어제의 이어서 오늘도 계속 머신러닝 강의를 듣고 있다! 수식적인 부분은 잘 이해가 가진 않지만, 개념을 이해하고 코드가 어떤역할을 수행하는지, 어떤 결과를 도출해내는지에 대한 이해를 하는 것을 목표로 강의를 듣고 있다
- 전처리
실제 업무에서 얻는 데이터는 오기입하는 경우도 있고 단위와 분포가 제각각이라 정제작업이 꼭 필요합니다
- 논리회귀 (Logistic regression)
머신러닝에서, 입력값과 범주 사이의 관계를 구하는 것을 논리 회귀라고 합니다
Q. 대학교 시험전날 공부시간을 가지고 이수여부를 예측 하는 문제.
입력값은 -> 공부한 시간
출력값 -> 이수 여부
이수여부를 0,1 이진클래스 (Binary class)로 나눌 수 있다.
이런 경우를 이진 논리 회귀 로 해결할 수 있다.
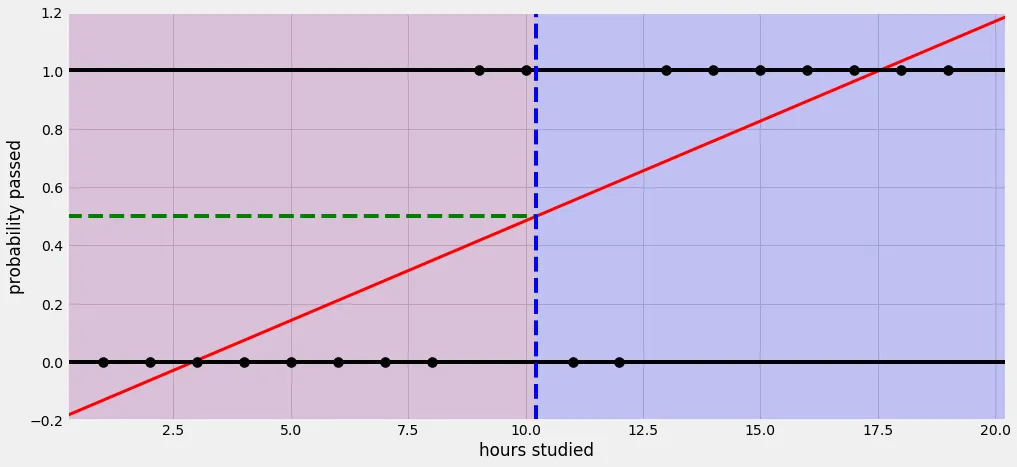
Reference https://ursobad.tistory.com/44
선형회귀로 문제를 풀 경우
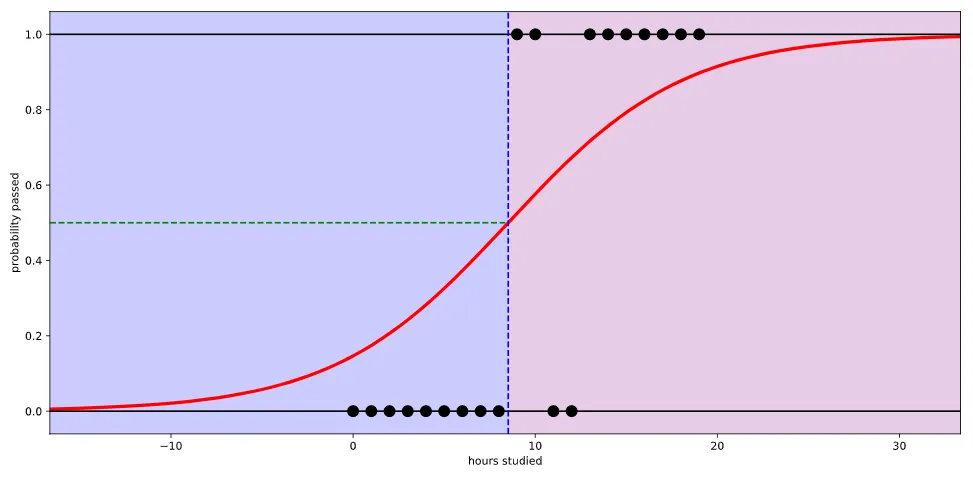
Reference https://ursobad.tistory.com/44
논리 회귀로 문제를 풀 경우
실제 많은 자연, 사회현상에서는 특정 변수에 대한 확률값이 선형이 아닌 S 커브 형태를 따르는 경우가 많다고 합니다. 이러한 S-커브를 함수로 표현해낸 것이 바로 로지스틱 함수(Logistic function)입니다. 딥러닝에서는 시그모이드 함수(Sigmoid function)라고 불립니다.
