
📢데이터분석 프로젝트
데이터분석 및 시각화 프로젝트를 진행함에 있어 이번은 분석편이다.
주제를 정했기에 데이터를 준비하고 분석하여 시각화하는 부분까지 진행해보자
데이터분석 프로젝트 - 인플레이션 발표편
데이터분석 프로젝트 - 미세먼지 발표편
데이터분석 프로젝트 - 인플레이션 분석편
데이터분석 프로젝트 - 미세먼지 분석편
데이터분석 프로젝트 - 주제선정
📢미세먼지 데이터 준비하기
대기 오염은 대기상에서 발생하는 환경오염이고 심각한 환경문제이다.
서울특별시의 대기오염은 얼마나 심각하고 어떻게 진행됐는지에 대해 알아보자
서울 열린데이터광장에서 일별 편균데이터오염도 데이터를 준비하였고, 이 데이터로 어떤 궁금증을 유발할 수 있을지 또, 풀어낼 수 있을지 생각해봤다.
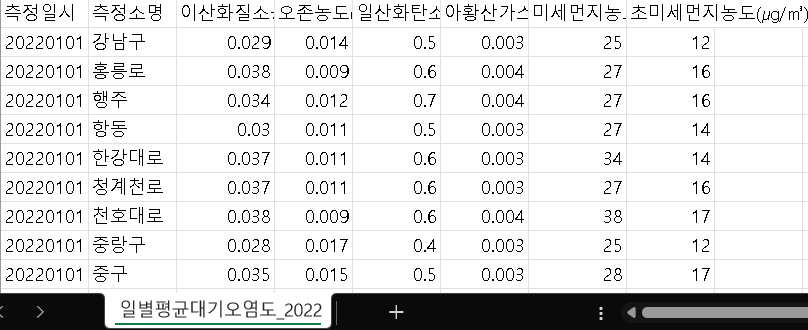
- 원본데이터의 구성은 필요한 이상의 내용이 들어가있었다.
미세먼지에 관한 데이터긴 하지만 대기오염에 관한 데이터파일이었기때문에 대기오염을 이루는 다른 물질의 농도까지 포함되어있었다.
그랬기에 이를 가공할 필요가 있었다.
import pandas as pd
# CSV 파일 불러오기
dust_data = pd.read_csv("데이터서울_일별평균대기오염도_2022.csv", encoding='cp949')
dust_data['측정일시'] = pd.to_datetime(dust_data['측정일시'], format="%Y%m%d")
dust_data
# 날짜별 미세먼지, 초미세먼지 평균 계산
seoul_daily_data = dust_data.groupby('측정일시')[['미세먼지농도', '초미세먼지농도']].mean()
print(seoul_daily_data)
# CSV 파일로 저장
seoul_daily_data.to_csv('서울특별시_일별_평균.csv', index=True, encoding='utf-8-sig')
seoul_daily_data
측정일시를 기준으로 미세먼지농도와 초미세먼지농도의 데이터만 따로 가공하였고, 이를 따로 csv파일에 저장했다.
여기서, 원본데이터에서는 일별-측정소별 농도가 기록되어있었는데 지금은 일별 농도가 필요했기에 📍groubby(), 📍mean()을 사용하여 일시기준으로 평균값을 내려 저장하였다.
📢가설 설정하기
데이터를 분석하고 시각화하기에 앞서 내가 어떤 결론을 도출하고, 시각화하여 듣는이에게 설명할 것인지에 대한 생각을 했다.
원하는 방향에 따라서 분석하는 방향도 시각화하는 기준도 다르기 때문이다.
먼저 일별 평균 대기오염도를 통해 무엇을 알 수 있을까라는 생각을 했다.
2022년도에 미세먼지 일별 농도는 어떤 트렌드를 보이는가에 대해 먼저 생각했다.
나빴는지, 좋았는지, 언제가 가장 좋았는지, 언제가 가장 나빴는지, 갈수록 좋아졌는지, 갈수록 나빠졌는지에 대해 의문이 들었다.
여기서 그럼 계절에 따라서 편차가 있는지에 대한 의문이 들었다.
어느 계절이 제일 안좋은지, 어느 계절이 제일 좋은지를 알 수 있을 것이다.
처음 데이터를 가공하기 전 측정소마다 농도가 있었는데 측정소끼리의 농도의 차이는 없을까? 라는 생각이 들었다.
그리고 연도별로 종합하여 미세먼지는 갈수록 나빠지고 있는 것인지?
아니면 정책의 방향에 따라 갈수록 줄어들고 있는 것인지? 에 대한 의문도 들었다.
그래서 4가지 가설을 세웠다.
- 미세먼지는 일별로 어떤 트렌드를 보이는가?
- 미세먼지는 계절적 편차가 존재하는가?
- 미세먼지는 지역별 편차가 존재하는가?
- 미세먼지는 과거에 비해 감소하는가?
그럼 이에 대해 하나씩 데이터를 분석하여 알아보도록 하자.
📢데이터 분석 및 시각화
📌일별로 어떤 트렌드를 보이는가?
📍미세먼지
# CSV 파일 불러오기
dust_data = pd.read_csv("서울특별시_일별_평균.csv", encoding='utf-8')
dust_data['측정일시'] = pd.to_datetime(dust_data['측정일시'], format="%Y년 %m월 %d일")
plt.figure(figsize=(8, 6))
# x축: 측정일시, y축: 미세먼지농도
x = dust_data['측정일시']
y1 = dust_data['미세먼지농도']
# 그래프 그리기
plt.plot(x, y1, label='미세먼지농도',marker='.')
