
📢데이터분석 및 시각화 - 미세먼지 발표편
파이썬을 활용하여 데이터분석 및 데이터 시각화 프로젝트를 진행해보자
데이터분석 프로젝트 - 인플레이션 발표편
데이터분석 프로젝트 - 미세먼지 발표편
데이터분석 프로젝트 - 인플레이션 분석편
데이터분석 프로젝트 - 미세먼지 분석편
데이터분석 프로젝트 - 주제선정
- 발표에서 사용했던 ppt를 활용하여 프로젝트를 만들때 어떤 의도를 가지고 어떤 이유에서 만들었는지에 대한 자세한 이유와 시각화 방식을 사용한 이유에 대해 자세히 설명할 것이다.

'미세먼지, 어디까지 알고있니?'라는 주제로 관중의 흥미를 유발할 수 있는 제목을 사용하여 도입부에서 궁금증을 유발하기 위해 제목을 선정하였다.
미세먼지라는 주제를 선정했던 이유는 데이터분석이 용이하고, 여러 가설에 대한 결론을 도출하기에 적정했기 때문에 선정하였다.
또, 미세먼지라는 주제가 요즘 사회적 이슈로 떠오르고 있고, 우리들의 인식이 점점 나빠지고 있는 상황이었기에 흥미를 끌기에 적절하다고 판단했기 때문이다.
그 결론에 대한 시각화를 할 때에도 눈에 확들어오는 변화가 보이기 때문에 조금 더 적절한 주제였던 것 같다.

프로젝트 배경 및 목적을 시작으로 전체적인 순서를 목차에서 소개한다.
미세먼지에 대한 배경지식이 약간을 필요하기 때문에 배경지식을 사전에 채워주고 시작하게 될 것이다.
또 4가지 가설과 물음에 대한 답을 채워가는 방식으로 진행될 것이고, 분석결과와 내 생각을 넣어서 마무리 하는 순서로 진행될 것이다.

이번 데이터분석 프로젝트의 목적은 서울특별시의 대기오염도 현황 데이터를 정제하고 분석하여 미리정한 가설에 따른 결론을 도출하고 이를 시각화하여 청중들이 한눈에 결론을 알아볼 수 있도록 만드는 것에 목적이 있다.
pandas, matplotlib을 사용하여 데이터 분석 및 시각화를 진행한다. 그리고 python언어를 기반으로 진행되며 folium을 활용하여 미세먼지 측정소의 위치를 마커를 사용하여 지도에 표기하여 측정소 위치를 표기한다.

미세먼지 농도에 대해 분석하기 전 미세먼지가 무엇인지에 대한 배경지식이 있어야 뒤에 나오는 미세먼지 지수에 대해 분석한 과정을 이해할 수 있다. 그래서 미세먼지에 대한 기본적인 지식을 설명하여 배경지식을 쌓는다.
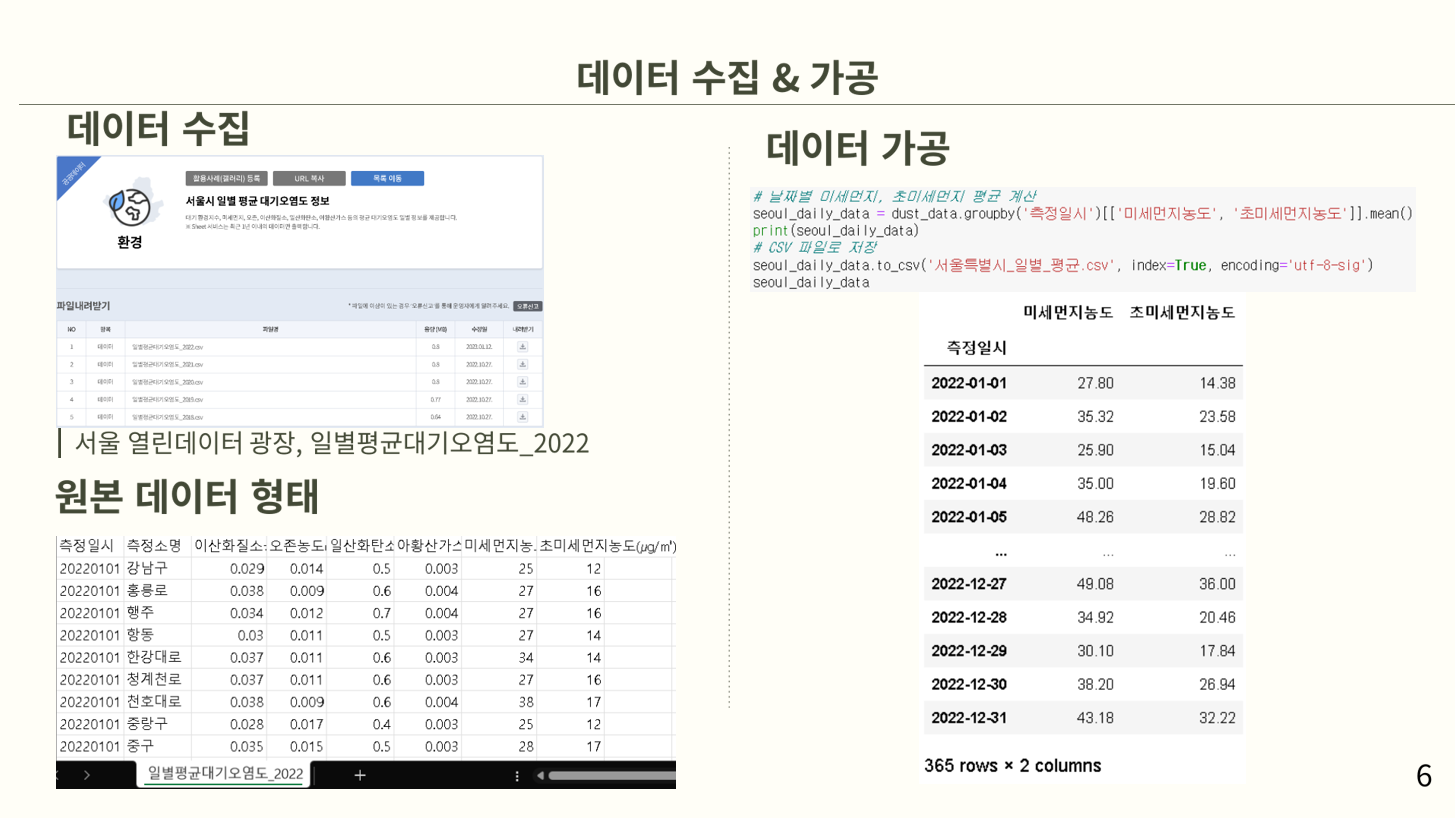
데이터는 서울 열린데이터 광장에서 다운받았고, 2022년 데이터를 사용한다.
원본 데이터의 형태는 측정일시별 측정소에서 측정한 각 대기오염의 농도를 기록한 데이터이다. 하지만 일별 미세먼지 초미세먼지의 농도가 필요하므로 측정소데이터의 평균을 계산하여 일별로 정립하고 대기오염 목록중에 미세먼지와, 초미세먼지만 따로 추출하여 csv파일로 저장한다.
그리고 이를 분석할 예정이다.
