DBMS와 버퍼
버퍼는 성능에 굉장히 중요한 영향을 미친다.
메모리는 한정된 희소 자원인 반면 데이터베이스가 메모리에 저장하고자 하는 데이터는 굉장히 많다.
따라서, 데이터를 버퍼에 어떠한 식으로 확보할 것인가 하는 부분에서 트레이드오프가 발생한다.
1. 기억장치의 계층
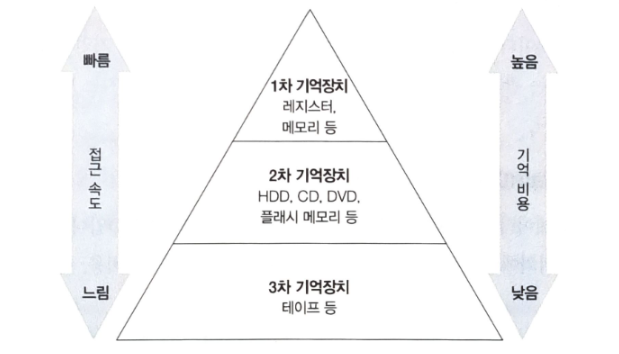
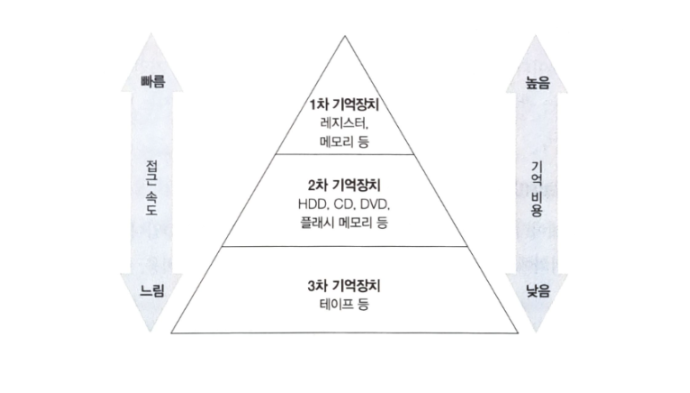
일반적으로 기억장치는 기억비용에 따라 1차에서 3차까지의 계층으로 분류된다.
많은 데이터를 영속적으로 저장하려 하면 속도를 잃고, 속도를 얻고자 하면 많은 데이터를 영속적으로 저장하기 힘들다는 트레이드 오프가 발생한다.
기억비용 : 데이터를 저장하는데 소모되는 비용
2. DBMS와 기억장치의 관계
DBMS는 데이터를 저장하는것을 목적으로 하는 미들웨어이다.
DBMS가 사용하는 대표적인 기억장치는 2가지가 있다.
하드디스크(HDD)
- DBMS가 데이터를 저장하는 매체(저장소)는 현재 대부분 HDD다.
- 용량, 비용, 성능의 관점에서 대부분 하드디스크를 채택하고 있다
- 하드디스크는 기억장치 계층에서 가운데 있는 2차 기억장치로 분류된다.
- 2차 기억장치는 그렇게 좋은 장점도 없지만, 그렇게 나쁜 단점도 없는 매채다.
- DB는 대부분의 시스템에서 범용적으로 사용하는 미들웨어이므로, 어떤 상황에서도
- 평균적인 수치를 가지는 매체를 선택하는 것이 자연스럽다.
- 그렇다고 해서 DBMS가 데이터를 디스크 이외에 장소에 저장하지 않는다는 뜻은 아니다.
메모리
- 메모리는 디스크에 비해 기억비용이 굉장히 비싸다.
- 따라서 하드웨어 1대에 탑재할 수 있는 양이 크지않다.
- 일반적인 DB서버에 경우 탑재되는 메모리의 양은 한두 자리 정도다
- 상용 시스템의 DB 내부 데이터를 모두 메모리에 올리는 것은 불가능하다.
버퍼를 활용한 속도 향상
그렇지만 DBMS가 일부라도 데이터를 메모리에 올리는 것은 성능 향상 때문이다.
메모리는 가장 빠른 1차 기억장치다. 따라서 자주 접근하는 데이터를 메모리 위에 올려둔다면, 같은 SQL 구문을 실행한다고 해도 디스크에서 데이터를 가져올 필요 없이 곧바로 메모리에서 읽어 빠르게 데이터를 검색할 수 있다.