- 다항 논리 회귀(Multinomial logistic regression)
Q. 대학교 시험전날 공부한 시간을 가지고 A,B,C,D,F 를 예측 하는 문제
이문제를 풀려면 클래스를 5개의 클래스로 나눈다. 이방법을 다중논리회귀 라고 부른다.
- 원핫 인코딩
원핫 인코딩은 다항 분류 (Multi-label classification) 문제를 풀 때 출력값의 형태를 가장 예쁘게 표현할 수 있는 방법입니다. 다항 논리 회귀도 다항 분류에 속하기 때문에 원핫 인코딩 방법을 사용합니다.
ex 1 -> 1,0,0,0,0
2 -> 0,1,0,0,0
컴퓨터가 알아보기 쉽게 바꾸어 준다!
- softmax 함수와 손실 함수
softmax는 선형 모델에서 나온 결과(Logit)를 모두가 더하면 1이 되도록 만들어주는 함수입니다. 다 더하면 1이 되도록 만드는 이유는 예측의 결과를 확률(=Confidence)로 표현하기 위함인데요. 우리가 One-hot encoding을 할때에도 라벨의 값을 전부 더하면 1(100%)이 되기 때문입니다.
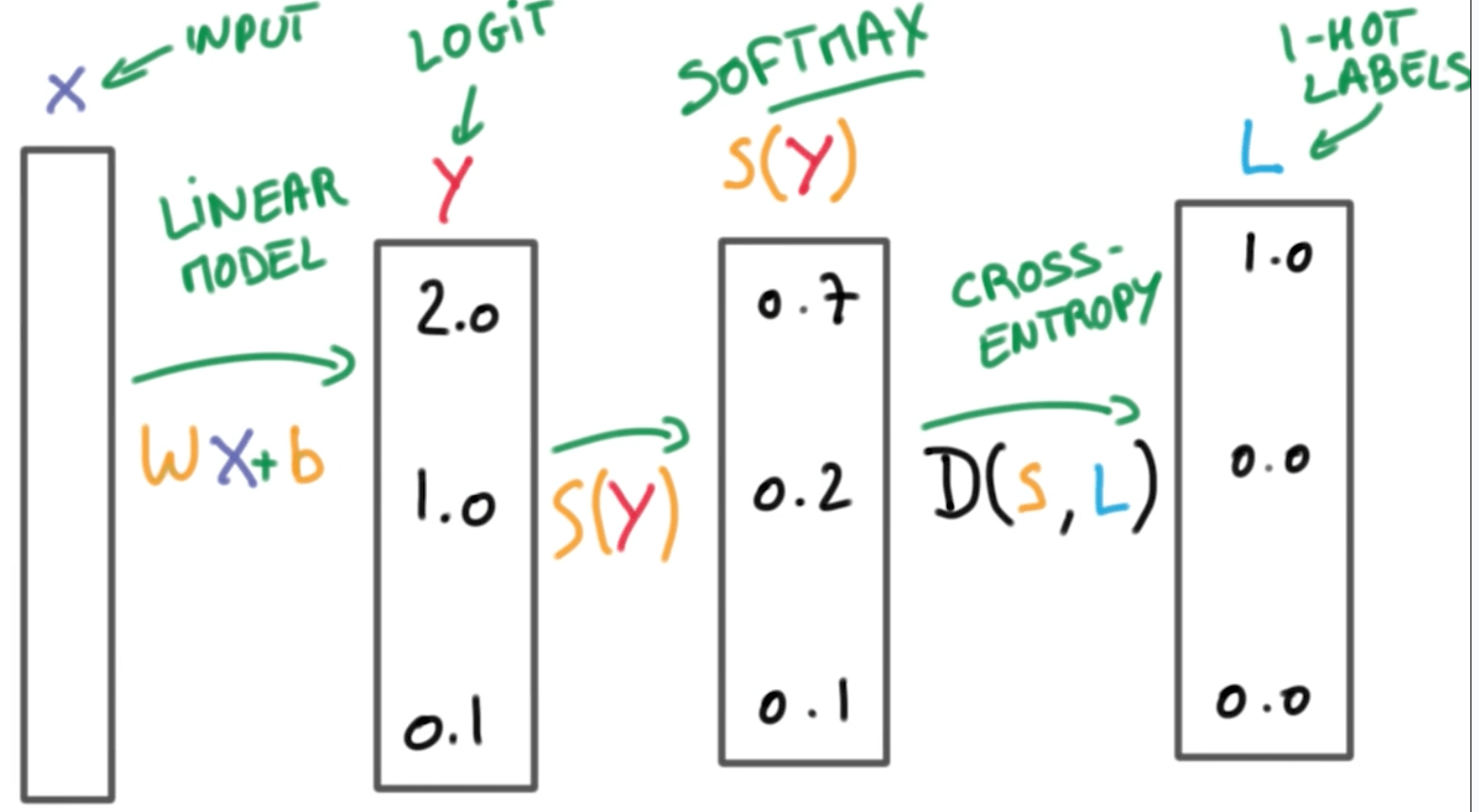
출처: https://www.programmersought.com/article/62574848686/
확률 분포의 차이를 계산할 때는 Crossentropy 함수를 씁니다!!
- Support vector machine (SVM)
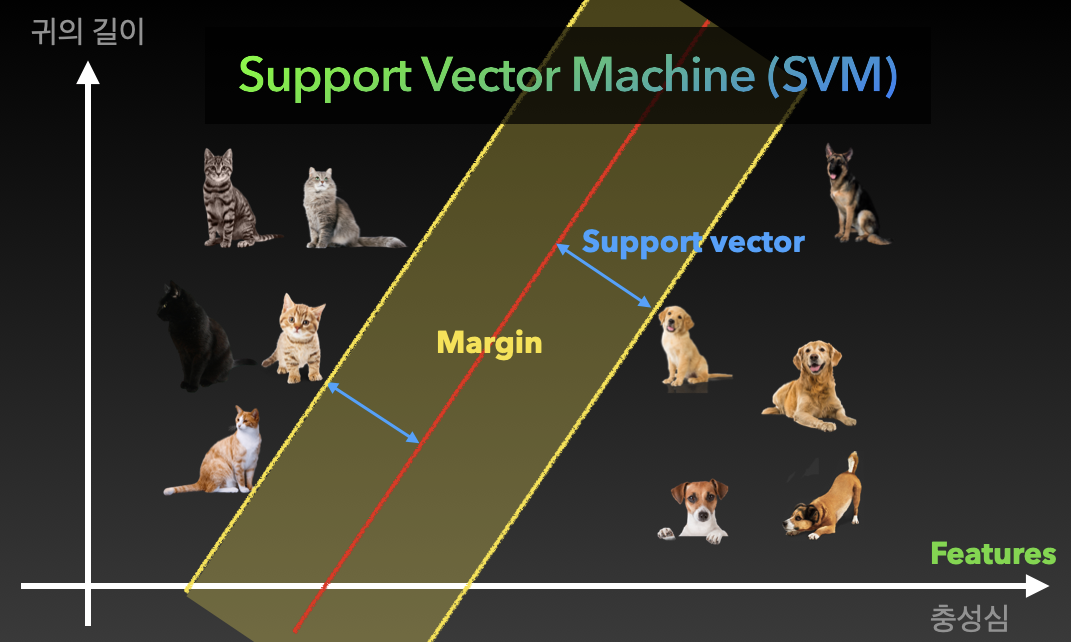
각 그래프의 축을 Feature(특징)라고 부르고 각 고양이, 강아지와 우리가 그린 빨간 벡터를 Support vector라고 부릅니다. 그리고 그 벡터의 거리를 Margin이라고 부르죠. 우리는 Margin이 넓어지도록 이 모델을 학습시켜 훌륭한 Support vector machine을 만들 수 있습니다
- 전처리(Preprocessing)란?