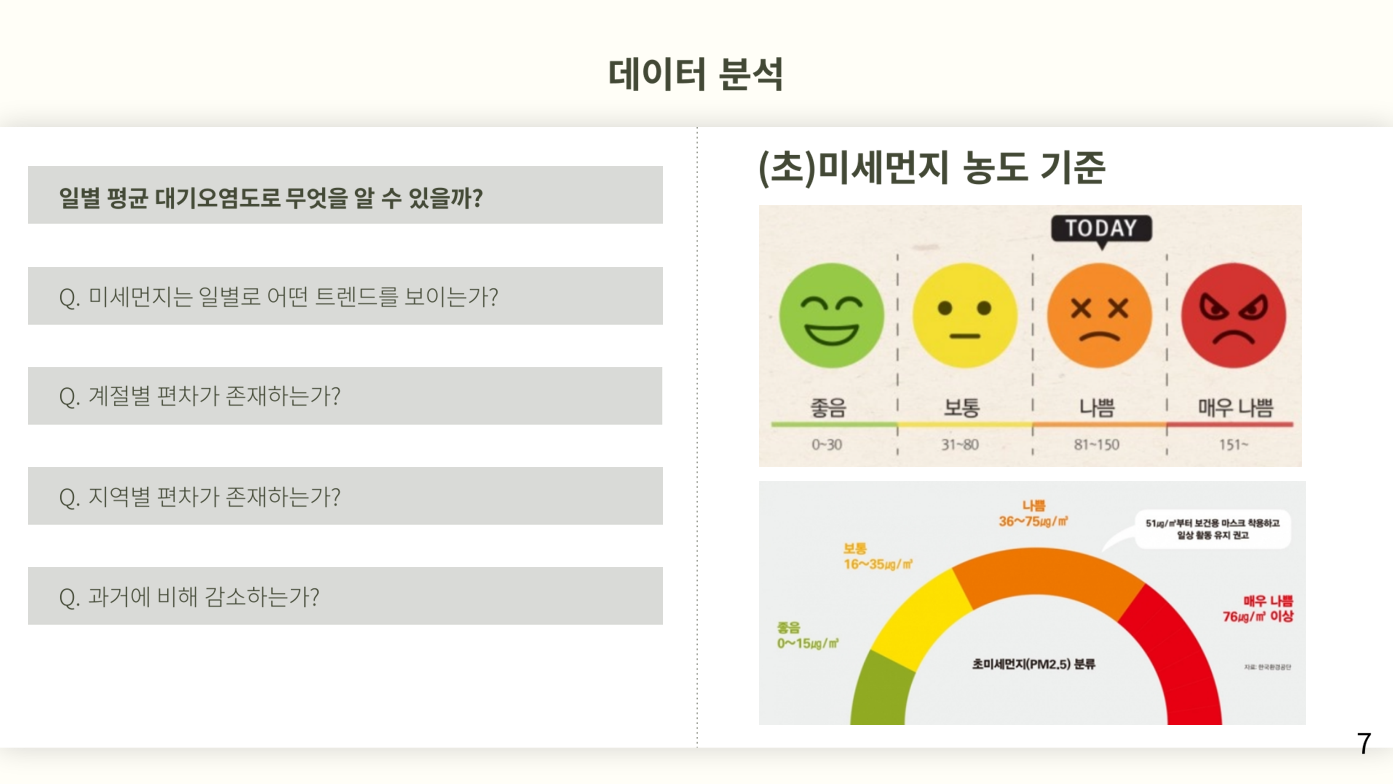
분석을 통해 알아볼 가설을 세운다. 미세먼지 일별 트렌드를 시각화하고 이를 통해 계절적 편차와 지역적 편차가 존재하는지에 대한 결론을 도출하는 방향으로 분석을 이어간다. 그리고 미세먼지의 연간 흐름을 분석해 과거에 비해 감소하고 있는지 심해지고 있는지 분석한다.
본격적인 분석에 앞서 이어 사용할 미세먼지의 심각성에 대한 지표로서 농도 지수가 나쁨이상인 날을 하나의 기준으로 정하여 사용할텐데 그를 위한 배경지삭을 위해 미세먼지 80이상, 초미세먼지 35이상이 나쁨이라는 것을 알려준다.
📌미세먼지는 일별로 어떤 트렌드를 보이는가?
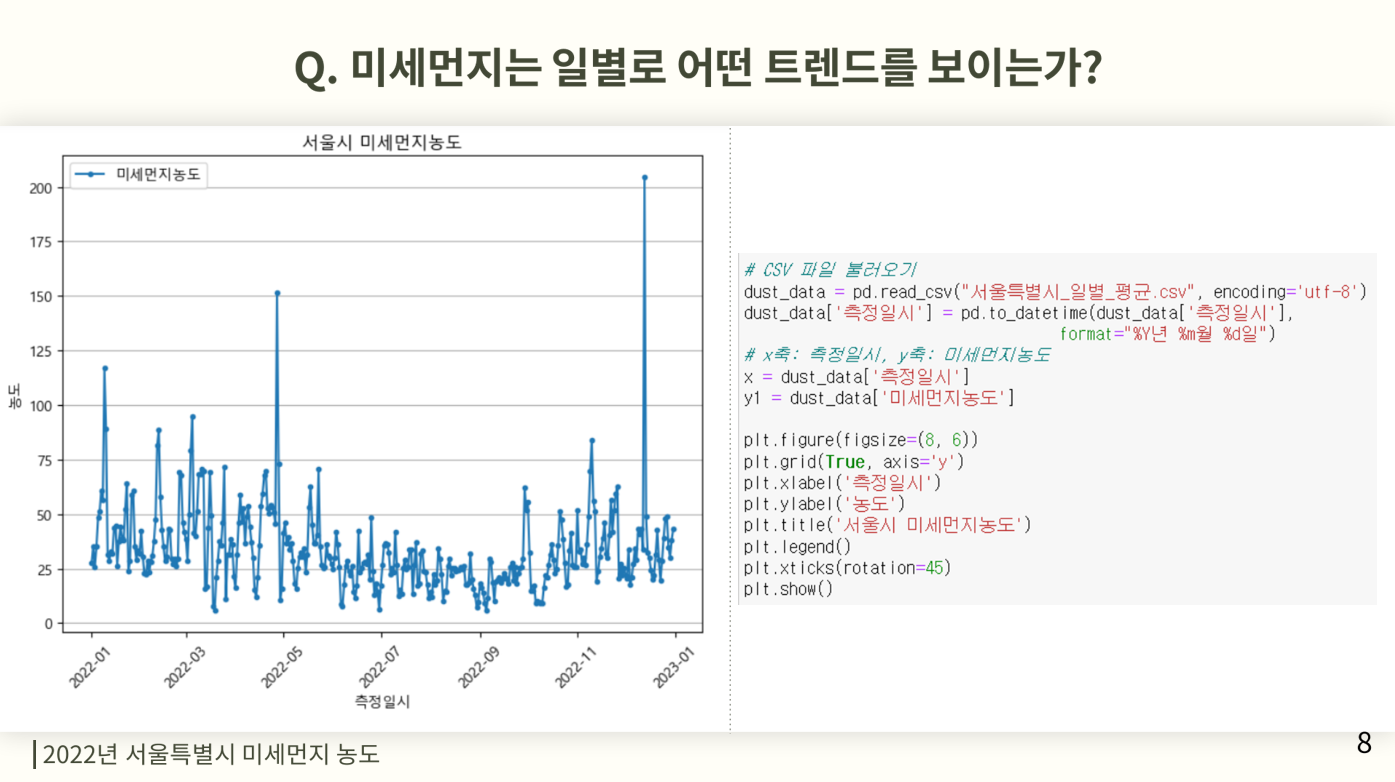
미세먼지의 일별평균을 선그래프를 통해 시각화하고 그에 마커를 사용하여 점을 찍어준다. 그럴경우 일별로 어느 부분때 심각한지 알수 있다.
