나는 기능 개발보다 개발 환경 설정에 더 관심이 많은 사람이다. Source Code를 한 줄 더 작성할 때 보다, yaml을 한 줄 추가할 때가 더 재밌다. 이번에 Spring을 공부하면서 가장 즐거웠던 순간 중 하나도 SonarLint의 대체제를 찾아볼 때였다. 사람은 실수하는 존재라는 믿음 아래에 자동화에 많은 관심을 가져 온 나였기에 예전부터 CI/CD란 개념을 참 좋아했던게 아닐까?
최근 겪었던 문제들 (feat. Hacking)
1. Docker Container가 꺼져 있었네?
내 첫 실사용 프로젝트는 간단한 Todo list App이었다. 서버는 express.js로 작성했으며, Docker를 활용해서 aws의 EC2와 RDS를 통해 배포했다. 다양한 기술 도입 및 개발 과정 간소화에 공을 많이 들였고, 예전부터 사용하던 husky와 lint-staged, Github Actions와 같은 도구를 통해서 나름 만족스러운 pipeline을 구성했다.
스스로 느껴왔던 불편을 해소하기 위해 만들어진 앱이다 보니 학기 중 은근히 잘 써먹었다. 그러다 종강을 맞이하고 Ubuntu를 벗어나면서 사용 중이던 모든 디바이스를 초기화하게 되었는데, 어차피 종강도 했겠다 밀려드는 과제도 없고 할 일도 줄어서 그냥 앱을 설치하지 않고 지냈다.
그리고 대망의 2024년, aws는 Elastic IP에 무조건 요금을 부과하기 시작했고, 어차피 안 쓰던 프로젝트이자 리뉴얼하기로 결정했던 프로젝트를 정리할 겸 모든 instance를 삭제했다. 이런 부분으로는 약간의 강박이 있는 편이어서, RDS와 EC2 instance 뿐만 아니라 CloudWatch log_group이나 VPC route_table, Security Group 등 내가 아는 모든 것을 삭제했다.
그리고 시간이 흐르고 흘러, 프로젝트 리뉴얼을 위해서 이전 기록을 정리하다가 잊고 있던 사실을 떠올렸다. 서버 호스팅 중 중간에 몇 번 App에서 Server에 접속하지 못하던 일이 있었고, 확인해 보니 EC2에 작동하고 있어야 할 docker container가 삭제되어 있었다. 당시 access, system-info, error의 3가지로 나눠 기록해 둔 log를 확인해 보았지만, Application Error는 어디에서도 발견할 수 없었다. 당장 log로 확인이 안 되는 상황이다 보니 상당한 삽질이 예상되는데, 실사용자는 나 혼자뿐이니 발견도 쉽고 대처도 쉬워 원인 파악을 미뤘다. 그러고 모든 걸 삭제한 나. 제정신인가?
하여튼, 이제 와서 원인을 분석하려 해도 관련 기록이 이미 말소된 후라 정확한 원인 힘들다. 그래도 추측하자면 아마 EC2 instance 관리를 위해 aws가 instance를 reboot 했고, docker run에 restart 옵션을 주지 않았던 내 container가 자동 실행되지 않아 벌어졌던 문제가 아닐까 싶다. aws CloudTrail에 reboot log는 없었지만, HW 문제가 아닌 system update 관련으로 reboot되면 log가 안 남을 수도 있다니 아마 맞지 않을까...?
2. Deployment는 성공했지만, 실패했다
종강 이후 GDSC 활동으로 프로젝트를 진행하고 있었는데 (이게 내 관심을 위 프로젝트에서 이곳으로 뺏어왔다) 어쩌다 보니 CI/CD를 내가 짜게 되었다. 그래서 위 프로젝트를 참고해서 간략한 Github Action workflow를 작성했다.
나에게 CD란 Delivery를 의미했다. Deployment를 적용하려면 설정해야 할 것도 많거니와, 단일 인스턴스를 사용하던 내게 무중단 배포는 불가능한 일이었기 때문이다. 배포라는 중요한 작업에 사람이 배제된 완전 자동화를 도입하는 데에 거부감이 여전하기도 하다.
그런데 GDSC Solution Challenge를 진행하면서 GCP의 Cloud Run을 사용해 자동 배포를 구성하신 분을 보니 욕심이 생겼다. serverless까지 갈 건 아니지만, 자동으로 배포되는게 그렇게 썩 나쁘지만은 않겠다는 생각이 들었다. 어차피 docker image를 hub에 넣어두고, Compute Engine에 접속해서 pull & run 할 일이라면 그냥 workflow에 추가해 둬도 나쁠 게 없다 싶었다.
