
1. 주제 선정
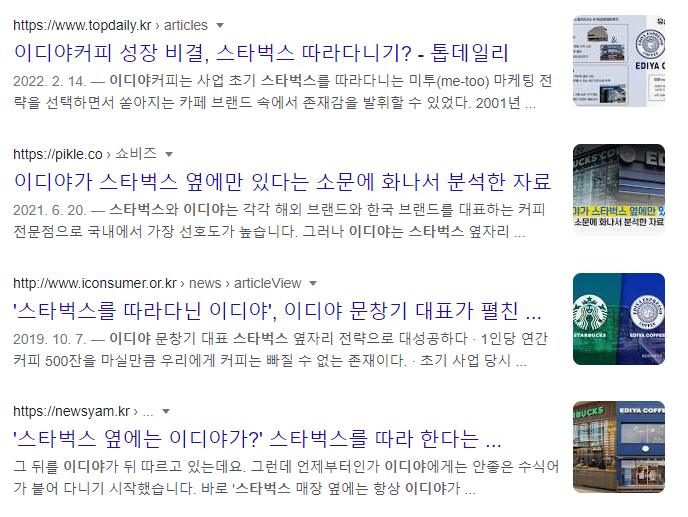
이디야 스타벅스를 구글에 검색하면 이런 결과를 볼 수 있다.
진짜 이디야 매장은 스타벅스 매장 옆에 있는지 서울시 스타벅스, 이디야 매장들의 위치를 분석해 알아보자!
2. 코드
필요한 모듈 불러오기!
1) 스타벅스 매장 위치 정보
- 스타벅스 홈페이지
- selenium과 BeautifulSoup 사용
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service('../driver/chromedriver.exe'), options=chrome_options)
url = "https://www.starbucks.co.kr/store/store_map.do"
driver.get(url)
time.sleep(5)페이지 접근
search_button = driver.find_element("xpath", '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a')
search_button.click()
time.sleep(5)
seoul_button = driver.find_element("xpath", '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a')
seoul_button.click()
time.sleep(5)
gu_button = driver.find_element("xpath", '//*[@id="mCSB_2_container"]/ul/li[1]/a')
gu_button.click()서울시에 있는 매장 검색
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")HTML 정보 추출
s_list = soup.find("div", id="mCSB_3_container").find_all("li")
star_name = []
star_address=[]
star_lat=[]
star_lng=[]
star_gu = []
for s in s_list:
star_name.append(s.get("data-name"))
star_address.append(s.find("p","result_details").text.split("1")[0])
star_gu.append(s.find("p","result_details").text.split()[1])
star_lat.append(s.get("data-lat"))
star_lng.append(s.get("data-long"))반복문으로 스타벅스 매장의 매장명, 주소, 위도, 경도, 구 이름 을 저장.
starbucks = pd.DataFrame({"매장명":star_name,
"주소":star_address,
"구":star_gu,
"lat":star_lat,
"lng":star_lng,
"브랜드":"스타벅스"})
starbucks.to_csv("../data/eda1_starbucks.csv", sep=',', encoding="utf-8")Dataframe 으로 만들고 파일로 저장!