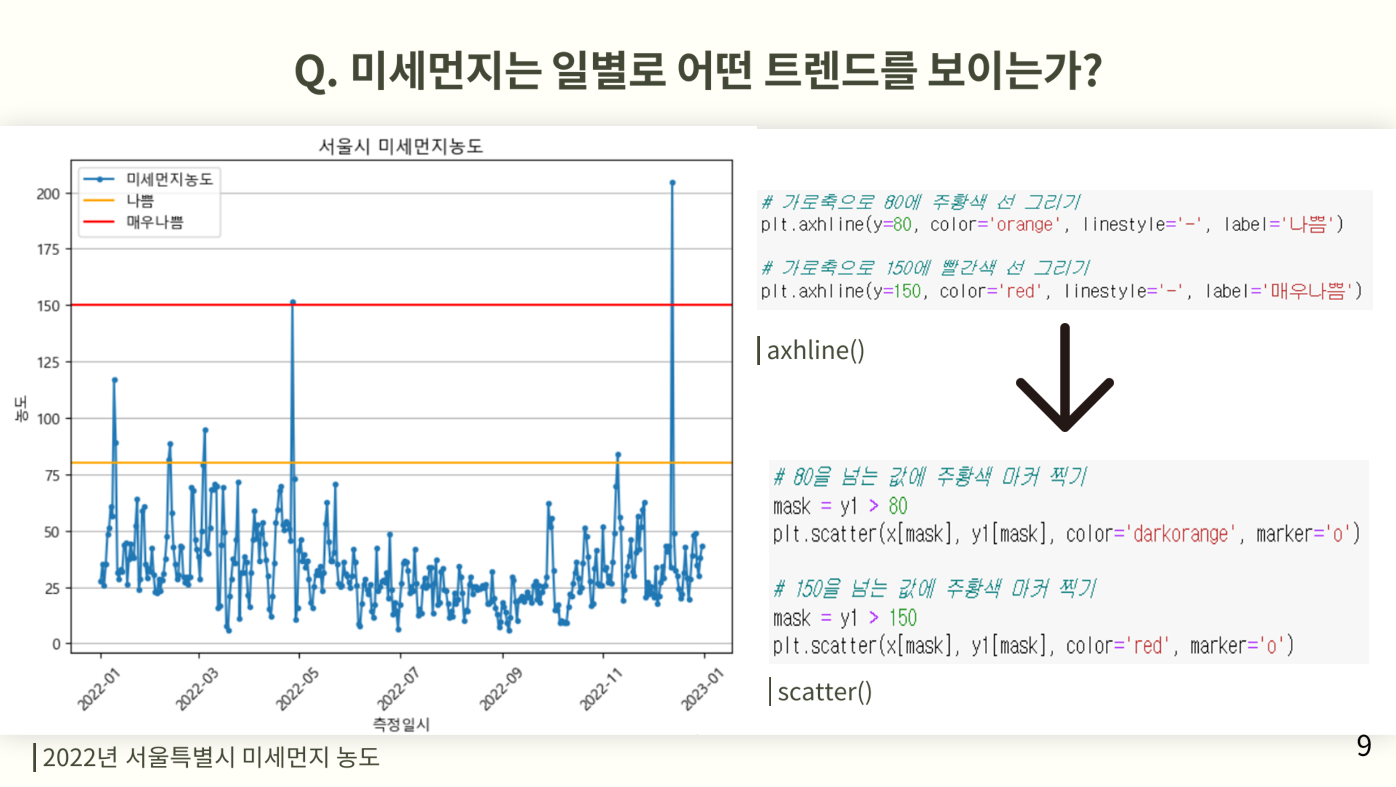
미세먼지 기준에서 나쁨과 매우나쁨의 농도기준에 주황색과 빨간색으로 가로선을 그어서 그 이상에 위치한 날이 얼마나 있는지 시각화하기위해 가로선을 긋는다.
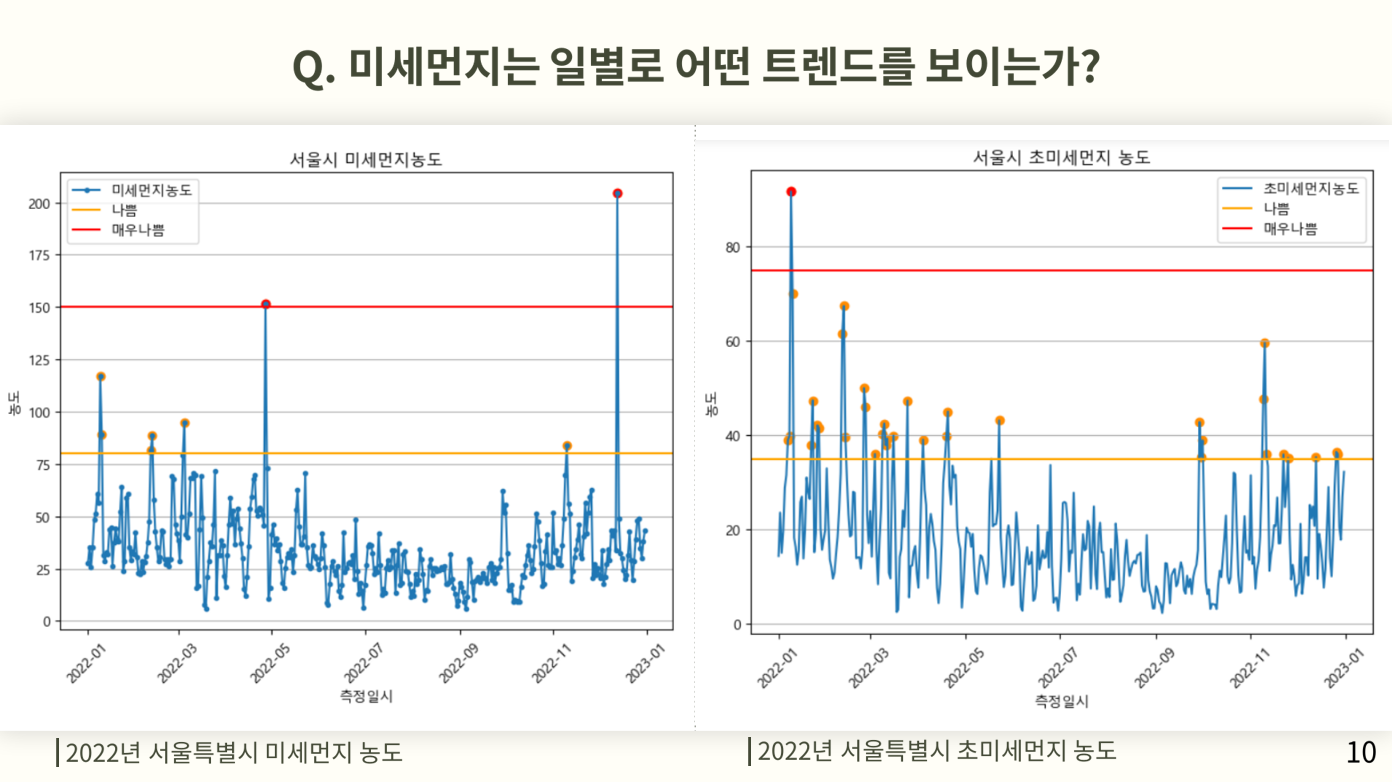
그리고 넘어간 점에 그 기준에 맞는 주황색과 빨간색으로 마커를찍어서 좀더 한눈에 알 수 있도록 시각화를 진행한다. 미세먼지는 몇 안되지만 초미세먼지의 경우는 다량의 점이 보이는 것을 알 수 있는데 이를 통해 결론을 도출한다.