전처리는 넓은 범위의 데이터 정제 작업을 뜻합니다. 필요없는 데이터를 지우고 필요한 데이터만을 취하는 것, null 값이 있는 행을 삭제하는 것, 정규화(Normalization), 표준화(Standardization) 등의 많은 작업들을 포함하고 있습니다. 또한 머신러닝 실무에서도 전처리가 80%를 차지한다는 말이 있을 만큼 중요한 작업이기도 하죠. 전처리 노가다에서 항상 시간이 오래 걸리고 실수가 많습니다.
- 정규화 (Normalization)
정규화는 데이터를 0과 1사이의 범위를 가지도록 만듭니다. 같은 특성의 데이터 중에서 가장 작은 값을 0으로 만들고, 가장 큰 값을 1로 만듭니다
ex) 각각50점이지만 100점만점기준, 500점만점 기준
둘다 500점만점기준이면 0.5 ->0.1
- 표준화 (Standardization)
표준화는 데이터의 분포를 정규분포로 바꿔줍니다. 즉 데이터의 평균이 0이 되도록하고 표준편차가 1이 되도록 만들어주죠.
일단 데이터의 평균을 0으로 만들어주면 데이터의 중심이 0에 맞춰지게(Zero-centered) 됩니다. 그리고 표준편차를 1로 만들어 주면 데이터가 예쁘게 정규화(Normalized) 되죠. 이렇게 표준화를 시키게 되면 일반적으로 학습 속도(최저점 수렴 속도)가 빠르고, Local minima에 빠질 가능성이 적습니다.
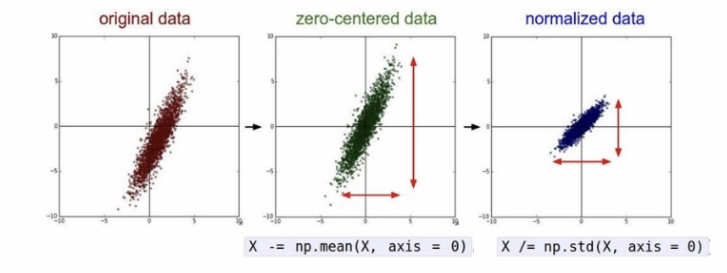
출처: http://cs231n.stanford.edu/2016/
- 보통은 정규화를 더 많이 쓴다고 합니다!!
숙제
이진 논리 회귀
https://colab.research.google.com/drive/1yJgjeLbza8ogST_vsC4zFNBkOw19grFh
다항 논리 회귀
https://colab.research.google.com/drive/1QY2Lj72z257AjxHKJpRf7Ye6R86a3jkm
현재 나는 4주차 강의를 듣고 있지만, TIL로 앞주차 강의 내용을 정리하면서 계속해서 복습을 하려고 한다, 사실 지금도 몇번씩 앞주차 강의를 들으면서 복습을 하고 있는데, 나도 모델처럼 반복 학습이 필요한 부분인 것 같다. 사실 코드자체는 그렇게 어렵다고 느껴지지는 않지만 개념을 확실히 이해할 필요는 있다. 코드만 가져와서 사용하다면 나는 개발자가 아닌 코더가 될테니.. 현재 머신러닝을 공부하는 과정에서 그런 부분을 많이 느낀다. 개념을 확실하게 이해하고 수식까지는 아니더라도 왜 이코드를 사용하는지, 어떤 개념으로 이 코드가 작동하는지는 반드시 파악하고 넘어가자!
-
주말동안 4주차까지 완강하고, 복습하기
-
주말동안 알고리즘,자료구조 공부하기
-
주말동안 실습도 계속 해보기.
