대응이 되지 않는 case는 두 가지다. 첫 번째는 trans_func_eq의 한 결과로 모일 때. f(0) = 1, f(1) = 1, f(2) = 1이면 역함수 g(x)를 구할 때 g(1)의 값이 0, 1, 2 중 무엇인지 결정해야 하는 상황이 만들어진다. 이때는 가장 작은 값을 택하도록 알고리즘을 설계했다. 두 번째는 결과값이 1씩 증가하지 않아 연관관계가 없는 결과값도 있을 때, 즉, 역함수의 특정 x값이 mapping되지 않은 상태다. 이를 방지하기 위해 공역을 가장 큰 수부터 1씩 감소하도록 알고리즘을 설계해 특정 x값의 f(x) 결과가 없는 빈틈을 방지했다.
알고리즘 자체는 단순하다. 각각의 입력 인덱스가 될 int형 변수 one, two에 L-2, L-1을 대입한다. HE 함수, 즉 역함수로 만들 함수의 치역의 범위가 [0, 255]이므로 픽셀 개수로 정의된 L을 사용하면 범위를 초과해 L-1로 맞게 설정했다. 그리고 L-1보다 1의 차이로 작은 L-2를 설정해, 치역의 범위를 L-1 미만이도록 설정한다. 일대일 대응을 위한 기본적이 조건이 설정됐다.
one이 0미만이 되면 중지되는 루프문 while 속에서, inverse mapping을 시작한다. trans_func_req[one], 즉 원래 함수의 결과이자 역함수의 입력이 되는 수로 i를 초기화 하고, for문의 조건을 i가 trans_func_ref_eq[two] 미만일 때까지 i를 증가시키는 것으로 한다. 이는, 원래 함수가 조건을 벗어날 경우, 즉, 단조함수가 되지 않으면 단조함수의 상태를 유지시키고 최대한 입력과 출력의 관계를 고르게 분포하기 위한 설정이다. 예를 들어 trans_func_req[one=254]=253이고 trans_func_req[two=255]=255인 초기 상황을 살펴보면, i=253, i<=255이다. trans_func[253]=255가 되고 i=254가 된다. 그리고 다시, i=254고 i=254<=255이므로 trans_func[254]=255가 되며 i=255다. 그리고 다시, i=255>254이므로 for문이 중지되고 one과 two는 각각 253, 254가 되어 다시 253부터 검사할 것이다. 이어진 두 번째 루프를 살벼본다. trans_func_req[one=253]=253이고 trans_func_req[one=254]=253일 때, i=253, i<=253이다. trans_func[253]=254, i=254가 된다. i=254, i>253이므로 루프가 종료된다. 이때, trans_func[253]이 255에서 254로 낮아졌다. 이런 교정 작업을 거쳐 역함수가 완성된다.
2) perform transfer function
hist_eq.cpp와 동일한 구조다. 설명은 생략한다.
2. 실험 결과 및 분석
1) 사진
 원래의 사진은 조금 더 어두웠는데, 참조 사진이 밝은 편이라 ME된 사진도 조금 밝아졌다. 그리고 여우의 수염 자국 디테일 부근이 조금 더 선명해진 것을 확인할 수 있으며, HE를 시행했을 때 강도의 대비의 차이로 washing-out 되는 현상이 없어졌다.
원래의 사진은 조금 더 어두웠는데, 참조 사진이 밝은 편이라 ME된 사진도 조금 밝아졌다. 그리고 여우의 수염 자국 디테일 부근이 조금 더 선명해진 것을 확인할 수 있으며, HE를 시행했을 때 강도의 대비의 차이로 washing-out 되는 현상이 없어졌다.
2) PDF, Matched PDF 히스토그램
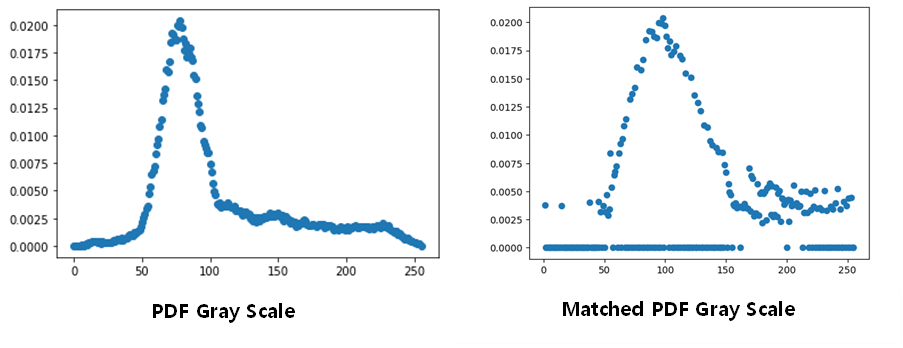 분산도가 높았던 원본에 비해 HM를 거친 완성본은 분포가 고르게 변한 것을 확인할 수 있다.