# 가로축으로 80에 주황색 선 그리기
plt.axhline(y=80, color='orange', linestyle='-', label='나쁨')
# 가로축으로 150에 빨간색 선 그리기
plt.axhline(y=150, color='red', linestyle='-', label='매우나쁨')
# 80을 넘는 값에 주황색 마커 찍기
mask = y1 > 80
plt.scatter(x[mask], y1[mask], color='darkorange', marker='o')
# 150을 넘는 값에 주황색 마커 찍기
mask = y1 > 150
plt.scatter(x[mask], y1[mask], color='red', marker='o')
plt.grid(True, axis='y')
plt.xlabel('측정일시')
plt.ylabel('농도')
plt.title('서울시 미세먼지농도')
plt.legend()
plt.xticks(rotation=45) # x축 눈금 라벨 회전
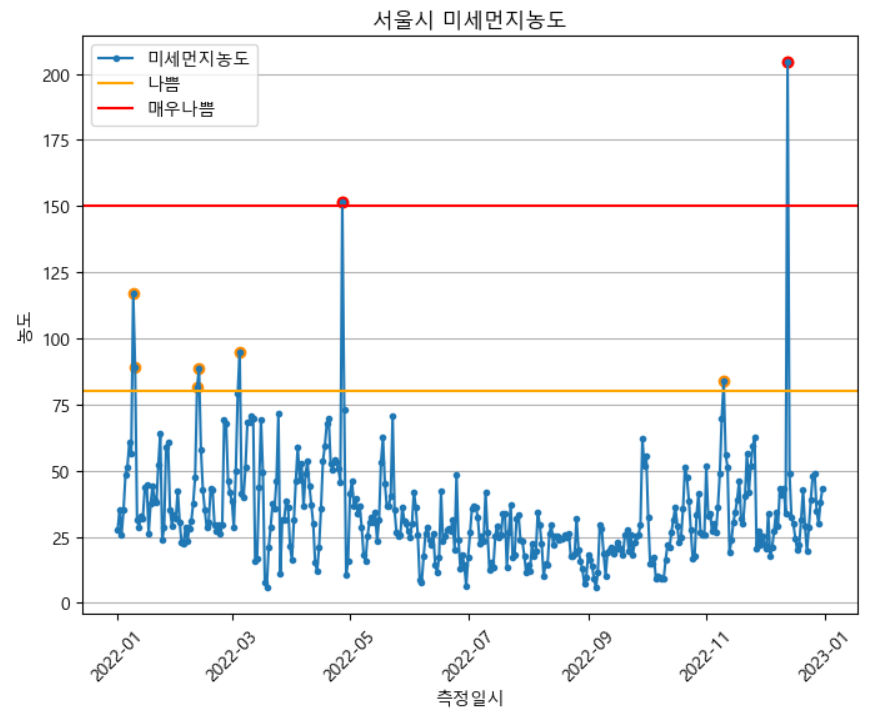
plt.show()📍axhline()
미세먼지의 나쁨과 매우나쁨에 주황색과 빨간색으로 가로선을 그어준다.
보기에 한눈에 어디가 나쁨 농도 이상인지 구별하기 쉽다.
📍scatter()
scatter() 함수를 사용하여 조건을 만족하는 곳에 색을 마커로 찍어준다
나쁨지수 위에는 주황색으로 매우나쁨지수 위에는 빨간색을 칠해주면서 한눈에 보기 편하게 시각화해준다.
결국 목적은 듣는이, 보는이가 결론을 이해하기 편하게 함이라는 것을 명심해야한다.
초미세먼지 역시 같은 방법으로 초미세먼지 농도에 맞추어 표시해준다.
📍초미세먼지
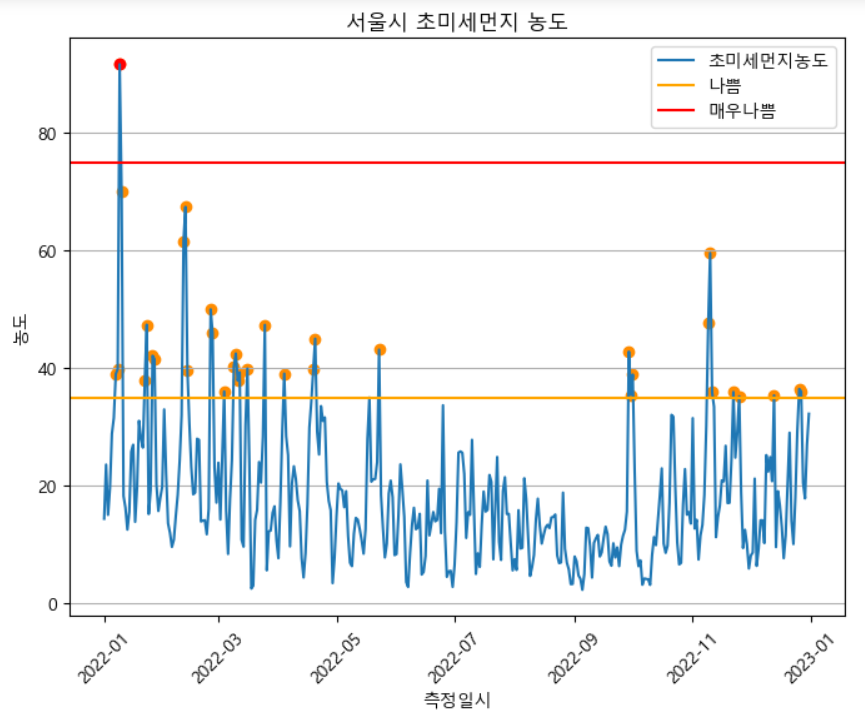
# CSV 파일 불러오기
dust_data = pd.read_csv("서울특별시_일별_평균.csv", encoding='utf-8')
dust_data['측정일시'] = pd.to_datetime(dust_data['측정일시'], format="%Y년 %m월 %d일")
plt.figure(figsize=(8, 6))
# x축: 측정일시, y축: 초미세먼지농도
x = dust_data['측정일시']
y1 = dust_data['초미세먼지농도']
# 그래프 그리기
plt.plot(x, y1, label='초미세먼지농도')
# 가로축으로 35에 주황색 선 그리기
plt.axhline(y=35, color='orange', linestyle='-', label='나쁨')
# 가로축으로 75에 빨간색 선 그리기
plt.axhline(y=75, color='red', linestyle='-', label='매우나쁨')
# 35을 넘는 값에 주황색 마커 찍기
mask = y1 > 35
plt.scatter(x[mask], y1[mask], color='darkorange', marker='o')
# 75을 넘는 값에 빨간색 마커 찍기
mask = y1 > 75
plt.scatter(x[mask], y1[mask], color='red', marker='o')
plt.grid(True, axis='y')
plt.xlabel('측정일시')
plt.ylabel('농도')
plt.title('서울시 초미세먼지 농도')
plt.legend()
plt.xticks(rotation=45) # x축 눈금 라벨 회전
plt.show()두 시각화한 그래프를 미루어 볼때 한눈에 파악할 수 있는 트렌드는 서울특별시의 대기오염은 미세먼지의 영향보다 초미세먼지에 의한 오염이 더 심하다는 것을 알 수 있다.
