지난 4월 초에 시작해서 4월 21일 마무리 했던 경진대회를 이제서야 정리를 해보려 한다.
그때는 코랩에 작성한 코드만 정리되어 있음 좋겠다 생각했지만 글로써 정리를 하면 더 좋을거 같아 미루고 미루다 이제 시작해 보려한다.

시작
저번 GPT경진대회에 같이 참가 했던 조원이 내가 산업공학과를 전공했던것을 기억했어서 같이 참여하면 좋을것 같다 추천해주어 시작하게 되었다. 처음 대회에 써 있던 내용은 '산업기기 피로도 예측'이라는 주제로 되어있어 대학에서 배웠던 지식들을 토대로 데이터에 접근하여 이와 관련한 모델들을 찾아보며 모델링을 해나가고자 했다.

대회 주제는 비지도 학습을 통한 이상탐지 였다. 비지도 학습은 처음 접해본 내용이라 이번기회에 팀원들과 공부해보면 좋겠다 생각들었다.
Unsupervised learning Anomaly detection
대회 주제 소개
■ 범천(주)은 ESG 가치를 담아 산업용 공기압축기를 개발하는 대덕연구개발특구 소재 기업입니다.제4회 연구개발특구 AI SPARK 챌린지는 산업기기 피로도를 예측하는 문제입니다.
산업용 공기압축기 및 회전기기에서 모터 및 심부 온도, 진동, 노이즈 등은 기기 피로도에 영향을 주는 요소이며, 피로도 증가는 장비가 고장에 이르는 원인이 됩니다.
피로도 증가 시 데이터 학습을 통해 산업기기 이상 전조증상을 예측하여 기기 고장을 예방하고 그로 인한 사고를 예방하는 모델을 개발하는 것이 이번 대회의 목표입니다.
데이터
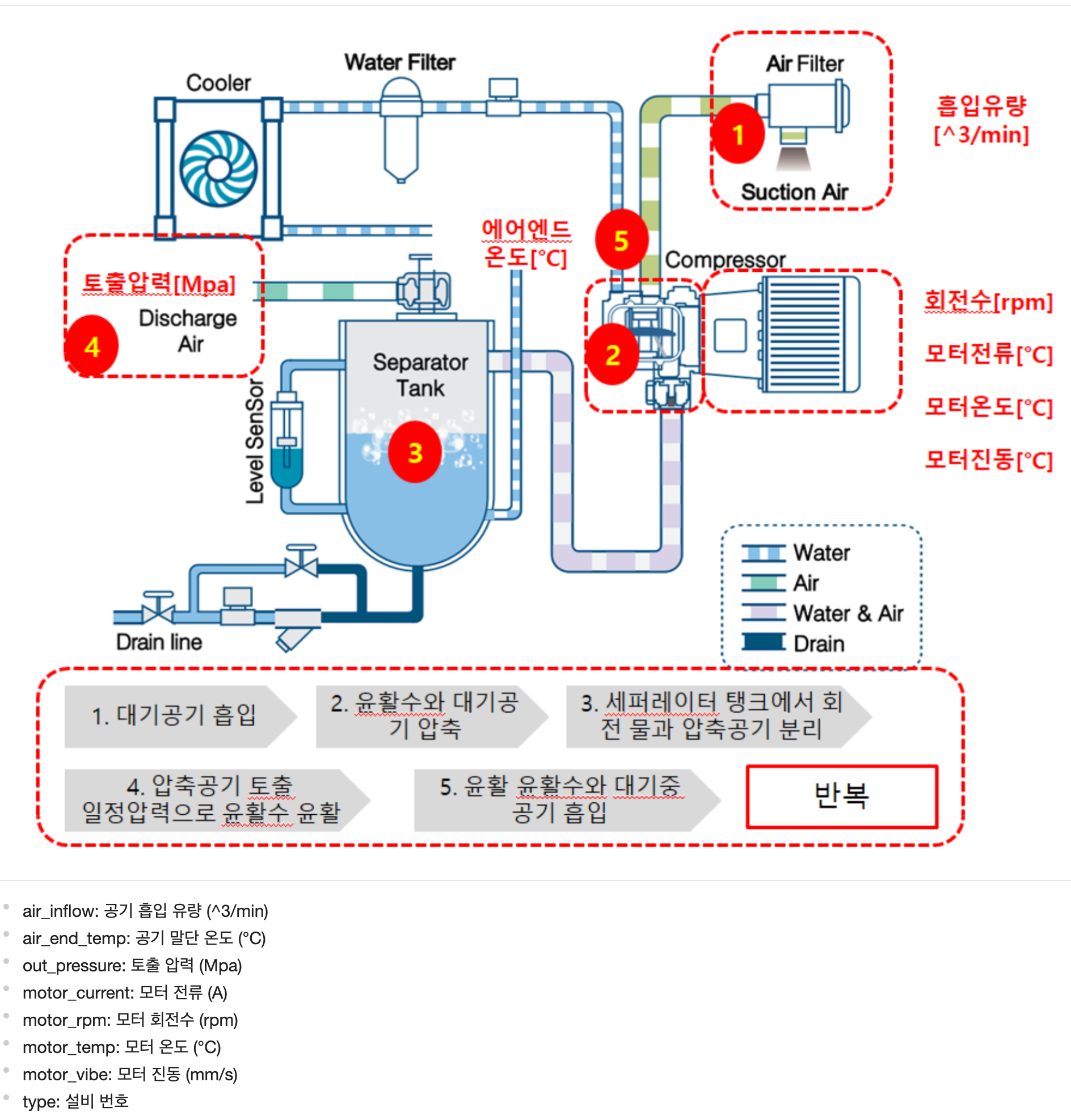
데이터들은 설비의 다음과 같은 Feature들을 포함하고 있다.
