시간이 없어 쓰다 멈추다를 반복하면서 이제서야 올리게 되었다.
3월초에 시작해서 4월 첫주에 마무리하고 이제서야 정리를 해보았다.

시작
KT Aivle School에 2월부터 교육에 참여하게 되면서 다양한 팀원들을 만나면서 운이좋게 팀원 추천으로 첫 경진대회에 참가하게 되었다. 3월 초 그 당시에서는 자연어 모델에 대해서는 아직 배우기 전이라 자연어 모델에 대해서 지식이 많이 부족하고 했지만 대회 경험도 쌓아보고 딥러닝 자연어 모델 GPT에 대해서 배워 보고자 참여하게 되었다.

베이스 라인 코드가 주어지기 때문에 조금 더 부담없이 대회에 참여할 수 있었고, 점수나 등수가 잘나오면 더욱더 좋겠지만 자연어 모델을 배워볼 수 있는 좋은 기회라 생각이 들었다.

제공되는 파일에서는 모델의 구조에 대해서도 설명해주고 있었고, 생성모델의 하이퍼파라미터들을 직접 소개해주고 있어서 GPT에 조금더 쉽게 다가갈 수 있었다.
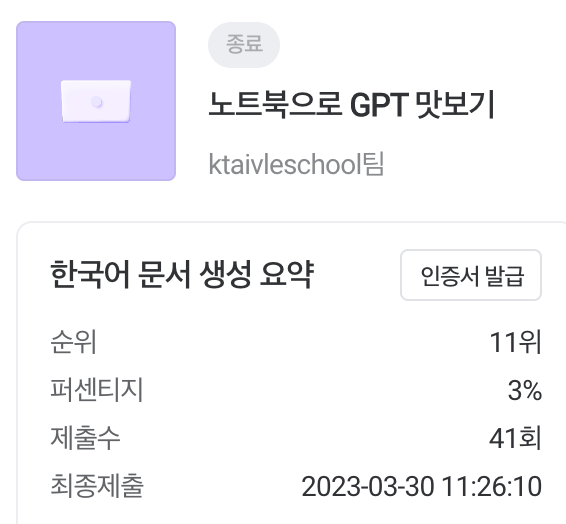
대회에 사용된 모델 성능지표

Rogue-1,2
Rouge Score란?
Recall-Oriented Understudy for Gisting Evaluation
label(정답 데이터)과 summary(모델을 훈련시켜 생성한 inference)을 비교해서 성능 계산
ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S 등 다양한 지표가 있음 대회에서는 Rogue-N, Rogue-L을 사용하였다.
Recall : label을 구성하는 단어 중 몇개가 inference와 겹치는가?
precision : inference를 구성하는 단어 중 몇개가 label과 겹치는가?
Rogue-N에서는 n-gram의 개수가 기준이 되어서 아래 사진과 같이 게산이된다.
Recall : output과 겹치는 N-gram의 수 / label의 N-gram의 수 이다.

Rogue-L에서는 LCS(longest common sequence) between model output 말 그대로 common sequence 중에서 가장 긴 것을 매칭한다. n-gram과 달리 순서나 위치관계를 고려한다.
Recall : LCS 길이 / label의 N-gram의 수
KoGPT가 아닌 ChatGPT를 사용하여 제출해보기
장난삼아 였지만 KoGPT가 GPT-3기반의 모델이라, 같은 기반인 ChatGPT에 직접 물어보면 어떨까 해서 시도해보게 되었다.
학습데이터의 label값을 확인하여 문장의 요약길이를 대충 파악하여 문장 길이를 60자 이하로 지정해 주었다.

장난삼아 한 실험이였지만 결과는 처참했다.