📌계절적으로는 어떨까
그렇다면 두번째 의문에 답해보자
두번째 가설에 답하려면 미세먼지와 초미세먼지의 초과 일수를 계절별로 나누어 보면 확연히 보일 것이다.
📍미세먼지
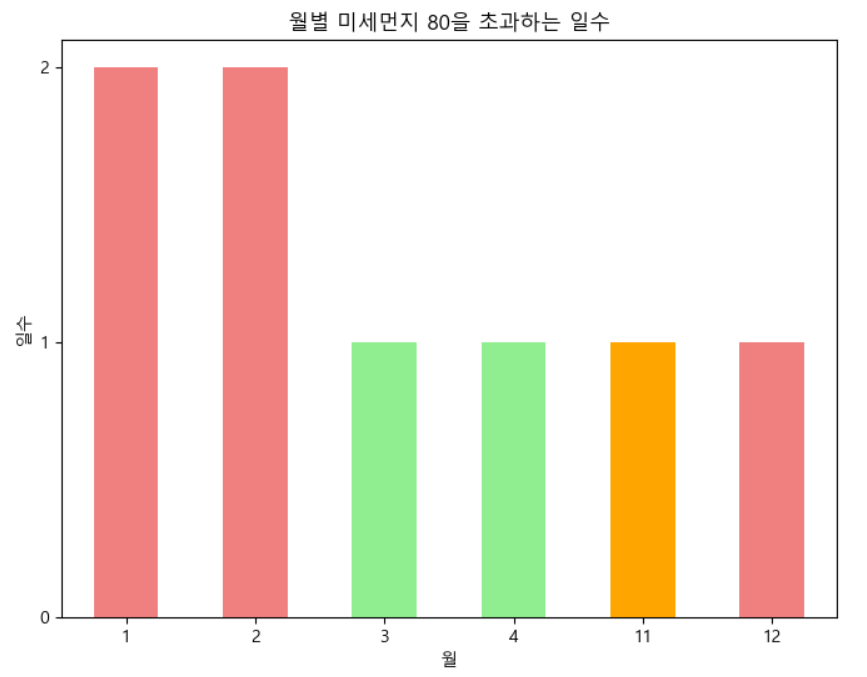
# 월별로 그룹화하여 미세먼지 농도가 80을 초과하는 일수 계산
monthly_counts = dust_data[dust_data['미세먼지농도'] > 80]['측정일시'].dt.month.value_counts().sort_index()
# 그래프 그리기
plt.figure(figsize=(8, 6))
colors = ['lightcoral', 'lightcoral', 'lightgreen', 'lightgreen','orange', 'lightcoral']
monthly_counts.plot(kind='bar', color=colors)
plt.xlabel('월')
plt.ylabel('일수')
plt.title('월별 미세먼지 80을 초과하는 일수')
plt.xticks(rotation=0) # x축 눈금 라벨 회전
plt.yticks(np.arange(0, monthly_counts.max()+1, 1)) # y축 눈금 설정
#plt.grid(axis='y')
plt.show()📍dust_data['미세먼지농도'] > 80: '미세먼지농도' 열에서 80보다 큰 값을 가지는 행을 필터링해주어서 나쁨농도 이상의 일수를 필터링 해준다.
📍dust_data[]: 미세먼지 농도가 80보다 큰 데이터만 선택하여 남겨준다.
📍['측정일시'].dt.month: 선택된 데이터를 측정일시 기준으로 월별로 선택하여 분류해준다.
📍value_counts(): 각 월에서 기준을 만족하는 값만 선별하여 카운트해준다.
📍sort_index(): 결과를 월별로 정렬해준다.
그리고 계절구분으로 색갈을 다르게 줘서 시각적으로 계절에 따라 묶일 수 있도록 조건을 달아준다.