Train Data
train_data: 학습용 데이터로 모두 정상 case로 이루어진 데이터입니다.
학습데이터는 모두 정상인 데이터들로만 구성이 되어있고 장비별로 데이터들의 추세를 확인해 큰 틀을 잡아가 보자 했다.
먼저 ydata_profiling을 사용하여 autoeda를 해보았다.

많은 데이터들이 서로 높은 상관관계를 가지고 있었고 직접 그래프로 데이터를 찍어보고 확인하자 했다. (0~7까지 설비가 존재하고 각 설비는 연속적으로 이어져있다.)
- 정규화 전의 데이터
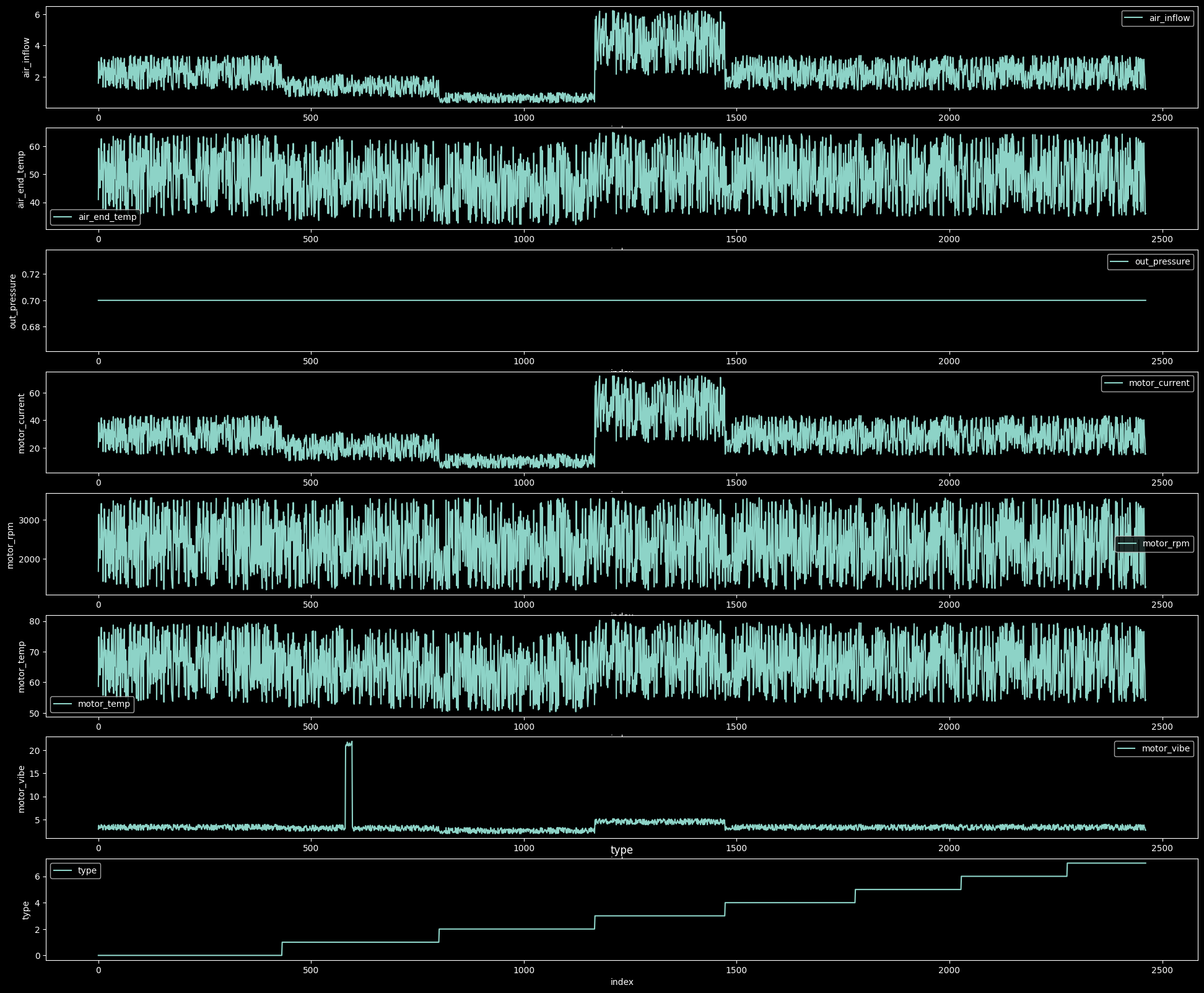
Q&A에서 말하길 설비별로 시간 순차적으로 이어져있지만 등간겨은 아니고 30초정도 오차는 날 수 있다 설며 되었다.
