
1. 크롤링으로 데이터 수집
- 인터파크 사이트
- 2021년 8월 12일(목) ~ 8월 15일(일) 부터 2022년 7월 21일(목) ~ 7월 24일(일) 까지 50주
- 1위 ~ 10위에 해당하는 영화의 순위 / 순위증감 / 영화 제목 / 예매점유율 / 개봉일 정보를 수집
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver import ActionChains
import pandas as pd
import time
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc("font", family = "Malgun Gothic")
%matplotlib inlinedates = pd.date_range("2021.08.12","2022.07.21",freq='7D')
result = dates.strftime("%Y.%m.%d")수집할 기간의 날짜 리스트를 pd.date_range()로 생성하고, dates.strftime()을 사용해 원하는 형식으로 바꿔준다.
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service('C:/Users/user/Documents/ds_study/driver/chromedriver.exe'), options=chrome_options)
url = "http://movie.interpark.com/Community/Movie/Ranking/Ranking_Report.asp"
driver.get(url)
total_data = []
for date in result:
select_date_but = driver.find_element(By.XPATH, '/html/body/table/tbody/tr[2]/td[3]/table/tbody/tr/td/table[3]/tbody/tr[2]/td/table[1]/tbody/tr[3]/td/form/select')
select_date_but.send_keys(date)
time.sleep(3)
tmp = driver.find_elements(By.XPATH, '/html/body/table/tbody/tr[2]/td[3]/table/tbody/tr/td/table[3]/tbody/tr[2]/td/table[3]/tbody/tr[3]/td[2]/table/tbody')[0].text
raw_data = tmp.split('\n')
raw_list = []
li = []
for data in raw_data:
data = data.strip()
if data == '':
continue
elif check_date(data) or data == "0000..":
li.append(data)
li.append(date)
raw_list.append(li)
li = []
else:
li.append(data)
total_data.append(raw_list)
driver.close()
driver.quit() selenium모듈을 사용해 원하는 정보를 수집해온다.
수집한 데이터는 [영화의 순위 / 순위증감 / 영화 제목 / 예매점유율 / 개봉일] 순서로 돌아가고, 최신작의 경우엔 순위증감 정보가 없다.
먼저 각 데이터의 앞뒤 빈공간은 strip()으로 제거하고
데이터가 날짜 형식이 아닌 경우엔 li에 저장하고
날짜 형식인 경우에는 지금까지 저장한 리스트를 raw_list에 검색한 주의 날짜와 함께 저장한다.
for row in total_data:
print("*"*50, "ROW","*"*50)
for data in row:
print(data)
위 설명이 잘 이해가 안되면 이 사진을 보는게 이해하기 쉽다.
날짜형식인 데이터가 나오기 전까지는 하나의 리스트로 저장하다가 날짜 형식 데이터가 나오면 그때까지의 모든 데이터를 list형으로 raw_list에 한번에 저장하는 것이다.
맨 뒤에 있는 날짜는 내가 검색한 기준 날짜를 의미한다.
2. 데이터 전처리
1) 괄호 제거, new 삽입
for row in total_data:
for data in row:
if data[1][0] != "(":
data.insert(1, 'new')
else:
data[1] = data[1][1:-1]
for row in total_data:
print("*"*50, "ROW","*"*50)
for data in row:
print(data)
순위증감 데이터에 있던 괄호를 제거하고 순위증감정보가 없는 경우에는 "new"를 입력했다.
2) Dataframe 생성
columns = ['순위', '순위증감', '영화제목', '예매점유율', '개봉일', '주']
tmp_li = []
for data in total_data:
tmp_df = pd.DataFrame(data, columns=columns)
tmp_li.append(tmp_df)
df_target = pd.concat(tmp_li)
df_target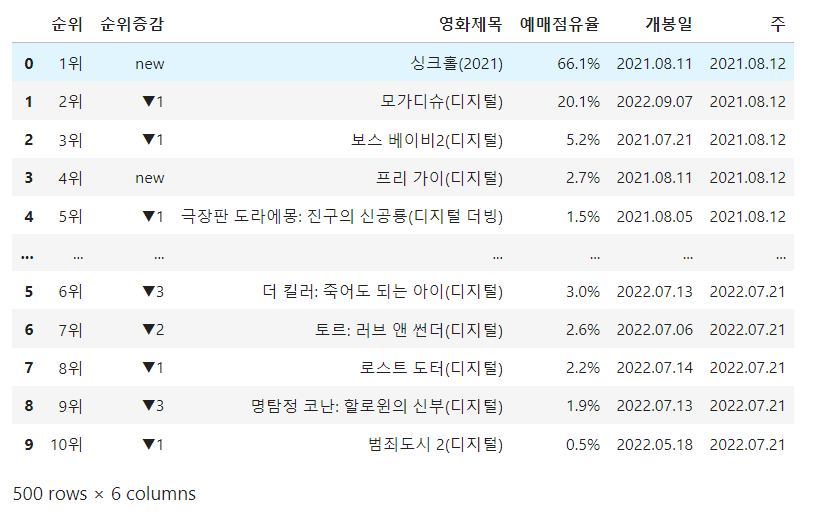
지금까지 수집한 데이터를 dataframe으로 만들어줬다.