2) 이디야 매장 위치 정보
- 이디야 홈페이지
- selenium과 BeautifulSoup 사용
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service('../driver/chromedriver.exe'), options=chrome_options)
url = "https://ediya.com/contents/find_store.html"
driver.get(url)홈페이지 접근
keys= starbucks['구'].unique()스타벅스 매장이 있는 구 이름을 keys로 설정
search_button = driver.find_element("xpath", '//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a')
search_button.click()
ediya_name = []
ediya_address=[]
ediya_gu = []
ar_box = driver.find_element("xpath", '//*[@id="keyword"]')
ar_button = driver.find_element("xpath", '//*[@id="keyword_div"]/form/button')
for key in tqdm_notebook(keys):
ar_box.send_keys("서울 " + key)
ar_button.click()
time.sleep(5)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
tmps = soup.find("ul",id ="placesList").find_all("dl")
length = len(tmps)
for n in range(0, length):
tmp = tmps[n]
name = tmp.find("dt").text
address = tmp.find("dd").text
ediya_name.append(name)
ediya_address.append(address)
ediya_gu.append(address.split()[1])
ar_box.clear()
반복문을 사용해 이디야 매장의 매장명, 주소, 구 이름을 저장
ediya = pd.DataFrame({"매장명":ediya_name,
"주소":ediya_address,
"구":ediya_gu,
"브랜드":"이디야"})Datarame으로 만든 다음
gmaps_key = "AIzaSyDEvuzM4oIo-S2FXTxUuG8gTsetREtGJ5w"
gmaps = googlemaps.Client(key=gmaps_key)
for idx, rows, in tqdm_notebook(ediya.iterrows()):
tmp = gmaps.geocode(rows["주소"], language="ko")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
ediya.loc[idx, "lat"] = lat
ediya.loc[idx, "lng"] = lng주소를 검색해 위도, 경도값을추가