첫번째 질문으로 정했던 미세먼지는 일별로 어떤 트렌드를 보이는가에 대한 대답으로 서울은 미세먼지보다 초미세먼지에 의한 오염이 더 심하다 라는 결론이 나온다. 우리가 정했던 기준은 나쁨 기준 이상이었던 날의 수로 정했기 때문에 미세먼지보다는 초미세먼지가 주황, 빨강 마커의 홧수가 많았으므로 미세먼지보다 초미세먼지에 의한 오염이 더 심하다는 결론을 도출 할 수 있다.
📌계절적 편차가 존재하는가?
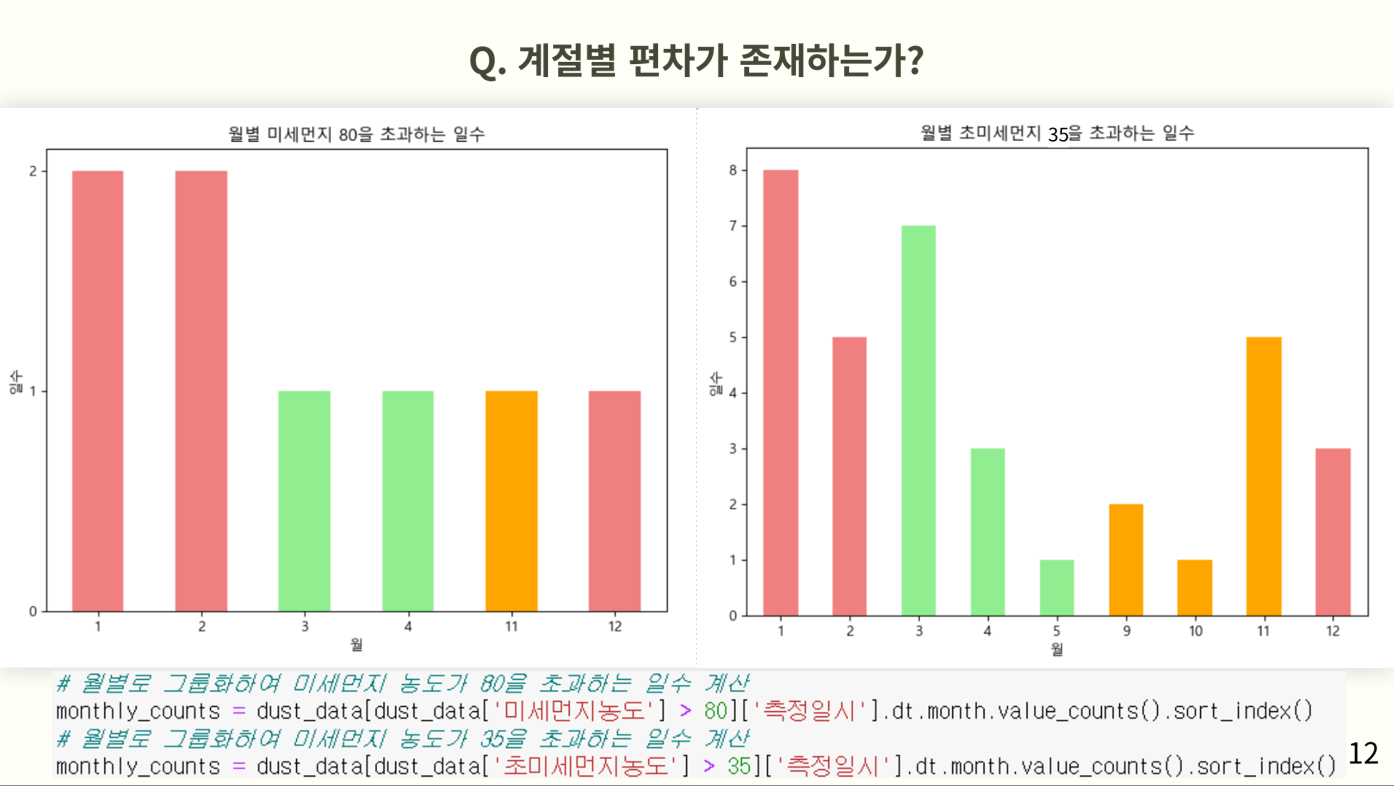
다음으로 계절적 편차가 존재하는지에 대한 질문의 결론을 도출하기 위해 분석을 진행해보자. 앞의 선그래프에서 주황 가로선을 넘어간 날을 월별로 분류하여 정리한 값에 막대그래프를 이용해 시각화하였다. 한눈에 보기위해 계절별로 색상을 다르게 하였고, 빨강이 겨울, 초록이 봄, 주황이 가을을 의미하는 색상으로 정했다.
여름은 한번의 미세먼지 나쁨농도 이상이었던 날이 없었고, 대부분이 겨울에 위치하고 있다는 점을 알 수 있다.