분산도가 높았던 원본에 비해 HM를 거친 완성본은 분포가 고르게 변한 것을 확인할 수 있다.
비교
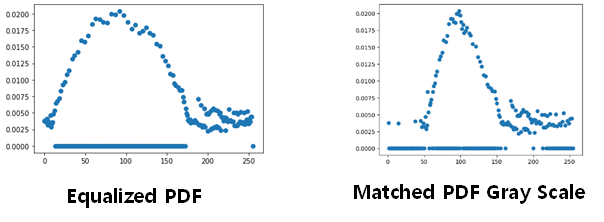 HE가 조금 분산도는 더 낮은 것으로 보인다. 하지만 ME의 분산도도 원본에 비하면 낮을 뿐만 아니라 디테일도 보존되어 사진 선정을 잘하면 ME로 좋은 이미지 조정 효과를 누릴 것이다.
HE가 조금 분산도는 더 낮은 것으로 보인다. 하지만 ME의 분산도도 원본에 비하면 낮을 뿐만 아니라 디테일도 보존되어 사진 선정을 잘하면 ME로 좋은 이미지 조정 효과를 누릴 것이다.
3) Transfer Function Equation 히스토그램
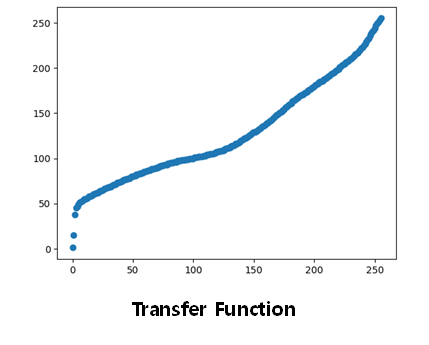 역함수 매핑의 영향으로 S자 개형보다는 선형에 가깝다.
역함수 매핑의 영향으로 S자 개형보다는 선형에 가깝다.
ㅤ
Histogram Matching
hist_me_YUV.cpp
#include "hist_func.h"
#include <iostream>
using namespace cv;
using namespace std;
void hist_eq(Mat& input, Mat& equalized, G* trans_func, float* CDF);
void hist_me(Mat& input, Mat& matched, G* trans_func_ref_eq, G* trans_func);
int main() {
Mat input = imread("input.jpg", CV_LOAD_IMAGE_COLOR);
Mat ref_input = imread("input_ref.jpg", CV_LOAD_IMAGE_COLOR);
Mat equalized_YUV, ref_equalized_YUV;
// convert RGB to YUV
cvtColor(input, equalized_YUV, CV_RGB2YUV);
cvtColor(ref_input, ref_equalized_YUV, CV_RGB2YUV);
Mat matched_YUV = equalized_YUV.clone();
// split each channel(Y, U, V)
Mat channels[3];
split(equalized_YUV, channels);
Mat Y = channels[0];
Mat ref_channels[3];
split(ref_equalized_YUV, ref_channels);
Mat ref_Y = ref_channels[0];
Mat matched_channels[3];
split(matched_YUV, matched_channels);
Mat matched_Y = matched_channels[0];
// PDF or transfer function txt files
FILE* f_PDF_RGB;
FILE* f_matched_PDF_YUV;
FILE* f_trans_func_me_YUV;
float** PDF_RGB = cal_PDF_RGB(input); // PDF of Input image(Grayscale) : [L]
float* CDF_YUV = cal_CDF(Y); // CDF of Input image(Grayscale) : [L]
float* ref_CDF_YUV = cal_CDF(ref_Y); // CDF of reference Input image(Grayscale) : [L]
fopen_s(&f_PDF_RGB, "PDF_RGB.txt", "w+");
fopen_s(&f_matched_PDF_YUV, "matched_PDF_YUV.txt", "w+");
fopen_s(&f_trans_func_me_YUV, "trans_func_me_YUV.txt", "w+");
G trans_func_eq_YUV[L] = { 0 }; // transfer function (equation)
G trans_func_ref_eq_YUV[L] = { 0 }; // transfer function (reference equation)
G trans_func_me_YUV[L] = { 0 }; // transfer function (matching)
// histogram equalization on original image (Y channel)
hist_eq(Y, Y, trans_func_eq_YUV, CDF_YUV);
// histogram equalization on reference image (Y channel)
hist_eq(ref_Y, ref_Y, trans_func_ref_eq_YUV, ref_CDF_YUV);
// histogram matching on original image (Y channel)