ediya.to_csv("../data/eda1_ediya.csv", sep=',', encoding="utf-8")이후 파일로 저장!
나는 Jupyter 연결이 끊길수도 있고, 오늘 한번에 코드 작성을 완성하지 못할수도 있으니
중요한 Datarame은 항상 파일로 만들어 저장해둔다.
3) 이디야가 진짜 스타벅스 근처에 있는지 분석
(1) 위도와 경도를 이용해 지점 간 거리 구하기
distance = []
for eidx, erow in tqdm_notebook(ediya.iterrows()):
tmp_e = (erow["lat"], erow["lng"])
for sidx, srow in starbucks.iterrows():
if (erow["구"] == srow["구"]):
tmp_s = (srow["lat"], srow["lng"])
dt = haversine(tmp_e, tmp_s)
each = {"이디야":erow["구"],
"스타벅스":srow["구"],
"차이":dt}
distance.append(each)
else:
continue
continue같은 구 안에 있는 모든 이디야, 스타벅스 매장의 거리 차이를 haversine 모듈을 사용해 구해준다.
haversine 모듈은 두 지점의 위도, 경도값을 입력하면 두 좌표간 거리(Km)를 반환한다.
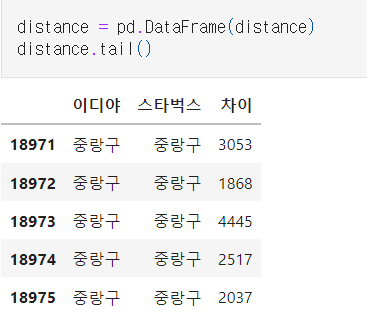
이런 Dataframe을 결과로 얻었다.
plt.figure(figsize=(20,15))
sns.boxplot(x="지역", y="차이",data=distance, palette='Set3')
plt.grid()
plt.xlabel("구 이름")
plt.ylabel("거리 차이")
plt.show()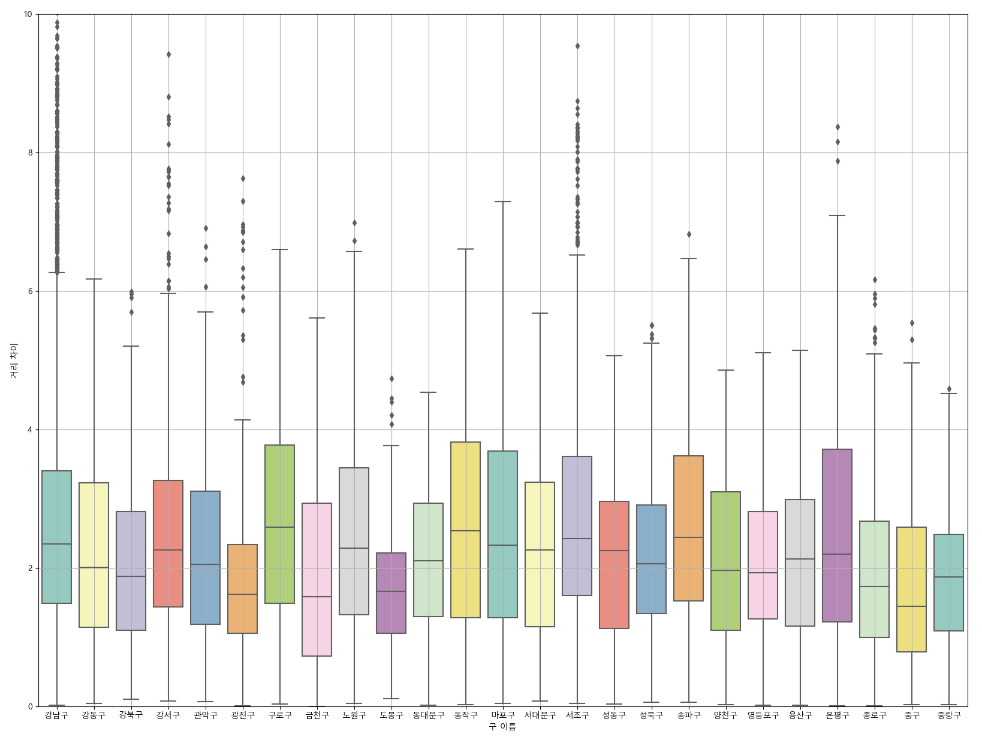
위 표를 그래프로 시각화 해봤다. 그 결과
(1) 약 7개 구를 제외하면 이상점은 많지 않다.
(2) 모든 구에서 중앙값이 2000m = 2km 부근이다.
(3) 차이가 0인 지점도 존재 한다.
따라서, 이디야 매장은 스타벅스 매장 옆에 위치한다고 볼 수 있다.
(2) folium으로 시각화
<1> 모든 매장을 지도 위에 표시
my_map = folium.Map(location=(37.5502, 126.982), zoom_start=10.5)
for idx, rows in starbucks.iterrows():
folium.Marker(location=[rows["lat"], rows["lng"]],icon=folium.Icon(icon="star", color= "green")).add_to(my_map)
for idx, rows in ediya.iterrows():
folium.Marker(location=[rows["lat"],
rows["lng"]],
icon=folium.Icon(icon="coffee",
prefix="fa",
color= "blue")).add_to(my_map)
my_map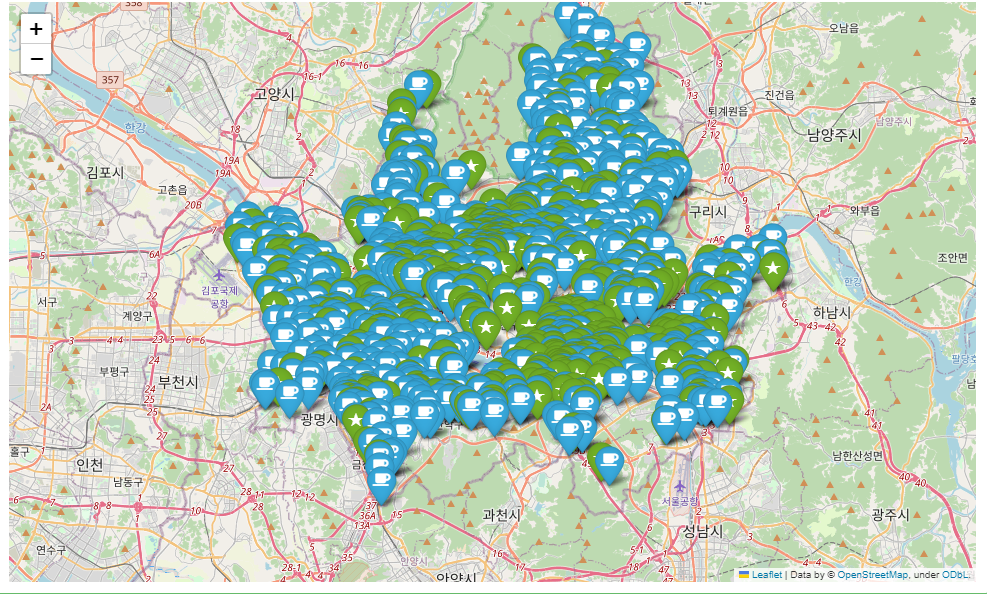
매장 개수가 너무 많아서 한눈에 들어오지 않는다.