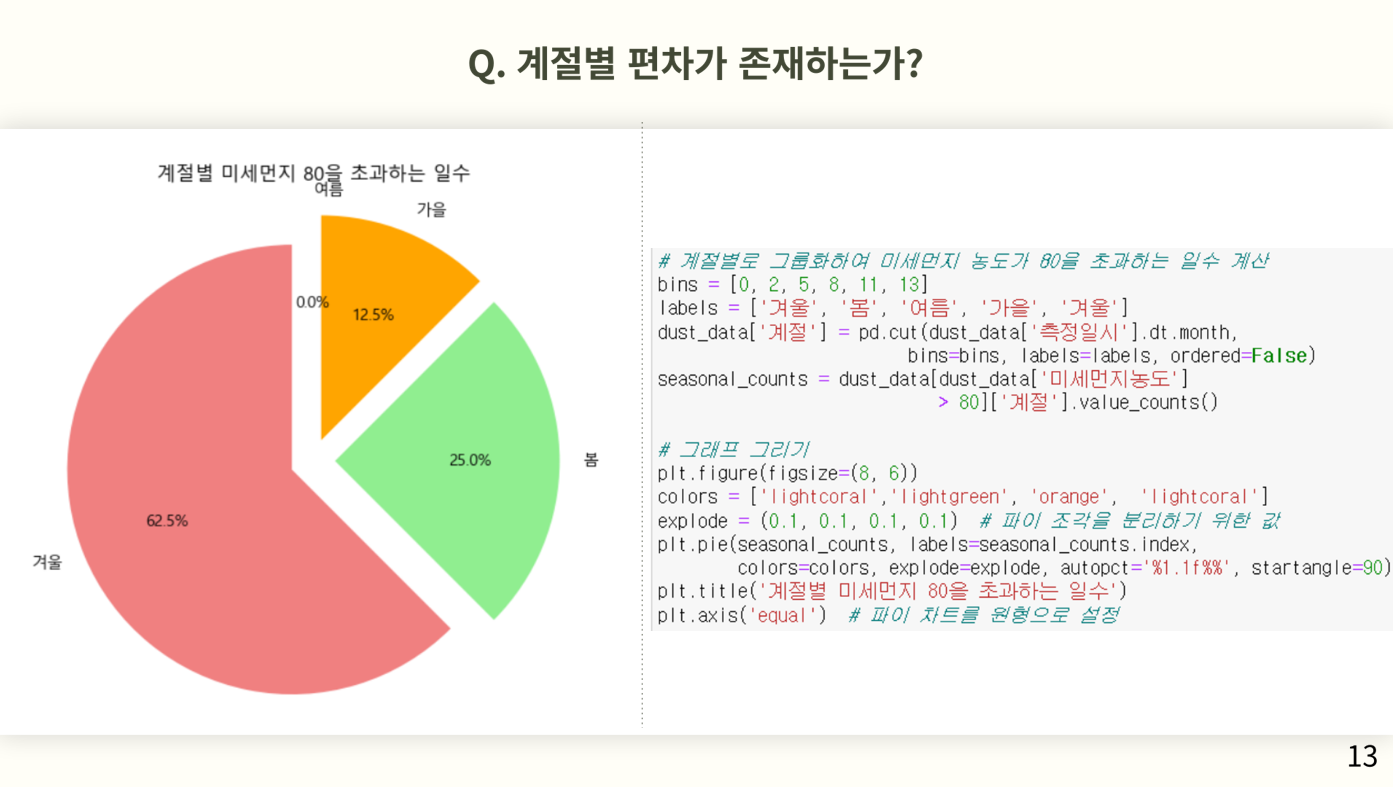
그렇다면 월별을 다시 계절별로 묶어서 나타내보자. 이는 막대그래프 대신 파이그래프를 사용하여 다른 계절에 비해 비중을 얼마나 차지하고 있는지를 나타내기 위함이다. 파이그래프를 사용했을때 겨울의 비중이 다른 계절보다 월등이 높음을 알 수 있다.
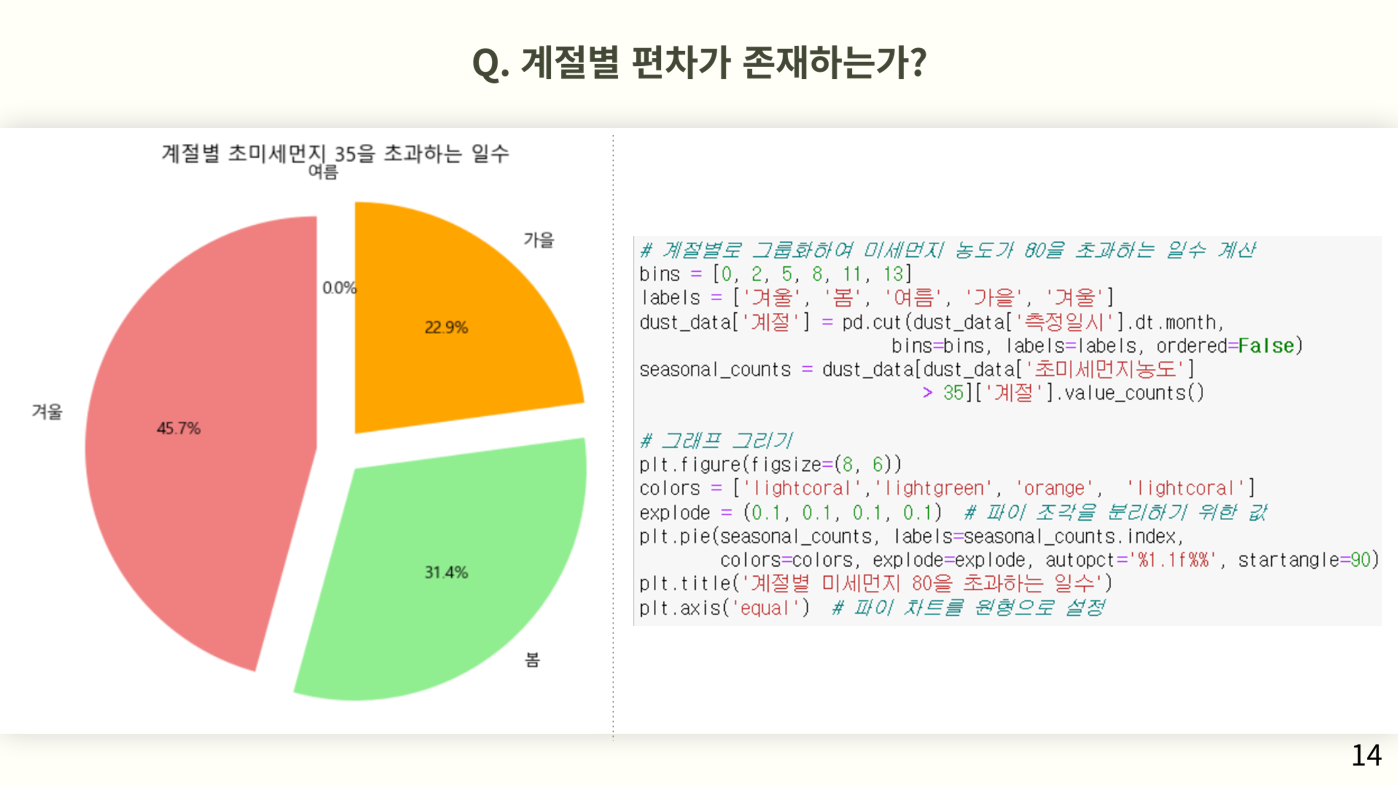
다음으로 초미세먼지에 대한 파이그래프이다. 초미세먼지 또한 35를 초과하는 일수가 여름은 0%고 겨울의 비중이 절반과 같다고 볼수있다. 이를 통해 알 수 있는 점은 미세먼지는 계절별 편차가 존재하고 여름보다 겨울에 더 심함을 알 수 있다.

미세먼지는 계절적 편차가 존재하는가? 라는 질문의 대답으로 나쁨이상인 일 수 는 겨울이 가장 많고 여름은 존재하지 않았다라는 결론을 도출할 수 있다. 그 이유로는 겨울에는 난방을 위해 화력발전소 등의 대기를 오염시킬 수 있는 등의 이유가 많고 여름에는 장마와 기류 속도등의 이유로 없다는 것을 유추해볼 수 있다.
📌지역별 편차가 존재하는가?