디스크 접근을 줄일 수 있다면 굉장히 큰 폭의 성능 향상이 가능하다.
SQL구문의 실행 시간을 대부분 저장소 I/O에 사용하기 때문이다.
이렇게 성능 향상을 목적으로 데이터를 저장하는 메모리를 버퍼 또는 캐시라고 부른다.
버퍼는 완충제라는 의미인데 사용자와 저장소 사이에서 SQL구문의 디스크 접근을 줄여주는 역할을 하므로 붙은 이름이다.
캐시 역시 사용자와 저장소 사이에서 데이터 전송 지연을 완화시켜주는 것이다.
모두 물리적인 매체로 메모리가 사용되는 경우가 많다, 따라서 하디드스크 위에 있는 데이터에 접근하는 것보다 훨씬 빠르다.
이러한 고속 접근이 가능한 버퍼에 데이터를 어떻게, 어느 정도의 기간동안 올릴지를 관리하는 것이 DBMS의 버퍼 매니저다.
3. 메모리 위에 있는 두 개의 버퍼
DBMS가 데이터를 유지하기 위해 사용하는 메모리는 두 종류가 있다.
- 데이터 캐시
- 로그 버퍼
대부분의 DBMS는 이러한 두 개의 역할을 하는 메모리 영역을 가지고 있다.
데이터 캐시
데이터 캐시는 디스크에 있는 데이터의 일부를 메모리에 유지하기 위해 사용하는 메모리영역이다.
내가 실행한 select 구문에서 선택하고 싶은 데이터가 데이터 캐시에 있다면 디스크와 같은 저속 저장소에 접근하지 않고 처리가 수행되기 때문에 빠르게 응답한다.
반대로 버퍼에서 데이터를 찾을 수 없다면 저속 저장소까지 데이터를 가지러 가야하기 때문에 SQL구문의 응답속도가 느려진다.
로그버퍼
로그 버퍼는 갱신처리(select, delete, update, merge)와 관련이 있다.
DBMS는 갱신과 관련된 SQL 구문을 사용자로부터 받으면, 곧바로 저장소에 있는 데이터를 변경하지 않는다.
로그 버퍼 위에 변경 정보를 보내고 이후 디스크에 변경을 수행한다.(갱신 처리는 비동기로)
DBMS가 이러한 시점 차이를 두는 이유는 성능을 높이기 위해서다.
=> 성능을 향상시키기 위한 방법인데 갱신을 할 때도 상당한 시간이 소모되기 때문에 저장소 변경이 끝날 때까지 기다리면 사용자는 장기간 대기해야 한다. 따라서 사용자에게 해당 SQL구문이 '끝났다'라고 통지하고, 내부적으로 관련된 처리를 계속 수행하는 것이다.
동기 vs 비동기
동기 방식은 서버에서 요청을 보냈을 때 응답이 돌아와야 다음 동작을 수행할 수 있다. 즉 A작업이 모두 진행 될때까지 B작업은 대기해야한다.
비동기 방식은 반대로 요청을 보냈을 때 응답 상태와 상관없이 다음 동작을 수행 할 수 있다. 즉 A작업이 시작하면 동시에 B작업이 실행된다. A작업은 결과값이 나오는대로 출력된다.
4. 메모리의 성질이 초래하는 트레이드오프
메모리가 가진 단점은 가격이 비싸서 보유할 수 있는 데이터양이 적은것 뿐만아니라, 이외의 몇가지 단점이 더 있다.
휘발성
메모리에는 데이터의 영속성이 없다. 하드웨어의 전원을 꺼버리면 메모리 위에 올라가 있는 데이터가 모두 사라진다. 이러한 성질을 휘발성이라고 한다.
DBMS을 껏다 켜면 버퍼위의 모든 데이터가 사라진다. 따라서 DBMS에 어떤 장애가 발생해서 프로세스다운이 일어나면(서버가 죽으면) 메모리 위에 있는 모든 데이터는 날아간다.