📍초미세먼지
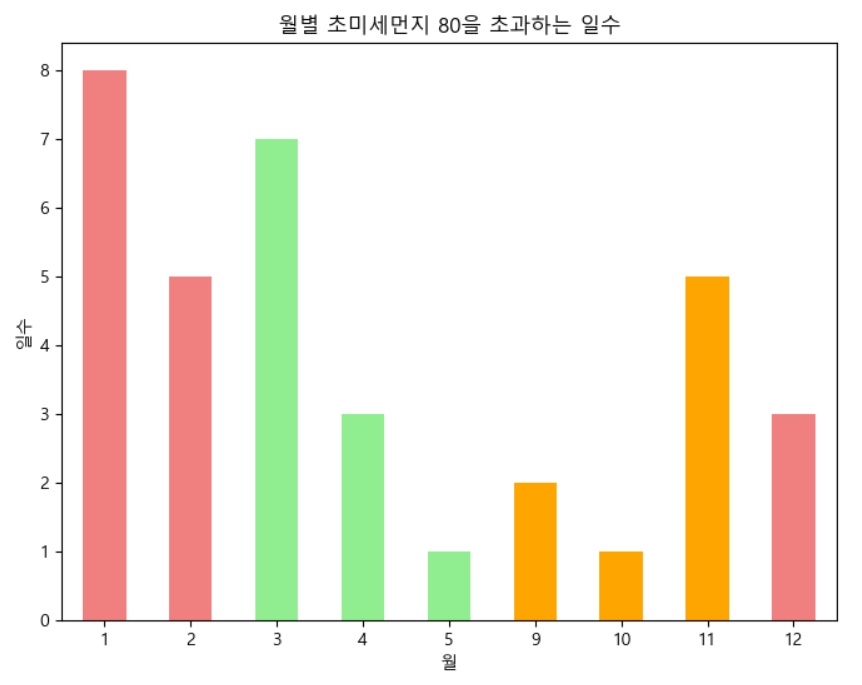
# 월별로 그룹화하여 미세먼지 농도가 35을 초과하는 일수 계산
monthly_counts = dust_data[dust_data['초미세먼지농도'] > 35]['측정일시'].dt.month.value_counts().sort_index()
# 그래프 그리기
plt.figure(figsize=(10, 6))
colors = ['lightcoral', 'lightcoral', 'lightgreen','lightgreen',
'lightgreen','orange','orange','orange', 'lightcoral']
monthly_counts.plot(kind='bar', color=colors)
plt.xlabel('월')
plt.ylabel('일수')
plt.title('월별 초미세먼지 35을 초과하는 일수')
plt.xticks(rotation=0) # x축 눈금 라벨 회전
plt.yticks(np.arange(0, monthly_counts.max()+1, 1)) # y축 눈금 설정
#plt.grid(axis='y')
plt.show()초미세먼지도 같은 방식으로 설정해준다.
- 여기까지 만으로도 시각적으로 보는 것은 편하다. 하지만 월별로 묶은 지금 상태에서 계절별로 묶는다면 더 계절적 편차를 알아보기에 편리할 것 같다.
📍미세먼지
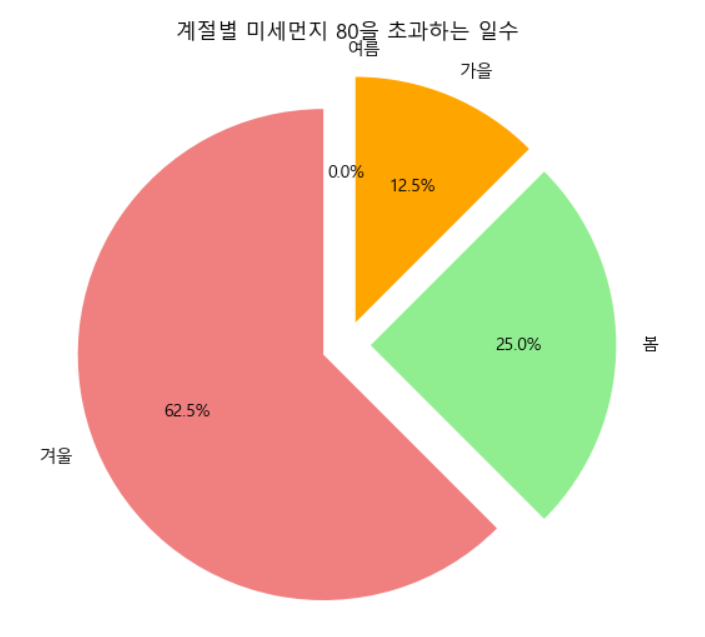
# 계절별로 그룹화하여 미세먼지 농도가 80을 초과하는 일수 계산
bins = [0, 2, 5, 8, 11, 13]
labels = ['겨울', '봄', '여름', '가을', '겨울']
dust_data['계절'] = pd.cut(dust_data['측정일시'].dt.month,
bins=bins, labels=labels, ordered=False)
seasonal_counts = dust_data[dust_data['미세먼지농도']
> 80]['계절'].value_counts()
# 그래프 그리기
plt.figure(figsize=(8, 6))
colors = ['lightcoral','lightgreen', 'orange', 'lightcoral']
explode = (0.1, 0.1, 0.1, 0.1) # 파이 조각을 분리하기 위한 값
plt.pie(seasonal_counts, labels=seasonal_counts.index,
colors=colors, explode=explode, autopct='%1.1f%%', startangle=90)
plt.title('계절별 미세먼지 80을 초과하는 일수')
plt.axis('equal') # 파이 차트를 원형으로 설정
plt.show()📍bins = [0, 2, 5, 8, 11, 13]: 계절을 구분하기 위한 구간(bin)을 정의한다.
📍labels = ['겨울', '봄', '여름', '가을', '겨울']: 각 구간에 대응하는 레이블을 정의하여 매핑해준다.
(0-2는 겨울, 2-5는 봄, 5-8은 여름, 8-11은 가을, 11-13은 겨울)📍pd.cut(dust_data['측정일시'].dt.month, bins=bins, labels=labels, ordered=False): pd.cut() 함수를 사용하여 월별 데이터를 구간에 맞게 레이블로 변환해준다.
📍초미세먼지
- 같은 방법으로 초미세먼지도 파이차트화해준다.