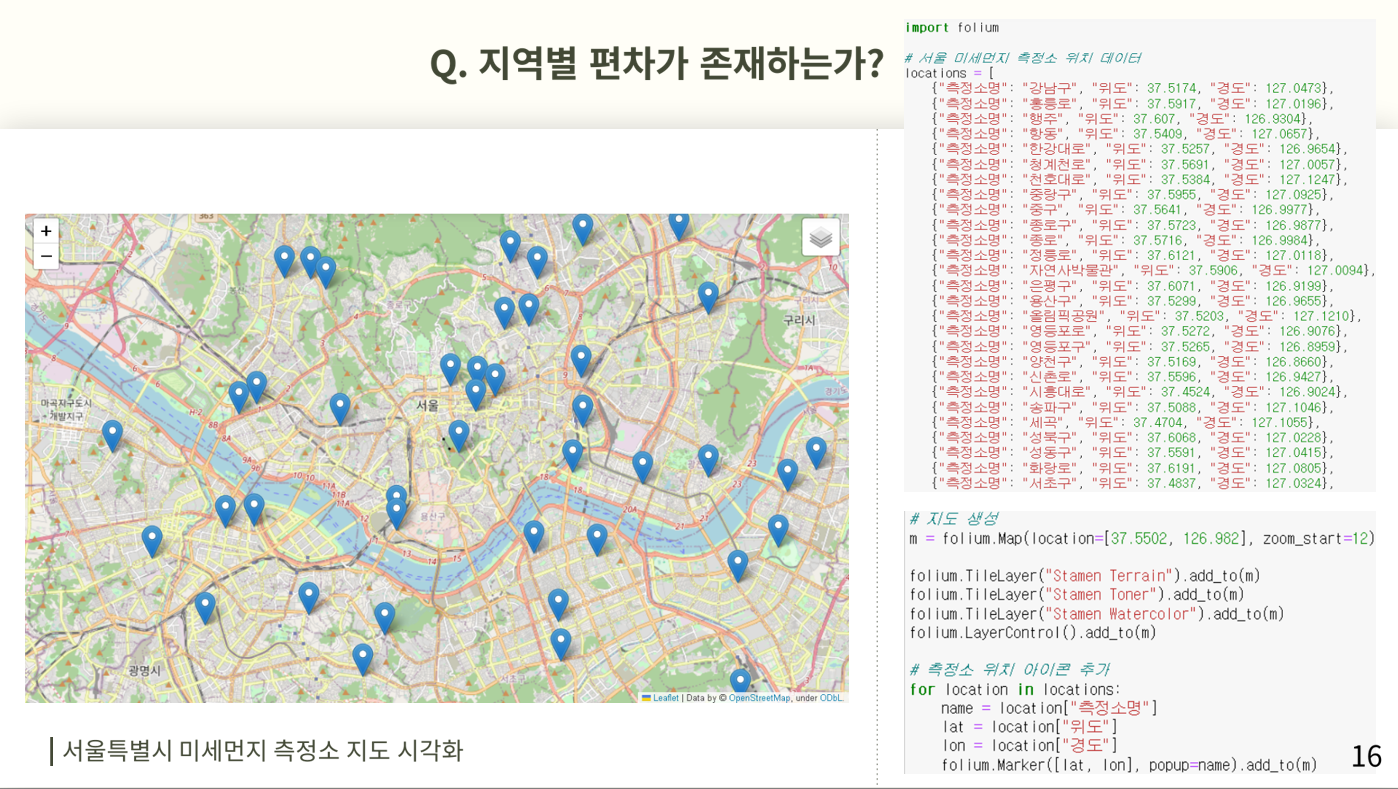
지역별 편차가 존재하는가에 대한 질문을 알아보기 위해 처음 원본데이터에서 존재했던 측정소별 농도를 사용할 텐데 측정소의 위치를 folium을 사용하여 지도에 표시하고 여러 지도 스킨 레이어를 사용하여 더 알아보기 쉽게 할 수 있도록 설정해준다.
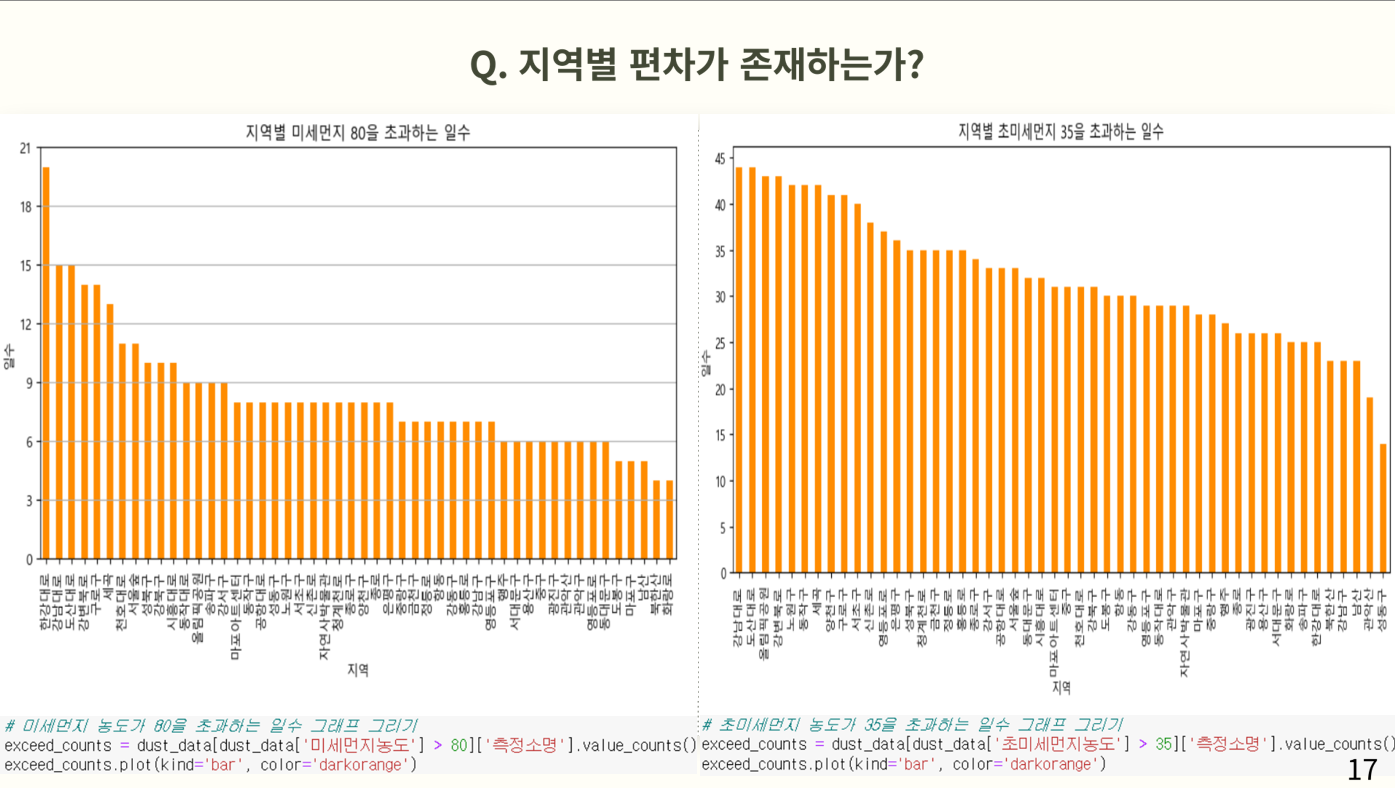
지역별 편차를 조사하기 위해 측정소별 미세먼지 80과 초미세먼지 35를 초과하는 일수를 막대그래프로 표시했다. 여기서 알 수 있는 점은 상위 부류에 대로변에 위치한 측정소가 많고, 하위 부류에 산에 위치한 측정소가 많다는 점이다. 이는 미세먼지와 초미세먼지가 모두 동일한 구조를 가지고 있다.