그리고 이제 False Psotivie가 발생했다. MySQL 실행 환경이 달라서 TEST는 통과했지만 운용 환경에서는 작동하지 않던 문제였다. MySQL은 Windows/Mac에서는 기본으로 Case-InSensitive지만 linux에서는 기본으로 Case-Sensitive다. Database Table을 모두 CAPITALIZE 해 둔 상태였는데, native query를 실행하는 과정에서 해당하는 Table을 찾지 못했다.
결과적으로 Spring Server가 runtime 오류로 종료되더라도, docker run 자체는 성공적으로 수행되었기 때문에 workflow는 pass하게 된다. 즉, 실패한 배포를 Github Action은 성공으로 받아들이게 된다.
3. MySQL Database 연쇄 증발 사건
MySQL은 Cloud SQL을 통해 호스팅하던 중이었다. 클라이언트 팀원에게서 자꾸 서버가 5xx를 반환한다고 연락이 왔다. log를 통해 MySQL: Unknown database xxx error를 확인할 수 있었다.
정말 당황했다. Cloud SQL instance가 과부하로 뻗었겠거니 싶었는데, 이상하게도 instance는 멀쩡했고 database가 사라졌었다. error log를 확인해 보니 중간에 instance가 reboot 된 이후로 MySQL: Unknown database xxx가 쉴 새 없이 기록되어 있었다.
다행히 실 운영 시점이 아닌 개발 단계였기 때문에 database를 다시 생성해서 임시로나마 서버 정상화가 가능했다. 문제를 해결하기 위해 log를 열심히 뒤져봤지만, 아무리 읽어봐도 원인은 알 수 없었다. 처음에는 MySQL data location 문제인가 싶었다가도 Cloud SQL 설정을 잘못 건드렸나 싶었다. 끝내는 Cloud SQL에서 하자 있는 instance를 할당받은게 아닐지 의심하는 지경에 이르렀다.
그렇게 database는 약 2~3일을 주기로 꾸준히 실종되었고... 화가 머리끝까지 솟을 무렵 다행히 원인을 파악하는데 성공했다. 해킹당했던 것. 이거 실환가요?
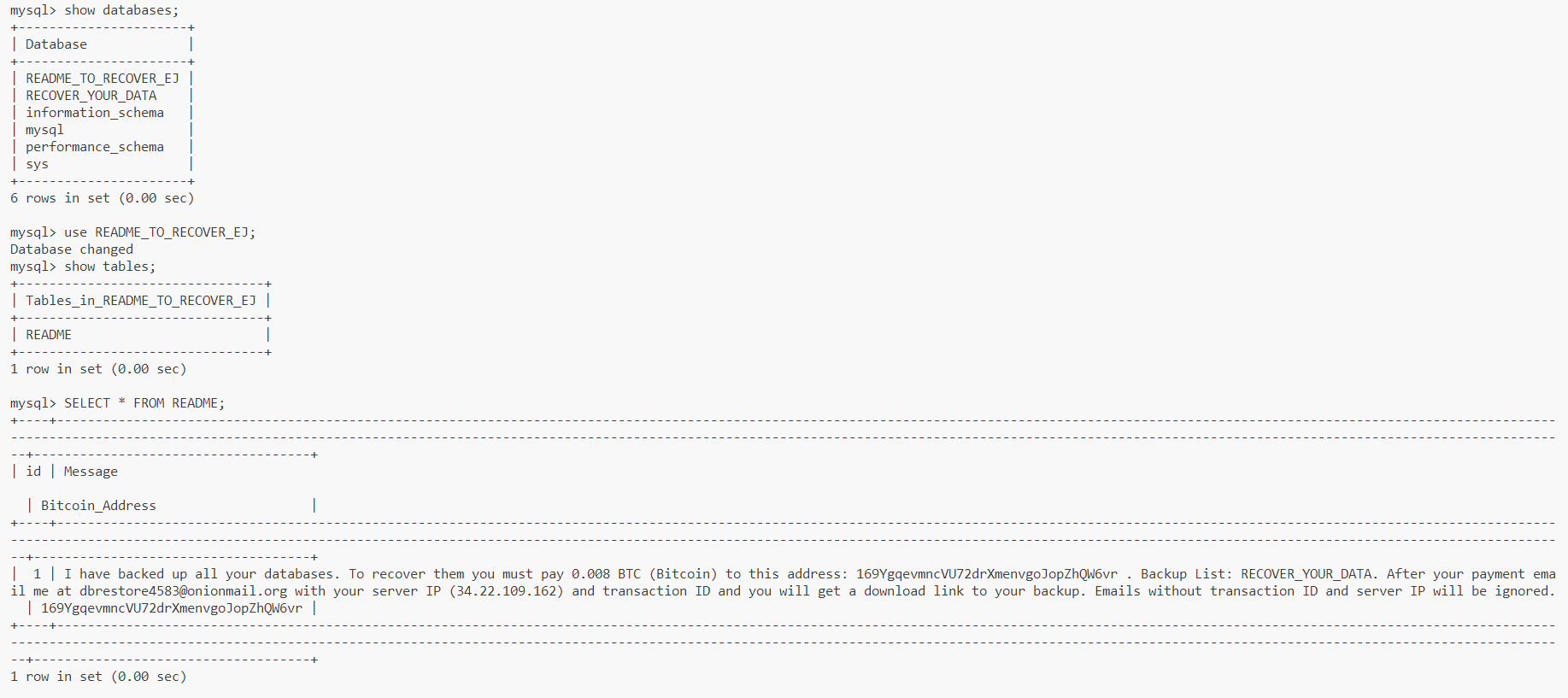
과거 express.js 프로젝트를 진행하면서 DB 형상관리를 위해 kenx.js를 사용했는데, migration을 EC2에서 실행하니 사양 부족으로 instance가 뻗어버리곤 했다. 그 이후론 DB를 외부 IP 접속이 허용되게끔 설정해 두곤 했는데, 거기에 더해서 이번엔 MySQL root 비밀번호를 root로 지정하는 멍청한 짓까지 겹쳐 버리니 바로 해킹당했던 것. 정말 웃지 못할 일이었다. DB IDE를 쓰고 싶거든 ssh tunneling을 했어야...