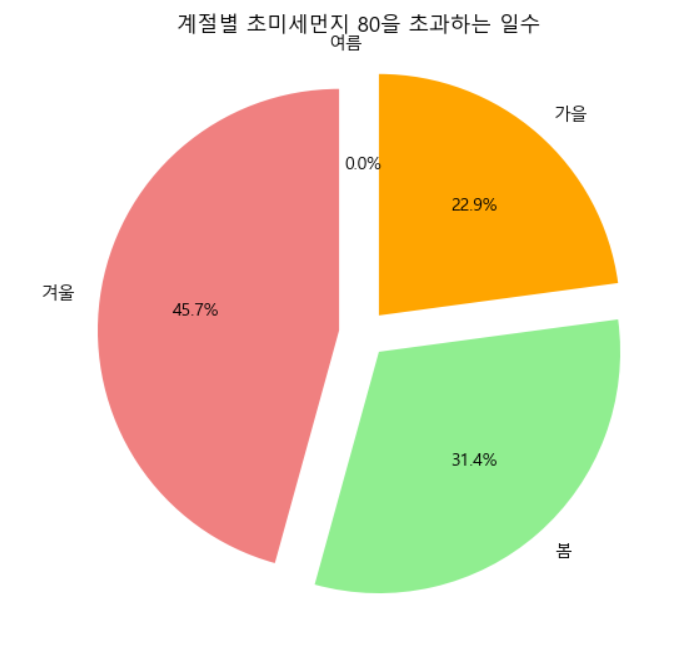
# 계절별로 그룹화하여 초미세먼지 농도가 35을 초과하는 일수 계산
bins = [0, 2, 5, 8, 11, 13]
labels = ['겨울', '봄', '여름', '가을', '겨울']
dust_data['계절'] = pd.cut(dust_data['측정일시'].dt.month, bins=bins, labels=labels, ordered=False)
seasonal_counts = dust_data[dust_data['초미세먼지농도'] > 35]['계절'].value_counts()
# 그래프 그리기
plt.figure(figsize=(8, 6))
colors = ['lightcoral','lightgreen', 'orange', 'lightcoral']
explode = (0.1, 0.1, 0.1, 0.1) # 파이 조각을 분리하기 위한 값
plt.pie(seasonal_counts, labels=seasonal_counts.index, colors=colors, explode=explode, autopct='%1.1f%%', startangle=90)
plt.title('계절별 초미세먼지 35을 초과하는 일수')
plt.axis('equal') # 파이 차트를 원형으로 설정
plt.show()두 시각화한 그래프를 미루어 볼때 서울특별시의 대기가 가장 깨끗해지는 계절은 여름이라는 결과가 나온다. 그리고 가장 대기오염이 심한 계절은 겨울로 나오는데 이는 난방으로 인해 화석연료를 사용하기 때문인 것 같다.
📌측정소별 차이는 있을까?
- 데이터를 가공하기 전의 원래 데이터를 활용해보자
측정소마다의 나쁨지수 이상의 일수를 카운트하여 막대그래프화 해보자
📍미세먼지
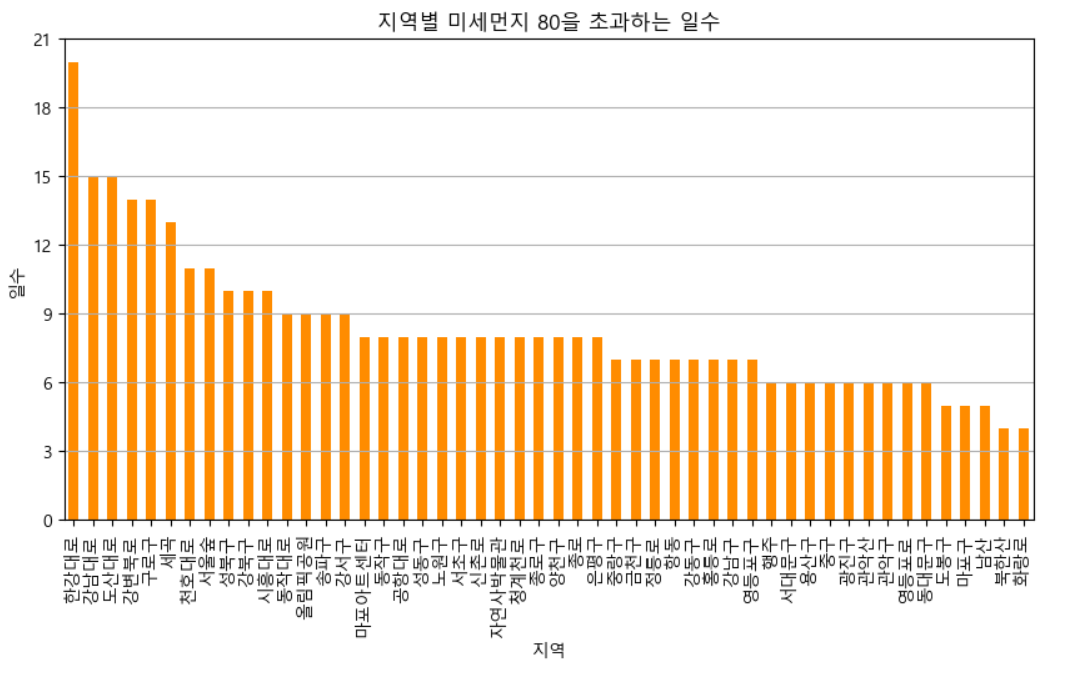
# CSV 파일 불러오기
dust_data = pd.read_csv("데이터서울_일별평균대기오염도_2022.csv", encoding='cp949')
dust_data['측정일시'] = pd.to_datetime(dust_data['측정일시'], format="%Y%m%d")
# 미세먼지 농도가 80을 초과하는 일수 그래프 그리기
exceed_counts = dust_data[dust_data['미세먼지농도'] > 80]['측정소명'].value_counts()
exceed_counts.plot(kind='bar', color='darkorange')
plt.xlabel('지역')
plt.ylabel('일수')
plt.title('지역별 미세먼지 80을 초과하는 일수')
plt.xticks(rotation=90) # x축 눈금 라벨 회전
plt.figure(figsize=(12, 5))
#plt.grid(axis='y')
plt.gca().yaxis.set_major_locator(plt.MaxNLocator(integer=True)) # y축 소수점 제거
plt.show()이번엔 가공데이터가 아닌 원본 데이터에서 필요한 정보만 사용해봤다.