따라서 데이터를 시계열 데이터 관점에서 생각하고자 했다.
motor_vibe(type1)구간에서 특정 값이 이상치처럼 보이는 경우가 있었지만 대회측에서 Train Data는 모두 정상데이터라 했기 때문에 별 의심없이 진행하였다. (하지만 결국 이 데이터가 대회의 결과에서 큰 변화를 만들었고 큰 논란이 되었다.)
- 정규화 후 데이터 (Type1)
대부분의 Featrue가 비슷한 추세선을 만들며 이동하고 있지만 특정 부분에서 이상치처럼 보이는 경우가 있었다.

Test Data
- 정규화 전의 데이터
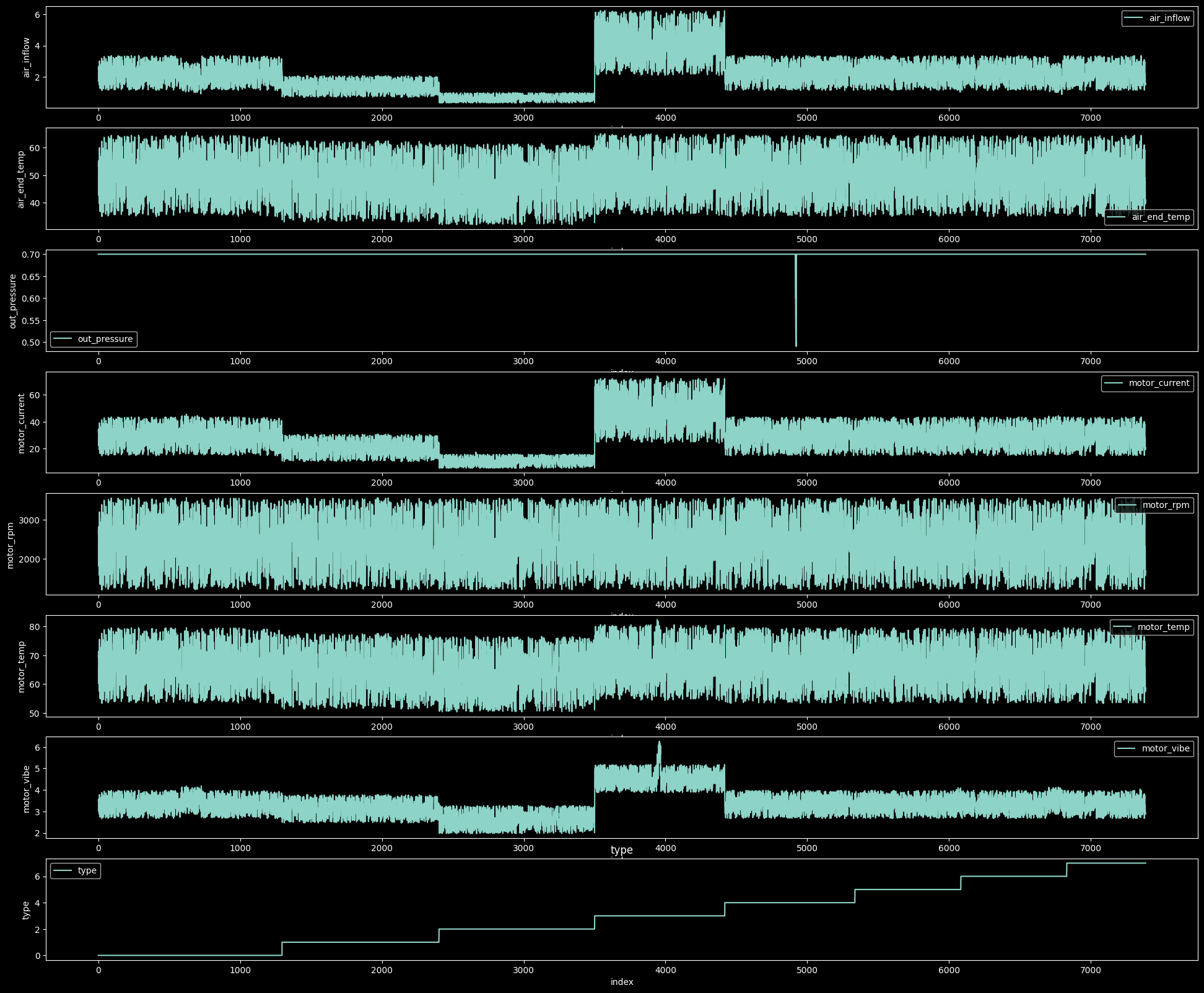
정규화를 진행하지 않고 직관적으로 보았을 때 type4의 out_pressure부분이 급격하게 줄어드는 구간이 있었고, type3의 motorvibe에서 갑자기 솟는 구간이 있어 이상치로 예상이 되었다.