LORA(LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)를 이용한 모델 학습시키기.
https://arxiv.org/pdf/2106.09685v2.pdf 논문을 자세히 읽어보지는 내가 생각한 틀은 다음과 같다.
Low Rank(저차원) 에 대해서 자세하게 이해는 못했지만 이 저차원의 파라미터만 가지고 fine-tunning을 진행하여도 충분히 모델의 성능을 높일 수 있다.!! LLM모델을 전체 파라미터를 학습시키는 것이 아니라 주요 파라미터만 fine-tune을 하여도 성능향상에 도움이 되었다 이렇게 이해하였습니다.
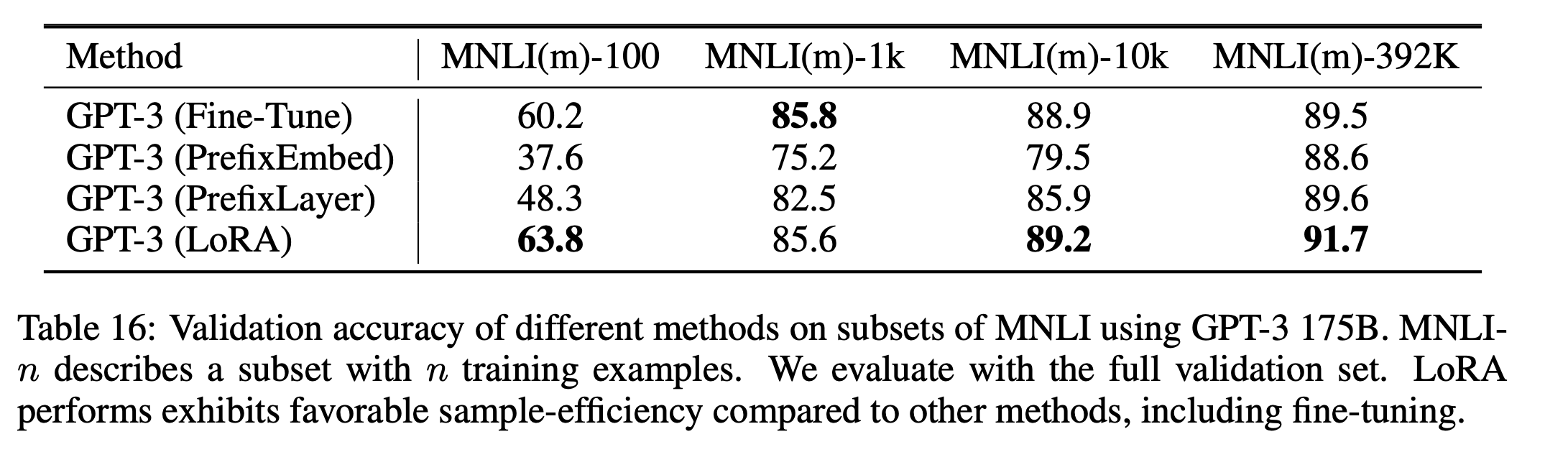
논문을 살펴보면 GPT-3 모델에 LoRA를 사용했을 때의 auccuracy가 fin-tune을 해쓸때 보다 소폭 증가하거나 거의 비슷한것으로 보여진다.
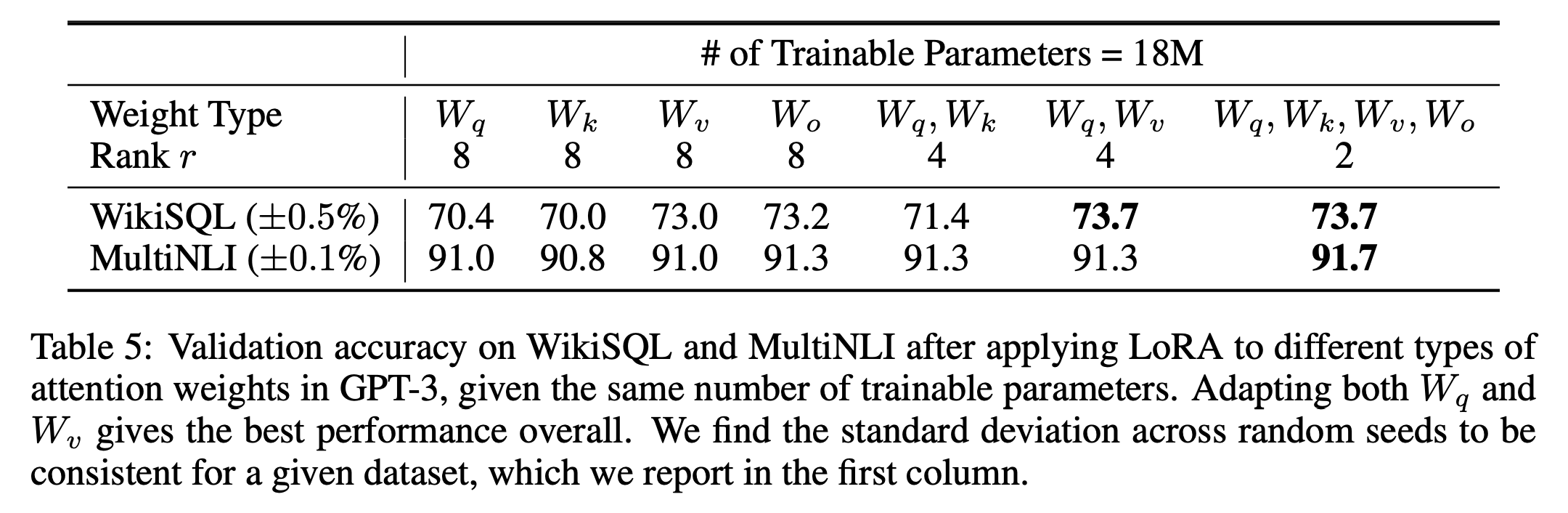
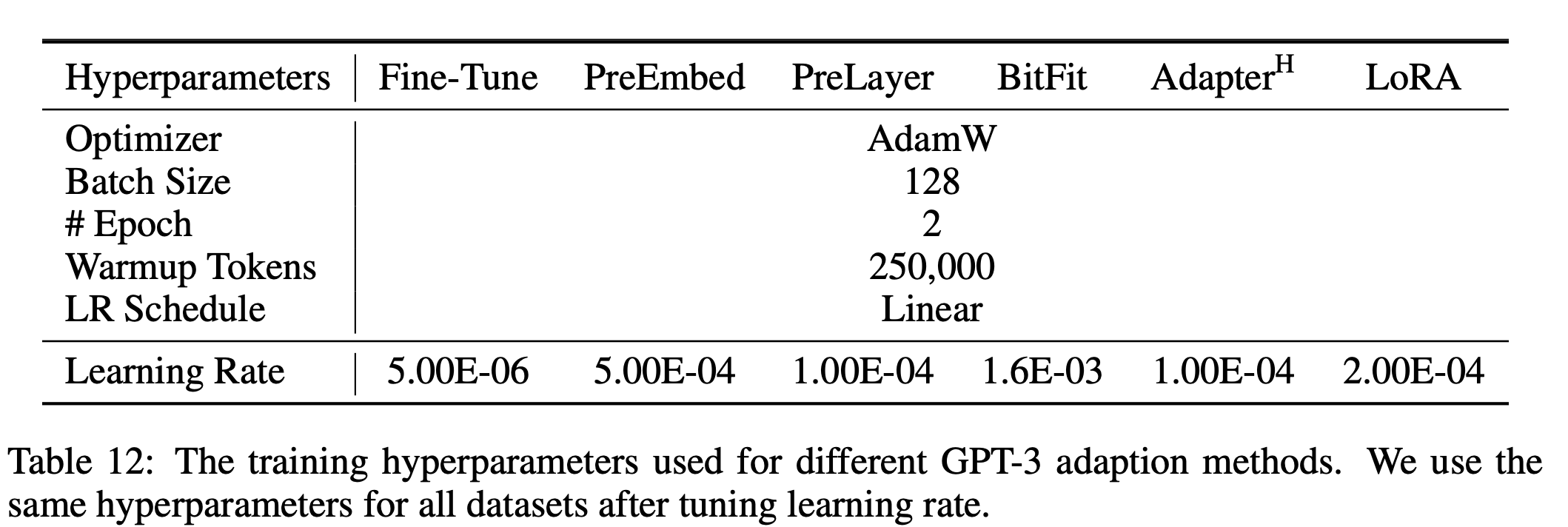
GPT-3를 실험할때 사용했던 학습률과 옵티마이저 등이 기록되어 있어 이를 사용하면 좋은 성능을 얻을 수 있을 않을까 생각이 들었다. 또한 Baseline 코드에 주어진 하이퍼파라미터 값들과 비교하고 Scheduler를 변경해보면서 학습을 시켜보고 하면 모델의 성능을 높일 수 있지 않을까 생각이 들었다.
peft_config = LoraConfig(
task_type = TaskType.CAUSAL_LM,
r=4, lora_alpha=32, lora_dropout=0.1,
target_modules = ['q_proj', 'v_proj'],
# target_modules = r".*(q_proj|v_proj)",
)LORA r값을 변경해가며 제출해보기
baseline의 코드는 다음과 같았고 이 값을 기본으로 하여 학습을 1에폭 시켜보고 그때 성능을 확인해보고 하이퍼파라미터를 변경해가며 학습을 시켜보며 성능을 개선해 나가보았다. 1에폭만 학습을 하여서 2시간 정도 걸렸던걸로 기억한다. 로컬에서 사용할수 있는 gpy가 없었기 때문에 colab을 사용하였지만 고사용ram에, 프리미엄으로 gpu를 돌려야하기 때문에 부담이 조금 되었다.

