머신러닝이란?
간략히 찾아본 정의에 의하면 이렇다
머신러닝은 인공지능(AI)의 하위 집합입니다. 학습과 개선을 위해 명시적으로 컴퓨터를 프로그래밍하는 대신, 컴퓨터가 데이터로 학습하고 경험을 통해 개선하도록 훈련하는 데 중점을 둡니다. 머신러닝에서 알고리즘은 대규모 데이터 세트에서 패턴과 상관관계를 찾고 분석을 토대로 최적의 의사결정과 예측을 수행하도록 훈련됩니다. 머신러닝 애플리케이션은 적용을 통해 개선되며 이용 가능한 데이터가 증가할수록 더 정확해집니다. 머신러닝의 응용 분야는 주거 공간부터 장바구니, 엔터테인먼트 미디어, 의료에 이르기까지 우리 주변에 퍼져 있습니다.
- 선형 회귀
컴퓨터가 풀수 있는 가장 간단한 두 데이터 간의 직선 관계를 찾아 x값으로 y값을 예측하는것 을 선형회귀 라고 한다.
또한 역시 이번 강의에서도 영어 사용의 중요성과 구글링에 중요성을 잠깐 다뤄주셨다. 정말 공감 가는 내용 들이다.
- 알고리즘
수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차-위키피디아
어떤 문제를 풀기위해 수학 공식을 만들었다고 보면 된다. 알고리즘은 코딩테스트, AI, 빅데이터 등등 여러분야에 걸쳐, 컴퓨터 프로그래밍 전반적으로 사용 되는 것 같다.
-
머신러닝의 회귀와 분류
머신러닝에서 문제를 풀 때, 해답을 내는 방법을 크게 회귀 또는 분류로 나타낼 수 있다. -
회귀(Regression)
강의 내용 외에 좀 찾아본 정보에 의하면
회귀(영어: regress 리그레스[*])의 원래 의미는 옛날 상태로 돌아가는 것을 의미한다. 영국의 유전학자 프랜시스 골턴은 부모의 키와 아이들의 키 사이의 연관 관계를 연구하면서 부모와 자녀의 키사이에는 선형적인 관계가 있고 키가 커지거나 작아지는 것보다는 전체 키 평균으로 돌아가려는 경향이 있다는 가설을 세웠으며 이를 분석하는 방법을 "회귀분석"이라고 하였다. 이러한 경험적 연구 이후, 칼 피어슨은 아버지와 아들의 키를 조사한 결과를 바탕으로 함수 관계를 도출하여 회귀분석 이론을 수학적으로 정립하였다.
출처 :
https://ko.wikipedia.org/wiki/%ED%9A%8C%EA%B7%80_%EB%B6%84%EC%84%9D
머신러닝의 (선형)회귀는 실제 값과 예측값의 차이를 최소화하는 식을 찾는 것으로, y=wx+b의 식에서 독립변수의 값에 영향을 미치는 회귀 계수(Regression Coefficients)의 최적의 값을 찾는 것입니다.
- 분류(Classification)
ex)대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or fail)를 예측하는 문제
입력값은 [공부한 시간] 그리고 출력값은 [이수 여부]가 됩니다. 우리는 이수 여부를 0, 1 이라는 이진 클래스(Binary class)로 나눌 수 있습니다. 0이면 미이수(Fail), 1이면 이수(Pass) 이런식으로요. 이런 경우를 이진 분류(Binary classification)이라고 부릅니다.
그 이상의 클래스로 나누고 이 방법을 다중 분류(Multi-class classification, Multi-label classification)라고 부릅니다.