- 정규화 이후의 데이터( 새탭에서 이미지를 열어보면 자세히 볼 수 있다.)





일부 부분에서 추세선과 일치하지 못하고 값들이 불안정한 모습을 보이는 구간을 찾을 수 있었다.
다양한 모델들을 찾아보면서 우리가 학습시킨 모델이 위 불안정한 데이터들을 이상치로 판단하는지 확인하면서 대회를 진행하고자 했다.
팀에서 각자 eda를 조금더 해볼 팀원과, 다양한 Feature를 만들 팀원, 모델을 찾아볼 팀원 이렇게 나누어 진행 하였고 나는 다양한 모델을 찾아 팀원들과 공유해보기로 하였다.
macro F1-Score
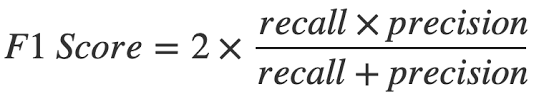
대회에서 평가 지표로는 macro F1-Score을 사용하였다.
F1 = 2 (정밀도 재현율) / (정밀도 + 재현율)
정밀도는 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 비율로 계산된다.
정밀도는 "모델이 양성으로 예측한 것 중에서 실제로 양성인 것이 얼마나 있는가"를 나타냅니다.
재현율은 실제로 양성인 샘플 중에서 모델이 양성으로 예측한 샘플의 비율로 계산됩니다.
재현율은 "실제로 양성인 것 중에서 모델이 얼마나 양성으로 예측할 수 있는가"를 나타냅니다.
F1-Score는 정밀도와 재현율의 조화평균값을 사용하여 두 값이 모두 높을때 좋은 결과를 얻을 수 있다.
Model
다양한 모델을 찾으며 삽질도 많이 하고 작동했지만 성능이 영 좋지 못했던 모델들도 많았었다.
그래도 그 중에서 두가지 정도 소개하면 좋을 것 같아 Autoencoder모델과 Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection(DAGMM)모델이다.
처음 Autoencoder로 학습을 시켜 결과를 제출해 보았을때 점수가 이전보다 많이 올라 정리해 보고 싶었고, 이와 관련된 모델을 찾다 정규분포를 사용한 Autoencoder 모델이 있어 정리해보면 좋을것 같아 이 두 모델을 정리하고자 한다.
Autoencoder
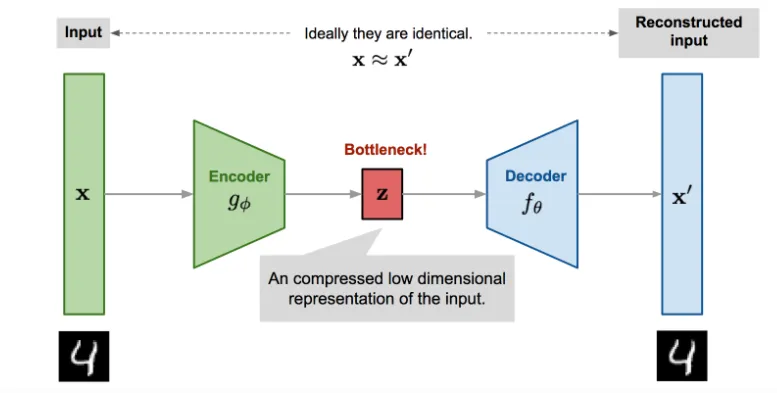
Autoencoder란 입력 데이터를 저차원으로 압축시켜 주요 특징만 추출하여 Bottleneck(intent variable)을 만들고 다시 차원을 확장시켜 입력데이터와 크기가 같은 데이터를 생성하게 된다.
