10) 임베딩 벡터의 시각화(Embedding Visualization)
- 임베딩 프로젝터 (enbedding projector) : 데이터 시각화 도구 (구글). 학습한 임베딩 벡터들을 시각화한다.
1. 워드 임베딩 모델로부터 2개의 tsv 파일 생성하기
(시각화를 위해서 모델 학습 과정을 끝내고 파일로 저장되어 있어야 함)
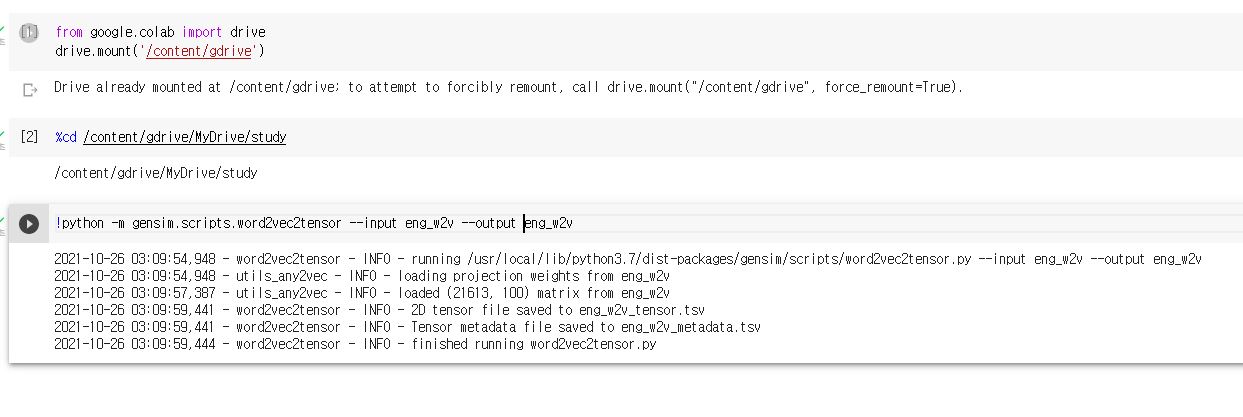

eng_w2v_metadata.tsv와 eng_w2v_tensor.tsv (벡터의 수치정보를 담고 있음) 를 생성한다.
tsv : Tab Seperated Values
eng_w2v_tensor.tsv : 단어별로 임베딩 벡터를 탭으로 구분한 파일
eng_w2v_metadata.tsv : eng_w2v_tensor.tsv 에서 각 벡터가 어떤 단어를 나타내는지 나타내는 파일

