📌 글로브(GloVe)
- 글로브(Global Vectors for Word Representation) : 카운트 기반 + 예측 기반
- 카운트 기반인 LSA와 예측 기반의 Word2Vec을 보완
1. 기존 방법론에 대한 비판
- LSA (Latent Semantic Analysis)
- 각 문서에서의 각 단어의 빈도수를 카운트한 행렬을 입력으로 해서 차원을 축소하여 잠재적 의미를 끌어냄
- 전체적인 통계 정보를 고려하지만 단어 의미 유추 작업에는 성능이 떨어진다
- Word2Vec
- 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반 방법론
- 단어 의미 유추 작업은 뛰어나지만 윈도우 크기 내의 단어만 고려하기 때문에 전체적인 통계 정보는 반영하지 못한다.
2. 윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)
- 동시 등장 행렬 : 행과 열을 전체 단어 집합의 단어들로 구성, i 단어의 윈도우 크기 내에서 k단어가 등장한 횟수를 i행 k열에 기재한 행렬
Ex) 윈도우 크기 : 1
I like deep learning
I like NLP
I enjoy flying
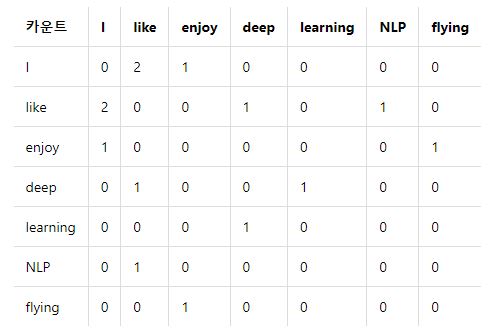
- 전치해도 같은 행렬 : 당연함
3. 동시 등장 확률(Co-occurrence Probability)
- 동시 등장 확률 (P(k|i) ) : 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 계산한 조건부 확률
- 동시 등장 행렬에서 i(중심단어)의 행의 모든 값을 더한 값을 분모로, i 행 k(주변단어)열의 값을 분자로 한 값
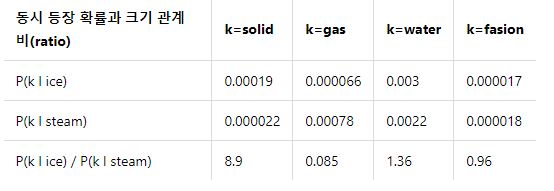
- ice가 등장했을 때 solid가 등장할 확률 = 0.00019
- steam이 등장했을 때 solid가 등장할 확률 = 0.000022
- steam이 등장했을 때 solid가 등장할 확률이 ice가 등장했을 때 solid가 등장할 확률보다 8.9배 큼
- solid 는 steam 보다 ice 와 의미적으로 가까움
4. 손실 함수(Loss function)

- 글로브의 아이디어 : 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것
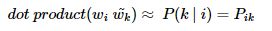
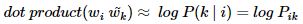
-
이렇게 되도록 임베딩 벡터를 만든다.