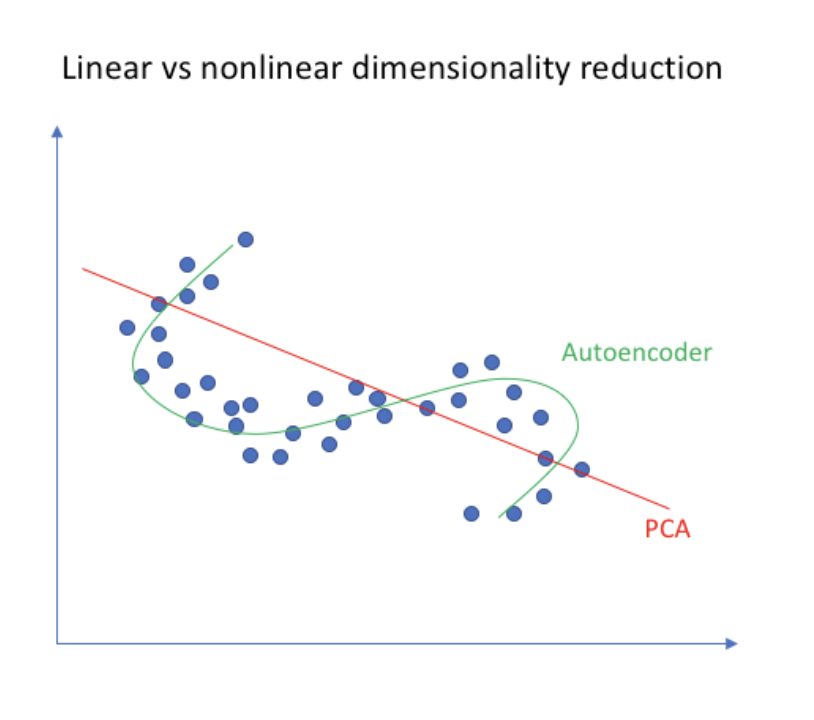
Encoder의 차원 축소 부분은 주성분 분석인 PCA(Principal Component Analysis)와 유사한점이 있다. 차원 축소는 결국 특징을 뽑아낸다는 것이다. 하지만 둘의 차이점은 PCA는 보통 선형적으로 데이터의 차원을 축소시키고(비선형 축소도 가능), Autoencoder의 Encoder는 비선형적으로 차원을 줄여나간다.
(사진 : https://www.ieremyiordan.me/autoencoders/)
Autoencoder모델을 만들어 입력과 정답을 동일한 훈련데이터로 주어 학습을 진행시켰다. 그리고 테스트 데이터를 입력으로 주어 이때의 입력과 출력을 바탕으로 재구성 오차의 백분위를 사용하여 이상탐지를 수행하였다.
# train
autoencoder.fit(train_data_scaled, train_data_scaled, epochs=500, batch_size=32, validation_split=0.1, callbacks=[early_stopping], verbose=1)
# 재구성 오차 계산
test_data_reconstructed = autoencoder.predict(test_data_scaled)
reconstruction_error = np.mean(np.square(test_data_scaled - test_data_reconstructed), axis=1)
# 재구성 오차 백분위를 임계값 지정
threshold = np.percentile(reconstruction_error, 95.36)
모델 레이어도 변경하고 임계값도 다양하게 변경하였지만 성능이 한 구간에 멈춰 오르지 못했었다.
DAGMM(Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection)
Ref:https://sites.cs.ucsb.edu/~bzong/doc/iclr18-dagmm.pdf
https://www.youtube.com/watch?v=byvMpGsl7cE
정상 데이터만을 가지고 이상탐지를 할 수 있는 비지도 모델을 찾던중 처음에 사용했던 Autoencoder기반의 GMM모델을 사용하여 직관적으로 이해하기 쉬워서 사용해보게 되었다.
결과적으로는 코드 실행에서 loss값이 none으로 출력되는 문제를 잡을 수 없어 사용해보지는 못했지만 다른 이상탐지 문제에 사용해볼 수 있을거 같아 정리해 본다. 이번 문제는 one-class에 관련한 문제였지만 이 모델은 mixture model에서도 사용할 수 있는 모델이기 때문에 더욱 유용할 것 같다.