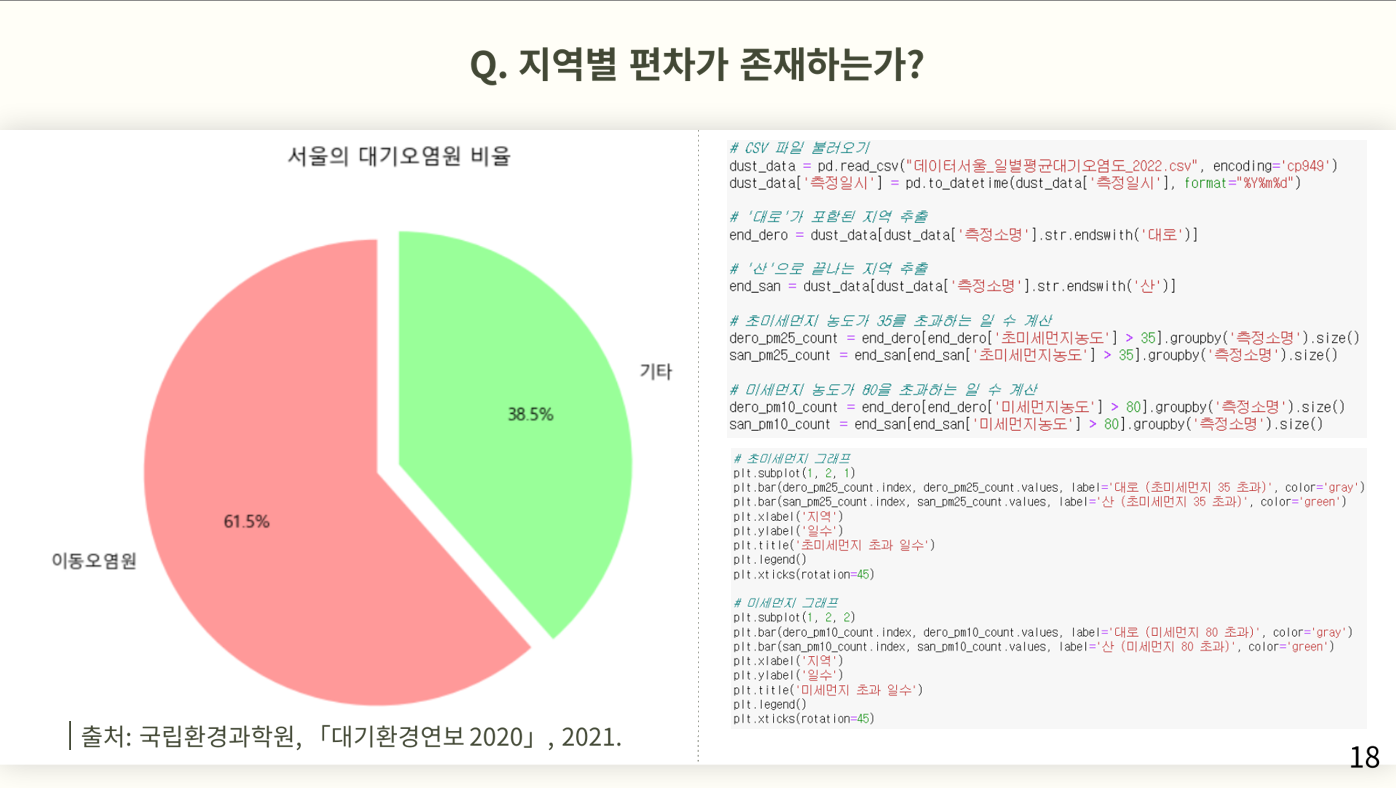
미세먼지의 대기오염은 그 원인을 분석했을때 이동오염원인 차량에 의한 오염발생률이 높다는 국립환경과학원의 분석을 파이그래프를 통해 알려준다. 대로변에 위치한 측정소의 미세먼지 나쁨초과일 수 가 많은 것에 대한 이유라는 가설을 세웠고, 이를 확인하기 위해 따로 분류하여 분석해봤다.
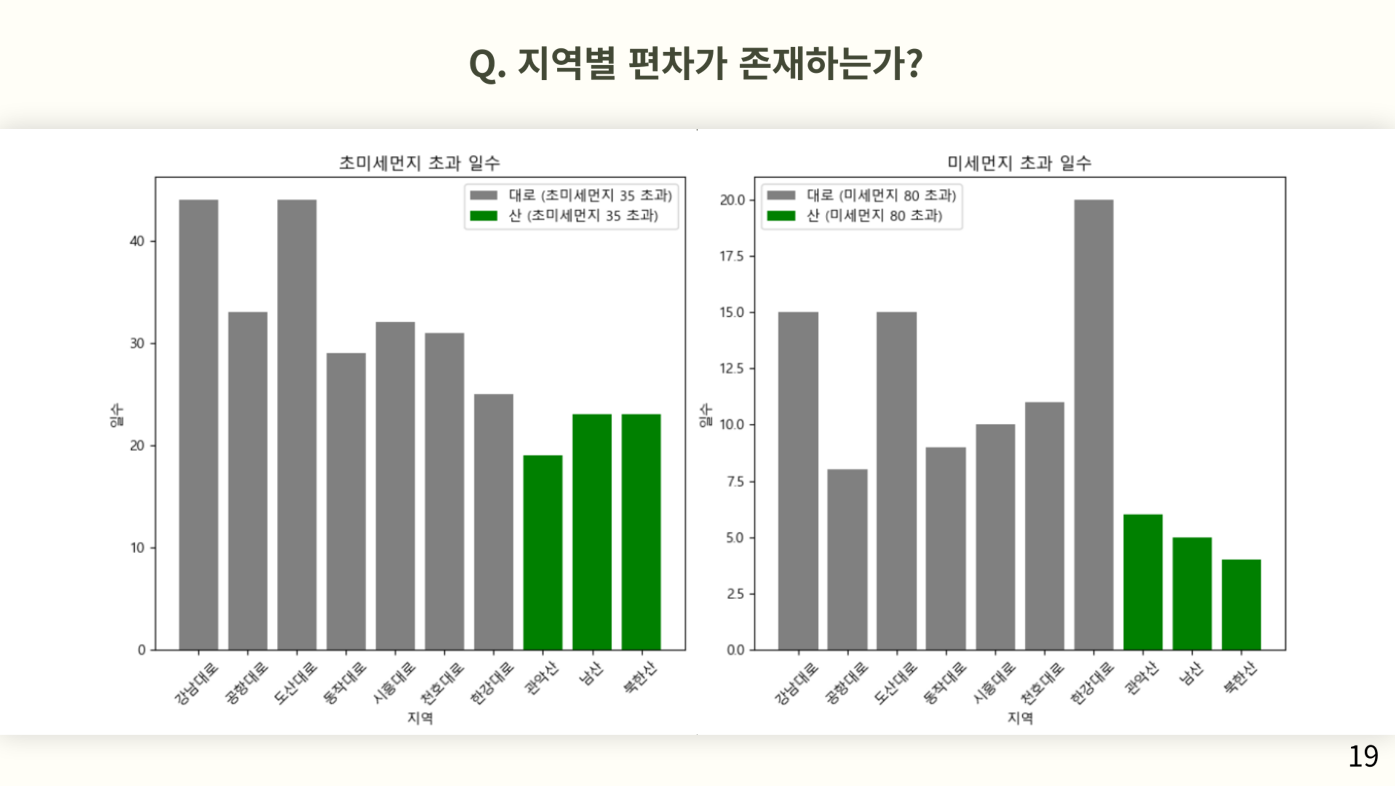
측정소 위치에 따른 지역적 편차를 알아보기 위해 대로로 끝나는 측정소와 산으로 끝나는 측정소의 나쁨 초과 일수를 따로 분류하여 막대그래프로 나타냈다. 조금더 보기 편하게하기 위해 대로는 회색으로, 산은 초록색으로 색상을 표시했다.