-
단어 간의 관계를 잘 표현하는 함수여야 함
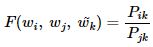
- 벡터를 F에 넣으면 우항이 나온다 (아직 F에 대해서는 정해진 것이 없는 상태)
- 이 식에 디테일을 추가하며 최적화
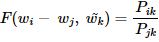
- F : 두 단어 사이의 동시 등장 확률의 크기 관계 비 정보를 벡터 공간에 인코딩
- 두 벡터의 차이를 입력으로 사용
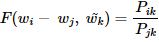
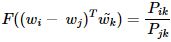
(내적을 통해 양 변을 모두 스칼라로 만듬)
5. GloVe 훈련시키기
📌 패스트텍스트(FastText)
- 단어 -> 벡터
- Word2Vec의 확장. 차이 : 내부 단어(subword) 고려. 하나의 단어 안에도 여러 단어들이 존재하는 것으로 간주
1. 내부 단어(subword)의 학습
- 각 단어는 글자 단위의 n-gram의 구성으로 취금
- ex. n = 3. apple -> <ap, app, ppl, ple, le>, <apple> 6개
- 실제 사용할 때는 n의 최소값과 최대값으로 범위 설정하여 벡터화(word2vec 수행)
- ex. n = 3 ~ 6. <ap, app, ppl, ppl, le>, <app, appl, pple, ple>, <appl, pple>, ..., <apple>
- apple = <ap + app + ppl + ppl + le> + <app + appl + pple + ple> + <appl + pple> + , ..., +<apple> (단어 apple의 벡터값은 총합으로 구성)
2. 모르는 단어(Out Of Vocabulary, OOV)에 대한 대응
- 장점 : 내부 단어를 통해 학습하지 않은 모르는 단어에 대해서도 다른 단어와의 유사도 계산 가능
- ex. 학습하지 않은 단어 birthplace가 있을 때 , 학습한 다른 단어에 birth 와 place라는 내부 단어가 있었으면 birthplace에 대한 벡터값을 얻을 수 있다.
- Word2Vec, GloVe와 다르게 모르는 단어에도 대처 가능
3. 단어 집합 내 빈도 수가 적었던 단어(Rare Word)에 대한 대응
- 희귀단어에서 그 단어의 n-gram이 다른 단어의 n-gram과 겹치면 정확한 임베딩 벡터값을 얻을 수 있음
- 같은 이유로 노이즈 많은(오타, 맞춤법 틀림) 코퍼스에 대해서도 강점을 가짐 (노이즈가 많으면 등장 빈도가 낮기 때문에 희귀단어가 됨)
- ex. appple -> apple과 n-gram 겹친다
- 이런 경우에 Word2Vec보다 성능이 높음
4. 실습으로 비교하는 Word2Vec Vs. FastText
5. 한국어에서의 FastText
- (1) 음절 단위
- ex. n = 3 <자연어처리> : <자연, 자연어, 연어처, 어처리, 처리>
- (2) 자모 단위
- 초성, 중성, 종성 단위로 임베딩
- 노이즈에 더 강한 임베딩
- ex. 분리된 결과 (종성 존재하지 않으면 언더바를 토큰으로 사용) : ㅈ ㅏ ㅇ ㅕ ㄴ ㅇ ㅓ ㅊ ㅓ ㄹ ㅣ : < ㅈ ㅏ, ㅈ ㅏ , ㅏ ㅇ, ... 중략>
📌 사전 훈련된 워드 임베딩(Pre-trained Word Embedding)
처음부터 학습시키지 않고
- 케라스의 임베딩 층 Embedding() : 케라스에서 갖고 있는 훈련 데이터의 임베딩 층을 구현하여 임베딩 벡터로 학습
- 사전 훈련된 워드 임베딩 : 방대한 코퍼스를 사용하여 Word2vec, FastText, GloVe 등을 통해 미리 훈련된 임베팅 벡터를 사용
1. 케라스 임베딩 층(Keras Embedding layer)
Embedding()
1) 임베딩 층은 룩업 테이블이다
- 어떤 단어 -> 단어에 부여된 고유한 정수값 -> 임베딩 층 통과 -> 밀집벡터
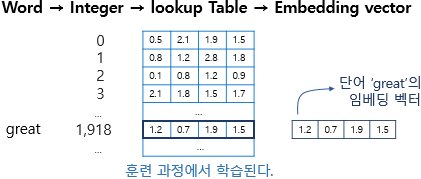
-
입력 정수를 임베딩 벡터로 맵핑
-