hist_me(Y, matched_Y, trans_func_ref_eq_YUV, trans_func_me_YUV);
// merge Y, U, V matched_channels
merge(matched_channels, 3, matched_YUV);
// YUV -> RGB (use "CV_YUV2RGB" flag)
cvtColor(matched_YUV, matched_YUV, CV_YUV2RGB);
// equalized PDF (YUV)
float** matched_PDF_YUV = cal_PDF_RGB(matched_YUV);
for (int i = 0; i < L; i++) {
// write PDF
fprintf(f_PDF_RGB, "%d\t%f\t%f\t%f\n", i, PDF_RGB[i][0], PDF_RGB[i][1], PDF_RGB[i][2]);
fprintf(f_matched_PDF_YUV, "%d\t%f\t%f\t%f\n", i, matched_PDF_YUV[i][0], matched_PDF_YUV[i][1], matched_PDF_YUV[i][2]);
// write transfer functions
fprintf(f_trans_func_me_YUV, "%d\t%d\n", i, trans_func_me_YUV[i]);
}
// memory release
free(PDF_RGB);
free(CDF_YUV);
fclose(f_PDF_RGB);
fclose(f_matched_PDF_YUV);
fclose(f_trans_func_me_YUV);
////////////////////// Show each image ///////////////////////
namedWindow("RGB", WINDOW_AUTOSIZE);
imshow("RGB", input);
namedWindow("Reference RGB", WINDOW_AUTOSIZE);
imshow("Reference RGB", ref_input);
namedWindow("Histogram Matched YUV", WINDOW_AUTOSIZE);
imshow("Histogram Matched YUV", matched_YUV);
//////////////////////////////////////////////////////////////
waitKey(0);
return 0;
}
// histogram equalization
void hist_eq(Mat& input, Mat& equalized, G* trans_func, float* CDF) {
// compute transfer function
for (int i = 0; i < L; i++)
trans_func[i] = (G)((L - 1) * CDF[i]);
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
equalized.at<G>(i, j) = trans_func[input.at<G>(i, j)];
}
// histogram matching
void hist_me(Mat& input, Mat& matched, G* trans_func_ref_eq, G* trans_func) {
// compute transfer function
int one = L - 2;
int two = L - 1;
while (one >= 0) {
// inverse mapping
for (int i = trans_func_ref_eq[one]; i <= trans_func_ref_eq[two]; i++) {
trans_func[i] = two;
}
two = one--;
}
// perform the transfer function
for (int i = 0; i < input.rows; i++)
for (int j = 0; j < input.cols; j++)
matched.at<G>(i, j) = trans_func[(input.at<G>(i, j))];
}1. 코드에 대한 설명
1) 개요
histme_YUV.cpp 코드는 input과 ref_input으로 사진들을 읽어 RGB와 YUV 형태로 각 변수에 저장한 후, 각 Y 채널의 0에서 255까지 정의된 256개의 intensity 분포 상태를 확률 밀도 함수로 변환하여 각 PDF에 저장하고, equalization을 통해 원본과 참조 이미지의 Y PDF의 분산도를 높여 equalized_YUV, ref equalized_YUV에 저장한 후 matching을 진행해 원본의 Y 분산도를 참조 이미지와 비슷하게 만들어 matched_YUV에 저장해 txt 파일 형태로 히스토그램을 정의한 함수이다. 코드가 실행되면 PDF_RGB.txt, matched_PDF_YUV.txt, trans_func_me_YUV.txt 파일이 생성된다.