원인을 알고 log를 다시 보니 확실히 Brute Forcing 흔적이 남아있었다. root로 지속적인 access와 deny가 반복된 기록이 꽤 많았다. 이것 역시, 이전 프로젝트에서 access log를 들여다보곤 했을 때, 온갖 크롤러가 내 사이트에 access 한 기억이 있어서 자연스럽게 그런 느낌으로 생각했다. 생각해 보면 Web Server에 요청하는 것과 DB에 root로 access를 시도하는 건 180도 다른 문제인데 해킹은 상상도 못했다보니 놓쳐버렸다.
Health Check System이 있었더라면...
위 경험했던 3가지 문제는 각각 원인이 달랐다. 첫 번째 문제는 Docker와 aws에 대한 부족한 이해, 두 번째는 MySQL과 Github Actions에 대한 부족한 이해, 마지막 문제는 그저 나의 안일했던 보안 설정이 문제였다. 그리고 각각의 원인을 파악하고 대처함으로써 모든 문제는 해결된 것처럼 보인다. 하지만 나는 보다 중요한 사실을 깨달았다.
위 문제의 공통점은 배포한 프로그램이 제대로 동작하지 않았다는데 있다. 심지어 첫 번째 문제는 몇몇 재발 과정에서 문제 발생 후 일주일 가량 모르고 있었던 적도 있었다. 프로그램이 제대로 동작하지 않는다는 사실을 너무 늦게 알았던 것이다.
물론 CI 단계에서 E2E TEST를 수행하거나 보안을 더 신경 쓴다면 해결될 문제다. 하지만 기록을 복기하면서 container의 상태가 정상적인지 확인하고 비정상이라면 빠르게 인지할 수 있는 시스템의 필요를 강하게 느꼈다.
물론 세 번째 경험과 같이 당장 해결이 불가능할 문제도 있다. 하지만 문제 발생 즉시 빠르게 인지할 수 있다면 DB 재생성과 같은 임시 조치라도 발 빠르게 수행해서 Client의 불편함을 최소화할 수 있지 않았을까?
지금까지 Linting을 local에서 git hook으로 강제할지 remote ci server에서 실행할지, 이런 걸 고민하면서, 막상 배포된 프로그램에 문제가 생겼을 때 알람을 전송할 시스템을 생각하지 않았던게 부끄럽다. 프로그램이란 결국 서비스를 제공하기 위해 존재한다. 번쩍이는 껍데기에 한눈파는 사이 중요한 본질을 놓친건 아니었을까?
이상과 현실을 생각해 보면
이상(?)은 이러하다
Server Error(5xx)의 최초 발견자는Server Engineer다.Database Error의 최초 발견자는DBA다.배포 환경 문제의 최초 발견자는SRE Engineer다.
거창하게 써놓았지만 내가 저 직군을 이해한다는 얘기가 아니라, 그만큼 말도 안 되는 환경이라는걸 표현하고 싶었다.
현실(?)은 이러하다
Server Error(5xx)의 최초 발견자는사용자거나Client Engineer다Database Error의 최초 발견자는Server Engineer다배포 환경 문제의 최초 발견자는사용자거나Server Engineer,DBA다
Monitoring System을 잘 구축한다면, 현실보다 이상에 가까워지지 않을까?