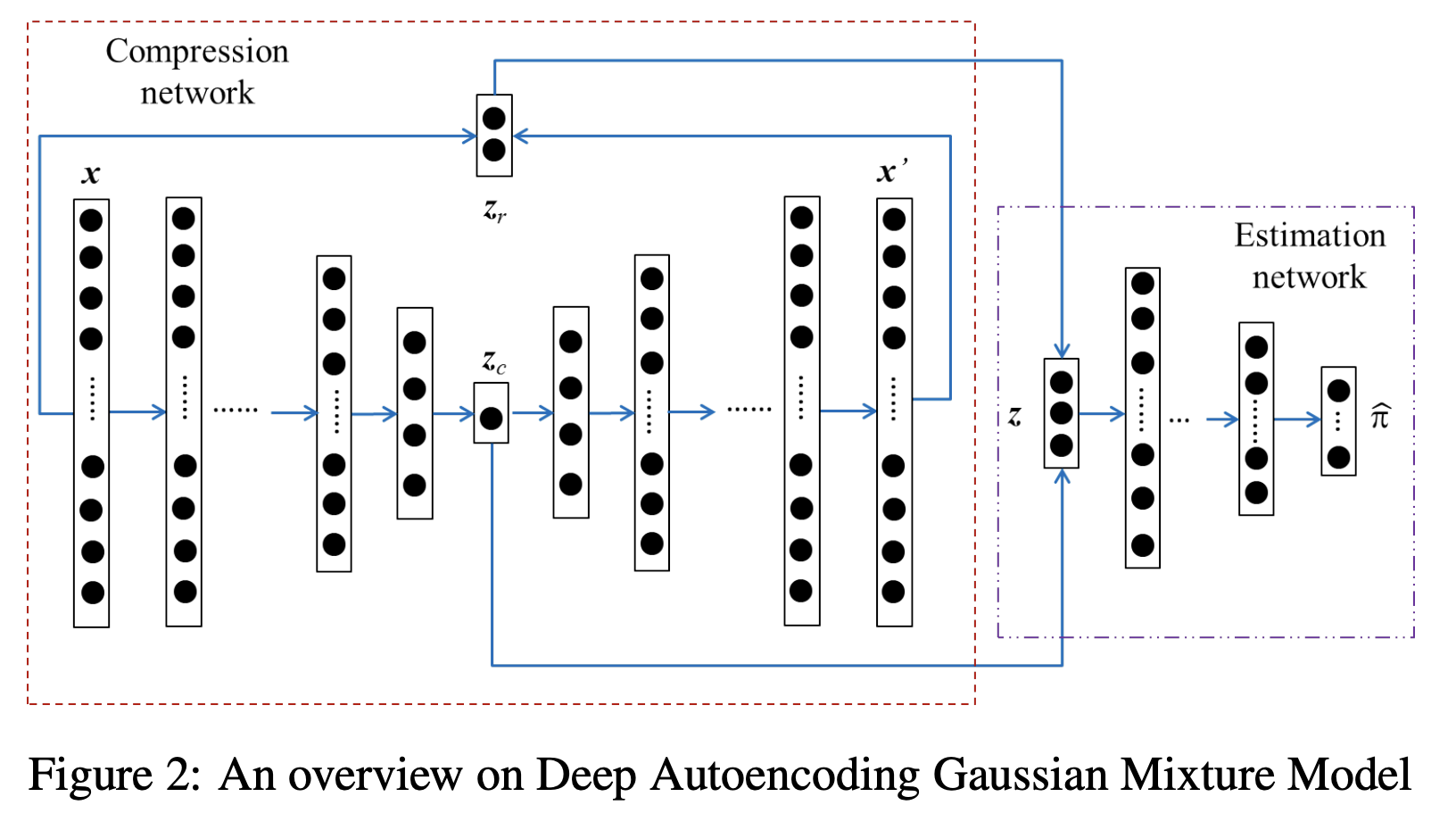
모델의 구조는 크게 2부분으로 나눌 수 있다.
- Compression Network
- Estimation Network
1) Compression Network

z는 Low-Dimensional Representation은 2가지 Features를 합쳐진 형태이다.
- (1) Autoencoder를 통해 얻어진 Latent Representation
- (2) Reconstruction Error로 부터 얻어진 Feature[Euclidean distance, Cosine Similarity]
zr을 사용한 이유는 latent vector에서 normal과 abnormal의 차이를 명확하기 위해서 사용되어 졌다.

2) Estimation Network
앞에서 찾은 z를 바탕으로 soft mixture-component membership prediction을 수행하게 된다. 이후 Softmax를 통하여 어떤 분포에 속할지 확률로서 표현하고, 이를 통하여 GMM 파라미터를 추정하고 이상 탐지를 수행하는 과정이다.
-
(1) Membership Prediction:
-Compression Network를 통해 얻어진 Input (저차원 Representation)을 가지고, 각 데이터 포인트가 Membership(분포/군집)에 속할 확률값을 추정한다.