<2> 매장 개수 차이 시각화
- 구별 매장 개수 차이를 시각화
- 색이 옅을수록 이디야와 스타벅스의 매장 개수 차이가 적다는 의미
e_data = pd.pivot_table(data=ediya, index="구",values="브랜드", aggfunc=len)
s_data = pd.pivot_table(data=starbucks, index="구",values="브랜드", aggfunc=len)
es_data= abs(s_data["브랜드"] - e_data["브랜드"] )
es = pd.DataFrame(es_data) 먼저 pivitable을 사용해 구별 매장 개수를 구하고, 그 차이를 es로 저장한다.
geo_path = "./02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
es_map = folium.Map(location=(37.5502, 126.982), zoom_start=11)
folium.Choropleth(geo_data = geo_str, data=es["브랜드"],
columns = [es.index, es["브랜드"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7).add_to(es_map)
es_map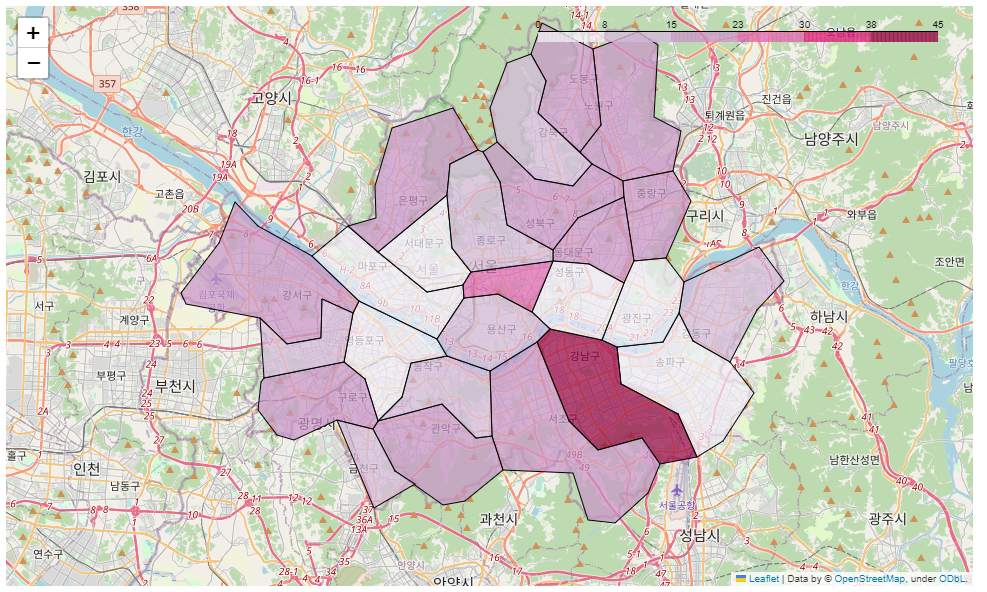
es데이터를 색상으로 지도 위에 시각화했다.
강남구를 제외하고는 모든 구의 색이 옅은것을 볼 수 있다.
따라서 모든 구에 스타벅스와 이디야의 매장 수가 비슷하다고 볼 수 있다.
3. 결론
모든 구에 이디야와 스타벅스 매장이 비슷한 개수로 존재하고,
그 매장 간 거리는 평균적으로 2km 밖에 차이나지 않는다.
따라서 이디야는 스타벅스 매장 옆에 존재한다고 할 수 있다.
그런데 둘 중 어느 매장이 먼저 생겼는지는 이 분석으론 알수 없다!