휘발성의 위험성
휘발성의 가장 큰 문제점은 장애가 발생했을 때 메모리에 있는 데이터가 모두 사라져버려 데이터 부정합을 발생시키는 것이다. 데이터 캐시라면 장애로 인한 메모리 위의 데이터가 사라져버려도, 원본 데이터는 디스크 위에 남아있으므로 아무 문제가 없다.
하지만 로그 버퍼 위에 존재하는 데이터가 디스크 위의 로그 파일에 반영되기 전 장애가 발생해 사라져 버리면 해당 데이터가 완전히 사라져서 복구조차 불가능해진다. 이는 사용자가 수행했던 갱신 정보가 사라진다는 의미이다.
이러한 문제를 회피하고자 DBMS는 커밋 시점에 반드시 갱신 정보를 로그파일에 씀으로써, 장애가 발생해도 정합성을 유지할 수 있게 한다.
커밋(Commit)이란 갱신 처리를 확정하는 것으로 DBMS는 커밋된 데이터를 영속화 함
커밋 때는 반드시 디스크에 동기 접근이 일어남. 여기에서 또다시 트레이드오프가 모습을 드러냄
디스크에 동기 처리를 한다면 데이터 정합성은 높아지고 성능이 낮아진다.
반대로 성능을 높이러면 데이터의 정합성이 낮아진다
5. 시스템 특성에 따른 트레이드 오프
데이터 캐시와 로그 버퍼의 크기
DBMS를 보면 데이터 캐시에 비해 로그 버퍼의 초깃값이 굉장히 작다.
이렇게 할당한 이유는 DB가 기본적으로 검색을 메인으로 처리한다고 가정하기 때문이다.
갱신 처리에 값비싼 메모리를 많이 사용하는 것보다는, 자주 검색하는 데이터를 캐시에 올려놓는 것이 좋다고 생각하기 때문이다.
왜냐하면, 데이터베이스의 데이터를 검색할 때 레코드가 수백만에서 수천만 건에 달하는 경우 많지만, 갱신 처리를 할 때는 갱신 대상이 많아 봤자 트랜잭션마다 한 건 에서 수만 건 정도밖에 안되기 때문이다.
검색 vs 갱신
우리는 검색과 갱신 중에서 어떤 것이 더 우선되어야 하는가라는 트레이드오프에 직면한다.
메모리라는 비깐 희소 자원으로 위해 어떤 것을 우선하여 지킬지, 어떤 것을 버릴지를 판단해야 한다.
6. 추가적인 메모리 영역 '워킹 메모리'
언제 사용될까?
DBMS는 메모리 영역을 하나 더 가지고 있는데 정렬 또는 해시 관련 처리에 사용되는 작업용 영역으로 워킹 메모리라고 부른다.
정렬은 ORDER BY구, 집합 연산, 윈도우 함수 등의 기능을 사용할 때 실행된다.
해시는 주로 테이블의 결합에서 해시 결합이 사용되는 때 실행된다.
이 작업용 메모리 영역은 SQL에서 정렬 또는 해시가 필요한 때 사용되고, 종료되면 해제되는 임시영역으로, 일반적으로는 데이터 캐시와 로그 버퍼와는 다른 영역으로 관리되는 경우가 많다.
이 영역이 성능적으로 중요한 이유는 만약 이 영역이 다루려는 데이터양보다 작아 부족해지는 경우 대부분의 DBMS가 저장소를 사용하기 때문이다. 이는 OS 동작에서 말하는 스왑과 같은 것이다.
저장소가 부족하면 무슨 일이 일어날까?
저장소는 메모리에 비해서 굉장히 느리다. 따라서 그런 곳에 접근하게 되면 전체적인 속도가 느려진다.
이 영역은 여러 개의 SQL 구문들이 공유해서 사용하므로, 하나의 SQL 구문을 실행하고 있을 때는
메모리가 잘 들어가지만 여러 개의 SQL 구문을 동시에 실행하면 메모리가 넘치는 경우가 있다.
하나가 있을 때의 성질뿐만 아니라, 여러 개가 있을 때의 성질도 주의해야 한다는 것이 컨트롤하기 힘든 성능 문제이다.
DBMS는 메모리가 부족하더라도 무언가를 처리하려고 계속 노력하는 미들웨어라고 생각할 수 있다.
DB는 메모리가 부족하다는 이유로 SQL 구문에 오류를 절대 발생시키지 않는다.