출처: https://towardsdatascience.com/the-future-with-reinforcement-learning-877a17187d54
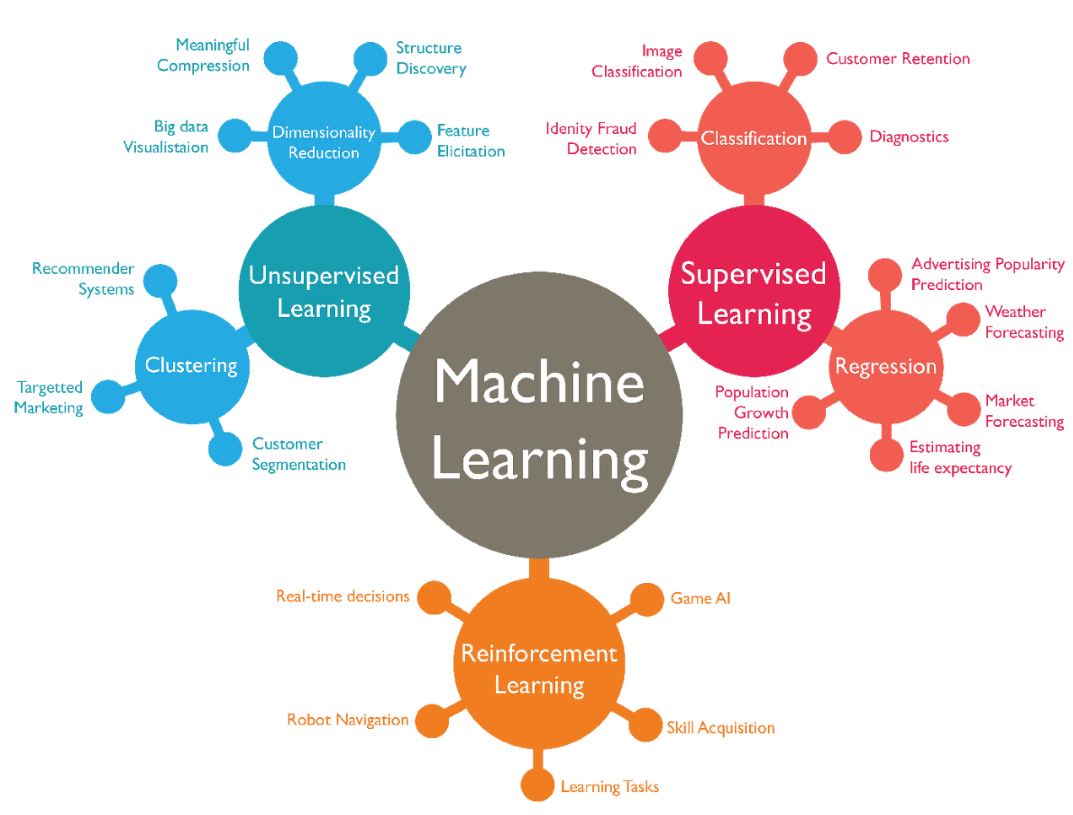
머신러닝의 3가지 학습 방법
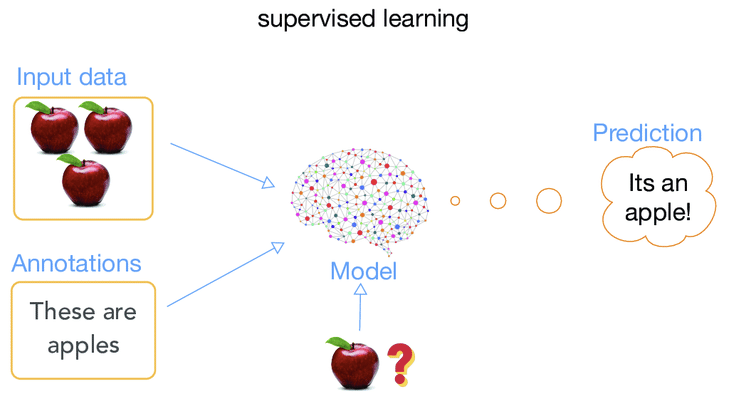
- 지도 학습(Supervised learning): 정답을 알려주면서 학습시키는 방법
회구와 분류가 대표적인 지도학습에 속한다. 지도학습은 기계에게 입력값과 출력값을 전부 보여주면서 학습시킨다. 정답(출력값)이 없으면 이 방법으로 학습이 불가능함.
문제를 풀기위해 많은 데이터가 필요한데 대부분 회사에서는 데이터가 없는 경우가 많다. 또는 출력값이 없는 경우가 많다. 이에따라 입력값에 정답(출력값)을 입력해주는 작업을 하는데 그과정을 라벨링(Labeling,노가다) 또는 어노테이션(Annotatino) 이라고 한다.
https://www.researchgate.net/figure/Supervised-learning-and-unsupervised-learning-Supervised-learning-uses-annotation_fig1_329533120
- 비지도 학습 (Unsuper!vised learning): 정답을 알려주지 않고 군집화(Clustering)하는 방법
우리가 가지고 있는 데이터에 입력값(음원파일)과 출력값(장르) 둘 다 존재한다면 우리는 지도 학습으로 이 문제를 풀 수 있지만 출력값에 해당하는 장르 데이터가 없을 때 비지도 학습 방법을 사용합니다. 비지도 학습 방법은 라벨(Label 또는 Class)이 없는 데이터를 가지고 문제를 풀어야 할 때 큰 힘을 발휘하죠! 음악 장르를 구분하는 문제를 비지도 학습을 사용해서 풀라고 시키면 아래와 같은 뉘앙스가 됩니다.