임베딩 벡터는 인공 신경망 학습 과정(가중치 학습)과 같은 방식으로 훈련되어 업데이트
-
정수에 해당하는 행 벡터를 가져와서 임베딩 벡터로 사용
-
Embedding()
- ex. v = Embedding(20000, 128, input_length=500)
- vocab_size : 텍스트 데이터 전체 단어 집합의 크기
- output_dim : 임베딩 후 임베딩 벡터의 차원
- input_length : 입력시퀀스의 길이. 각 샘플의 길이가 500개의 단어이면 input_length는 500이 된다
- 입력은 (number of samples, input_length)인 2D 정수 텐서
- 리턴은 (number of samples, input_length, embedding word dimentionality)인 3D 실수 텐서
2) 임베딩 층 사용하기
2. 사전 훈련된 워드 임베딩(Pre-Trained Word Embedding) 사용하기
- 훈련데이터가 적은 상황이라면 케라스의 Embedding()보다 사전 훈련된 워드 임베딩을 사용하는 것이 낫다 (데이터가 적다면 케라스로는 특화된 임베딩 벡터 만들기 힘들기 때문에 차라리 일반적이고 많은 훈련데이터를 사용하여 이미 학습된 임베딩 벡터를 사용하는 낫다)
📌 엘모(Embeddings from Language Model, ELMo)
- 엘모(Embeddings from Language Model, ELMo) : 워드임베딩 방법론. 언어모델로 하는 임베딩
- 사전 훈련된 언어 모델을 사용한다
1. ELMo(Embeddings from Language Model)
- Word2Vec이나 GloVe 같은 임베딩으로는 다른 의미를 가진 단어들을 구별하지 못한다.
- ex. Bank(은행) Account 와 River Bank(강둑) 의 Bank는 전혀 다른 의미를 가지는데 이를 반영하지 못함
- 같은 표기의 다른 의미를 가진 단어들을 문맥에 따라 다르게 임베딩할 필요성
- -> 문맥을 반영한 워드임베딩(Contextualized Word Embedding) 탄생
2. biLM(Bidirectional Language Model)의 사전 훈련
- biLM(Bidirectional Language Model) : 순방향 + 역방향(문장의 반대방향으로 스캔)

- 기본 RNN 언어 모델은 순방향
- ELMo 는 양쪽 방향 모두 활용하기 때문에 biLM
- biLM 는 다층구조(은닉층이 최소 2개 이상)를 전제로 한다
- 입력 : char CNN (char 단위로 계산. subword처럼 문맥과 상관 없이 단어의 연관성을 찾아내고 OOV에도 견고하다)
3. biLM의 활용
- ELMo가 사전 훈련된 biLM을 통해 입력 문장으로부터 단어를 임베딩하기 위한 과정
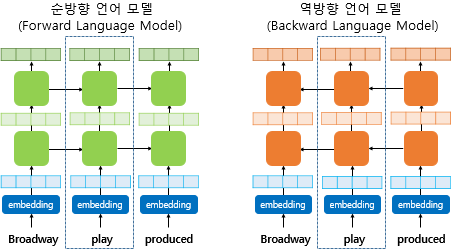
1) 각 층의 출력값을 연결(concatenate)한다.(순방향과 역방향)
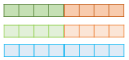
2) 각 층의 출력값 별로 가중치를 준다.
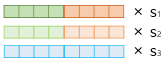
3) 각 층의 출력값을 모두 더한다.
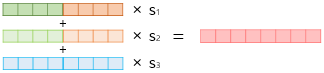
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱한다.
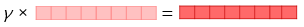
- 완성된 벡터를 ELMo 표현(representation)라고 함
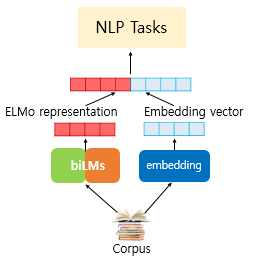
- 엘모 표현은 기존 임베딩 벡터와 함께 사용되어 자연어처리 작업의 입력이 된다
- 예를 들면 기존의 방법론인 GloVe 벡터와 엘모 표현을 연결해서 입력으로 사용할 수 있다.
- 사전 훈련된 언어모델의 가중치는 고정시키고 s1, s2, s3, γ는 훈련과정에서 학습됨
4. ELMo 표현을 사용해서 스팸 메일 분류하기

^^~