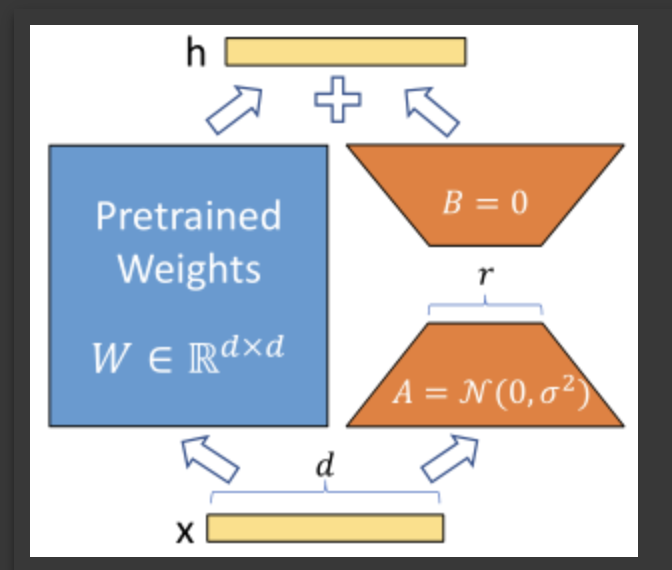
처음 시작은 위의 논문에서 GPT-3 실험에서 LoRA에 사용할 rank인 r값을 줄여 나갔을 때 성능이 개선되는것을 보고 r값을 4로 줄이고 (lora_dropout: A, B 보다 앞에 추가할 Dropout 레이어의 drop 비율)dropout ratio를 내 임의로 0.05로 줄여서 1epoch학습하고 결과를 제출해보았다.