2. 임베딩 프로젝터를 사용하여 시각화하기
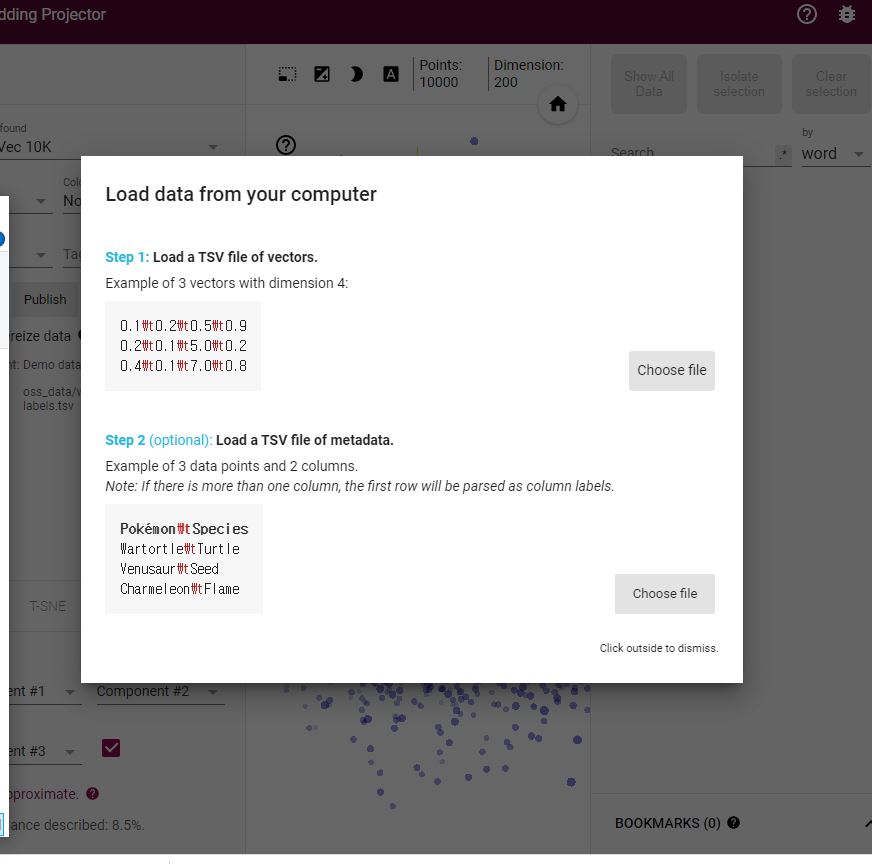
PCA : 고차원의 데이터를 저차원의 데이터로 환원시키는 기법 (복잡한 데이터를 차원을 축소하여 시각화)
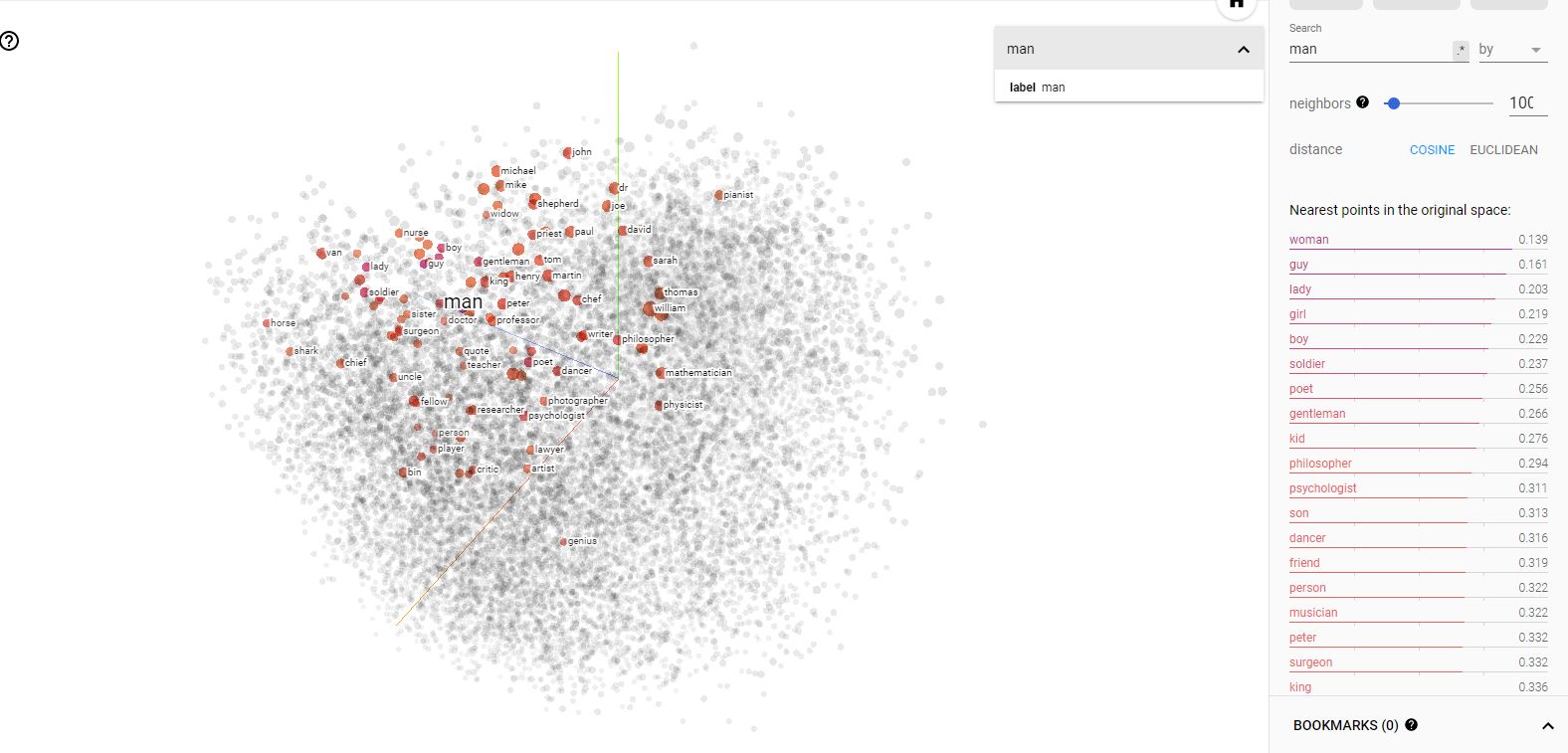
- man 을 검색했을 때 유사 벡터 상위의 결과가 같다
11) 문서 벡터를 이용한 추천 시스템(Recommendation System using Document Embedding)
- 다수의 문장이나 문서에 대한 유사도 비교 -> 각 문서를 고정된 벡터로 변환하여 벡터 비교를 통해 문서 비교
- 문서 벡터로 변환하는 방법
- Doc2Vec, Sent2Vec 등 패키지 이용
- 문서에 존재하는 단어들의 평균을 구함 (문서 내의 단어들을 Word2Vec을 통해 단어벡터로 변환 -> 평균 냄)
- 문서 벡터를 구하여 선호하는 도서와 유사한 도서를 찾아주는 도서 추천 시스템
https://colab.research.google.com/drive/1ge0MnvvCW6Vzpvx4mo-YIb8JjdTztV7F#scrollTo=8i35bE6F405f
12) 워드 임베딩의 평균(Average Word Embedding)
(임베딩이 잘 됐을 때) 단어 벡터들의 평균만으로 텍스트 분류를 할 수 있음을 입증
https://colab.research.google.com/drive/12O5pCl3Sb2btXGktFRkuoWjmtrJ-swop#scrollTo=whfSr8uUG89I

^^~