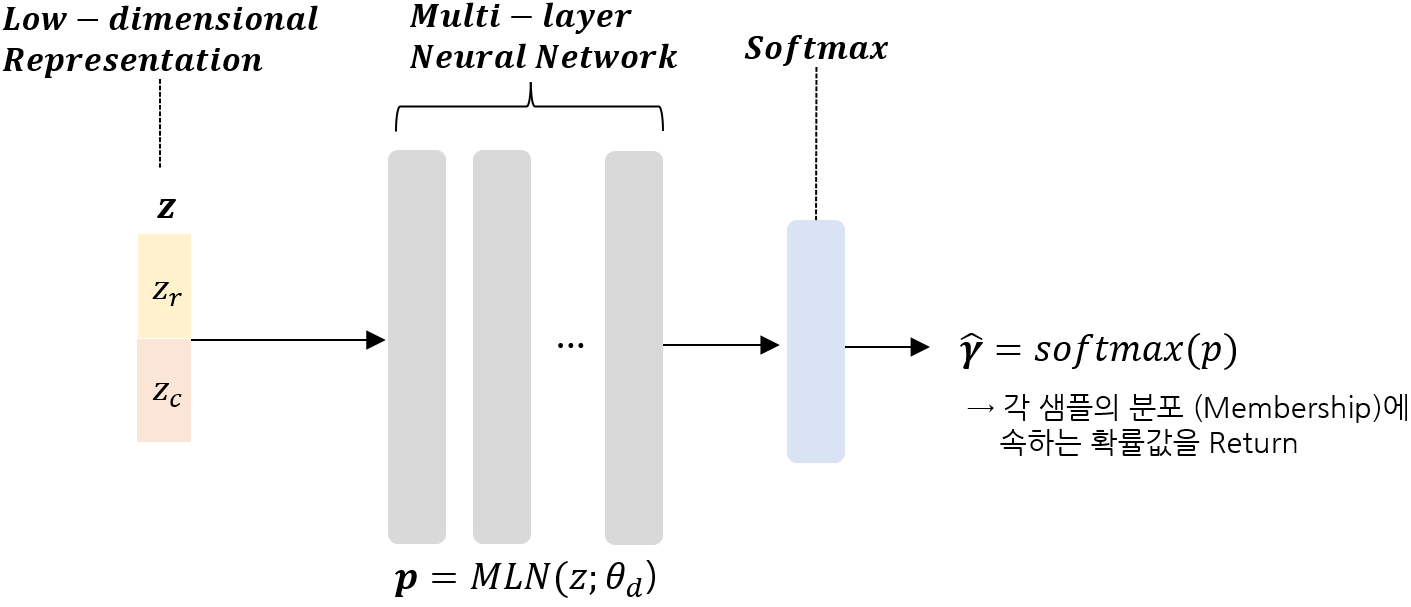
-
(2) 가우시안 분포의 파라미터 추정:
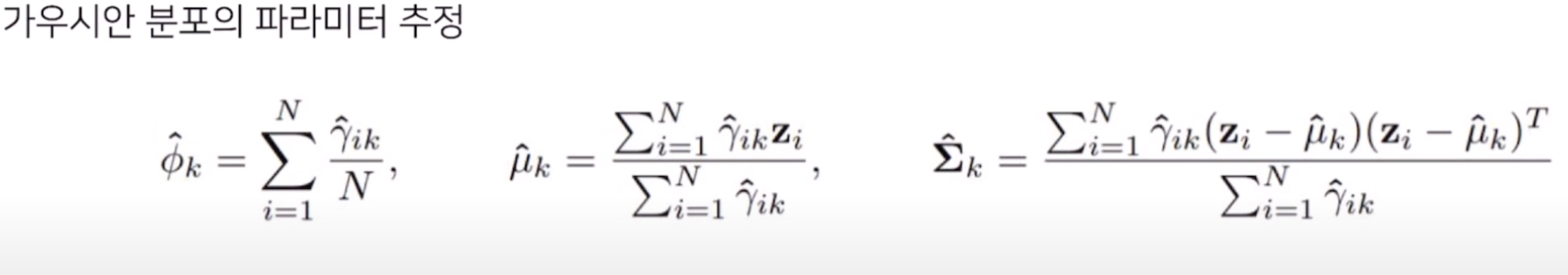
-
(3) Sample Energy 도출:
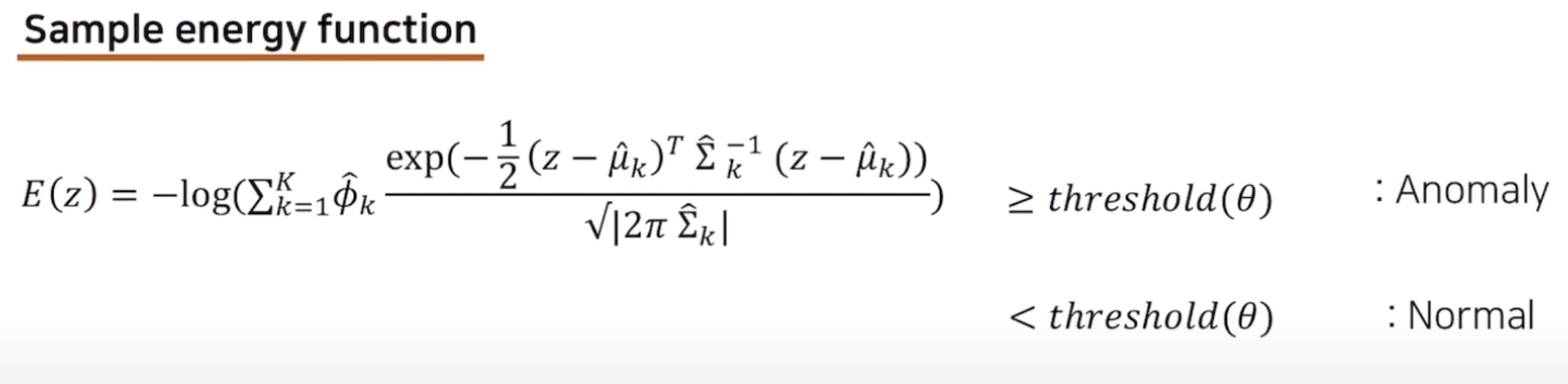
3) Object Function
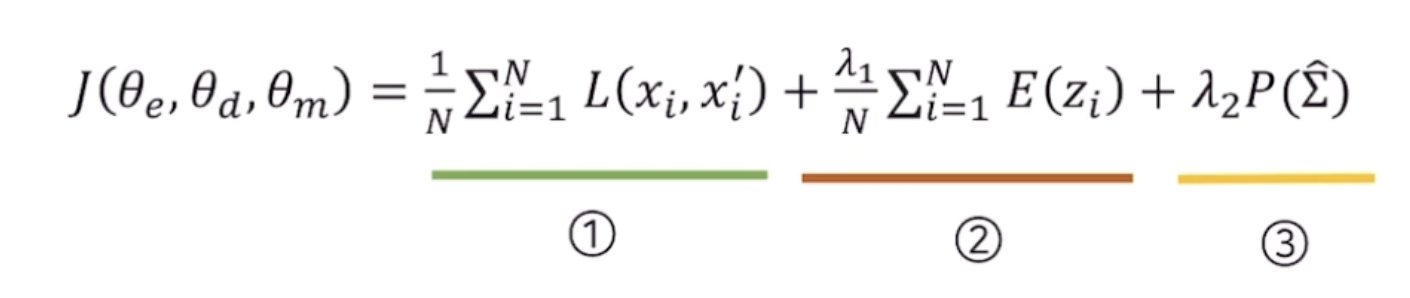
- Reconstruction Error (Compression Network)
- Energy Function (Estimation Network) - Input을 관측할 확률이 높아지도록 학습.
- Pernalised term (for Covariance matrices Diagonal Entries to 0)

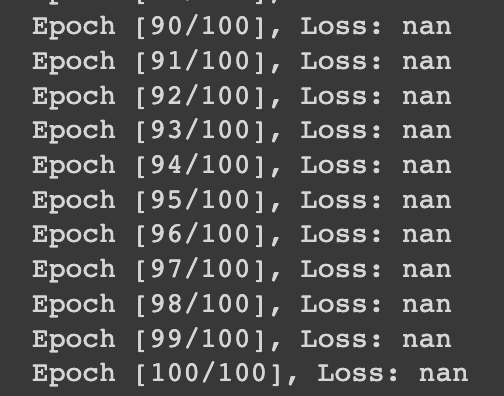
아래 사진과 같이 loss가 nan으로 나오는 오류를 잡지 못해서 아쉽게 사용은 못해봤지만 이와 비슷한 문제가 나온다면 제대로 사용해 보고 싶다.
Feature Engineering
train_data["motor_power"] = train_data["motor_current"] * train_data["motor_vibe"] # 모터의 출력과 밀접한 관련. 값이 높을수록 모터의 부하가 높아질 가능성
train_data["air_flow_per_hp"] = train_data["air_inflow"] / train_data["hp"] # 설비 크기와 공기 처리량의 관계