각 측정소별로 dust_data['미세먼지농도'] > 80 가 넘는 횟수만 분석하고 kind='bar' 막대바 형식으로 시각화하였다.
📍초미세먼지
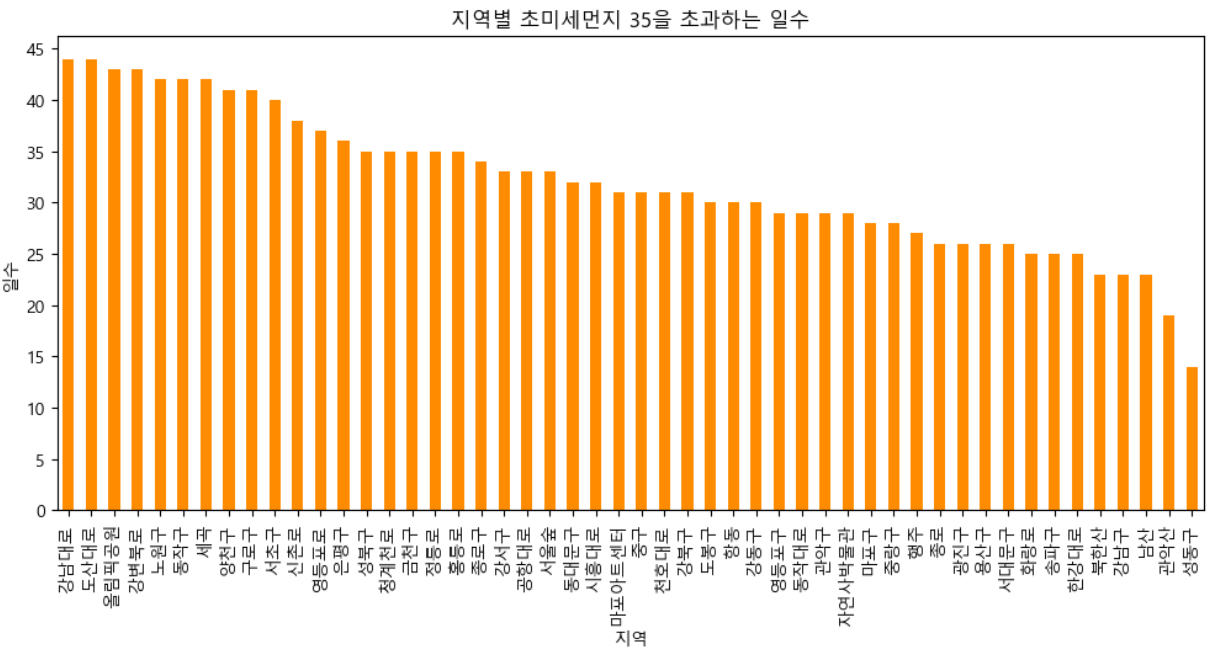
# CSV 파일 불러오기
dust_data = pd.read_csv("데이터서울_일별평균대기오염도_2022.csv", encoding='cp949')
dust_data['측정일시'] = pd.to_datetime(dust_data['측정일시'], format="%Y%m%d")
# 초미세먼지 농도가 35을 초과하는 일수 그래프 그리기
exceed_counts = dust_data[dust_data['초미세먼지농도'] > 35]['측정소명'].value_counts()
exceed_counts.plot(kind='bar', color='darkorange')
# 그래프 그리기
plt.figure(figsize=(12, 5))
plt.xlabel('지역')
plt.ylabel('일수')
plt.title('지역별 초미세먼지 35을 초과하는 일수')
plt.xticks(rotation=90) # x축 눈금 라벨 회전
#plt.grid(axis='y')
plt.gca().yaxis.set_major_locator(plt.MaxNLocator(integer=True)) # y축 소수점 제거
plt.show()초미세먼지도 같은 방식을 사용하여 막대그래프로 시각화하였다.
여기서 앞부분엔 대로가 많고 뒷부분엔 산이 많은 것을 발견하였다.
측정소가 위치한 곳에 따라서 농도차이가 있을까라는 의문을 품고 분석해봤다.