2) 상세
기본적인 코드의 구조는 hist_eq_YUV.cpp와 hist_me_gray.cpp를 따라간다. 두 코드를 조합하는 과정이었으므로, 차이점을 위주로 설명하겠다.
main 함수
기존에 더해 input뿐만 아니라 refinput도 cvtColor을 통해 YUV로 변환되어 각각 equalized_YUV, ref equalized_YUV에 저장된다. 그리고 channel뿐 아니라 ref_channel, matched_channel 모두 선언하여 split한 Y 정보를 Y, ref_Y, matched_Y 변수에 저장한다는 차이점이 있다.
PDF_RGB는 히스토그램 출력을 위해 선언되고, 이때는 RGB이므로 이중 포인터 변수다. 나머지는 CDF로 Y와 ref_Y를 변환하여 포인터 변수에 저장한다.
transfer function은 세 개 필요하다. trans_func_eq_YUV, trans_func_ref_eq_YUV, trans_func_me_YUV. 앞의 두 개는 HE 함수를 담을 것이고 뒤의 한 개는 ME 함수를 담을 것이다.
hist_eq를 Y, ref_Y에 진행한다. 각 CDF 정보를 사용해 trans_func를 만들어 결과를 자기 자신에 저장한다. 그리고 hist_me를 실행하는데, 입력은 Y, 출력은 matched_Y로 진행한다.
matched_YUV의 YUV 정보를 합쳐 matched_YUV를 완성하고 RGB로 바꾼 정보를 다시 자신에게 저장한다.
파일을 쓸 때, PDF_RGB와 matched_PDF_YUV는 RGB 정보이므로 인덱스는 픽셀과 R 강도, G 강도, B 강도 네 개이며 tans_func_me는 Y 채널을 ME한 일차원 배열이므로 인덱스는 픽셀과 Y 강도 두 개다.
2. 실험 결과 및 분석
1) 사진

참조 이미지를 gray에 사용한 같은 사막여우로 했다. 참조 쪽이 밝고 채도가 높은 편이라 결과물도 밝고 색감이 있는 느낌으로 매핑되었다. 수염의 디테일이 밝아지면서 더 선명해졌다. 또한 배경의 무늬의 디테일도 조금 더 선명해졌다.
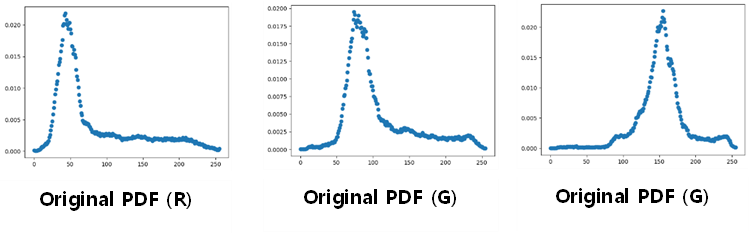
2) Original PDF 히스토그램
3) Matched (YUV) RGB PDF 히스토그램
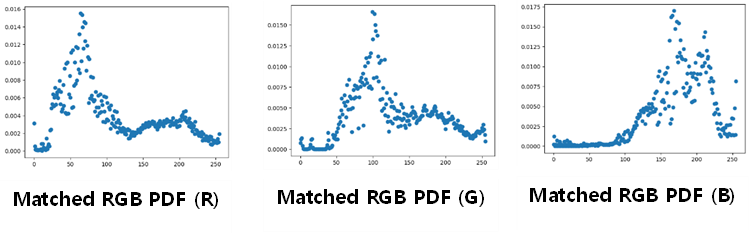 개형이 조금 특이하다. 참조 이미지의 영향으로 분산되면서 연속성을 잃어버린 듯하다.
개형이 조금 특이하다. 참조 이미지의 영향으로 분산되면서 연속성을 잃어버린 듯하다.
4) Transfer Function Equation 히스토그램
 선형에 가까운 개형으로, 역함수 매핑 과정의 영향을 받은 듯하다.
선형에 가까운 개형으로, 역함수 매핑 과정의 영향을 받은 듯하다.
ㅤ
나가기
Histogram Equalization과 Matching을 각각의 Transfer Function을 정의하여 적용하는 방식으로 구조화하는 작업이 즐거웠다. 온라인에서 H.E와 M.E를 검색할 때 단순히 opencv의 툴을 사용하거나 c++ 코드를 단순히 정의하여 사용하는 경우가 많아서 보고서를 작성할 때 애먹었는데, 이 포스팅으로 T(r)을 사용하는 방식을 구조화할 수 있다면 기분 좋을 것 같다.
ㅤ