train_data["air_end_temp_diff"] = train_data["air_end_temp"] - train_data["motor_temp"] # 모터와 공기 말단의 온도 차이가 클수록 이상이 있을 가능성이 높음
train_data["efficiency"] = train_data["out_pressure"] / (train_data["air_inflow"] * train_data["motor_rpm"]) # 공기 압축기의 효율성
train_data["air_power"] = train_data["air_inflow"] / train_data["out_pressure"]
train_data["air_temp_diff"] = train_data["air_end_temp"] - (train_data["out_pressure"] * 10)
train_data["power_efficiency"] = train_data["out_pressure"] / (train_data["air_inflow"] * train_data["motor_current"])공기 압축기에 대한 지식이 부족에 ChatGPT에게 물어보기도 하고 구글링해서 팀원이 위와 같이 새로운 특징들을 만들어주고 했지만 모델 성능에는 아무런 영향을 주지 못하였다.
데이터들 간의 상관계수가 이미 충분히 높았어서 다양하게 변수를 추가했어도, 중복이나 다중 공선성의 문제로 모델의 성능이 오르지 못했던 것 같다.
내가 생각했던 이상치와 모델이 찾은 이상치 비교하기

Autoencoder를 통하여 다음과 같은 성능이 나왔을 때와 내가 생각했던 이상치와 모델이 찾은 이상치를 비교하고자 했다.