📍미세먼지, 초미세먼지
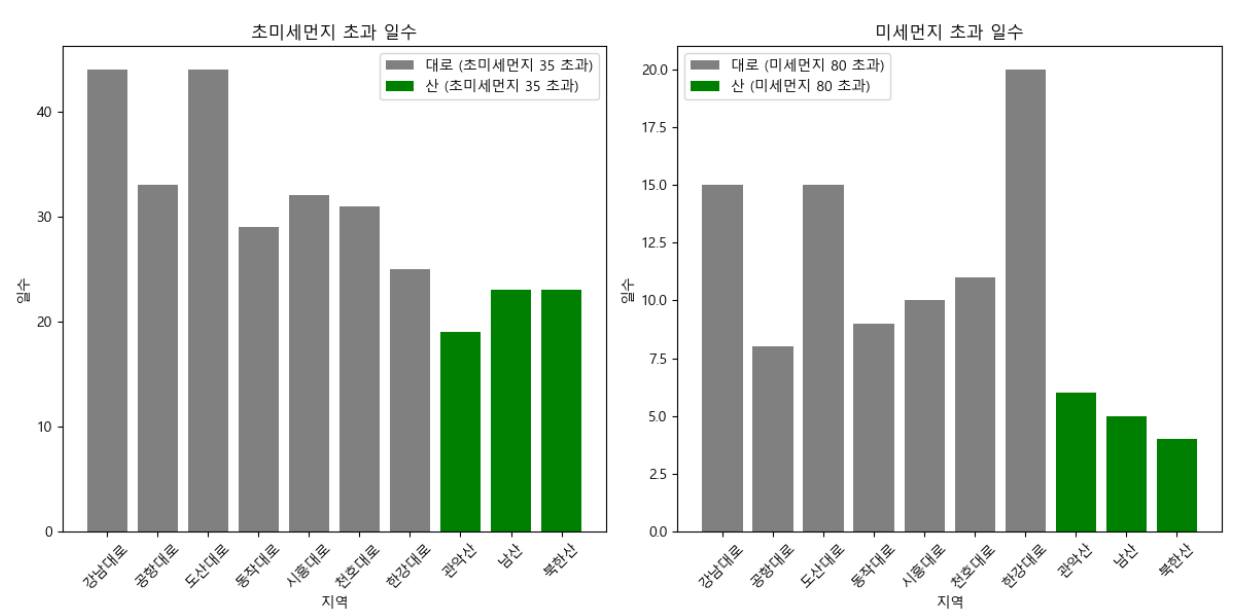
# '대로'가 포함된 지역 추출
end_dero = dust_data[dust_data['측정소명'].str.endswith('대로')]
# '산'으로 끝나는 지역 추출
end_san = dust_data[dust_data['측정소명'].str.endswith('산')]
# 초미세먼지 농도가 35를 초과하는 일 수 계산
dero_pm25_count = end_dero[end_dero['초미세먼지농도'] > 35].groupby('측정소명').size()
san_pm25_count = end_san[end_san['초미세먼지농도'] > 35].groupby('측정소명').size()
# 미세먼지 농도가 80을 초과하는 일 수 계산
dero_pm10_count = end_dero[end_dero['미세먼지농도'] > 80].groupby('측정소명').size()
san_pm10_count = end_san[end_san['미세먼지농도'] > 80].groupby('측정소명').size()
# 시각화
plt.figure(figsize=(12, 6))
# 초미세먼지 그래프
plt.subplot(1, 2, 1)
plt.bar(dero_pm25_count.index, dero_pm25_count.values, label='대로 (초미세먼지 35 초과)', color='gray')
plt.bar(san_pm25_count.index, san_pm25_count.values, label='산 (초미세먼지 35 초과)', color='green')
plt.xlabel('지역')
plt.ylabel('일수')
plt.title('초미세먼지 초과 일수')
plt.legend()
plt.xticks(rotation=45)
# 미세먼지 그래프
plt.subplot(1, 2, 2)
plt.bar(dero_pm10_count.index, dero_pm10_count.values, label='대로 (미세먼지 80 초과)', color='gray')
plt.bar(san_pm10_count.index, san_pm10_count.values, label='산 (미세먼지 80 초과)', color='green')
plt.xlabel('지역')
plt.ylabel('일수')
plt.title('미세먼지 초과 일수')
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.showend_dero = dust_data[dust_data['측정소명'].str.endswith('대로')]
end_san = dust_data[dust_data['측정소명'].str.endswith('산')]
측정소 이름에서 대로가 포함된 단어와 산이 포함된 단어를 따로 추출했다.
원래는 포함된 단어로 했었는데 도산대로의 경우 산도 포함하고 대로도 포함하기 때문에 endswith()를 사용하여 끝나는 단어로 수정하였다.plt.bar(dero_pm10_count.index, dero_pm10_count.values, label='대로 (미세먼지 80 초과)', color='gray')
plt.bar(san_pm10_count.index, san_pm10_count.values, label='산 (미세먼지 80 초과)', color='green')
막대그래프를 만들때 도로의 경우에 도로색상인 그레이색상을 넣어줬고, 산의 경우에는 산을 의미하는 초록색을 넣어서 조금더 구분이 편하게 되도록 시각화하였다.
- 이로써 측정소마다 농도에 차이가 있다는 점을 발견할 수 있었다.
산보다는 대로에 위치한 측정소에서 미세먼지, 초미세먼지 농도가 높게 나왔다.
📌과거에 비해 감소하는가?
그렇다면 과거에 비해 감소하고 있는지 증가하고 있는지에 대한 물음에 대답해보자
먼저 2022 서울특별시의 일별 대기오염 농도라는 데이터를 사용하고 있기 때문에 연별로 정리된 데이터를 활용해야했다.
연보로 구성되어 있었기 때문에 csv파일을 받는 것은 어려웠고, 각 연데이터를 직접 데이터프레임화 시켜서 만들었다.