여기서 볼 수 있듯이 산에 비해 대로가 더 많은 초과일 수를 가지고 있는 것을 볼 수 있다.

미세먼지는 지역별 편차가 존재하는가에 대한 질문의 답으로 나쁨 이상의 일수는 대로에 위치한 측정소가 산에 위치한 측정소보다 더 많다는 것을 알 수 있었고 이로써 지벽별 편차가 존재한다는 것을 알 수 있다.
📌과거에 비해 감소하는가?
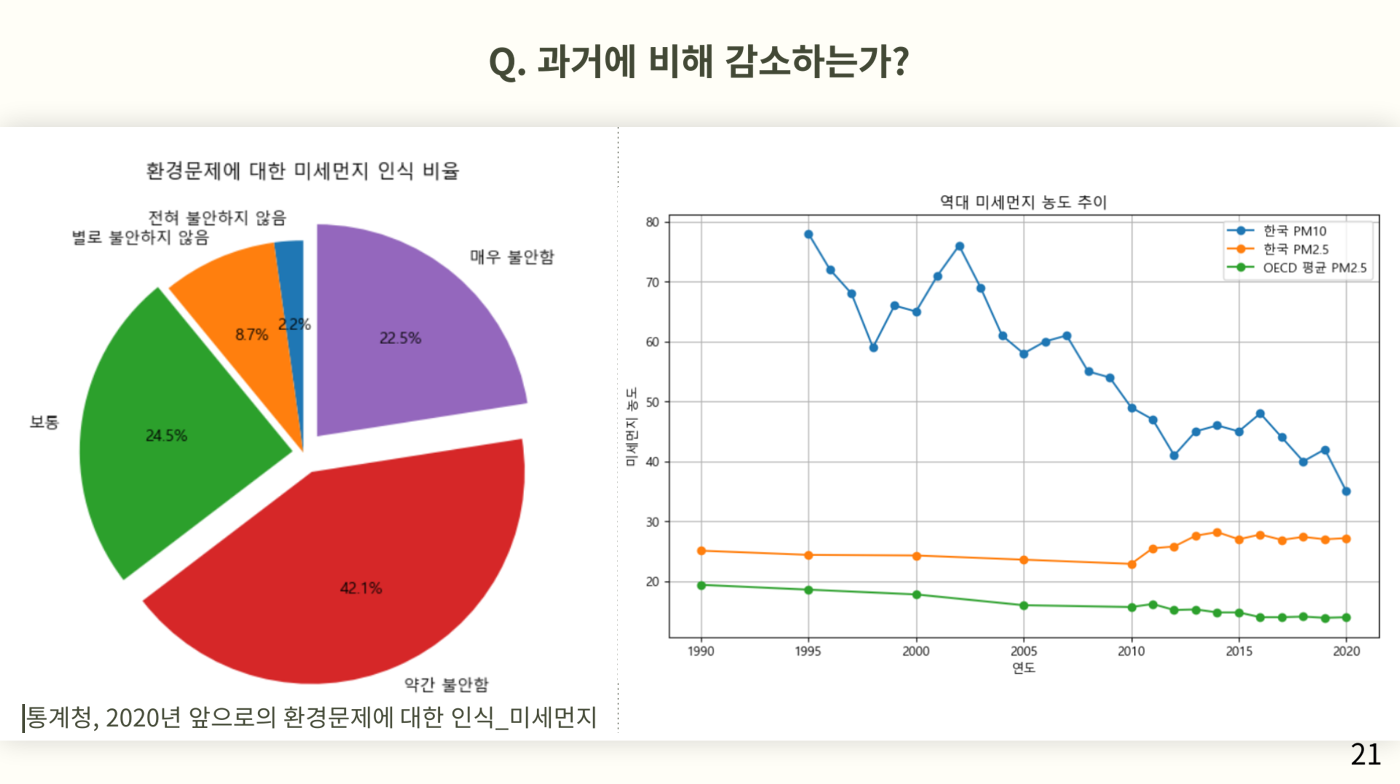
마지막으로 과거에 비헤 감소하는지 알아보기 위해 1990년도부터의 데이터를 분석하여 선그래프로 나타냈고, 미세먼지는 과거에 비해 줄어들었다는 그래프를 보며 경각심이 줄어들까봐 oecd평균 그래프를 활용하여 여전히 oecd평균에 비해 높은 수치를 가지고 있다는 점을 시각화하였다,

마지막으로 과거에 비해 감소하는가? 에 대한 질문의 답으로 미세먼지 농도는 줄어들었지만, 초미세먼지는 증가했고, 증가폭이 높지는 않지만 oecd평균에 비해 높은 수치를 가지고 있다라는 점을 시각화하였다.
📢마치며..
미세먼지 농도에 관련한 데이터분석을 하고 이를 시각화하여 결론을 나타내면서 어떤 결론을 내려야할지에 대한 고민을 가장 많이했다.
결론을 정하고 그결론을 보여주기 위해 분석하고 시각화하면 되기때문에 목적지를 정하는 것에서 많은 시간을 보냈다.
서울특별시가 아닌 전국으로 하고 싶었지만 전국적으로 할경우 지역적 특성때문에 미세먼지가 모두 각각의 특성을 지니기에 일관된 방식으로 분석하기가 어려웠다.
변수를 포함하여 하기엔 너무 지엽적인 것이 될 것같아서 서울특별시로 범위를 좁혔고, 전국으로 확대하여 분석해보고 싶은 마음이 있다. 이를 지도에 표기하여 나타낸다면 괜찮은 시각화가 나올것 같기 때문이다.
2개의 데이터 분석 프로젝트를 진행하면서 각 분야 별로 데이터 분석 방법에 차별화를 두어야 한다는 점을 알게 되었다. 환경 데이터는 시간에 따른 환경 변화에 주안점을 둔 통시적 시각화가 효과적이었다. 이에 반해 금융 데이터는 백테스팅 기법을 통해 과거 데이터를 활용해 분석하여 누적 수익률 및 성공률로 입증했을 때 효과적이라는 것을 알게 되었다. 데이터 분석 프로젝트를 통해 데이터 분석과 시각화에 전문성을 키울 수 있는 좋은 경험이 되었고, 각 데이터 분야별 특성을 고려해 데이터 분석 방법을 다르게 해야 효과적이라는 것을 깨닫는 경험이었다.