결과는 오히려 떨어져 r값은 8로 유지하는게 좋을것이라 생각이 들었다.
AdamW Optimizer의 사용
위의 논문 실험에서 사용한 AdamW를 사용하면 도움이 되지 않을까 생각이 들었다.
기존에 사용한 Optimizer는 Adam이여서 L2정규화 효과가 wieght decay에 비해 성능이 별로 좋지 못하기 때문에 weight decay를 Adam 과 함께 이용하기 위해 고안된 AdamW를 사용하면 성능향상에 도움이 되지 않을까 생각 들었다.
AdamW(2e-4)LoRA(r=8 lora_alpha=32, lora_dropout=0.1) 다음과 같이 하이퍼파라미터를 조정하였다.

모든 지표에서 성능이 소폭 증가하였다. 1epcoch밖에 학습을 못하긴 했지만 성능이 나름 개선되었다.
디코딩 알고리즘 조절
코랩을 사용함에 있어 1번학습을 시킬떄만 컴퓨팅 소모가 심해 비용적으로 부담이 되기 시작했다.
이때 생각난 방법은 학습된 모델의 생성시 디코딩 알고리즘을 조절하면 성능을 조금이나마 올릴 수 있지 않을까 생각이 들었다.
- Greedy decoding은 타임스텝 t에서 가장 높은 확률을 가지는 단어를 다음 단어로 선택하는 가장 일반적인 전략이다.
- Beam search는 특정 시점에서 빔의 개수(=K)만큼 다음 단어들을 탐색하고 가장 확률 높은 단어를 고르는 방식으로,이 때 빔의 개수 만큼의 시퀀스를 유지한다.
- Top-K Sampling은 랜덤 샘플링에서 선택할 수 있는 단어의 집합을 제한하는 방법으로, 전체 단어들에 대한 확률 분포를 상위 K개의 단어들에 대해 재분배하는 전략이다.
- Top-p sampling 방법은 높은 확률을 가지는 k개의 단어로부터 샘플링하는 대신, 누적 확률이 확률 p에 다다르는 최소한의 단어 집합으로부터 샘플링하는 방식이다.
- Temperature Scaling 예측한 다음 단어들의 확률 분포를 변형시키는 방법이다.
단어들의 분포를 변경시키지 않기 위해 Temperature를 1로 유지하고, Beam값을 다양하게 변경하고 top-p, top-k값을 아주 조금씩 변경하여 결과를 제출해 보았지만 성능에 있어서는 개선을 보이지 못하였다.
CosineAnnealingWarmRestart
디코딩 알고리즘에서 쓴맛을 본후 epoch수를 많이 가져가지 못하지만, scheduler를 사용해보면 어떨까 라는 생각이 들었다.
논문에서는 Linear scheduler를 사용하였기 때문에 다양한 Scheduler를 찾아보면서 성능을 개선시켜보고자 했다.