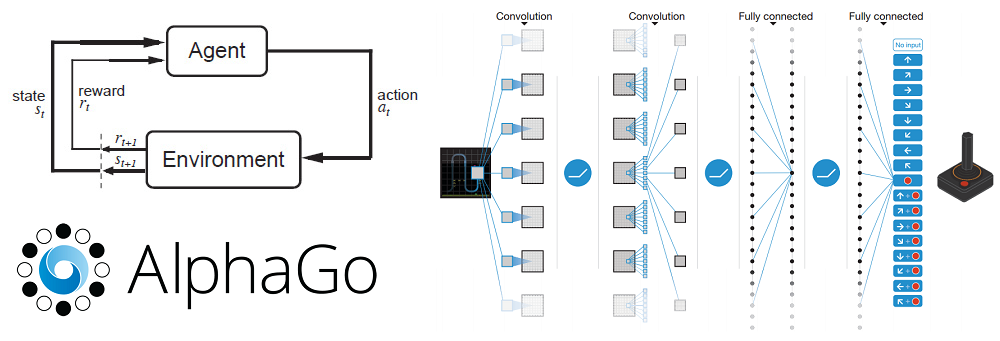
출처: https://adeshpande3.github.io/Deep-Learning-Research-Review-Week-2-Reinforcement-Learning
- 강화학습(Reinforcement learning): 주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법 (알파고를 탄생시킨 머신러닝 방법!!)
행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하지 않거나, 데이터가 있어도 정답이 따로 정해져 있지 않고, 자신이 한 행동에 대해 보상(Reward)를 받으며 학습하는 것을 말합니다.
강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
선형 회귀 (Linear Regression)
(직선 = 1차 함수)
사실 수학적인 부분을 잘 몰라서 중간에 수학 공부를 잠깐 하고 왔다.. 1차함수 그래프 랑, 기울기랑 이런것들이 조금 햇갈려서 수학 개념을 살짝 보고 왔더니 이해가 조금은 된 것 같다.
여기서 H(x)는 우리가 가정한 직선이고 y 는 정답 포인트라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 학습되었다고 말할 수 있을겁니다.
여기서 우리가 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cost를 손실 함수(Cost or Loss function)라고 합니다.
- 다중 선형 회귀(Multi-variable linear regression)
선형 회귀 와 똑같지만 변수가 여러개 이다!!
x값만 증가 시켜주는걸로 일단 이해하면 될듯 하다
경사 하강법 (Gradient descent method)
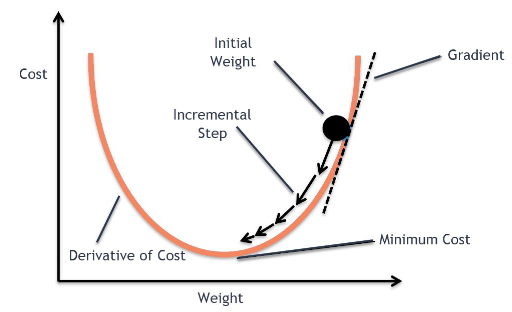
출처: https://towardsdatascience.com/using-machine-learning-to-predict-fitbit-sleep-scores-496a7d9ec48
손실함수를 최소화 하는것, 손실 함수를 최소화 하는 방법은 이 그래프를 따라 점점 아래로 내려가는 것이다.
컴퓨터는 사람과 달리 경사하강법 이라는 방법을 써서 점진적으로 문제를 풀어간다. 처음에는 랜덤으로 한점에서 시작하고, 좌우로 조금씩 그리고 한번씩 움직이면서 이전 값보다 작아지는지를 관찰한다. 한칸씩 전진하는 Learning rate 라고 부른다.
- learnin rate 가 지나치게 크면 Overshooting 이 발생할 수 도 있다.
데이터셋 분할
- 학습/ 검증/ 테스트 데이터
1.Training set (학습 데이터셋, 트레이닝셋)
교과서 라고 생각하면 편하다. 전체 데이터셋의 80% 정도를 사용, 모델을 학습시크는 용도로 사용
- Validation set(검증 데이터셋,벨리데이션셋)
모의고사 라고 생가하면 편하다. 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용, 이 데이터는 정답 라벨이 있고 학습단계에서 사용하기는 하지만 모델에게 데이터를 직접 보여주지는 않으므로 모델의 성능에 영향을 미치진 않는다.
손실함수,Optimizer 등을 바꾸면서 모델을 검증하는 용도로 사용
전체데이터의 20% 정도를 차지
3.Test SET(평가 데이터셋, 테스트셋) = 수능
정답 라벨이 없는 실제 환경에서의 평가 데이터셋, 검증 데이터셋으로 평가된 모델이 아무리 정확도가 높아도 사용자가 사용하는 제품에서 제대로 동작하지 않는 다면 소용 없는 것이다. 그걸 테스트 하기 위한 방법.
1,2주차 강의를 다듣고 숙제까지 완료를 했다. 우선오늘은 1주차에 대한 내용들을 강의자료와 구글링 자료들을 참고와 가져와서 정리를 좀 해보았다. 어렵고, 처음 보는 내용들이 많아 정리를 잘해서 복습하는 시간이 많이 필요 할 것 같다. 또한 강의를 듣는내내 아이패드로 pdf 파일을 가져와서 필기도하고, 같이 보면서 진행을 하였는데, 강의 듣는데, 그리고 이해하고 정리 하는데 많은 도움이 된 것 같다.