3) 날짜에서 . 삭제
for idx, row in df_target.iterrows():
row['개봉일'] = row['개봉일'].replace('.', '')
row['주'] = row['주'].replace('.', '')
4) 정렬 & 인덱스 재설정
- 검색한 주, 영화 순위를 기준으로 정렬
custom_dict = {'1위':0, '2위':1, '3위':2, '4위':3, '5위':4, '6위':5, '7위':6, '8위':7, '9위':8, '10위':9}
df_target['rank'] = df_target['순위'].map(custom_dict)
df_target.sort_values(by=['주', 'rank'], ascending=[True, True], inplace= True)
df_target.reset_index(drop=True, inplace=True)
df_target.drop('rank', axis=1, inplace=True)
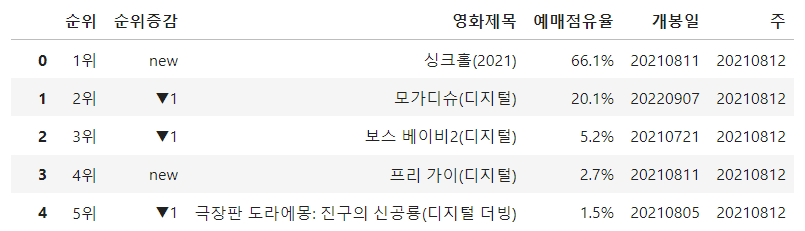
df_target"순위" 컬럼으로는 내가 원하는대로 정렬할 수 없어서 "rank"컬럼을 새로 만들어준다.
"rank"컬럼은 map()함수로 "순위" 값에 따라 값을 갖도록 만들었다.
정렬 후에는 사용할 일이 없어서 삭제했다.
3. 시각화
(1) 6주(6번) 이상 Top10에 올랐던 영화 제목
tmp_pt = pd.DataFrame(pd.pivot_table(data=df_target, index='영화제목', values='주', aggfunc=len))
tmp_pt.reset_index(inplace=True)
tmp_pt = tmp_pt[tmp_pt["주"] >= 6]
tmp_pt.sort_values(by="주", inplace=True, ascending=False)pivot_table로 몇번 Top10에 올랐는지 계산한 데이터를 만들어
6회 이상인 자료만 남겼다.
plt.figure(figsize=(12, 8))
sns.barplot(x=tmp_pt["영화제목"], y=tmp_pt["주"])
plt.xticks(rotation=90)
plt.ylabel("")
plt.xlabel("")
plt.show()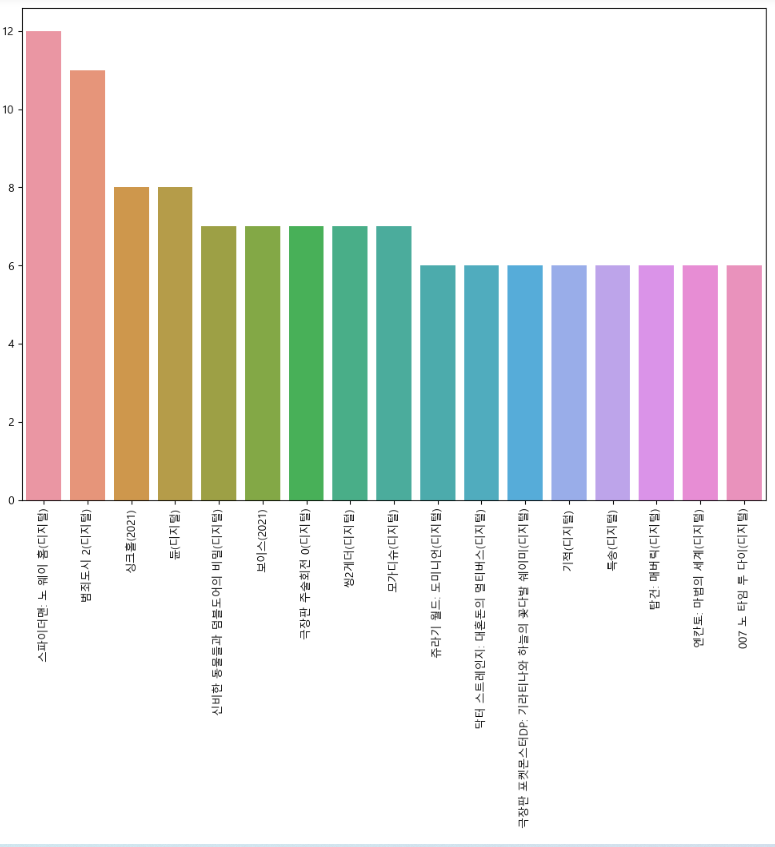
6회 이상 top10에 오른 영화는 17개이고,
그중 스파이더맨이 가장 오래 top10에 올랐다.