https://towardsdatascience.com/the-best-learning-rate-schedules-6b7b9fb72565
이 글을 읽어보면서 주기적으로 lr를 증가시켰다 감소시켰다 하면서 local optima에 빠지는 문제도 해결해주고 global minima에 보다 빠르게 도달하는 것을 보고 다양한 scheduler를 찾아보다 CosineAnnealingWarmRestart를 알게 되었다.
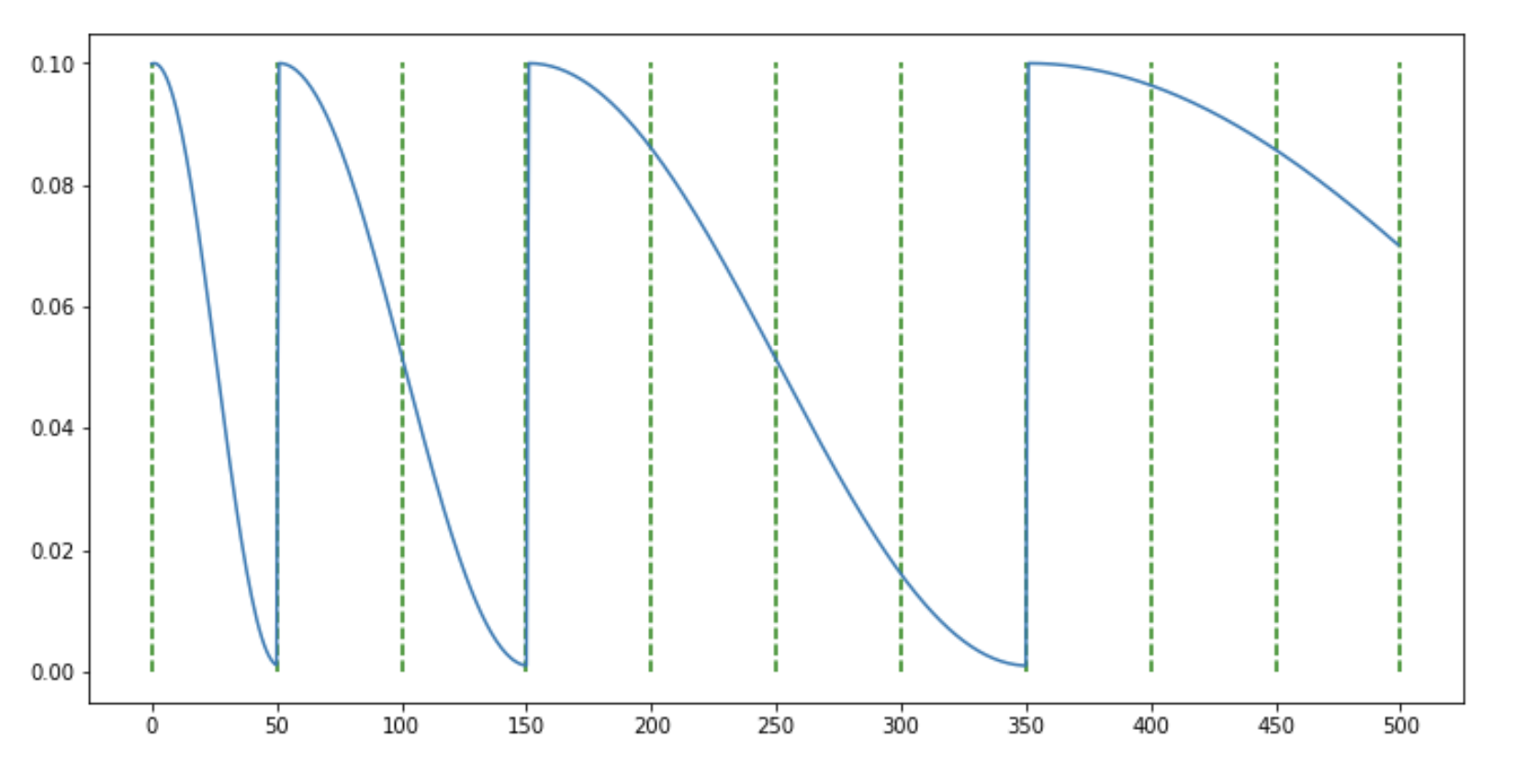
위 그림과 같은 방식으로 주기적으로 iteration마다 lr을 크게 증가시켜 학습을 진행하는 방식이다.
내가 가진 조건에서는 epoch을 여러번 가져가지 못하기 때문에 batch내에서 조금이나마 개선이 있기를 원했다.
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
learning_rate = 2e-4
optimizer = torch.optim.AdamW(peft_model.parameters(), lr=learning_rate)
# 학습률 스케줄러 설정
T_0 = 202
T_mult = 2
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=T_0, T_mult=T_mult)
scaler = torch.cuda.amp.GradScaler()다음과 같이 코드를 사용하였고 성능은 아래와 같이 향상되었다.

내가 제출한것은 이정도 된다.
다양하게 하이퍼 파라미터를 변경하면서 제출을 하였지만, 성능이 떨어진 경우가 훨씬 많았었고, 성능이 향상되거나 이번에 새롭게 배우게 된 부분에 집중해서 작성해 보았다.
이번 대회를 마치며..
첫 경진대회 이기도 했고 자연어 처리에 대한 제대로된 지식 없이 참여한 대회였지만, 많은 것을 배운것 같다.
다양한 자연어 모델을 접해볼 수 있었고, huggingface라는 강력한 도구도 얻은것 같다. 자연어 모델에 있어 다양한 모델을 불러와 사용하고 파이토치 학습 스크립트에서 반복되는 부분(optimizer, lr schedul, tensorbord, gpu 병렬 처리,..)을 따로 구현하지 않고 arguments로 통제할 수 있다는 장점이 있어 자연어 관련 프로젝트에 유용하게 사용할 수 있을것 같다.
KT AIVLE교육과 함께 진행하다 보니 시간을 쓸 수 없었어서 조금 아쉬움이 남는다. 하지만 비슷한 대회가 생긴다면 더 잘할 수 있을 것 같다.