📍미세먼지, 초미세먼지
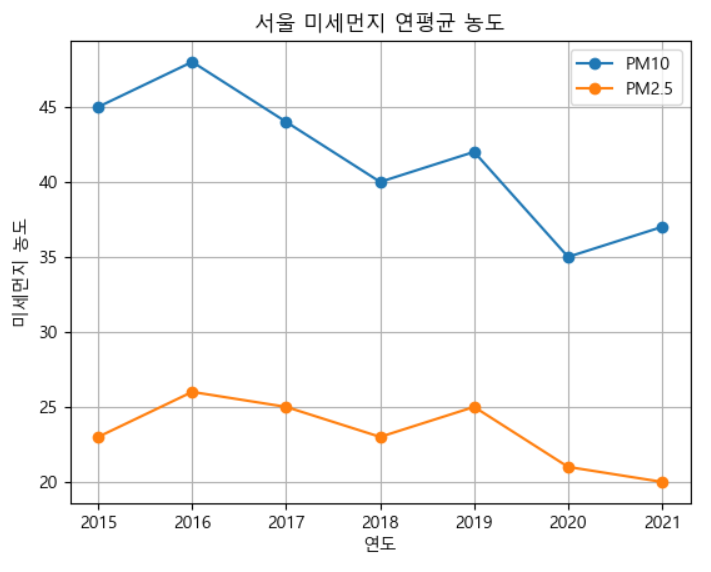
# 연도와 미세먼지 데이터
years = [2015, 2016, 2017, 2018, 2019, 2020, 2021]
pm10_dust_levels = [45, 48, 44, 40, 42, 35, 37]
pm25_dust_levels = [23, 26, 25, 23, 25, 21, 20]
# 그래프 생성
plt.figure(figsize=(10, 6))
plt.plot(years, pm10_dust_levels, marker='o', label='PM10')
plt.plot(years, pm25_dust_levels, marker='o', label='PM2.5')
plt.title('서울 미세먼지 연평균 농도')
plt.xlabel('연도')
plt.ylabel('미세먼지 농도')
plt.grid(True)
plt.legend()
plt.show()
📍미세먼지, 초미세먼지
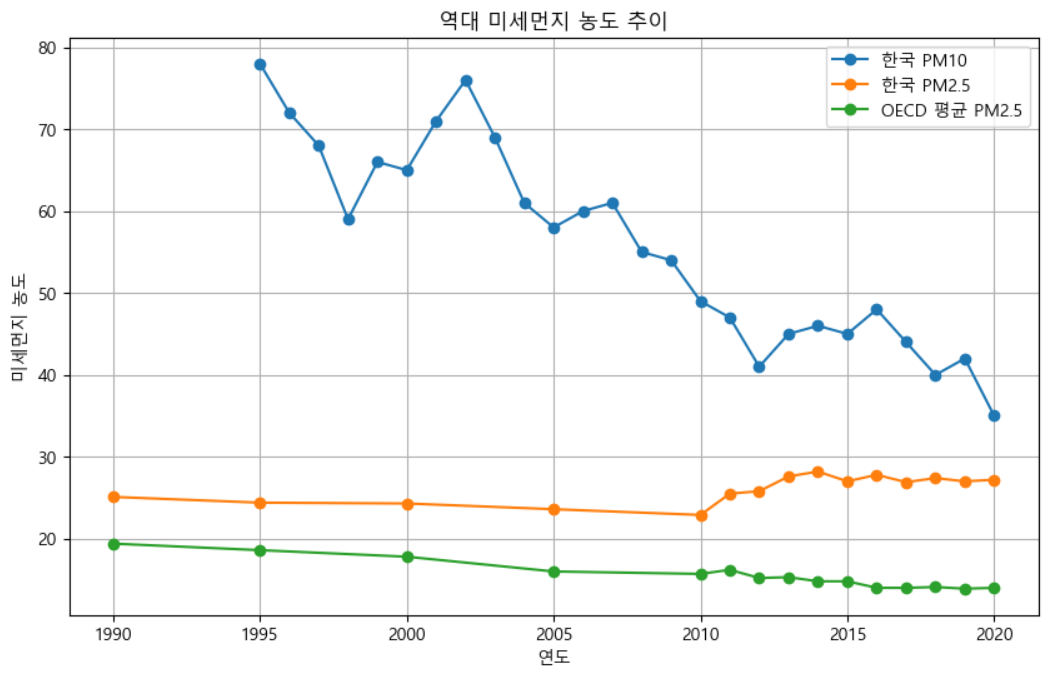
# 한국 PM2.5 데이터
years_korea_pm25 = [1990, 1995, 2000, 2005, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
pm25_korea = [25.1, 24.4, 24.3, 23.6, 22.9, 25.5, 25.8, 27.6, 28.2, 27.0, 27.8, 26.9, 27.4, 27.0, 27.2]
# OECD 평균 PM2.5 데이터
years_oecd_pm25 = [1990, 1995, 2000, 2005, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
pm25_oecd = [19.4, 18.6, 17.8, 16.0, 15.7, 16.2, 15.2, 15.3, 14.8, 14.8, 14.0, 14.0, 14.1, 13.9, 14.0]
years_korea_pm10 = [1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
pm10_korea = [78, 72, 68, 59, 66, 65, 71, 76, 69, 61, 58, 60, 61, 55, 54, 49, 47, 41, 45, 46, 45, 48, 44, 40, 42, 35]
# 그래프 생성
plt.figure(figsize=(10, 6))
plt.plot(years_korea_pm10, pm10_korea, marker='o', label='한국 PM10')
plt.plot(years_korea_pm25, pm25_korea, marker='o', label='한국 PM2.5')
plt.plot(years_oecd_pm25, pm25_oecd, marker='o', label='OECD 평균 PM2.5')
plt.title('역대 미세먼지 농도 추이')
plt.xlabel('연도')
plt.ylabel('미세먼지 농도')
plt.grid(True)
plt.legend()
plt.show()csv파일화 시켜서 데이터를 분석하고 시각화했으면 좋았겠다라는 생각이 들었다. 하지만 데이터분석을 마친 후 발표를 준비하면서 이 데이터가 있었으면 좋겠다는 생각을 하여 급하게 만들었기 때문에 시간 부족으로 미흡했던 것 같다.
- 결국 미세먼지는 과거에 비해 줄어들고 초미세먼지는 오히려 늘었다는 결론을 도출할 수 있었다. 그리고 oecd평균에 비하면 우리는 나쁜 대기질속에서 살고 있다는 것 또한 알 수 있었다.
📢제언
산업화로 인해 갈수록 심해지고 있는 대기 속에서 미래엔 방독면을 쓰고 살아야하는 거 아닌가 생각을 했는데 시각화된 데이터를 통해 보니 기술 발전과 대기오염 줄이는 노력 덕분에 그 포인트가 지연되고 있는 점에서 다행이라고 생각했다. 하지만 그래도 좋은 지표는 아니기 때문에 계속된 정책적인 노력과 더불어 개인적인 노력을 통해 지켜나가야 할 것이다.