(2) Top10에 오른 기간 동안 예매점유율의 평균
df_target['예매율'] = 0
for idx, row in df_target.iterrows():
df_target.loc[idx, '예매율'] = float(row['예매점유율'][:-1])
tmp_pt = pd.pivot_table(data=df_target, index='영화제목', values='예매율', aggfunc=np.mean)
df_result = pd.DataFrame(tmp_pt)
df_result.reset_index(inplace=True)
df_result['예매율'] = round(df_result['예매율'], 2)
df_result.sort_values(by="예매율", ascending=False, inplace=True)"예매점유율"에서 %기호를 제거한 값을 "예매율"컬럼으로 입력했다.
pivot_table을 사용해 영화별 예매율의 평균을 구한 데이터를 새로 만들었다.
plt.figure(figsize=(12, 8))
sns.barplot(data = df_result[df_result["예매점유율"] >=30] , x="영화제목", y="예매율")
plt.xticks(rotation=90)
plt.ylabel("")
plt.xlabel("")
plt.show()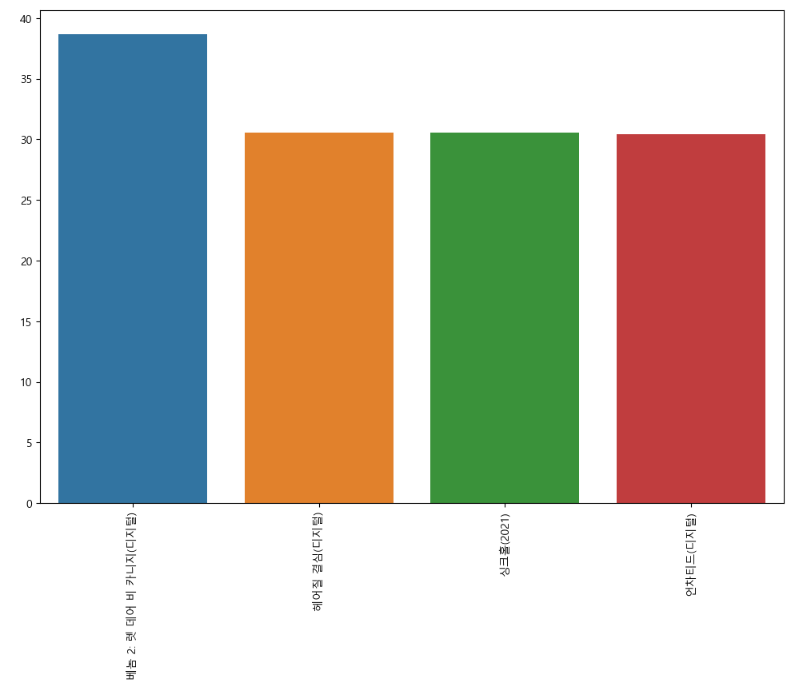
예매율(예매점유율)이 30% 이상이었던 영화는 총 4편이다.
plt.figure(figsize=(12, 8))
sns.barplot(data = df_result[df_result["예매점유율"] >=20] , x="영화제목", y="예매율")
plt.xticks(rotation=90)
plt.ylabel("")
plt.xlabel("")
plt.show()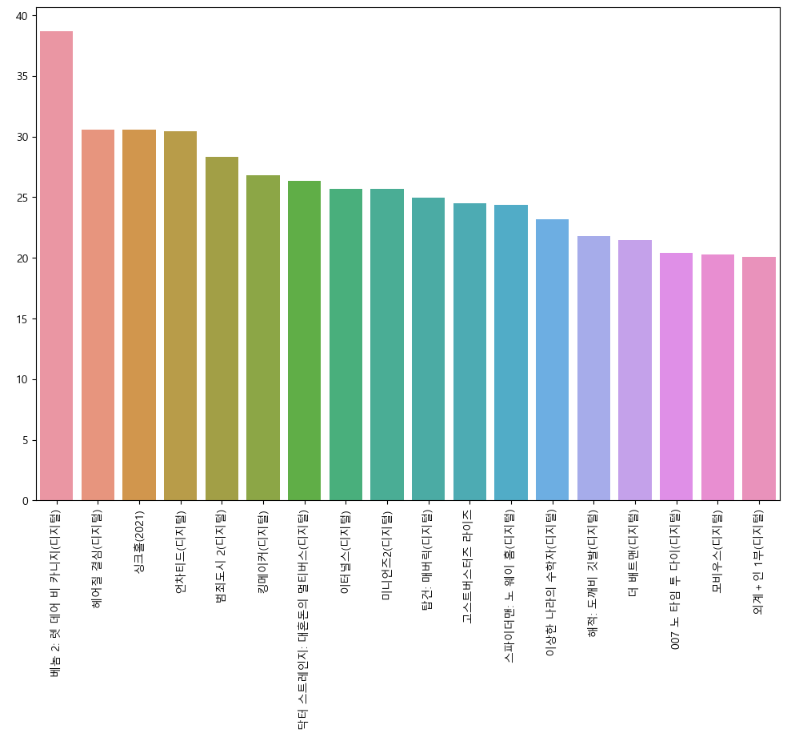
예매율(예매점유율)이 20% 이상이었던 영화는 총 18편이다.
